Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten artykuł jest skierowany do modelarzy danych korzystających z programu Power BI Desktop. Jest to ważny temat projektowania modelu, który jest niezbędny do dostarczania intuicyjnych, dokładnych i optymalnych modeli.
Aby dowiedzieć się więcej na temat optymalnego projektu modelu, w tym ról tabel i relacji, zobacz Zrozumienie schematu gwiazdy i jego znaczenia dla Power BI.
Cel relacji
Relacja modelu propaguje filtry zastosowane w kolumnie jednej tabeli modelu do innej tabeli modelu. Filtry będą propagowane tak długo, jak istnieje ścieżka relacji do naśladowania, co może obejmować propagację do wielu tabel.
Ścieżki relacji są deterministyczne, co oznacza, że filtry są zawsze propagowane w taki sam sposób i bez przypadkowych zmian. Relacje mogą być jednak wyłączone lub mieć kontekst filtru zmodyfikowany przez obliczenia modelu, które używają określonych funkcji języka DAX (Data Analysis Expressions). Aby uzyskać więcej informacji, zobacz sekcję Odpowiednie funkcje języka DAX w dalszej części tego artykułu.
Ważne
Relacje modelu nie wymuszają integralności danych. Aby uzyskać więcej informacji, zobacz sekcję Ocena relacji w dalszej części tego artykułu, w której wyjaśniono, jak zachowują się relacje modelu, gdy występują problemy z integralnością danych.
Oto jak relacje propagują filtry za pomocą animowanego przykładu.
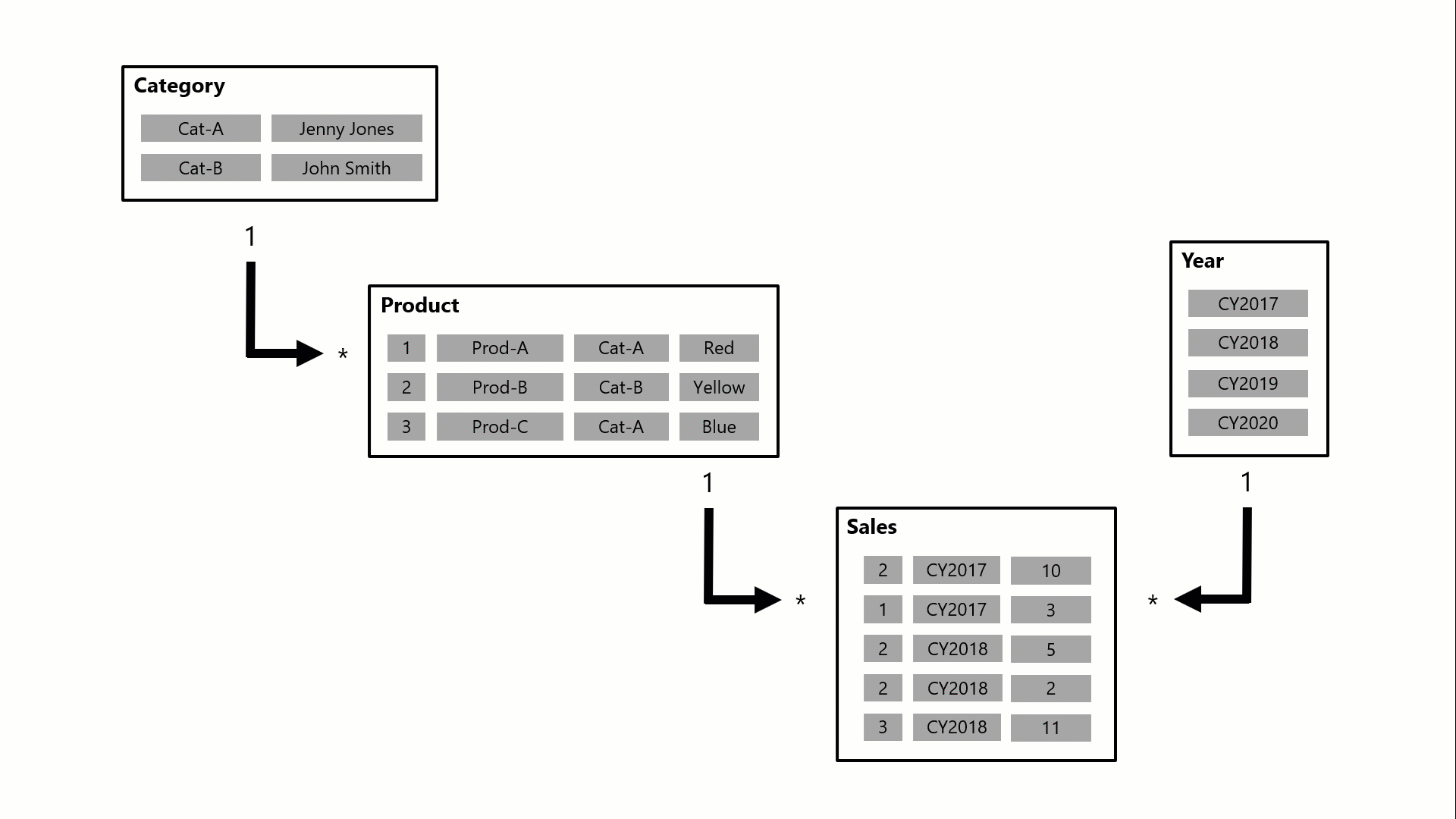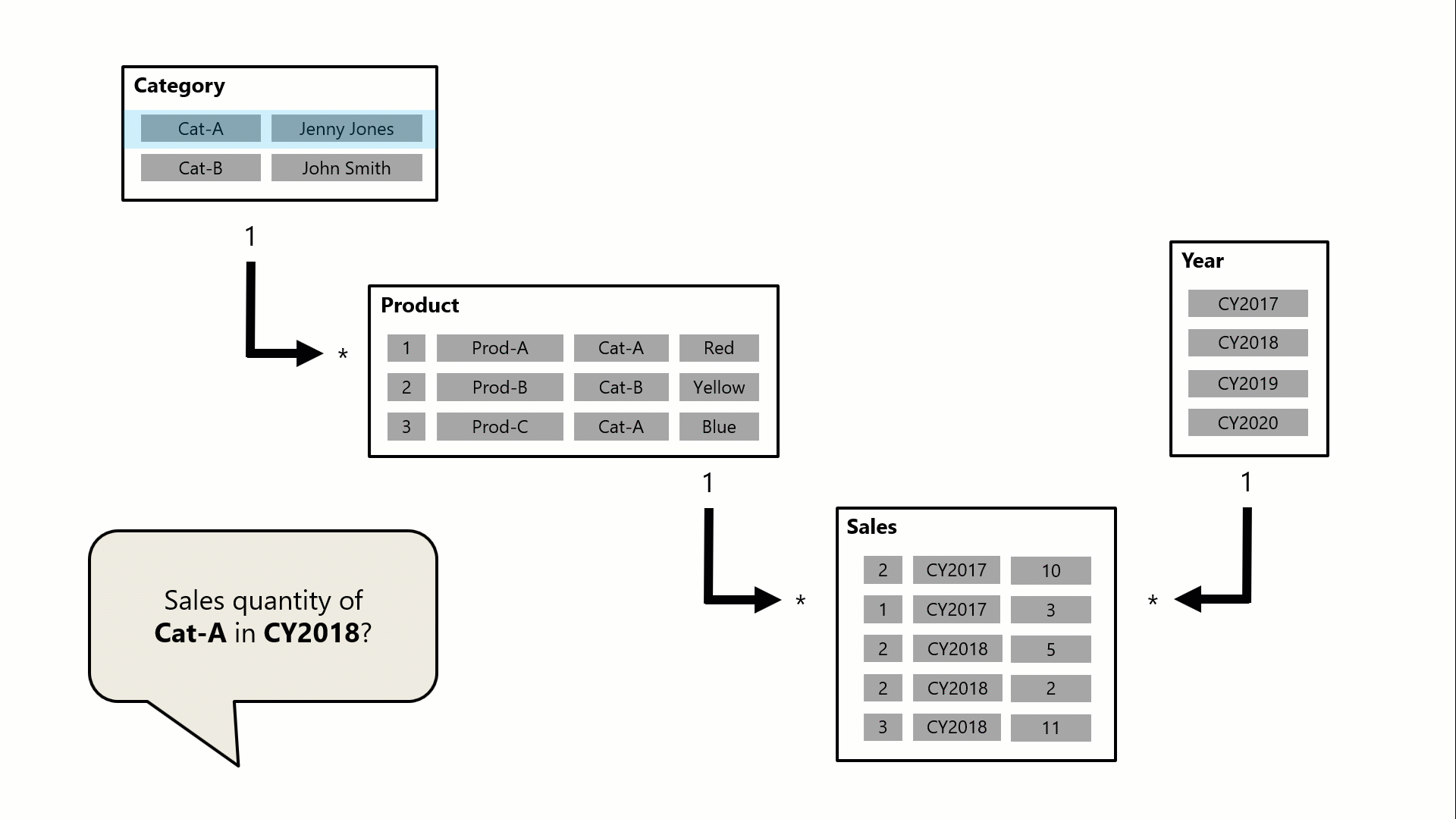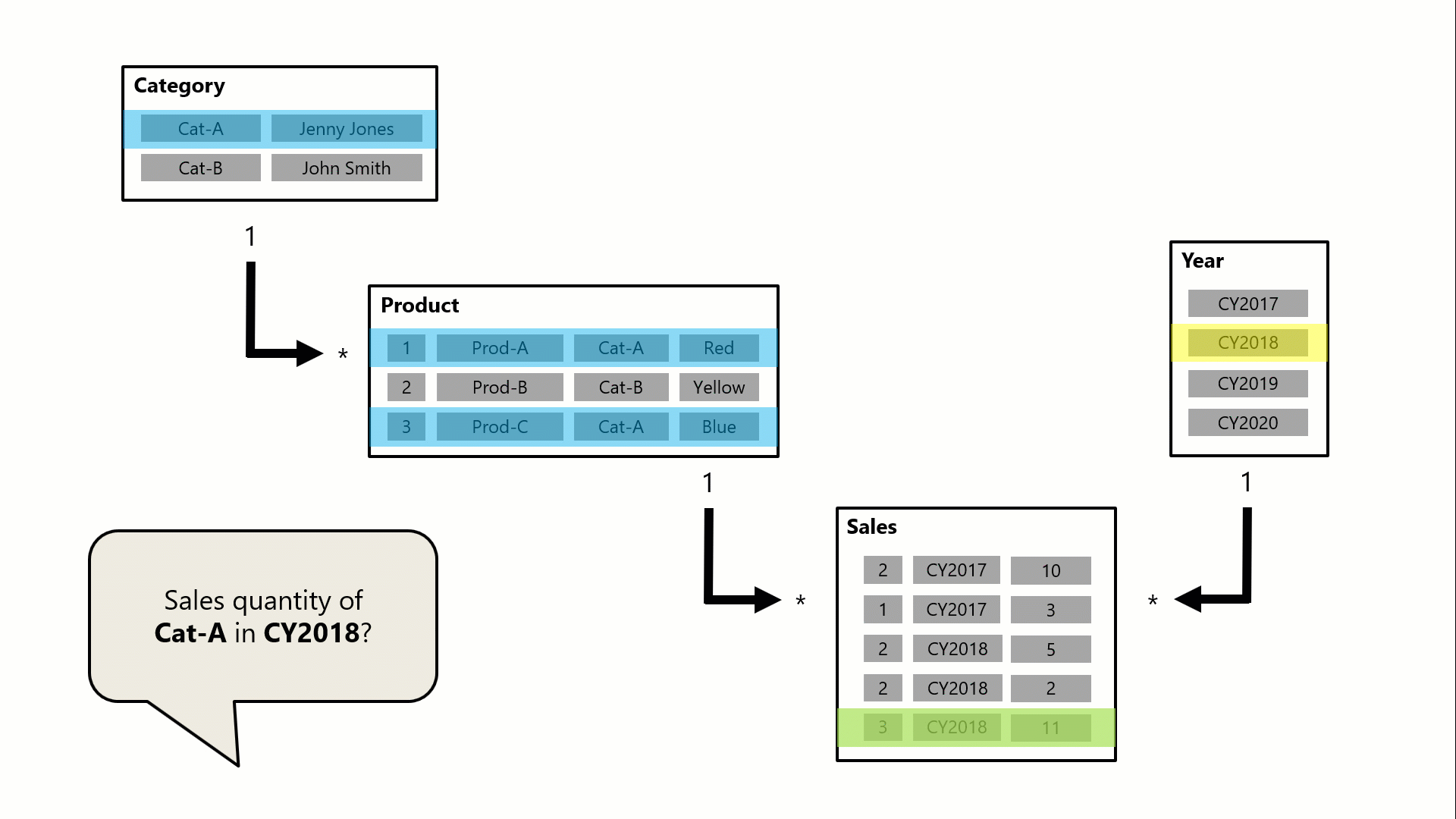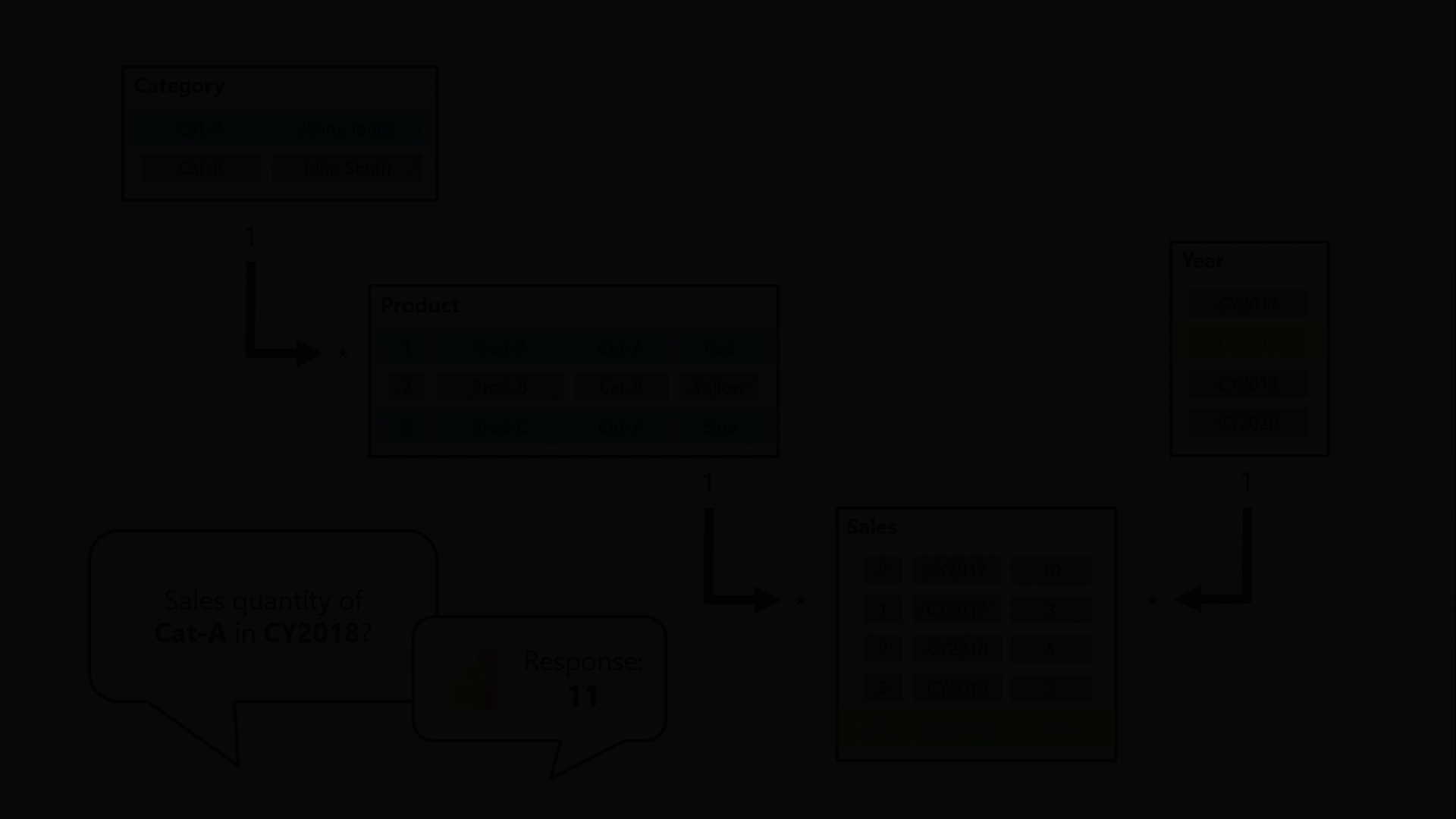
W tym przykładzie model składa się z czterech tabel: Category (Kategoria), Product (Produkt), Year (Rok) i Sales (Sprzedaż). Tabela Category odnosi się do tabeli Product , a tabela Product jest powiązana z tabelą Sales . Tabela Year odnosi się również do tabeli Sales . Wszystkie relacje to jeden do wielu (szczegóły opisane w dalszej części tego artykułu).
Zapytanie, prawdopodobnie wygenerowane przez wizualizację karty usługi Power BI, żąda łącznej ilości sprzedanych zamówień dla jednej kategorii, Cat-A, i dla jednego roku, CY2018. Dlatego można zobaczyć filtry zastosowane w tabelach Category i Year . Filtr w tabeli Category (Kategoria ) jest propagowany do tabeli Product (Produkt ), aby odizolować dwa produkty przypisane do kategorii Cat-A. Następnie filtry tabeli Product (Produkt ) są propagowane do tabeli Sales (Sprzedaż ), aby odizolować tylko dwa wiersze sprzedaży dla tych produktów. Te dwa wiersze sprzedaży reprezentują sprzedaż produktów przypisanych do kategorii Cat-A. Ich łączna ilość wynosi 14 jednostek. Jednocześnie filtr tabeli Year jest propagowany, aby dalej filtrować tabelę Sales, skutkując tylko jednym wierszem sprzedaży dla produktów przypisanych do kategorii Cat-A i zamówionych w roku CY2018. Wartość ilości zwrócona przez zapytanie to 11 jednostek. W przypadku zastosowania wielu filtrów do tabeli (na przykład tabeli Sales w tym przykładzie) zawsze jest to operacja AND, która wymaga, aby wszystkie warunki były spełnione.
Stosowanie zasad projektowania schematu gwiazdy
Zalecamy stosowanie zasad projektowania schematu gwiazdy w celu utworzenia modelu składającego się z tabel wymiarów i faktów. Typowe jest skonfigurowanie usługi Power BI do wymuszania reguł, które filtrują tabele wymiarów, co pozwala na efektywne rozprzestrzenianie tych filtrów na tabele faktów.
Na poniższej ilustracji przedstawiono diagram modelu danych analizy sprzedaży firmy Adventure Works. Przedstawia on projekt schematu gwiazdy składający się z pojedynczej tabeli faktów o nazwie Sales. Pozostałe cztery tabele to tabele wymiarów, które obsługują analizę miar sprzedaży według daty, stanu, regionu i produktu. Zwróć uwagę na relacje modelu łączące wszystkie tabele. Te relacje propagują filtry (bezpośrednio lub pośrednio) do tabeli Sales .
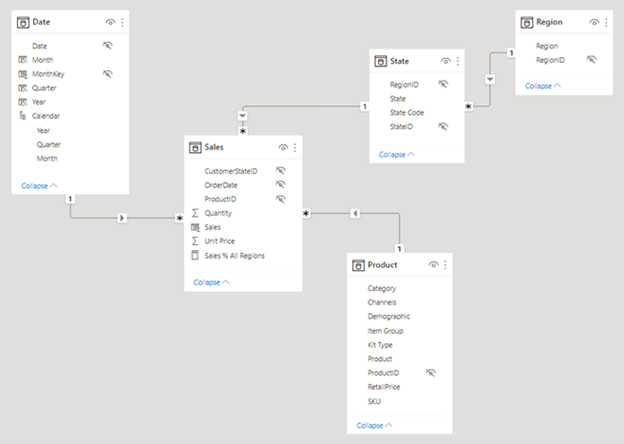
Rozłączone tabele
Nietypowe jest to, że tabela modelu nie jest powiązana z inną tabelą modelu. Taka tabela w prawidłowym projekcie modelu jest opisana jako rozłączona tabela. Odłączona tabela nie jest przeznaczona do propagowania filtrów do innych tabel modelu. Zamiast tego akceptuje "dane wejściowe użytkownika" (na przykład z wizualizacją fragmentatora), dzięki czemu obliczenia modelu mogą używać wartości wejściowej w znaczący sposób. Rozważmy na przykład rozłączonej tabeli załadowanej z zakresem wartości kursu wymiany waluty. Jeśli filtr jest stosowany do filtrowania według pojedynczej wartości stawki, wyrażenie miary może użyć tej wartości do konwersji wartości sprzedaży.
Parametr warunkowy programu Power BI Desktop jest funkcją, która tworzy rozłączone tabele. Aby uzyskać więcej informacji, zobacz Create and use a What if parameter to visualize variables in Power BI Desktop (Tworzenie i używanie parametru analizy warunkowej do wizualizacji zmiennych w programie Power BI Desktop).
Właściwości relacji
Relacja modelu wiąże jedną kolumnę w tabeli z jedną kolumną w innej tabeli. (Istnieje jeden specjalistyczny przypadek, gdzie to wymaganie nie jest spełnione i odnosi się tylko do wielokolumnowych relacji w modelach DirectQuery. Aby uzyskać więcej informacji, zobacz artykuł funkcji DAX COMBINEVALUES.)
Uwaga
Nie można powiązać kolumny z inną kolumną w tej samej tabeli. Ta koncepcja jest czasami mylona z możliwością definiowania ograniczeń klucza obcego relacyjnej bazy danych, które jest samodzielne odwoływanie się do tabeli. Tej koncepcji relacyjnej bazy danych można użyć do przechowywania relacji nadrzędny-podrzędny (na przykład każdy rekord pracownika jest powiązany z pracownikiem, do którego raportuje). Nie można jednak używać relacji modelu do generowania hierarchii modelu na podstawie tego typu relacji. Aby utworzyć hierarchię rodzic-dziecko, zobacz Funkcje nadrzędne i podrzędne.
Typy danych kolumn
Typ danych dla kolumn "from" i "to" relacji powinien być taki sam. Praca z relacjami zdefiniowanymi w kolumnach DateTime może nie zachowywać się zgodnie z oczekiwaniami. Silnik, który przechowuje dane usługi Power BI, używa tylko typów danych DateTime; Typy danych Data, Godzina i Data/Godzina/Strefa czasowa to konstrukcje formatowania usługi Power BI zaimplementowane w oparciu o nie. Wszelkie obiekty zależne od modelu będą nadal wyświetlane jako DateTime w aparacie (takie jak relacje, grupy itd.). W związku z tym, jeśli użytkownik wybierze Data na karcie Modelowanie dla takich kolumn, nadal nie są one rejestrowane jako ta sama data, ponieważ część czasu danych jest nadal uwzględniana przez silnik. Dowiedz się więcej na temat obsługi typów daty/godziny. Aby poprawić zachowanie, należy zaktualizować typy danych kolumn w Edytorze Power Query, aby usunąć część godzinową z zaimportowanych danych, tak aby podczas przetwarzania danych wartości były wyświetlane tak samo.
Kardynalność
Każda relacja modelu jest definiowana przez typ kardynalności. Istnieją cztery opcje typu kardynalności, reprezentujące cechy danych powiązanych kolumn "from" i "to". Strona "jeden" oznacza, że kolumna zawiera unikatowe wartości; strona "wiele" oznacza, że kolumna może zawierać zduplikowane wartości.
Uwaga
Jeśli operacja odświeżania danych próbuje załadować zduplikowane wartości do kolumny bocznej "jeden", całe odświeżanie danych zakończy się niepowodzeniem.
Cztery opcje, wraz z ich skróconymi notacjami, są opisane na poniższej liście:
- Jeden do wielu (1:*)
- Wiele do jednego (*:1)
- Jeden do jednego (1:1)
- Wiele do wielu (*:*)
Podczas tworzenia relacji w programie Power BI Desktop projektant automatycznie wykrywa i ustawia typ kardynalności. Program Power BI Desktop wysyła zapytanie do modelu, aby wiedzieć, które kolumny zawierają unikatowe wartości. W przypadku modeli importu używa ona statystyk magazynu wewnętrznego; w przypadku modeli DirectQuery wysyła zapytania profilowania do źródła danych. Czasami jednak program Power BI Desktop może się pomylić. Może to być błędne, gdy tabele nie zostały jeszcze załadowane z danymi lub ponieważ kolumny, których oczekujesz, że zawierają zduplikowane wartości, zawierają obecnie unikatowe wartości. W obu przypadkach można zaktualizować typ kardynalności, o ile jakiekolwiek kolumny po stronie "jeden" zawierają unikalne wartości (lub tabela nie została jeszcze załadowana wierszami danych).
Kardynalność jeden do wielu (i wiele do jednego)
Opcje kardynalności "jeden do wielu " i " wiele do jednego " są zasadniczo takie same i są również najczęstszymi typami kardynalności.
Podczas konfigurowania relacji jeden do wielu lub wiele do jednego wybierz relację zgodną z kolejnością, w której są powiązane kolumny. Zastanów się, jak skonfigurować relację z tabeli Product do tabeli Sales przy użyciu kolumny ProductID znajdującej się w każdej tabeli. Typ kardynalności to jeden do wielu, ponieważ kolumna ProductID w tabeli Product zawiera unikatowe wartości. Jeśli powiązałeś tabele w odwrotnym kierunku, Sales do Product, to kardynalność byłaby wiele do jednego.
Kardynalność jeden do jednego
Relacja jeden do jednego oznacza, że obie kolumny zawierają unikatowe wartości. Ten typ kardynalności nie jest wspólny i prawdopodobnie reprezentuje nieoptymalny projekt modelu ze względu na przechowywanie nadmiarowych danych.
Aby uzyskać więcej informacji na temat korzystania z tego typu kardynalności, zobacz Wskazówki dotyczące relacji jeden do jednego.
Kardynalność wiele-do-wielu
Relacja wiele do wielu oznacza, że obie kolumny mogą zawierać zduplikowane wartości. Ten typ kardynalności jest rzadko używany. Zwykle jest to przydatne podczas projektowania złożonych wymagań dotyczących modelu. Można go użyć, aby powiązać relacje wiele-do-wielu lub powiązać fakty o wyższym poziomie szczegółowości. Na przykład gdy fakty dotyczące sprzedaży są przechowywane na poziomie kategorii produktu, a tabela wymiarów produktu jest przechowywana na poziomie produktu.
Aby uzyskać wskazówki dotyczące korzystania z tego typu kardynalności, zobacz Wskazówki dotyczące relacji wiele-do-wielu.
Uwaga
Typ kardynalności wiele-do-wielu jest obsługiwany dla modeli opracowanych dla Power BI Report Server od stycznia 2024 r. i nowszych.
Wskazówka
W widoku modelu programu Power BI Desktop można interpretować typ kardynalności relacji, przeglądając wskaźniki (1 lub *) po obu stronach linii relacji. Aby określić, które kolumny są powiązane, zaznacz linię relacji lub najedź na nią kursorem, aby wyróżnić powiązane kolumny.
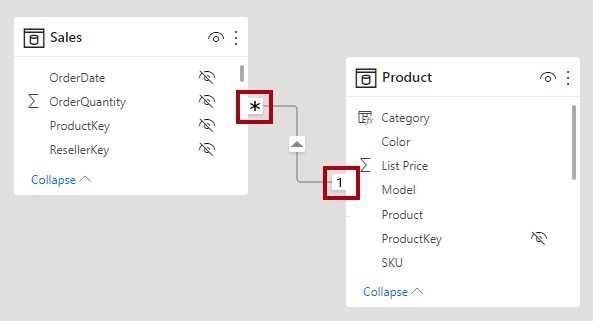
Kierunek filtrowania krzyżowego
Każda relacja modelu jest definiowana zgodnie z kierunkiem filtrowania krzyżowego. Ustawienie określa kierunki propagacji filtrów. Możliwe opcje filtrowania krzyżowego zależą od typu kardynalności.
| Typ kardynalności | Opcje filtrowania krzyżowego |
|---|---|
| Jeden do wielu (lub wiele do jednego) | Singiel Oboje |
| Jeden do jednego | Oboje |
| Wiele do wielu | Pojedynczy (Tabela1 do Tabela2) Pojedynczy (Tabela2 do Tabela1) Oboje |
Pojedynczy kierunek filtrowania krzyżowego oznacza "pojedynczy kierunek", a oba oznaczają "oba kierunki". Relacja, która filtruje w obu kierunkach, jest często opisywana jako dwukierunkowa.
W przypadku relacji jeden-do-wielu kierunek filtrowania krzyżowego jest zawsze ze strony "jeden" i opcjonalnie po stronie "wiele" (dwukierunkowy). W przypadku relacji jeden do jednego kierunek filtrowania krzyżowego jest zawsze z obu tabel. Na koniec w przypadku relacji wiele-do-wielu kierunek filtrowania krzyżowego może pochodzić z jednej z tabel lub z obu tabel. Zwróć uwagę, że gdy typ kardynalności zawiera stronę "jeden", filtry będą zawsze propagowane z tej strony.
Gdy kierunek filtrowania krzyżowego jest ustawiony na Oba, kolejna właściwość jest dostępna. Może ona stosować filtrowanie dwukierunkowe, gdy usługa Power BI wymusza reguły zabezpieczeń na poziomie wiersza. Aby uzyskać więcej informacji na temat zabezpieczeń na poziomie wiersza (RLS) w programie Power BI Desktop, zobacz Zabezpieczenia na poziomie wiersza (RLS) w Power BI Desktop.
Kierunek filtrowania krzyżowego relacji, w tym wyłączenie propagacji filtru, można zmodyfikować przy użyciu obliczeń modelu. To jest osiągane za pomocą funkcji DAX CROSSFILTER.
Należy pamiętać, że relacje dwukierunkowe mogą mieć negatywny wpływ na wydajność. Ponadto próba skonfigurowania relacji dwukierunkowej może spowodować niejednoznaczne ścieżki propagacji filtru. W takim przypadku program Power BI Desktop może nie zatwierdzić zmiany relacji i wyświetli alert z komunikatem o błędzie. Czasami jednak program Power BI Desktop może umożliwić definiowanie niejednoznacznych ścieżek relacji między tabelami. Rozwiązywanie niejednoznaczności ścieżki relacji opisano w dalszej części tego artykułu.
Zalecamy używanie filtrowania dwukierunkowego tylko w razie potrzeby. Aby uzyskać więcej informacji, zobacz Poradnik dotyczący dwukierunkowych relacji.
Wskazówka
W widoku modelu programu Power BI Desktop można interpretować kierunek filtrowania krzyżowego relacji, zauważając strzałki wzdłuż linii relacji. Pojedyncza strzałka reprezentuje filtr jednokierunkowy w kierunku grotu strzałki; podwójna strzałka reprezentuje relację dwukierunkową.
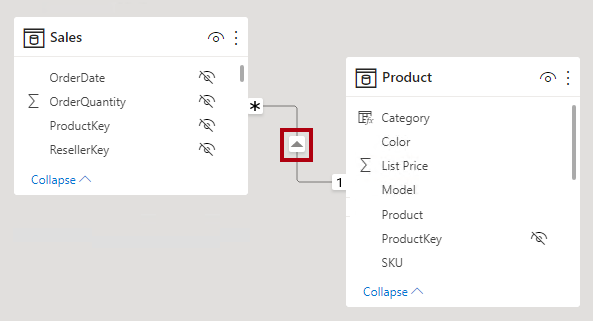
Aktywuj tę relację
Między dwiema tabelami modelu może istnieć tylko jedna aktywna ścieżka propagacji filtru. Można jednak wprowadzić dodatkowe ścieżki relacji, chociaż te relacje należy ustawić jako nieaktywne. Nieaktywne relacje mogą być aktywne tylko podczas obliczania modelu. Jest osiągana za pomocą funkcji DAX USERELATIONSHIP.
Ogólnie rzecz biorąc, zalecamy definiowanie aktywnych relacji zawsze wtedy, gdy jest to możliwe. Rozszerzają zakres i potencjał sposobu używania modelu przez autorów raportów. Używanie tylko aktywnych relacji oznacza, że tabele wymiarów odgrywających różne role powinny być zduplikowane w modelu.
W określonych okolicznościach można jednak zdefiniować jedną lub więcej nieaktywnych relacji dla tabeli wymiarów odgrywających rolę. Ten projekt można wziąć pod uwagę, gdy:
- Nie ma potrzeby jednoczesnego filtrowania wizualizacji raportów według różnych ról.
- Funkcji
USERELATIONSHIPjęzyka DAX używasz do aktywowania określonej relacji dla odpowiednich obliczeń modelu.
Aby uzyskać więcej informacji, zobacz Wskazówki dotyczące aktywnej i nieaktywnej relacji.
Wskazówka
W widoku modelu programu Power BI Desktop można interpretować stan aktywny i nieaktywny relacji. Linia ciągła reprezentuje aktywną relację, a linia przerywana reprezentuje nieaktywną relację.
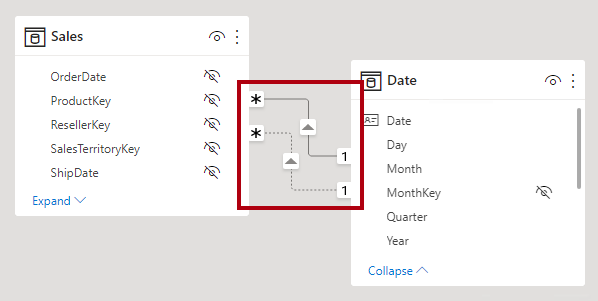
Przyjmij integralność referencyjną
Właściwość Przyjmij integralność referencyjną jest dostępna tylko dla relacji jeden do wielu i jeden do jednego między dwiema tabelami trybu przechowywania DirectQuery należącymi do tej samej grupy źródłowej. Tę właściwość można włączyć tylko wtedy, gdy kolumna po stronie "wiele" nie zawiera wartości NULL.
Po włączeniu natywne zapytania wysyłane do źródła danych łączą dwie tabele przy użyciu INNER JOIN zamiast OUTER JOIN. Ogólnie rzecz biorąc, włączenie tej właściwości zwiększa wydajność zapytań, chociaż zależy od specyfiki źródła danych.
Zawsze włączaj tę właściwość, gdy między dwiema tabelami istnieje ograniczenie klucza obcego bazy danych. Nawet jeśli ograniczenie klucza obcego nie istnieje, rozważ włączenie właściwości, o ile istnieje pewna integralność danych.
Ważne
Jeśli integralność danych powinna zostać naruszona, sprzężenie wewnętrzne eliminuje niedopasowane wiersze między tabelami. Rozważmy na przykład model tabeli Sales (Sprzedaż ) z wartością kolumny ProductID , która nie istnieje w powiązanej tabeli Product (Produkt ). Propagacja filtru z tabeli Product do tabeli Sales eliminuje wiersze sprzedaży dla nieznanych produktów, co powoduje niedopowiedzenie wyników sprzedaży.
Aby uzyskać więcej informacji, zobacz Przyjmij ustawienia integralności referencyjnej w programie Power BI Desktop.
Odpowiednie funkcje języka DAX
Istnieje kilka funkcji języka DAX, które są istotne dla relacji modelu. Każda funkcja jest krótko opisana na poniższej liście:
- POWIĄZANE: Pobiera wartość z "jednej" strony relacji. Jest to przydatne w przypadku angażowania obliczeń z różnych tabel, które są oceniane w kontekście wiersza.
- RELATEDTABLE: Pobieranie tabeli z wierszami z "wielu" strony relacji.
- USERELATIONSHIP: umożliwia obliczeniu użycie nieaktywnej relacji. (Technicznie ta funkcja modyfikuje wagę określonej nieaktywnej relacji modelu, pomagając wpłynąć na jej użycie). Jest to przydatne, gdy model zawiera tabelę wymiarów odgrywających rolę i wybierasz tworzenie nieaktywnych relacji z tej tabeli. Możesz również użyć tej funkcji, aby rozwiązać niejednoznaczność w ścieżkach filtru.
- CROSSFILTER: Modyfikuje kierunek filtrowania krzyżowego relacji (do jednego lub obu) lub wyłącza propagację filtru (brak). Jest to przydatne, gdy trzeba zmienić lub zignorować relacje modelu podczas oceny określonego obliczenia.
- COMBINEVALUES: łączy co najmniej dwa ciągi tekstowe w jeden ciąg tekstowy. Celem tej funkcji jest obsługa relacji wielokolumnowych w modelach DirectQuery, gdy tabele należą do tej samej grupy źródłowej.
- TREATAS: stosuje wynik wyrażenia tabeli jako filtry do kolumn z niepowiązanej tabeli. Jest to przydatne w zaawansowanych scenariuszach, gdy chcesz utworzyć relację wirtualną podczas oceny określonego obliczenia.
- Funkcje nadrzędne i podrzędne: rodzina powiązanych funkcji, których można użyć do generowania kolumn obliczeniowych w celu naturalizacji hierarchii nadrzędny-podrzędny. Następnie możesz użyć tych kolumn, aby utworzyć hierarchię na stałym poziomie.
Ocena relacji
Relacje modelu z perspektywy oceny są klasyfikowane jako zwykłe lub ograniczone. Nie jest to konfigurowalna właściwość relacji. W rzeczywistości jest on wywnioskowany z typu kardynalności i źródła danych dwóch powiązanych tabel. Ważne jest, aby zrozumieć typ oceny, ponieważ może to mieć wpływ na wydajność lub konsekwencje, jeśli integralność danych zostanie naruszona. Te konsekwencje i konsekwencje integralności opisano w tej sekcji.
Najpierw wymagana jest pewna teoria modelowania, aby w pełni zrozumieć oceny relacji.
Model importu lub DirectQuery pobiera wszystkie dane z pamięci podręcznej Vertipaq lub z bazowej bazy danych. W obu przypadkach usługa Power BI może określić, że istnieje "jedna" strona relacji.
Jednak model złożony może składać się z tabel przy użyciu różnych trybów przechowywania (import, DirectQuery lub podwójny) lub wielu źródeł DirectQuery. Każde źródło, w tym pamięć podręczna Vertipaq zaimportowanych danych, jest uważane za grupę źródłową. Relacje modelu można następnie klasyfikować jako wewnątrz grupy źródłowej lub między/między grupami źródłowymi. Relacja wewnątrz grupy źródłowej wiąże dwie tabele w grupie źródłowej, podczas gdy relacja między/między grupami źródłowymi wiąże tabele między dwiema grupami źródłowymi. Należy pamiętać, że relacje w modelach importu lub DirectQuery są zawsze wewnątrz grupy źródłowej.
Oto przykład modelu złożonego.
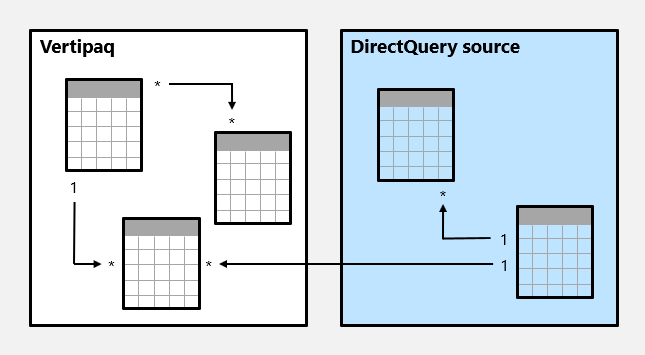
W tym przykładzie model złożony składa się z dwóch grup źródłowych: grupy źródłowej Vertipaq i grupy źródłowej DirectQuery. Grupa źródłowa Vertipaq zawiera trzy tabele, a grupa źródłowa DirectQuery zawiera dwie tabele. Istnieje jedna relacja między grupami źródłowymi, aby powiązać tabelę w grupie źródłowej Vertipaq z tabelą w grupie źródłowej DirectQuery.
Zwykłe relacje
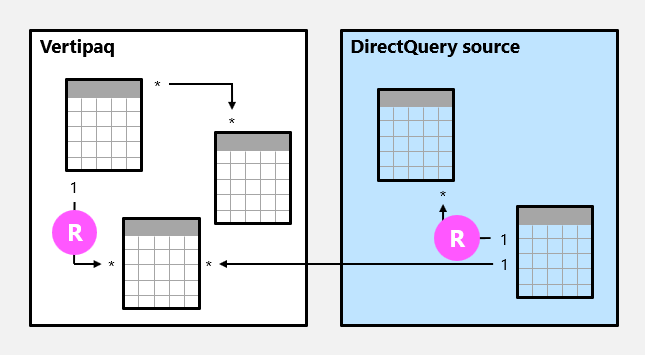
Relacja modelu jest regularna , gdy aparat zapytań może określić "jedną" stronę relacji. Posiadamy potwierdzenie, że kolumna po stronie "jeden" zawiera unikatowe wartości. Wszystkie relacje "jeden do wielu" wewnątrz grupy źródłowej są zwykłymi relacjami.
W poniższym przykładzie istnieją dwie zwykłe relacje, które są oznaczone jako R. Relacje obejmują relację jeden do wielu zawartą w grupie źródłowej Vertipaq i relację jeden do wielu zawartą w źródle zapytania bezpośredniego.
W przypadku modeli importu, w których wszystkie dane są przechowywane w pamięci podręcznej Vertipaq, usługa Power BI tworzy strukturę danych dla każdej regularnej relacji w czasie odświeżania danych. Struktury danych składają się z indeksowanych mapowań wszystkich wartości typu kolumna-kolumna, a ich celem jest przyspieszenie łączenia tabel w czasie wykonywania zapytań.
W czasie wykonywania zapytania regularne relacje umożliwiają rozszerzanie tabeli . Rozszerzenie tabeli powoduje utworzenie tabeli wirtualnej przez uwzględnienie natywnych kolumn tabeli bazowej, a następnie rozwinięcie do powiązanych tabel. W przypadku tabel importowanych rozszerzenie tabeli odbywa się w aparacie zapytań; w przypadku tabel DirectQuery jest ono wykonywane w zapytaniu natywnym wysyłanym do źródłowej bazy danych (o ile właściwość Załóż integralność referencyjną nie jest włączona). Następnie aparat zapytań działa na rozwiniętej tabeli, stosując filtry i grupując według wartości w rozwiniętych kolumnach tabeli.
Uwaga
Nieaktywne relacje są również rozszerzane, nawet jeśli relacja nie jest używana w obliczeniach. Relacje dwukierunkowe nie mają wpływu na rozszerzanie tabeli.
W przypadku relacji jeden do wielu rozszerzenie tabeli odbywa się od "wielu" do "jeden" stron przy użyciu semantyki LEFT OUTER JOIN. Gdy nie istnieje zgodna wartość z "wielu" do strony "jeden", do tabeli bocznej "jeden" zostanie dodany pusty wiersz wirtualny. To zachowanie dotyczy tylko zwykłych relacji, a nie ograniczonych relacji.
Rozszerzanie tabeli występuje również w przypadku relacji "jeden do jednego" w ramach grupy źródłowej, ale przy wykorzystaniu semantyki FULL OUTER JOIN. Ten typ łączenia gwarantuje, że puste wiersze wirtualne są dodawane po obu stronach, w razie potrzeby.
Puste wiersze wirtualne to w istocie nieznani członkowie. Nieznani członkowie reprezentują naruszenia spójności referencyjnej, w których wartość po stronie "wiele" nie ma odpowiadającej wartości po stronie "jeden". W idealnym przypadku te puste elementy nie powinny istnieć. Można je wyeliminować przez czyszczenie lub naprawianie danych źródłowych.
Oto jak rozszerzenie tabeli działa z animowanym przykładem.

W tym przykładzie model składa się z trzech tabel: Category ( Kategoria), Product (Produkt) i Sales (Sprzedaż). Tabela Category odnosi się do tabeli Product z relacją Jeden do wielu, a tabela Product jest powiązana z tabelą Sales z relacją Jeden do wielu. Tabela Category zawiera dwa wiersze, tabela Product zawiera trzy wiersze, a tabele Sales zawierają pięć wierszy. Po obu stronach wszystkich relacji istnieją zgodne wartości, co oznacza, że nie ma żadnych naruszeń integralności referencyjnej. Ujawniono tabelę rozszerzaną podczas wyszukiwania. Tabela składa się z kolumn ze wszystkich trzech tabel. Jest to faktycznie zdenormalizowana perspektywa danych zawartych w trzech tabelach. Nowy wiersz jest dodawany do tabeli Sales i ma wartość identyfikatora produkcji (9), która nie ma pasującej wartości w tabeli Product . Jest to naruszenie integralności referencyjnej. W rozwiniętej tabeli nowy wiersz ma wartości (Blank) dla kolumn tabeli Kategoria i Produkt.
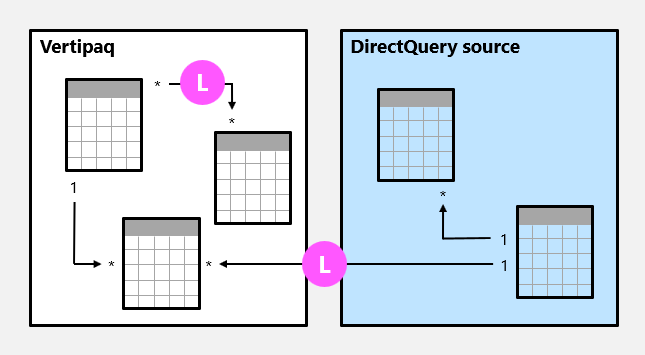
Ograniczone relacje
Relacja modelu jest ograniczona, gdy nie ma gwarantowanej "jednej" strony. Ograniczona relacja może wystąpić z dwóch powodów:
- Relacja wykorzystuje typ kardynalności wiele-do-wielu (nawet jeśli jedna lub obie kolumny zawierają unikatowe wartości).
- Relacja jest między grupami źródeł (co jest możliwe tylko w przypadku modeli złożonych).
W poniższym przykładzie istnieją dwie ograniczone relacje, które są oznaczone jako L. Te dwie relacje obejmują relację wiele-do-wielu zawartą w grupie źródłowej Vertipaq oraz relację jeden do wielu między grupami źródłowymi.
W przypadku modeli importu struktury danych nigdy nie są tworzone dla ograniczonych relacji. W takim przypadku usługa Power BI rozwiązuje sprzężenia tabeli w czasie wykonywania zapytania.
Rozszerzanie tabeli nigdy nie występuje w przypadku relacji o ograniczonym zasięgu. Sprzężenia tabel są osiągane przy użyciu INNER JOIN semantyki, a z tego powodu puste wiersze wirtualne nie są dodawane w celu zrekompensowania naruszeń integralności referencyjnej.
Istnieją inne ograniczenia związane z ograniczonymi relacjami:
- Nie można użyć funkcji DAX do pobrania wartości z kolumny po stronie "jeden".
- Wymuszanie RLS ma ograniczenia topologii.
Wskazówka
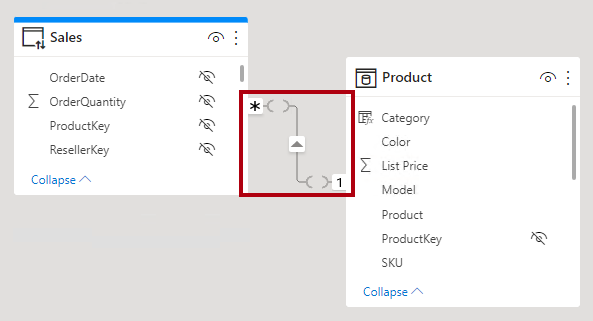
W widoku modelu programu Power BI Desktop można interpretować relację jako ograniczoną. Ograniczona relacja jest reprezentowana ze znakami przypominającymi nawiasy ( ) po wskaźnikach kardynalności.
Rozwiązywanie niejednoznaczności ścieżki relacji
Relacje dwukierunkowe mogą wprowadzać liczne, a co za tym idzie, niejednoznaczne ścieżki propagacji filtrów między tabelami modelu. Podczas oceny niejednoznaczności usługa Power BI wybiera ścieżkę propagacji filtru zgodnie z priorytetem i wagą.
Priorytet
Warstwy priorytetowe definiują sekwencję reguł używanych przez usługę Power BI do rozpoznawania niejednoznaczności ścieżki relacji. Pierwsze dopasowanie reguły określa ścieżkę, którą będzie podążać usługa Power BI. W poniższej sekwencji każda reguła opisuje, jak filtry przepływają z tabeli źródłowej do tabeli docelowej.
- Ścieżka składająca się z relacji jeden do wielu.
- Ścieżka składająca się z relacji jeden do wielu lub wiele do wielu.
- Ścieżka składająca się z relacji wiele-do-jednego.
- Ścieżka składająca się z relacji jeden do wielu z tabeli źródłowej do tabeli pośredniej, a następnie z relacji wiele do jednego z tabeli pośredniej do tabeli docelowej.
- Ścieżka składająca się z relacji jeden do wielu lub wiele-do-wielu, prowadzących z tabeli źródłowej do tabeli pośredniej, po czym następuje relacja wiele-do-jednego lub wiele-do-wielu z tabeli pośredniej do tabeli docelowej.
- Dowolna inna ścieżka.
Gdy relacja jest uwzględniona we wszystkich dostępnych ścieżkach, zostanie wykluczona z rozważania we wszystkich ścieżkach.
Ciężar
Każda relacja w ścieżce ma wagę. Domyślnie każda waga relacji jest równa, chyba że jest używana funkcja USERELATIONSHIP . Waga ścieżki jest maksymalną wartością spośród wszystkich wag relacji wzdłuż ścieżki. Usługa Power BI używa wag ścieżek do rozwiązywania niejednoznaczności między wieloma ścieżkami w tej samej warstwie priorytetu. Nie wybierze ścieżki o niższym priorytcie, ale wybierze ścieżkę o większej wadze. Liczba relacji w ścieżce nie ma wpływu na wagę.
Możesz wpływać na wagę relacji przy użyciu funkcji USERELATIONSHIP . Waga jest określana przez poziom zagnieżdżenia wywołania do tej funkcji, gdzie najbardziej wewnętrzne wywołanie otrzymuje najwyższą wagę.
Rozważmy poniższy przykład. Miara Product Sales przypisuje większą wagę relacji między Sales[ProductID] i Product[ProductID], a następnie między Inventory[ProductID] a Product[ProductID].
Product Sales =
CALCULATE(
CALCULATE(
SUM(Sales[SalesAmount]),
USERELATIONSHIP(Sales[ProductID], Product[ProductID])
),
USERELATIONSHIP(Inventory[ProductID], Product[ProductID])
)
Uwaga
Jeśli usługa Power BI wykryje wiele ścieżek, które mają ten sam priorytet i tę samą wagę, zwraca niejednoznaczny błąd ścieżki. W takim przypadku należy rozwiązać niejednoznaczność, wpływając na wagi relacji przy użyciu funkcji USERELATIONSHIP lub usuwając lub modyfikując relacje modelu.
Preferencje dotyczące wydajności
Poniższa lista porządkuje wydajność propagacji filtrów, zaczynając od najszybszej do najwolniejszej.
- Relacje "jeden do wielu" wewnątrz grupy źródłowej
- Relacje modelu wiele-do-wielu osiągnięte za pomocą tabeli pośredniej, które obejmują co najmniej jedną relację dwukierunkową
- Relacje kardynalności wielu do wielu
- Relacje między grupami źródłowymi
Powiązana zawartość
Aby uzyskać więcej informacji na temat tego artykułu, zapoznaj się z następującymi zasobami:
- Zrozumienie schematu gwiazdy i jego znaczenia dla Power BI
- Wskazówki dotyczące relacji jeden do jednego
- Wskazówki dotyczące tworzenia relacji wiele do wielu
- Wskazówki dotyczące aktywnej i nieaktywnej relacji
- Wskazówki dotyczące relacji dwukierunkowych
- wskazówki dotyczące rozwiązywania problemów z relacjami
- Wideo: Co robić i czego unikać w relacjach Power BI
- Masz pytania? Spróbuj zapytać społeczność Power BI
- Sugestie? Współtworzenie pomysłów na ulepszanie usługi Power BI