Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Wskazówka
Usługa Power BI Dataflow Gen1 znajduje się teraz w stanie przestarzałym i nie będzie otrzymywać nowych inwestycji w rozwój funkcji. Dla klientów w warstwie Premium z dostępem do Fabric zalecany jest przepływ danych Gen2, oferujący ulepszenia w zakresie wydajności, skalowania, niezawodności, funkcjonalności oraz wbudowanej sztucznej inteligencji. Klienci Pro/PPU mogą nadal korzystać z usługi Gen1, ponieważ wytyczne dotyczące tych scenariuszy dla Gen2 ewoluują. Aby uzyskać wskazówki dotyczące uaktualniania, zobacz Upgrade from Dataflow Gen1 to Dataflow Gen2 (Uaktualnianie z usługi Dataflow Gen1 do usługi Dataflow Gen2 ).
Projektowanie modelu wymiarowego jest jednym z najczęstszych zadań, które można wykonać za pomocą przepływu danych. W tym artykule przedstawiono niektóre z najlepszych rozwiązań dotyczących tworzenia modelu wymiarowego przy użyciu przepływu danych.
Przejściowe przepływy danych
Jednym z kluczowych punktów w dowolnym systemie integracji danych jest zmniejszenie liczby odczytów ze źródłowego systemu operacyjnego. W tradycyjnej architekturze integracji danych ta redukcja jest wykonywana przez utworzenie nowej bazy danych o nazwie przejściowej bazy danych. Celem przejściowej bazy danych jest załadowanie danych as-is ze źródła danych do przejściowej bazy danych zgodnie z regularnym harmonogramem.
Pozostała część integracji danych używa przejściowej bazy danych jako źródła do dalszej transformacji i konwertuje ją na strukturę modelu wymiarowego.
Zalecamy stosowanie tego samego podejścia przy użyciu przepływów danych. Utwórz zestaw przepływów danych odpowiedzialnych za ładowanie danych as-is z systemu źródłowego (i tylko dla potrzebnych tabel). Wynik jest następnie przechowywany w strukturze przechowywania przepływu danych (Azure Data Lake Storage lub Dataverse). Ta zmiana gwarantuje, że operacja odczytu z systemu źródłowego jest minimalna.
Następnie możesz utworzyć inne przepływy danych, które pobierają dane z przejściowych przepływów danych. Zalety tego podejścia obejmują:
- Zmniejszenie liczby operacji odczytu z systemu źródłowego i zmniejszenie obciążenia systemu źródłowego w rezultacie.
- Zmniejszenie obciążenia bram danych, jeśli jest używane lokalne źródło danych.
- Posiadanie pośredniej kopii danych na potrzeby uzgodnień w przypadku zmiany danych systemu źródłowego.
- Tworzenie przepływów danych transformacji niezależnych od źródła.
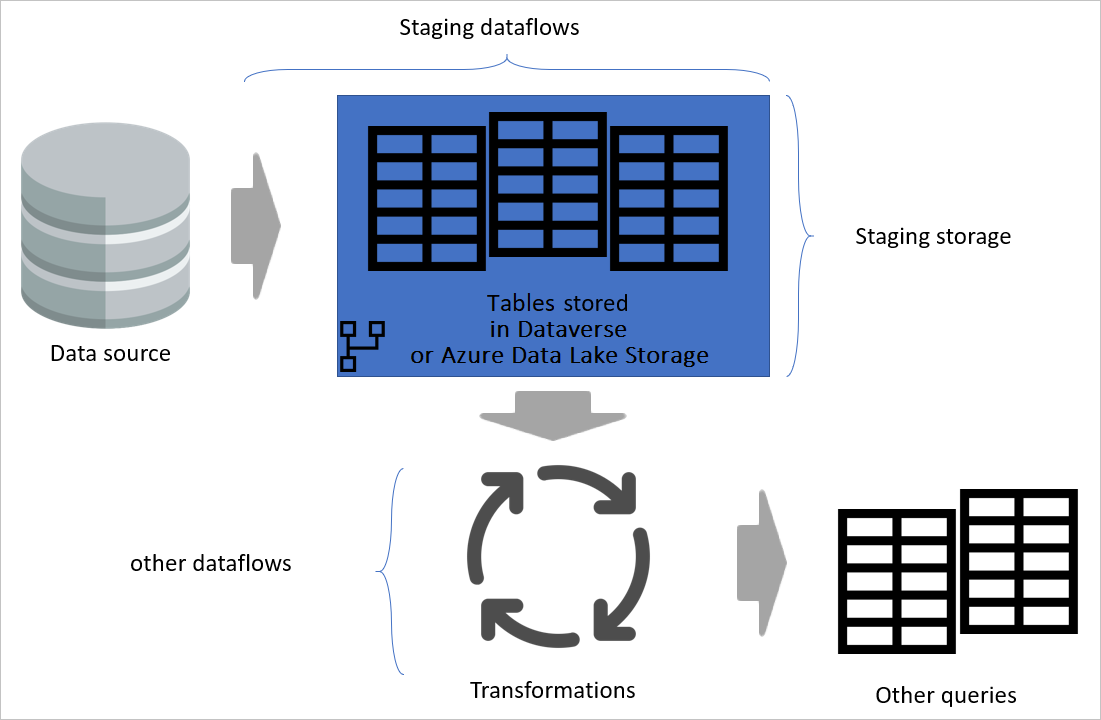
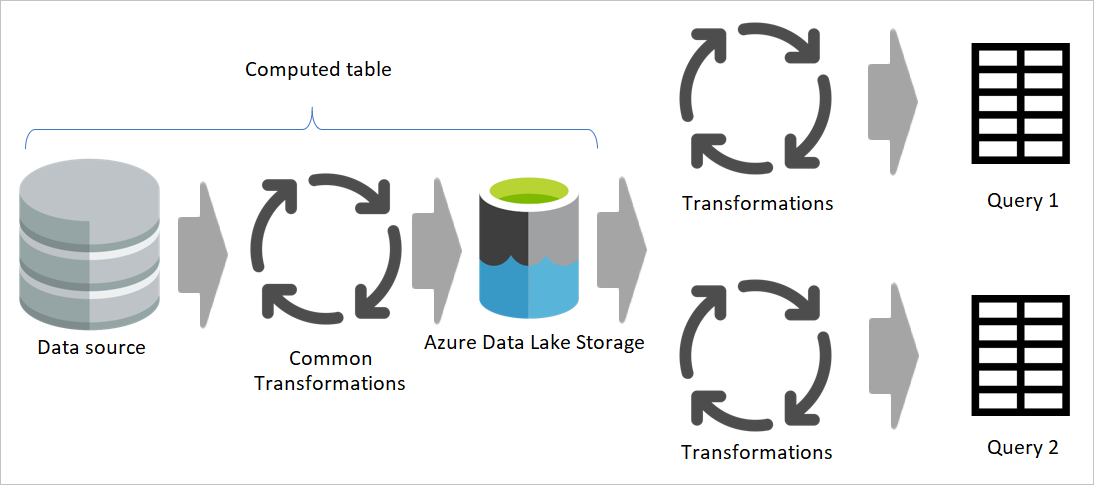
Diagram przedstawiający przejściowe przepływy danych i magazyn przejściowy. Na diagramie przedstawiono dane, do których uzyskuje się dostęp ze źródła danych przez przejściowy przepływ danych, a tabele są przechowywane w usługach Cadavers lub Azure Data Lake Storage. Następnie tabele są pokazywane, jak są przekształcane wraz z innymi przepływami danych, które następnie są wysyłane jako zapytania.
Przekształcanie przepływów danych
W przypadku oddzielenia przepływów danych transformacji od przejściowych przepływów danych transformacja jest niezależna od źródła. Ta separacja pomaga w przypadku migrowania systemu źródłowego do nowego systemu. W takim przypadku wystarczy zmienić przejściowe przepływy danych. Przepływy danych przekształcania mogą działać bez żadnego problemu, ponieważ pochodzą tylko z przejściowych przepływów danych.
Ta separacja pomaga również w przypadku, gdy połączenie z systemem źródłowym działa wolno. Przepływ danych transformacji nie musi czekać na długo, aby uzyskać rekordy przechodzące przez powolne połączenie z systemu źródłowego. Przepływ danych przejściowych już wykonał tę część zadania, i dane są gotowe do przekształceń.
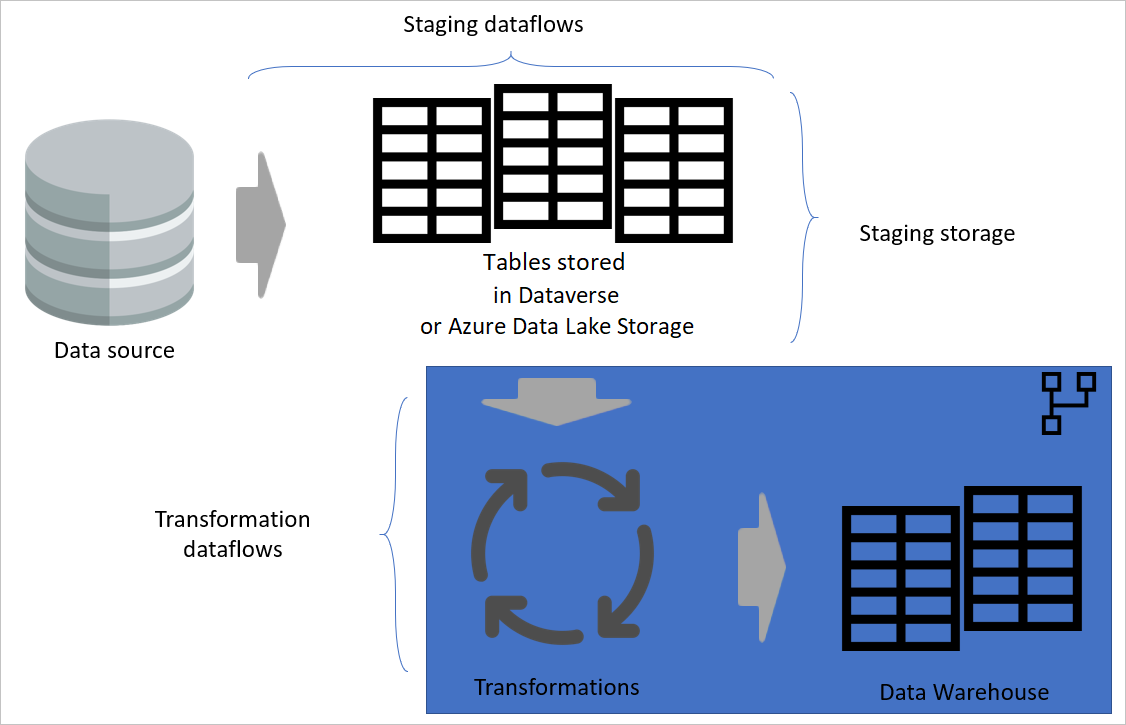
Architektura warstwowa
Architektura warstwowa to architektura, w której wykonujesz akcje w oddzielnych warstwach. Przepływy danych staging i przekształcania mogą być dwiema warstwami wielowarstwowej architektury przepływów danych. Wykonywanie działań w warstwach zapewnia minimalną wymaganą konserwację. Jeśli chcesz coś zmienić, wystarczy zmienić ją w warstwie, w której się znajduje. Pozostałe warstwy powinny nadal działać prawidłowo.
Na poniższej ilustracji przedstawiono wielowarstwową architekturę dla przepływów danych, w których ich tabele są następnie używane w modelach semantycznych usługi Power BI.
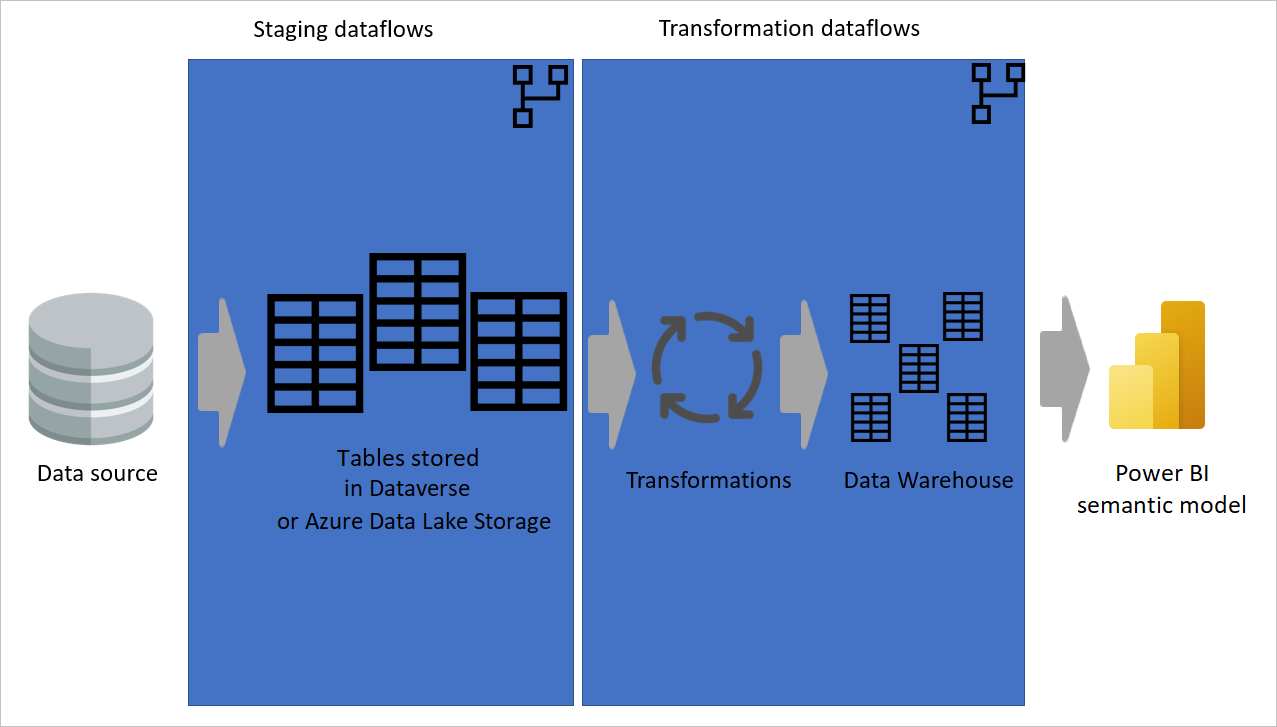
Jak najwięcej użyj obliczonej tabeli
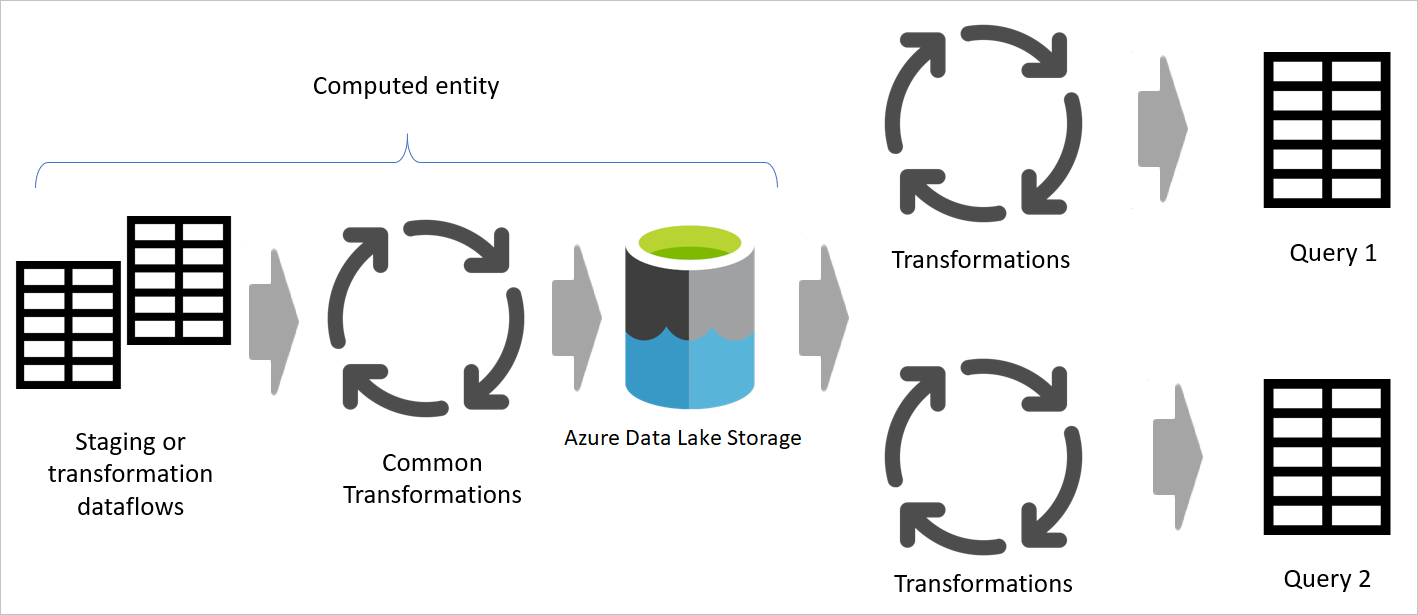
Gdy używasz wyniku przepływu danych w innym przepływie danych, używasz koncepcji obliczonej tabeli, co oznacza pobieranie danych z tabeli "już przetworzonej i przechowywanej". To samo może się zdarzyć wewnątrz przepływu danych. Jeśli odwołujesz się do tabeli z innej tabeli, możesz użyć obliczonej tabeli. Ta metoda jest przydatna, gdy masz zestaw przekształceń, które należy wykonać w wielu tabelach, które są nazywane typowymi przekształceniami.
Na poprzedniej ilustracji obliczona tabela pobiera dane bezpośrednio ze źródła. Jednak w architekturze przepływów danych dotyczących warstwy pośredniej i przekształceń prawdopodobnie obliczone tabele pochodzą z przepływów danych dotyczących warstwy pośredniej.
Zbuduj schemat gwiazdy
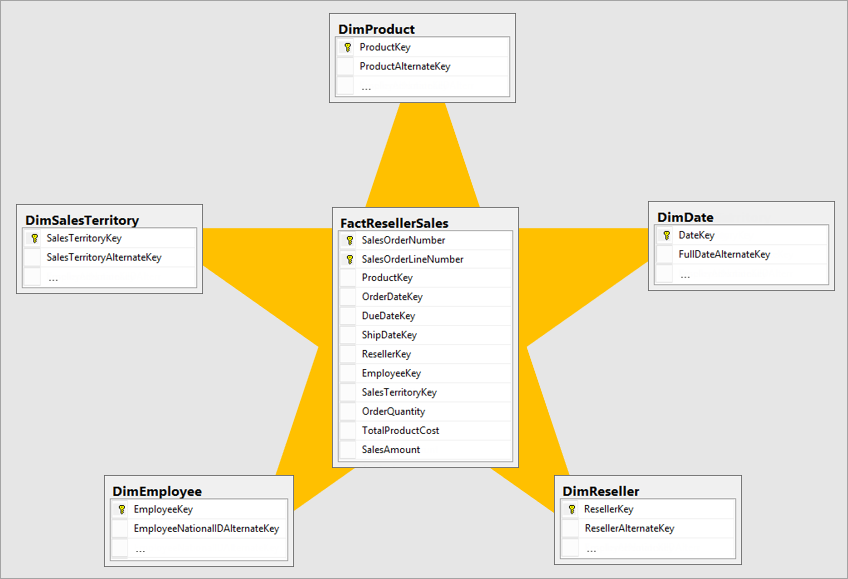
Najlepszy model wymiarowy to model schematu gwiazdy, który ma wymiary i tabele faktów zaprojektowane w celu zminimalizowania czasu wykonywania zapytań dotyczących danych z modelu. Model schematu gwiazdy ułatwia również zrozumienie wizualizatora danych.
Nie jest idealne, aby przenosić dane w tym samym układzie systemu operacyjnego do systemu BI. Tabele danych powinny zostać przemodelowane. Niektóre tabele powinny mieć postać tabeli wymiarów, która przechowuje informacje opisowe. Niektóre tabele powinny mieć formę tabeli faktów, aby umożliwić agregację danych. Najlepszym układem do utworzenia tabel faktów i tabel wymiarów jest schemat gwiazdy. Aby uzyskać więcej informacji, przejdź do Zrozum schemat gwiazdy i jego znaczenie dla Power BI.
Używanie unikatowej wartości klucza dla wymiarów
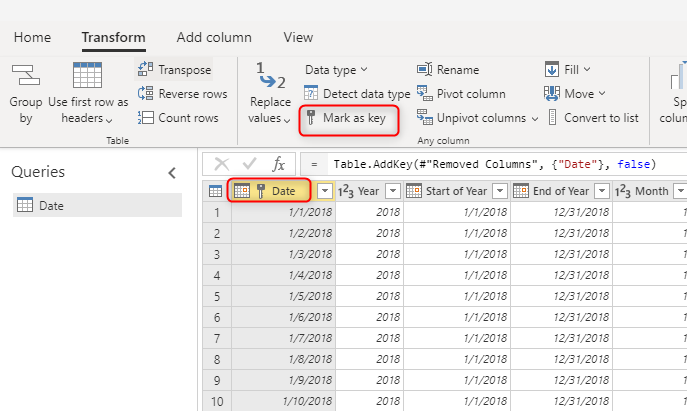
Podczas tworzenia tabel wymiarów upewnij się, że masz klucz dla każdego z nich. Ten klucz gwarantuje, że między wymiarami nie ma relacji wiele-do-wielu (lub innymi słowy"słabych"). Klucz można utworzyć, stosując pewne przekształcenia, aby upewnić się, że kolumna lub kombinacja kolumn zwraca unikatowe wiersze w wymiarze. Następnie kombinacja kolumn może być oznaczona jako klucz w tabeli w przepływie danych.
Wykonaj odświeżanie przyrostowe dla dużych tabel faktów
Tabele faktów są zawsze największymi tabelami w modelu wymiarowym. Zalecamy zmniejszenie liczby wierszy przesyłanych dla tych tabel. Jeśli masz bardzo dużą tabelę faktów, upewnij się, że używasz odświeżania przyrostowego dla tej tabeli. Odświeżanie przyrostowe można wykonać w modelu semantycznym usługi Power BI, a także w tabelach przepływu danych.
Odświeżanie przyrostowe służy do odświeżania tylko części danych, czyli części, która uległa zmianie. Istnieje wiele opcji wyboru, która część danych ma być odświeżona i która część ma być utrwalone. Aby uzyskać więcej informacji, zobacz Używanie odświeżania przyrostowego za pomocą przepływów danych usługi Power BI.

Odwoływanie się do tworzenia tabel wymiarów i tabel faktów
W systemie źródłowym często jest używana tabela służąca do generowania tabel faktów i wymiarów w magazynie danych. Te tabele są dobrymi kandydatami do tabel obliczeniowych, a także pośrednich przepływów danych. Wspólna część procesu — taka jak czyszczenie danych i usuwanie dodatkowych wierszy i kolumn — można wykonać raz. Wykorzystując odniesienie z wyników tych działań, można utworzyć tabele wymiarów i faktów. To podejście używa obliczonej tabeli dla typowych przekształceń.