Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Zapytanie bezpośrednie w Power BI umożliwia przechowywanie danych w źródle i wykonywanie zapytań względem niego w czasie raportu zamiast ich importowania. W tym artykule wyjaśniono, kiedy używać trybu DirectQuery, jego ograniczeń i alternatyw, takich jak tabele hybrydowe, usługa Direct Lake i połączenia na żywo, dzięki czemu można wybrać odpowiedni tryb.
W tym artykule opisano:
- Power BI tryby łączności danych i gdzie pasuje tryb DirectQuery
- Kiedy należy używać trybu DirectQuery lub importu, tabel hybrydowych, Direct Lake lub połączenia na żywo
- Ograniczenia, implikacje i zagadnienia dotyczące wydajności
- Zalecenia dotyczące modelowania i projektowania raportów
- Diagnozowanie i poprawianie wydajności
Uwaga
Tryb DirectQuery jest również funkcją SQL Server Analysis Services. Chociaż istnieją podobieństwa, ten artykuł koncentruje się na trybie DirectQuery z modelami semantycznymi Power BI.
Aby uzyskać więcej informacji na temat modeli złożonych, zobacz Użyj modele złożone w programie Power BI Desktop. Pobierz dokument PDF DirectQuery w SQL Server 2016 Analysis Services z Microsoft.
Szybki przewodnik po decyzjach
W poniższej tabeli podsumowano, który tryb łączności Power BI należy rozważyć na podstawie wymagań. Skorzystaj z niego jako szybkiego odniesienia, aby ułatwić wybór między importem, DirectQuery, tabelami hybrydowymi, Direct Lake lub połączeniami na żywo:
| Jeśli potrzebujesz | Rozważ najpierw | Dlaczego |
|---|---|---|
| Maksymalna interakcyjność i pełna elastyczność przekształcania | Import | Silnik kolumnowy w pamięci i bogate funkcje modelowania |
| Zmiany w niemal rzeczywistym czasie dotyczą najnowszych danych faktograficznych oraz kontekstu historycznego. | Tabela hybrydowa (partycja Import i DirectQuery) | Wysyła zapytania do źródła gorących danych i buforuje dane historyczne. |
| Duża skala magazynu danych lub hurtowni z odczytami o niskich opóźnieniach (Fabric) | Direct Lake | Pomija zaplanowane odświeżanie i zachowuje funkcje importu |
| Dostęp federacyjny do wielu źródeł zewnętrznych bez pełnego pozyskiwania | Zapytanie bezpośrednie (model złożony) | Pozostawia dane na miejscu i łączy źródła. |
| Już opublikowany centralnie zarządzany model przedsiębiorstwa | Połączenie na żywo z modelem semantycznym lub usługami Analysis Services | Używa ponownie modeli kuratorowanych i unika duplikowania. |
| Przesyłanie parametrów do źródła w czasie wykonywania (filtrowanie sterowane przez użytkownika) | Zapytanie bezpośrednie z dynamicznymi parametrami języka M | Zmniejsza zeskanowane dane i poprawia wydajność. |
| Duże wyzwania związane ze współbieżnością i opóźnieniami zdalnymi | Importowanie lub agregacje za pośrednictwem zapytania bezpośredniego | Agregacje przyspieszają typowe zapytania |
tryby łączności danych Power BI
Power BI łączy się z wieloma źródłami danych:
- Usługi online, takie jak Salesforce i Dynamics 365
- Bazy danych, takie jak SQL Server, PostgreSQL, MySQL, Oracle, Snowflake i Amazon Redshift
- Pliki (Excel, CSV, JSON, Parquet)
- Silniki big data i analizy, takie jak Spark i Databricks
- Inne źródła, takie jak witryny internetowe i Microsoft Exchange
Zaimportuj dane z tych źródeł. Niektóre obsługują również tryb DirectQuery. Aby uzyskać zarządzaną listę, zobacz źródła danych Power BI. Źródła z obsługą trybu DirectQuery zwykle zapewniają interaktywną zagregowaną wydajność zapytań.
Użyj opcji importu domyślnie. Wykorzystuje aparat Power BI o wysokiej wydajności w pamięci operacyjnej i zapewnia najbogatszy zestaw funkcji. Przejdź poza importowanie tylko wtedy, gdy wymagają tego obostrzenia (opóźnienie, rozmiar, zasady zarządzania, zabezpieczenia lub architektura).
Nowoczesne ulepszenia — tabele hybrydowe, direct lake, agregacje automatyczne, modele złożone i odświeżanie przyrostowe — zmniejszają częstotliwość, w których potrzebujesz czystego trybu DirectQuery.
W poniższych sekcjach omówiono tryby importowania, trybu DirectQuery i połączenia na żywo. Pozostała część artykułu koncentruje się na trybie DirectQuery, uznając alternatywne podejścia.
Importowanie połączeń
Podczas importowania danych:
- Wybory danych definiują zapytania dla zestawu tabel; można je dopasowywać (filtrować, agregować, łączyć) przed załadowaniem.
- Wszystkie dane zdefiniowane przez te zapytania są ładowane do pamięci podręcznej modelu semantycznego.
- Wizualizacja budowana jest poprzez wykonywanie zapytań tylko do danych buforowanych — szybko i w pełni interaktywna.
- Wizualizacje nie odzwierciedlają zmian w źródle, dopóki nie zostanie odświeżone (ponownie zaimportuj).
- Publikowanie przesyła model semantyczny zawierający zaimportowane dane. Odświeżanie można zaplanować (częstotliwość zależy od licencji) i może wymagać lokalnej bramy danych.
- Kompilowanie lub otwieranie raportów w usłudze używa zaimportowanych danych.
- Przypięte kafelki pulpitu nawigacyjnego odświeżają się wraz z odświeżeniem modelu semantycznego.
Połączenia trybu DirectQuery
W przypadku korzystania z trybu DirectQuery:
- Pobieranie danych ustanawia połączenie z obsługiwanym źródłem. W przypadku źródeł relacyjnych można nadal wybierać tabele lub widoki; w przypadku źródeł wielowymiarowych (na przykład SAP BW) wybierasz model źródłowy.
- Żadne dane nie są importowane w czasie ładowania. Każda wizualizacja wyzwala co najmniej jedno zapytanie do bazowego źródła.
- Latencja odświeżania wizualnego zależy całkowicie od wydajności bazowego źródła (oraz obciążenia sieci/bramy, jeśli dotyczy).
- Zmiany w danych źródłowych są wyświetlane tylko po akcjach, które wymagają ponownych zapytań (nawigacja, slicer/zmiany filtru, odświeżanie ręczne).
- Publikowanie tworzy semantyczną definicję modelu (schemat i metadane) bez zaimportowanych danych.
- Raporty w usłudze wysyłają zapytanie do źródła. Brama sieciowa może być wymagana dla lokalnych źródeł.
- Płytki pulpitu oparte na modelach DirectQuery są odświeżane zgodnie z harmonogramem, aby buforować wyniki i umożliwić szybkie otwieranie pulpitu.
- Kafelki pulpitu nawigacyjnego pokazują wyniki z ostatniego zaplanowanego odświeżania, chyba że odświeżono je ręcznie.
Połączenia na żywo
Połączenie na żywo łączy Power BI bezpośrednio z istniejącym modelem semantycznym (na przykład z usługą Analysis Services lub innym opublikowanym modelem semantycznym Power BI). Podobnie jak w przypadku DirectQuery (bez importowanych danych), semantyka (na przykład wymuszanie ról) jest obsługiwana przez model wyższej warstwy. Po nawiązaniu połączenia na żywo:
- Zostanie wyświetlona pełna lista pól modelu zewnętrznego — bez Power Query definicji zapytania.
- Połączenia na żywo zawsze przekazują tożsamość użytkownika do usług Analysis Services lub modelu semantycznego Power BI w celu kontroli dostępu.
- Niektóre działania modelowania (takie jak dodawanie tabel obliczeniowych) nie są dostępne, ponieważ model jest zewnętrzny.
Gdzie tryb DirectQuery pasuje do nowszych opcji
Tryb DirectQuery był podstawowym rozwiązaniem dla bardzo dużych lub szybko zmieniających się danych, których nie można efektywnie importować. Dzisiaj:
- Tabele hybrydowe umożliwiają mieszanie partycji w pamięci i trybie DirectQuery w jednej tabeli (najnowsze i historyczne).
- Direct Lake (Fabric) umożliwia niemal rzeczywisty dostęp do tabel typu lakehouse bez tradycyjnego obciążenia odświeżania.
- Automatyczne agregacje i ręczne tabele agregacyjne przyspieszają częste zapytania.
- Odświeżanie przyrostowe w czasie rzeczywistym umożliwia wykonanie najnowszego zapytania bezpośredniego do źródła, podczas gdy starsze dane pozostają zaimportowane.
Przed wdrożeniem w pełni modelu DirectQuery należy ocenić te opcje.
W przypadku obciążeń szeregów czasowych w czasie rzeczywistym na Microsoft Fabric typowym wzorcem jest zapytanie bezpośrednie do bazy danych KQL Fabric (Real-Time Intelligence) sparowanej z agregacjami po stronie źródła i dynamicznymi parametrami języka M. Aby uzyskać wskazówki dotyczące tego obciążenia, zobacz Zagadnienia dotyczące źródła opartego na usłudze Kusto .
Przypadki użycia zapytania bezpośredniego
Zapytanie bezpośrednie jest najbardziej korzystne, gdy:
- Dane zmieniają się zbyt często, aby umożliwić import (nawet przy odświeżaniu przyrostowym i maksymalnej częstotliwości zaplanowanego odświeżania), a Ty potrzebujesz widoczności przy niskim opóźnieniu.
- Ograniczenia dotyczące ilości danych lub zarządzania danymi sprawiają, że pełne importowanie danych jest niepraktyczne.
- Zabezpieczenia wymuszane przez źródło (reguły wierszy szczegółowe) muszą pozostać autorytatywne za pośrednictwem przekazywania.
- Niezależność danych lub reguły regulacyjne ograniczają utrwalane pełne kopie.
- Źródło jest wielowymiarowe lub skoncentrowane na mierze (na przykład SAP BW), a miary zdefiniowane przez serwer muszą być rozwiązane dla każdej wizualizacji.
Dane zmieniają się często, a ty potrzebujesz raportowania niemal w czasie rzeczywistym.
Zaimportowane modele (Pro) mogą planować maksymalnie 8 odświeżeń dziennie (plus wyzwalacze na żądanie, interfejs API). Obsługa do 48 zaplanowanych odświeżeń dziennie w warstwie Premium i PPU, a także odświeżanie przyrostowe i tryb DirectQuery w czasie rzeczywistym dla najnowszej partycji (hybrydowej). Jeśli nadal nie można spełnić wymaganego opóźnienia — lub pełny import jest niewykonalny — użyj trybu DirectQuery, tabel hybrydowych lub usługi Direct Lake. Dashboardy DirectQuery mogą odświeżać kafelki co 15 minut.
Dane są duże
Pełny import może przekraczać dostępne zasoby pamięci lub limity odświeżania. Zapytanie bezpośrednie przetwarza dane na miejscu. Jeśli źródło jest zbyt wolne, aby zapewnić interaktywne działanie, rozważ:
- Importowanie tylko zagregowanych lub filtrowanych podzestawów.
- Używanie odświeżania przyrostowego i agregacji.
- Używanie tabel hybrydowych lub Direct Lake dla najnowszych i wartościowych segmentów.
Zobacz duże modele semantyczne w Power BI Premium dla zarządzania dużymi zbiorami danych w pamięci.
Zabezpieczenia wymuszone przez źródło
Importowanie opiera się na poświadczeniach Power BI oraz opcjonalnych zabezpieczeniach (RLS) zdefiniowanych na poziomie wiersza w modelu semantycznym. Zapytanie bezpośrednie może (jeśli jest obsługiwane) przekazywać tożsamość użytkownika (SSO), aby źródło wymuszało własne reguły zabezpieczeń. Zobacz Przegląd logowania jednokrotnego dla lokalnych bram danych w Power BI.
Ograniczenia niezależności danych
Gdy przepisy wymagają, aby dane pozostawały w kontrolowanych granicach, limity trybu DirectQuery ograniczają utrwalanie kopii. Pamięci podręczne wizualizacji i kafelków mogą nadal zawierać ograniczone zagregowane dane.
Źródło z miarami określonymi przez serwer
Niektóre systemy (takie jak SAP BW) zawierają logikę semantyczną (miary i hierarchie), które są rozpoznawane w czasie wykonywania zapytania. Tryb DirectQuery umożliwia rozpoznawanie poszczególnych wizualizacji. Zobacz DirectQuery i SAP BW i DirectQuery i SAP HANA.
Zagadnienia dotyczące konkretnych źródeł (w tym PostgreSQL i MySQL)
Zachowanie i wydajność różnią się w zależności od silnika.
- PostgreSQL: Identyfikatory cytowane rozróżniają wielkość liter. Upewnij się, że odpowiednie indeksy b-tree w kolumnach sprzężenia i filtrowania. Unikaj funkcji, które wcześnie przerywają proces składania zapytania. Sprawdzanie niejawnych rzutów na sprzężenia tekstowe i liczbowe.
-
MySQL: Używaj spójnego sortowania i trybów SQL. Tworzenie indeksów złożonych dla typowych wzorców filtrów i sprzężeń. Duże
TEXTkolumny mogą zmniejszyć składanie lub wymusić przetwarzanie poprocesowe. - Snowflake, BigQuery i Databricks: Elastyczne skalowanie zwiększa współbieżność, ale opóźnienie zimnego startu może mieć wpływ na pierwsze zapytanie. Wysyłaj polecenia ping rozgrzewkowe lub zaplanuj okresową aktywność.
- Azure Synapse, SQL i Fabric Warehouse: Indeksy magazynów kolumnowych i buforowanie zestawów wyników zapewniają silne przyspieszenie. Połącz je z funkcją automatycznych agregacji.
- źródła Kusto (bazy danych Azure Data Explorer i Fabric KQL): Przycinanie projekcji ma znaczenie. Wybierz tylko wymagane kolumny i zastosuj filtry na wczesnym etapie. W przypadku telemetrii szeregów czasowych o dużej ilości użyj agregacji po stronie źródła, zamiast grupowania po stronie klienta: wypchnij
make-series,summarizeiseries_decompose_anomaliesdo silnika KQL i zwróć zagregowane wyniki do wizualizacji. Upewnij się, że kroki Power Query są przetwarzane do natywnego języka KQL, aby podsumowane wyniki — a nie surowe zdarzenia — zostały zwrócone do Power BI. - SAP BW i SAP HANA: Rozdzielczość miar i semantyka hierarchii kształtują wzorce zapytań. Unikaj nakładania przekształceń, które blokują składanie.
Potwierdź składanie zapytań (wybierz View Native Query w Edytor Power Queryze), aby przekształcenia zostały przesunięte w dół.
Ograniczenia trybu DirectQuery
Korzystanie z trybu DirectQuery ma wpływ na spójność, wydajność, zabezpieczenia, przekształcenia, modelowanie i raportowanie.
Ogólne implikacje
Podczas korzystania z trybu DirectQuery w Power BI mają zastosowanie następujące ogólne implikacje:
- Odśwież, aby wyświetlić najnowsze dane. Pamięci podręczne (wizualne, kafelkowe, wyniki) oznaczają, że element wizualny może wyświetlać wcześniejsze wyniki do czasu odświeżenia. Wybierz Odśwież, aby wymusić ponowne załadowanie wszystkich wizualizacji na stronie.
- Wizualizacje nie zawsze są spójne w czasie. Różne wizualizacje (lub zapytania wewnętrzne w jednej wizualizacji) mogą być wykonywane nieco inaczej. Odśwież stronę lub projektuj zagregowane migawki, jeśli wymagana jest ścisła dokładność punktualna.
- Zmiany schematu wymagają odświeżenia Power BI Desktop. Usługa nie wykrywa automatycznie porzuconych lub zmienionych kolumn. Otwórz model w programie Power BI Desktop i odśwież, aby uzgodnić metadane modelu.
- Limit jednego miliona wierszy dla pośrednich wyników. Każde zapytanie (lub operacja pośrednia), które zwraca więcej niż 1000 000 wierszy, kończy się niepowodzeniem. Pojemności Premium mogą zwiększyć ten limit — zobacz Maksymalna liczba zestawów wierszy pośrednich.
- Zmiana trybu przechowywania jest ograniczona. Nie można w sposób globalny przełączyć modelu tylko do importu na DirectQuery. Zobacz następną sekcję.
Ważne
Ponieważ mechanizm przechowywania i przetwarzania danych w Power BI ignoruje wielkość liter, należy zachować szczególną ostrożność podczas pracy w trybie DirectQuery ze źródłem uwzględniającym wielkość liter. Power BI zakłada, że źródło wyeliminowało zduplikowane wiersze. Ponieważ Power BI ignoruje wielkość liter, traktuje dwie wartości różniące się tylko wielkością liter jako duplikaty, a źródło może nie traktować ich w ten sposób. W takich przypadkach ostateczny wynik jest niezdefiniowany.
Aby uniknąć takiej sytuacji, jeśli używasz trybu DirectQuery ze źródłem danych uwzględniającym wielkość liter, normalizuj wielkość liter w zapytaniu źródłowym lub w Edytorze Power Query.
Zmienianie trybów przechowywania (Import ↔ DirectQuery)
Nie można przełączać całego modelu importu do trybu DirectQuery. Zamiast:
- Dodaj nowe połączenie DirectQuery z tym samym źródłem i mapuj wizualizacje do nowych tabel.
- Utwórz model złożony: zachowaj wymiary dla importu, dodaj tabele faktów DirectQuery (lub odwrotnie), i opcjonalnie ustaw niektóre tabele na tryb podwójny.
- Użyj tabel hybrydowych (ostatnich partycji DirectQuery i importu historycznego) w celu optymalizacji gorącej i zimnej.
- Przebuduj za pomocą przekształceń przyjaznych dla składania, jeśli wcześniejsze kroki uniemożliwiają tryb DirectQuery.
Uwaga
Poszczególne tabele dodane za pośrednictwem połączenia z obsługą trybu DirectQuery mogą przełączać się między trybami DirectQuery, Import i Dual, jeśli wszystkie zastosowane przekształcenia nadal są składane.
Wpływ na wydajność i obciążenie
Wydajność interaktywna zależy od opóźnienia źródła i współbieżności. Dążyć do typowych czasów odświeżania wizualizacji poniżej 5 sekund; więcej niż 30 sekund obniża użyteczność. Każda akcja użytkownika wyzwala zapytania. Duża liczba odświeżeń użytkowników, wizualizacji i kafelków może spowodować znaczne obciążenie — odpowiednio zaplanuj pojemność.
Implikacje dotyczące zabezpieczeń
Jeśli nie skonfigurowano logowania jednokrotnego, DirectQuery używa skonfigurowanych przechowywanych poświadczeń dla wszystkich użytkowników. Zdefiniuj RLS (zabezpieczenia na poziomie wiersza) w modelu semantycznym zgodnie z potrzebami. Wiele źródeł w modelach złożonych może przenosić dane między źródłami; ocena przenoszenia poufnych danych — zobacz Implikacje dotyczące zabezpieczeń.
Ograniczenia przekształcania danych
Power Query składanie jest wymagane w celu uzyskania skalowalnej wydajności. Przekształcenia muszą skondensować się w jedno zapytanie natywne. Złożone kroki (niefoldowalne operacje, niektóre funkcje niestandardowe, wieloetapowa logika proceduralna) mogą powodować błędy, które wymagają uproszczenia lub przełączenia na import. Źródła OLAP, takie jak SAP BW, nie zezwalają na transformacje wewnątrz zapytań, ponieważ cały model zewnętrzny jest odsłonięty. Wywołania procedur składowanych i wspólne wyrażenia tabel (CTEs) nie są obsługiwane w sposób, który umożliwia składanie w trybie DirectQuery.
Ograniczenia modelowania
Większość funkcji wzbogacania działa, ale niektóre możliwości są ograniczone:
- Brak automatycznej hierarchii dat (utwórz jawną tabelę dat).
- Precyzja czasu ograniczona do sekund (usuń milisekundy w źródle).
- Kolumny obliczeniowe ograniczone do wyrażeń na poziomie wiersza, które składają się; nieobsługiwane funkcje pominięte z autouzupełniania.
- Funkcje PATH dla relacji nadrzędny-podrzędny są niedostępne.
- Klastrowanie nie jest obsługiwane.
Ograniczenia raportowania
Większość wizualizacji działa, jeśli źródło jest responsywne. Obejrzyj następujące ograniczenia i zagadnienia dotyczące wydajności:
- Długie kolumny tekstowe dłuższe niż 32 764 znaki nie są obsługiwane.
- Filtry miar, filtry TopN,
Median, tekst zaawansowany zawiera/rozpoczyna filtry, fragmentatory wielokrotnego wyboru i sumy/sumy częściowe (szczególnie w przypadkuDistinctCount) mogą dodawać dodatkowe zapytania lub obniżać wydajność. - Rozważ uproszczenie projektu lub wyłączenie niektórych interakcji.
Przykład (filtr miary):
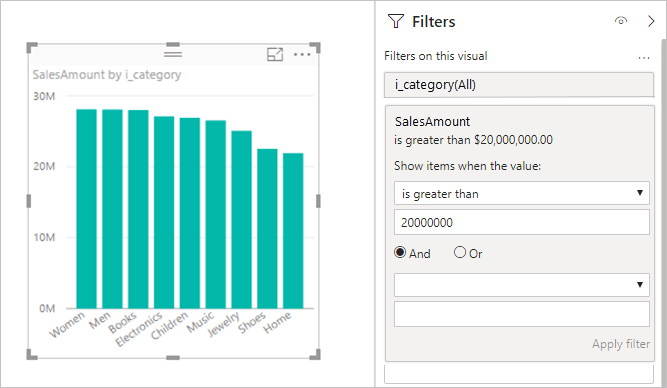
Zalecenia dotyczące trybu DirectQuery
Ta sekcja zawiera praktyczne zalecenia dotyczące projektowania, optymalizowania i rozwiązywania problemów z modelami DirectQuery w Power BI. Postępuj zgodnie z tymi wytycznymi, aby zwiększyć wydajność, niezawodność i środowisko użytkownika podczas pracy z połączeniami DirectQuery.
Wydajność bazowego źródła danych
Weryfikowanie interakcyjnych zapytań bazowych. Jeśli działają wolno, sprawdź zapytania przy użyciu Analizator wydajności i zoptymalizuj schemat źródłowy (indeksy, statystyki i magazyn kolumn tam, gdzie ma to zastosowanie). Preferuj klucze całkowite przy sprzężeniach.
Projektowanie modelu
- Zachowaj kroki Power Query prostymi i przetwarzalnymi. Często podglądaj "Wyświetl zapytanie natywne".
- Zacznij od prostych miar , a następnie iteruj.
- Unikaj łączeń na kolumnach z wyrażeniami obliczeniowymi — w razie potrzeby zmaterializuj je w źródle.
-
Unikaj sprzężeń na
uniqueidentifiergdzie rzutowania przerywają użycie indeksu; materializuj alternatywne typy kluczy. - Ukryj klucze zastępcze/systemowe; w razie potrzeby utwórz widoczne kolumny aliasowe.
- Przejrzyj tabele obliczeniowe/kolumny , które mogą tworzyć niefoldowalne wyrażenia.
- Ogranicz filtry dwukierunkowe tylko do wymaganych przypadków. Przetestuj wpływ na wydajność.
-
Rozważ założenie, że integralność referencyjna umożliwia użycie
INNER JOIN. - Unikaj filtrów dat względnych w Power Query. Zaimplementuj względną logikę w warstwie modelu lub raportu.
Przykład filtrowania:
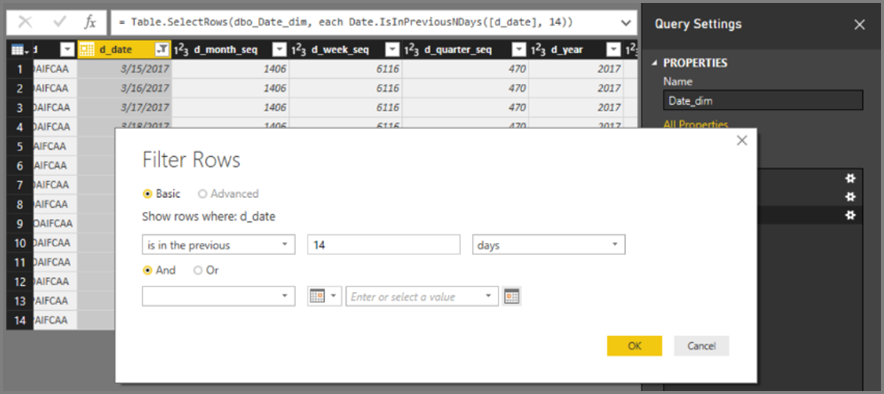
Wynikowe zapytanie natywne używa stałej daty literału:

Projekt raportu
Podczas projektowania raportów korzystających z trybu DirectQuery należy wziąć pod uwagę następujące najlepsze rozwiązania, aby zoptymalizować użyteczność i wydajność:
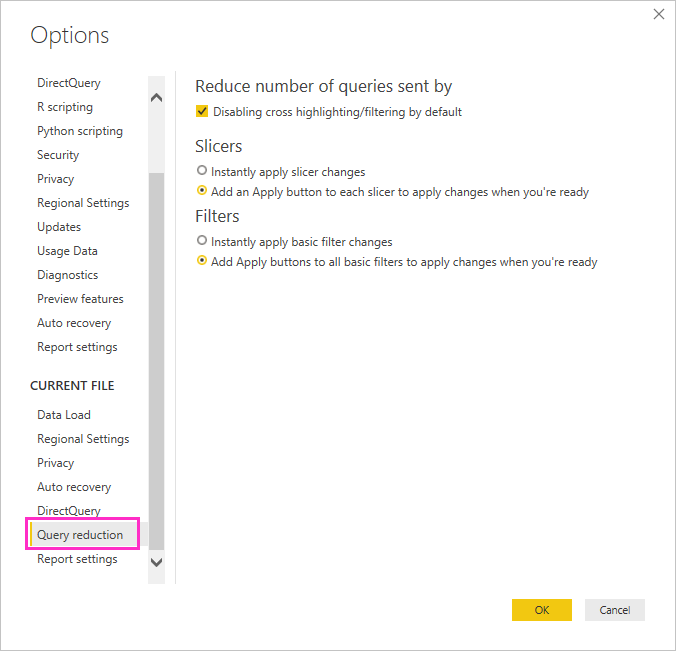
Użyj opcji redukcji zapytań (użyj przycisku Zastosuj dla fragmentatorów i filtrów i wyłącz wyróżnianie krzyżowe, gdy opóźnienie wpływa negatywnie na wrażenia użytkownika).
Zastosuj filtry kluczy na wczesnym etapie , aby zmniejszyć liczbę wierszy pośrednich i uniknąć osiągnięcia limitów.
Ogranicz wizualizacje na stronę , aby zminimalizować równoległe i serializowane zapytania.
Wyłącz niepotrzebne interakcje (filtrowanie krzyżowe lub wyróżnianie), jeśli wyzwalają kosztowne zapytania źródłowe.
Maksymalna liczba połączeń
Dostosuj współbieżność DirectQuery dla pliku (domyślnie 10) w Plik > Opcje i ustawienia > Opcje > DirectQuery dla bieżącego pliku.
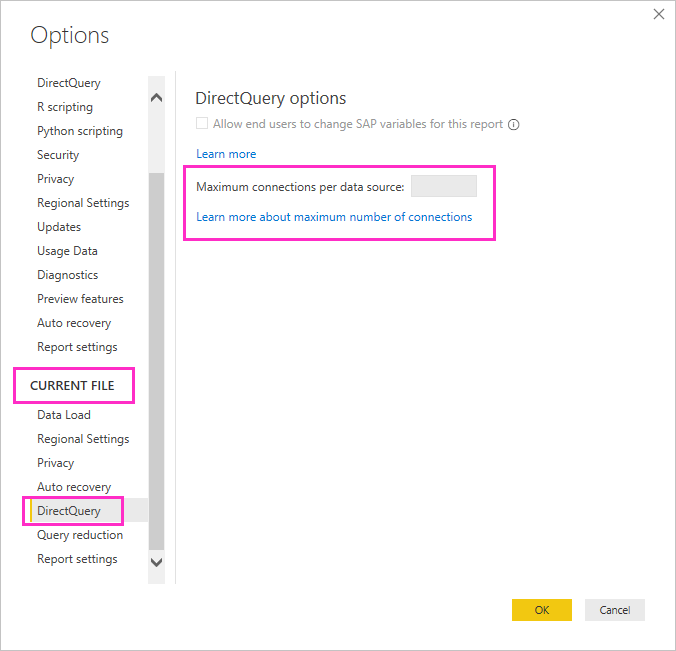
Wyższe wartości mogą zwiększyć przepływność dla wielu wizualizacji, ale mogą również zwiększyć obciążenie źródła. Opublikowane zachowanie zależy również od limitów usługi lub pojemności.
| Środowisko | Górny limit dla źródła danych |
|---|---|
| Power BI Pro | 10 aktywnych połączeń |
| Power BI Premium | Zależy od ograniczenia jednostki SKU modelu semantycznego |
| Serwer raportów usługi Power BI | 10 aktywnych połączeń |
Uwaga
Ustawienie maksymalnej liczby połączeń trybu DirectQuery dotyczy wszystkich źródeł trybu DirectQuery po włączeniu rozszerzonych metadanych (ustawienie domyślne dla nowych modeli).
Funkcje ograniczania wydajności
Użyj tych funkcji, aby zwiększyć wydajność trybu DirectQuery:
- Automatyczne agregacje i ręczne tabele agregacji: Buforowanie podsumowanych danych w celu zmniejszenia liczby zapytań źródłowych.
- Tabele hybrydowe: Przechowują ostatnie dane poprzez DirectQuery, a historyczne poprzez import.
- Projekt miary z obsługą agregacji: Upewnij się, że DAX przeprowadza ocenę na warstwie agregacji, jeśli jest to możliwe.
- Dynamiczne parametry M: Wczesne przekazywanie wyborów użytkowników do predykatów źródłowych.
- Buforowanie zapytań i wyników (ustawienia pojemności): Ponowne używanie niedawno używanych zestawów wyników dla często powtarzających się wizualizacji.
- Podwójny tryb przechowywania dla udostępnionych tabel wymiarów: Zmniejsz powtarzające się zdalne skanowanie wymiarów.
Zapytanie bezpośrednie w usłudze Power BI
Wszystkie źródła danych trybu DirectQuery są obsługiwane za pośrednictwem programu Power BI Desktop. Tylko ograniczony podzestaw rozpoczyna się bezpośrednio z poziomu interfejsu użytkownika usługi. Zacznij od Power BI Desktop, aby uzyskać bogatszą kontrolę modelowania i przekształcania. Aby uzyskać bieżącą listę źródeł dostępnych bezpośrednio w usłudze, zobacz Power BI źródła danych.
Wydajność w usłudze zależy od:
- Liczba współbieżnych użytkowników
- Złożoność wizualna i liczba elementów wizualnych na stronę
- Obecność zabezpieczeń na poziomie wiersza (może zmniejszyć ponowne użycie pamięci podręcznej)
- Harmonogramy odświeżania kafelków
Zgłaszanie zachowań w usłudze Power BI
Otwieranie strony raportu uruchamia zapytania dla każdej wizualizacji (czasami wiele na wizualizację). Interakcje (zmiany fragmentatora, wyróżnianie krzyżowe, filtry) ponownie uruchamiają zapytania. Usługa buforuje niektóre wyniki. Zapytania powtarzane dokładnie mogą być zwracane natychmiast, chyba że różnią się granice zabezpieczeń.
Niuanse możliwości:
- Szybkie spostrzeżenia: Nieobsługiwane w przypadku modeli semantycznych DirectQuery.
- Eksploruj w Excel / Analizuj w Excel: Obsługiwane, ale może działać wolniej. Rozważ użycie trybu importu lub agregacji w przypadku dużego użycia Excel.
- Hierarchies w Excel: Niektóre hierarchie modelu semantycznego trybu DirectQuery nie są takie same w Excel.
Odświeżanie pulpitu nawigacyjnego
Kafelki trybu DirectQuery są odświeżane zgodnie z harmonogramem. Wartość domyślna to co godzinę i można ją ustawić z co 15 minut do co tydzień. W przypadku zabezpieczeń na poziomie wiersza każdy użytkownik uruchamia oddzielne zapytania dotyczące kafelków. Duża liczba kafelków pomnożona przez liczbę użytkowników i częstotliwość odświeżania może powodować duże obciążenie — planowanie pojemności i uwzględnianie agregacji.
Limity czasu zapytań
Usługa wymusza 4-minutowy limit czasu na zapytanie. Wizualizacje, które przekraczają limit, kończą się niepowodzeniem z powodu błędu timeout. Przed wybraniem trybu DirectQuery upewnij się, że bazowe źródła zapewniają interaktywną wydajność.
Diagnostyka wydajności
Najpierw zdiagnozuj wydajność w programie Power BI Desktop.
Użyj analizatora wydajności , aby odizolować powolne wizualizacje. Skoncentruj się na jednej problematycznej wizualizacji naraz.
Wyświetlanie zapytań za pomocą SQL Server Profilera
Power BI Desktop zapisuje ślady sesji, w tym DirectQuery SQL dla niektórych źródeł, do pliku FlightRecorderCurrent.trc w folderze AnalysisServicesWorkspaces użytkownika.
Aby zlokalizować ślad:
W programie Power BI Desktop wybierz pozycję Plik > Opcje i ustawienia > Opcje > Diagnostyka.
Wybierz pozycję Otwórz folder Zrzut awaryjny/ślady.
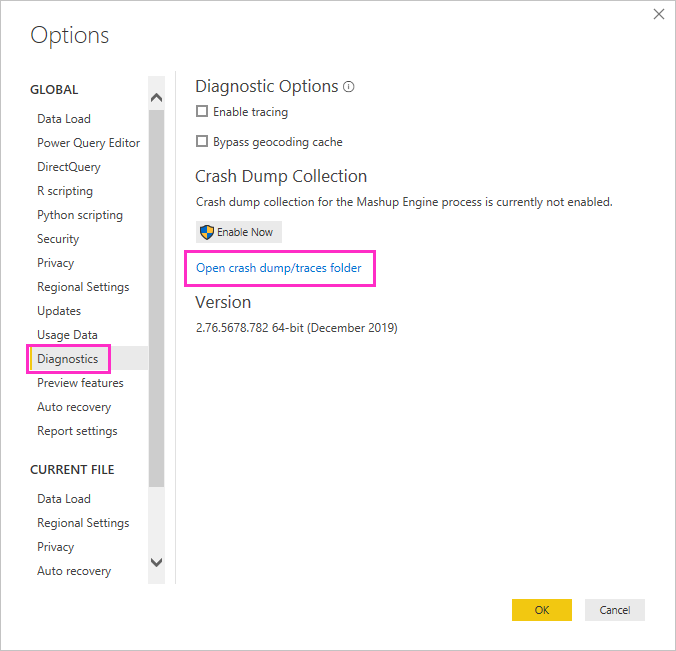
Przejdź w górę o jeden poziom do AnalysisServicesWorkspaces, otwórz aktywny folder obszaru roboczego, następnie przejdź do Data i znajdź pozycję FlightRecorderCurrent.trc.
W programie SQL Server Profiler otwórz plik: File > Otwórz plik > Trace File.
Profiler wyświetla pogrupowane zdarzenia:

Kolumny zdarzeń:
- TextData: Język DAX (początek/zakończenie zapytania) lub Natywny SQL (początek/zakończenie DirectQuery).
- Czas trwania (ms) i EndTime pomagają wskazać powolne etapy.
- ActivityID grupuje powiązane zdarzenia.
Wskazówki dotyczące przechwytywania:
- Zachowaj krótkie sesje (≈10 sekund docelowych działań).
- Otwórz ponownie plik śledzenia, aby wyświetlić nowo opróżnione zdarzenia.
- Unikaj wielu współbieżnych wystąpień Pulpitu, aby zmniejszyć zamieszanie.
Omówienie formatu zapytań
Power BI często używa podzapytania (tabela pochodna) dla każdej tabeli logicznej zdefiniowanej przez kroki Power Query.
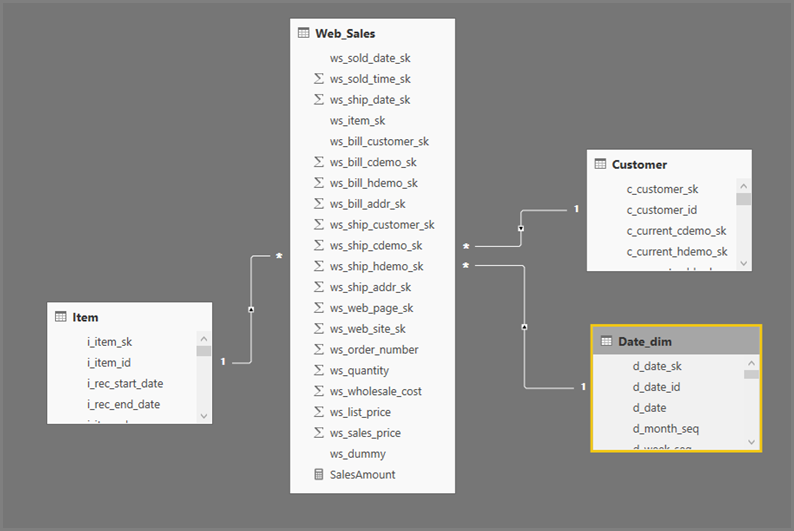
Przykładowa logika zapytań:
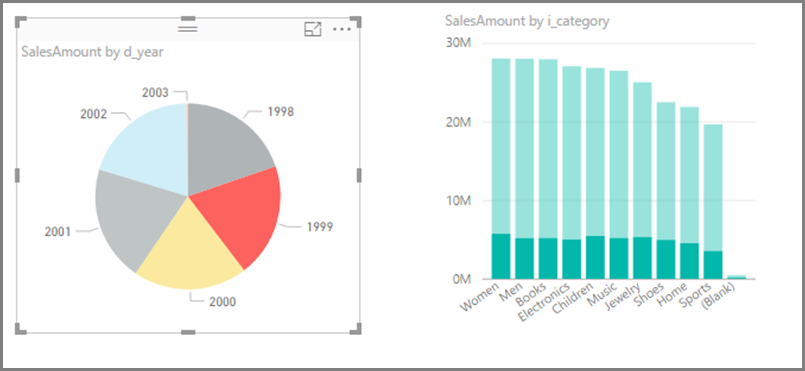
SalesAmount (SUMX(Web_Sales, [ws_sales_price]*[ws_quantity]))
by Item[i_category]
for Date_dim[d_year] = 2000
Wynikowa wizualizacja:
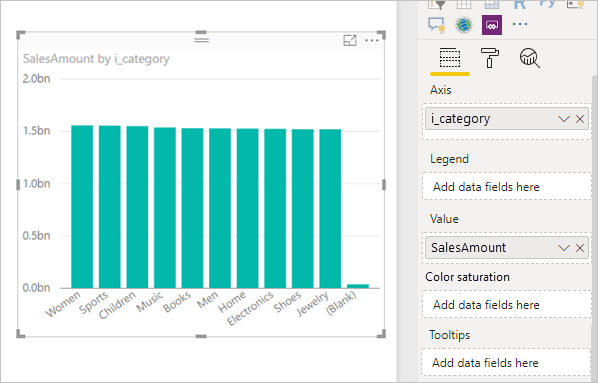
Wygenerowano sql z podwybierzami:
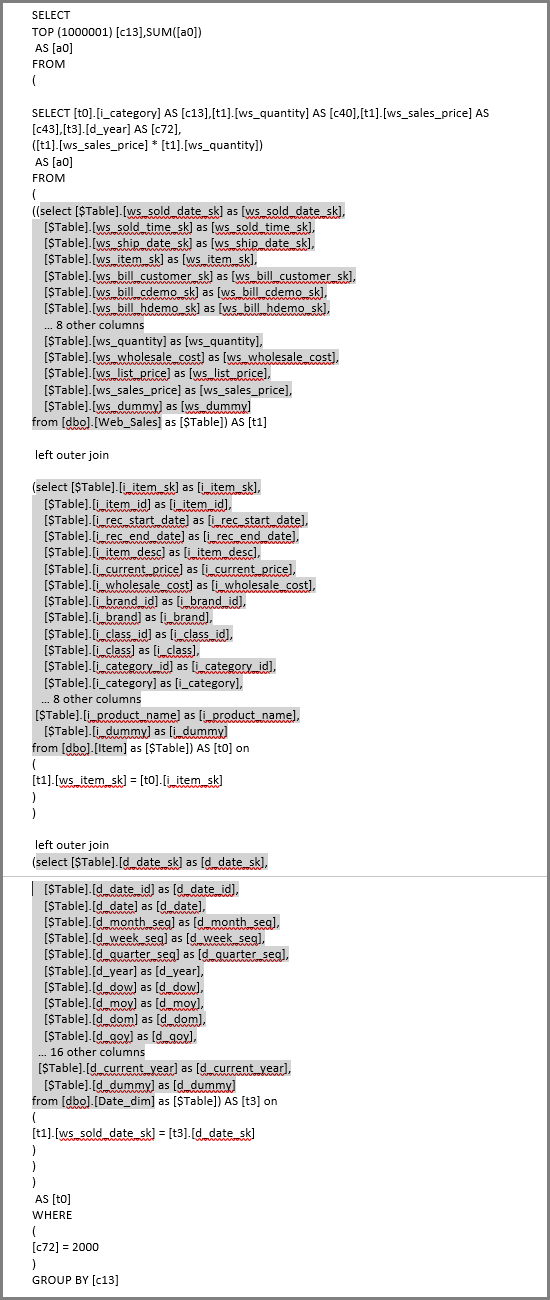
Wzorce zapytań z podzapytaniami zwykle nie wpływają negatywnie na wydajność obsługiwanych silników, ponieważ optymalizatory eliminują nieużywane kolumny. Priorytetyzuj składanie.
Uwaga
Ten artykuł zawiera ogólne wskazówki dotyczące trybu DirectQuery w Power BI. Przed wdrożeniem w środowisku produkcyjnym należy zawsze weryfikować wydajność i zachowanie zapytania bezpośredniego przy użyciu określonego źródła danych, schematu, indeksów, obciążenia i wymagań współbieżności.
Powiązana zawartość
- Użyj zapytania bezpośredniego w programie Power BI Desktop
- DirectQuery i SAP HANA
- Zapytanie bezpośrednie i oprogramowanie SAP BW
- Użyj trybu DirectQuery dla modeli semantycznych Power BI i usług Analysis Services
- Aggregacje w Power BI
- Analizator wydajności
- Modele złożone
- Omówienie zabezpieczeń na poziomie wiersza
- logowania jednokrotnego (SSO)