Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
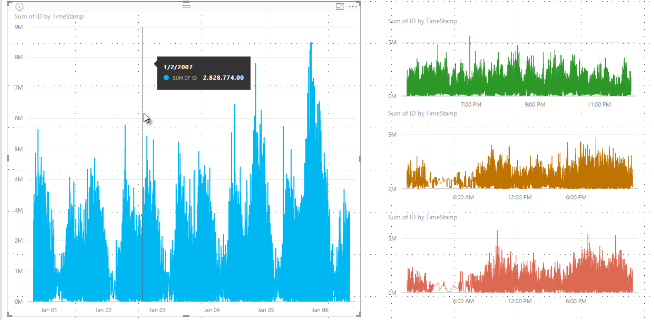
Algorytm próbkowania w usłudze Power BI ulepsza wizualizacje, które próbkują dane o wysokiej gęstości. Możesz na przykład utworzyć wykres liniowy na podstawie wyników sprzedaży sklepów detalicznych, przy czym każdy sklep ma ponad 10 000 paragonów sprzedaży rocznie. Wykres liniowy takich informacji o sprzedaży próbkuje dane z danych dla każdego sklepu i tworzy wieloserowy wykres liniowy reprezentujący dane bazowe. Wybierz znaczącą reprezentację tych danych, aby zilustrować różnice sprzedaży w czasie. Ta praktyka jest powszechna w wizualizacji danych o wysokiej gęstości. Szczegóły próbkowania danych o wysokiej gęstości opisano w tym artykule.
Uwaga / Notatka
Algorytm próbkowania o wysokiej gęstości opisany w tym artykule jest dostępny zarówno w programie Power BI Desktop , jak i usłudze Power BI.
Jak działa próbkowanie liniowe o wysokiej gęstości
Wcześniej usługa Power BI wybrała kolekcję przykładowych punktów danych w pełnym zakresie danych bazowych w sposób deterministyczny. Na przykład w przypadku danych o wysokiej gęstości w wizualizacji obejmującej jeden rok kalendarzowy wizualizacja wyświetla 350 przykładowych punktów danych. Algorytm wybiera każdy punkt danych, aby upewnić się, że pełny zakres danych jest reprezentowany w wizualizacji. Aby zrozumieć, jak to się stanie, wyobraź sobie wykreślenie ceny akcji w okresie jednego roku i wybranie 365 punktów danych w celu utworzenia wizualizacji wykresu liniowego. Jest to jeden punkt danych dla każdego dnia.
W takiej sytuacji istnieje wiele wartości dla ceny akcji w ciągu każdego dnia. Oczywiście, istnieje dzienny wysoki i niski, ale te wartości mogą wystąpić w dowolnym momencie w ciągu dnia, gdy giełda jest otwarta. W przypadku próbkowania liniowego o wysokiej gęstości, jeśli próbka danych bazowych jest pobierana o godzinie 10:30 i 12:00 każdego dnia, otrzymasz reprezentatywną migawkę danych bazowych, taką jak cena o godzinie 10:30 i 12:00. Jednak wycinek może nie odzwierciedlać rzeczywistych wartości maksymalnych i minimalnych ceny akcji dla tej reprezentatywnej wartości danych tego dnia. W takiej sytuacji i innych próbkowanie jest reprezentatywne dla danych bazowych, ale nie zawsze przechwytuje ważne punkty, co w tym przypadku byłoby dziennym wzrostem cen akcji i upadkami.
Zgodnie z definicją dane o wysokiej gęstości są próbkowane w celu tworzenia wizualizacji odpowiednio szybko reagujących na interakcyjność. Zbyt wiele punktów danych na wizualizacji może zmniejszyć jej wydajność i obniżyć widoczność trendów. Sposób próbkowania danych powoduje utworzenie algorytmu próbkowania w celu zapewnienia najlepszego środowiska wizualizacji. W programie Power BI Desktop algorytm zapewnia najlepszą kombinację reaktywności, reprezentacji i czytelnego zachowania ważnych punktów w każdym przekroju czasu.
Jak działa algorytm próbkowania liniowego
Algorytm próbkowania liniowego o wysokiej gęstości jest dostępny dla wizualizacji wykresu liniowego i wykresu warstwowego z ciągłą osią x.
W przypadku wizualizacji o wysokiej gęstości usługa Power BI inteligentnie dzieli dane na fragmenty o wysokiej rozdzielczości, a następnie wybiera ważne punkty reprezentujące każdy fragment. Ten proces fragmentowania danych o wysokiej rozdzielczości jest dostrojony, aby upewnić się, że wynikowy wykres jest wizualnie nie do odróżnienia od renderowania wszystkich bazowych punktów danych, ale jest szybszy i bardziej interaktywny.
Minimalne i maksymalne wartości wizualizacji liniowych o wysokiej gęstości
W przypadku każdej wizualizacji obowiązują następujące ograniczenia:
- 3500 to maksymalna liczba punktów danych wyświetlanych na większości wizualizacji, niezależnie od liczby bazowych punktów danych lub serii. W sprawach wyjątków, zobacz poniższą listę. Jeśli na przykład masz 10 serii z 350 punktami danych, wizualizacja osiągnie maksymalny ogólny limit punktów danych. Jeśli masz jedną serię, może to mieć do 3500 punktów danych, jeśli algorytm uzna, że najlepsze próbkowanie danych bazowych.
- Dla każdej wizualizacji istnieje maksymalnie 60 serii . Jeśli masz więcej niż 60 serii, podziel dane i utwórz wiele wizualizacji z nie więcej niż 60 seriami. Dobrym rozwiązaniem jest użycie fragmentatora do pokazywania tylko segmentów danych, ale tylko dla niektórych serii. Jeśli na przykład wyświetlasz wszystkie podkategorie w legendzie, możesz użyć fragmentatora do filtrowania według ogólnej kategorii na tej samej stronie raportu.
Maksymalna liczba limitów danych jest wyższa dla następujących typów wizualizacji, które są wyjątkami od limitu 3500 punktów danych:
- Maksymalnie 150 000 punktów danych dla wizualizacji języka R.
- 30 000 punktów danych dla wizualizacji usługi Azure Map.
- 10 000 punktów danych dla niektórych konfiguracji wykresu punktowego (wykresy punktowe domyślnie 3 500).
- 3,500 dla wszystkich pozostałych wizualizacji przy użyciu próbkowania o wysokiej gęstości. Niektóre inne wizualizacje mogą wizualizować więcej danych, ale nie używają próbkowania.
Te parametry zapewniają szybkie renderowanie wizualizacji w programie Power BI Desktop, reagowanie na interakcję użytkownika i nie powodują nadmiernego obciążenia obliczeniowego na komputerze renderujący wizualizację.
Ocena reprezentatywnych punktów danych dla wizualizacji liniowych o wysokiej gęstości
Gdy liczba bazowych punktów danych przekracza maksymalną liczbę punktów danych, które może reprezentować wizualizacja, rozpoczyna się proces nazywany grupowaniem. Segmentowanie dzieli dane bazowe na grupy nazywane pojemnikami, a następnie iteracyjnie ulepsza te pojemniki.
Algorytm tworzy jak najwięcej pojemników, aby utworzyć największy stopień szczegółowości dla wizualizacji. W każdym pojemniku algorytm znajduje minimalną i maksymalną wartość danych, aby upewnić się, że ważne i znaczące wartości, takie jak wartości odstające, są przechwytywane i wyświetlane w wizualizacji. Na podstawie wyników kwantowania i późniejszej oceny danych przez usługę Power BI minimalna rozdzielczość osi x dla wizualizacji jest określana w celu zapewnienia maksymalnego stopnia szczegółowości wizualizacji.
Jak wspomniano wcześniej, minimalny stopień szczegółowości dla każdej serii wynosi 350 punktów, a maksymalna wartość to 3500 dla większości wizualizacji. Wyjątki są wymienione w poprzedniej sekcji.
Każdy pojemnik jest reprezentowany przez dwa punkty danych, które stają się reprezentatywne punkty danych pojemnika w wizualizacji. Punkty danych są wysoką i niską wartością dla tego pojemnika. Po wybraniu wartości maksymalnych i minimalnych proces dyskretyzacji zapewnia uchwycenie i wizualizację ważnych wartości maksymalnych lub istotnych wartości minimalnych.
Jeśli ten proces wydaje się wymagać wielu analiz, aby upewnić się, że sporadyczne odstające przypadki są zidentyfikowane i prawidłowo przedstawione na grafice, masz rację. Jest to dokładna przyczyna algorytmu i procesu kwantowania.
Etykietki narzędzi i próbkowanie liniowe o wysokiej gęstości
Proces kwantowania przechwytuje i wyświetla minimalną i maksymalną wartość w danym pojemniku. Ten proces może mieć wpływ na wyświetlanie danych przez etykiety narzędziowe po najechaniu wskaźnikiem myszy na punkty danych. Aby wyjaśnić, jak i dlaczego ten proces ma wpływ na etykietki narzędzi, wróćmy do naszego przykładu na temat cen akcji.
Tworzysz wizualizację na podstawie ceny akcji i porównujesz dwie różne akcje, z których obie korzystają z próbkowania o wysokiej gęstości. Dane bazowe dla każdej serii mają wiele punktów danych. Na przykład, przechwytywanie ceny akcji co sekundę w ciągu dnia. Algorytm próbkowania liniowego o wysokiej gęstości wykonuje kwantowanie dla każdej serii niezależnie od drugiej.
Teraz pierwsze akcje skakają w górę w cenie 12:02, a następnie szybko wracają 10 sekund później. Jest to ważny punkt danych. W przypadku wystąpienia segmentacji dla tego zasobu, wysoka wartość o godzinie 12:02 jest reprezentatywnym punktem danych dla tej grupy.
Jednak w przypadku drugiego papieru wartościowego 12:02 nie jest najwyższą ani najniższą wartością w przedziale czasowym, który obejmuje tę godzinę. Może wysokie i niskie dla przedziału czasowego, który obejmuje 12:02, zdarzają się trzy minuty później. W takiej sytuacji po utworzeniu wykresu liniowego i umieszczeniu wskaźnika myszy na wartości 12:02 zostanie wyświetlona wartość w etykietce narzędzia dla pierwszej akcji. Ta wartość istnieje, ponieważ pierwszy skok akcji następuje o godzinie 12:02, a algorytm wybiera tę wartość jako najwyższy punkt danych dla zakresu. Jednak nie widzisz żadnej wartości w podpowiedzi o godzinie 12:02 dla drugiego waloru. Druga akcja giełdowa nie miała najwyższej ani najniższej wartości dla przedziału czasowego, który obejmował 12:02. W związku z tym nie ma danych do pokazania dla drugiej akcji o godzinie 12:02, więc nie są wyświetlane żadne dane w podpowiedzi.
Taka sytuacja występuje często w etykietkach narzędzi. Wysokie i niskie wartości dla określonego pojemnika prawdopodobnie nie pasują idealnie do punktów wartości osi x równomiernie skalowanych, więc etykietka narzędzia nie wyświetla wartości.
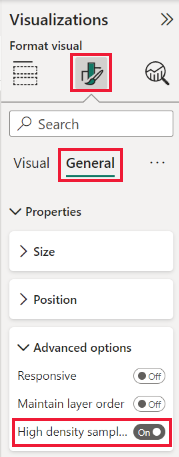
Włącz próbkowanie liniowe o wysokiej gęstości
Domyślnie algorytm jest włączony. Aby zmienić to ustawienie, przejdź do okienka Formatowanie , na karcie Ogólne i u dołu zobaczysz suwak próbkowania o wysokiej gęstości . Wybierz suwak, aby włączyć lubwyłączyć.
Uwagi i ograniczenia
Algorytm próbkowania liniowego o wysokiej gęstości jest ważnym ulepszeniem usługi Power BI, ale istnieje kilka zagadnień, które należy znać podczas pracy z wartościami i danymi o wysokiej gęstości.
- Ze względu na zwiększony stopień szczegółowości i proces grupowania, okienka z podpowiedzią mogą pokazywać wartość tylko wtedy, jeśli dane reprezentatywne są zgodne z położeniem kursora. Aby uzyskać więcej informacji, zobacz sekcję Etykietki narzędzi i próbkowanie liniowe o wysokiej gęstości w tym artykule.
- Gdy rozmiar ogólnego źródła danych jest zbyt duży, algorytm eliminuje serię (elementy legendy), aby uwzględnić maksymalne ograniczenie importu danych.
- W takiej sytuacji algorytm porządkuje serię legend alfabetycznie. Rozpoczyna się ona w dół listy elementów legendy w kolejności alfabetycznej, dopóki nie zostanie osiągnięta maksymalna liczba importowanych danych i nie importuje większej liczby serii.
- Jeśli podstawowy zestaw danych ma więcej niż 60 serii, maksymalną liczbę serii, algorytm porządkuje serię alfabetycznie i eliminuje serię poza 60 serią uporządkowaną alfabetycznie.
- Jeśli wartości w danych nie są typami liczbowymi ani data/godzina, Power BI nie używa algorytmu i przywraca poprzedni algorytm próbkowania o niskiej gęstości.
- Ustawienie Pokaż elementy bez danych nie jest obsługiwane przez algorytm.
- Algorytm nie jest obsługiwany w przypadku korzystania z połączenia na żywo z modelem hostowanym w usługach SQL Server Analysis Services w wersji 2016 lub starszej. Jest ona obsługiwana w modelach hostowanych w usługach Power BI lub Azure Analysis Services.