Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Jedną z najlepszych rozwiązań dotyczących implementacji przepływu danych jest rozdzielenie obowiązków przepływów danych na dwie warstwy: pozyskiwanie danych i przekształcanie danych. Ten wzorzec jest szczególnie przydatny w przypadku obsługi wielu zapytań wolniejszych źródeł danych w jednym przepływie danych lub wielu przepływów danych, które wysyłają zapytania o te same źródła danych. Zamiast ponownie uzyskiwać dane z powolnego źródła danych dla każdego zapytania, proces pozyskiwania danych można wykonać raz, a przekształcenie można wykonać na podstawie tego procesu. W tym artykule wyjaśniono proces.
Lokalne źródło danych
W wielu scenariuszach lokalne źródło danych jest powolnym źródłem danych. Szczególnie biorąc pod uwagę, że brama istnieje jako warstwa środkowa między przepływem danych a źródłem danych.
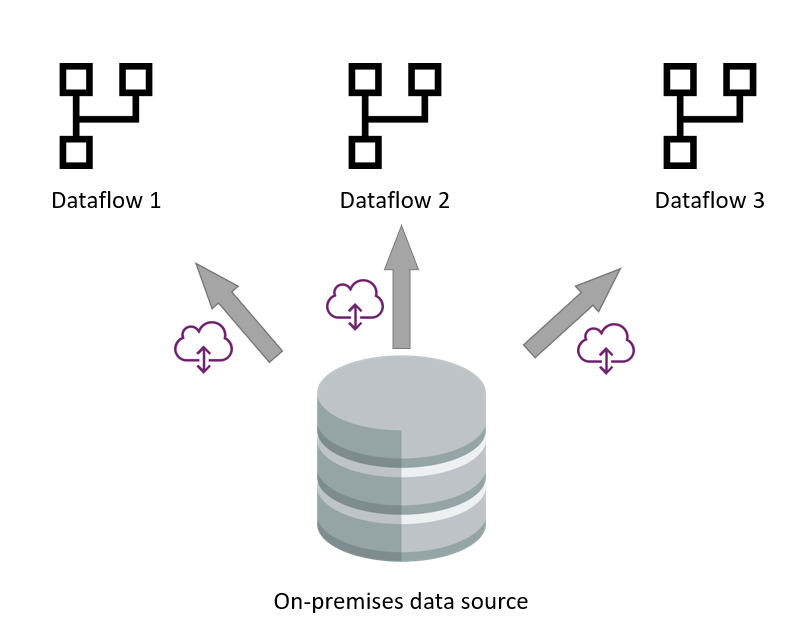
Korzystanie z analitycznych przepływów danych na potrzeby pozyskiwania danych minimalizuje proces pobierania danych ze źródła i koncentruje się na ładowaniu danych do usługi Azure Data Lake Storage. Po zapisaniu w magazynie można utworzyć inne przepływy danych, które korzystają z danych wyjściowych przepływu danych pozyskiwania. Silnik przepływu danych może odczytywać dane i wykonywać przekształcenia bezpośrednio z Data Lake, bez kontaktu z oryginalnym źródłem danych lub bramą.
Powolne źródło danych
Ten sam proces jest prawidłowy, gdy źródło danych działa wolno. Niektóre źródła danych oprogramowania jako usługi (SaaS) działają powoli ze względu na ograniczenia wywołań interfejsu API.
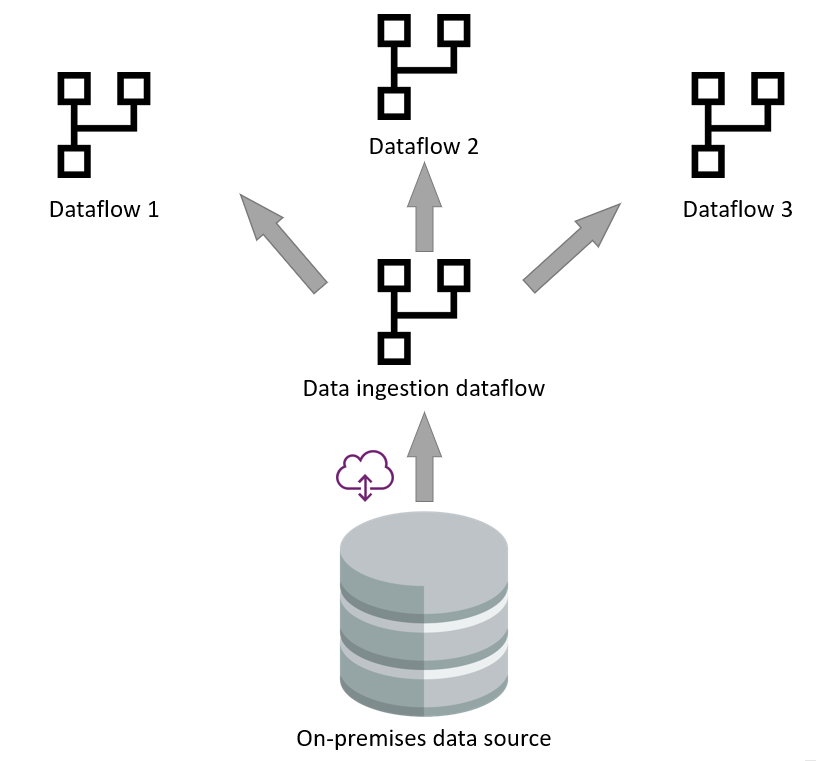
Rozdzielenie przepływów pozyskiwania i przekształcania danych
Rozdzielenie dwóch warstw — pozyskiwanie i przekształcanie danych — jest przydatne w scenariuszach, w których źródło danych działa wolno. Pomaga zminimalizować interakcję ze źródłem danych.
Ta separacja nie jest tylko przydatna ze względu na poprawę wydajności, ale także jest przydatna w scenariuszach, w których stary starszy system źródła danych został zmigrowany do nowego systemu. W takich przypadkach należy zmienić tylko przepływy pozyskiwania danych. Przepływy wariantowe przekształcania danych pozostają bez zmian dla tego typu zmian.
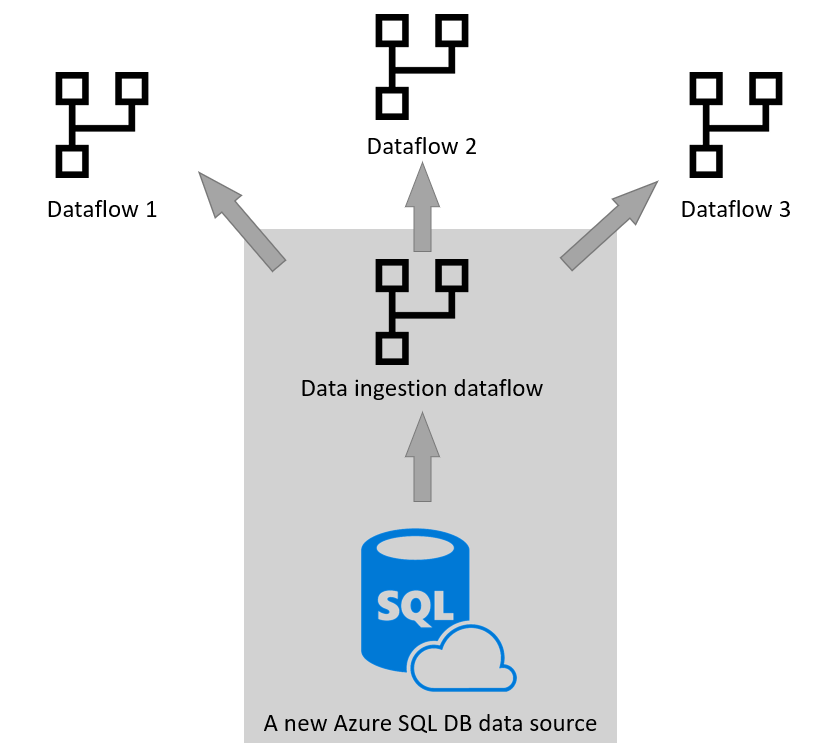
Ponowne użycie w innych narzędziach i usługach
Separacja przepływów danych pozyskiwania danych z przepływów danych przekształcania danych jest przydatna w wielu scenariuszach. Innym scenariuszem przypadku użycia tego wzorca jest użycie tych danych w innych narzędziach i usługach. W tym celu lepiej użyć analitycznych przepływów danych i użyć własnej usługi Data Lake Storage jako silnika magazynującego. Więcej informacji: Analityczne przepływy danych
Optymalizowanie przepływu danych wprowadzania danych
Rozważ optymalizację przepływu danych przyswajania, jeśli to możliwe. Jeśli na przykład wszystkie dane ze źródła nie są potrzebne, a źródło danych obsługuje składanie zapytań, filtrowanie danych i uzyskiwanie tylko wymaganego podzestawu jest dobrym rozwiązaniem. Aby dowiedzieć się więcej na temat składania zapytań, zobacz Omówienie oceny zapytań i składania zapytań w dodatku Power Query.
Twórz przepływy pozyskiwania danych jako przepływy analityczne
Rozważ tworzenie przepływów pozyskiwania danych jako analityczne przepływy danych. W szczególności pomaga to innym usługom i aplikacjom korzystać z tych danych. Ułatwia to również przepływy danych przekształcania danych w celu pobrania danych z przepływu danych pozyskiwania analitycznego. Aby dowiedzieć się więcej, przejdź do sekcji Analityczne przepływy danych.