Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Uwaga / Notatka
Poziomy prywatności są obecnie niedostępne w przepływach danych platformy Power Platform, ale zespół produktu pracuje nad włączeniem tej funkcji.
Jeśli używasz dodatku Power Query przez dowolny czas, prawdopodobnie go doświadczysz. Gdy buszujesz po zapytaniach i nagle napotykasz błąd, którego nie da się naprawić, niezależnie od tego, jak długo szukasz pomocy w sieci, dostosowujesz zapytania czy desperacko próbujesz różnych rozwiązań. Błąd podobny do:
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
A może:
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
Te Formula.Firewall błędy są wynikiem zapory prywatności danych dodatku Power Query (znanej również jako Zapora), która czasami może wydawać się, że istnieje wyłącznie w celu sfrustrowania analityków danych na całym świecie. Uwierz lub nie, jednak Firewall służy ważnemu celowi. W tym artykule przyjrzymy się szczegółom, aby lepiej zrozumieć, jak to działa. Uzbrojony w lepsze zrozumienie, będziesz w stanie lepiej zdiagnozować i naprawić błędy zapory w przyszłości.
Co to jest?
Celem zapory prywatności danych jest prosty: istnieje, aby zapobiec przypadkowemu wyciekowi danych między źródłami przez Power Query.
Dlaczego jest to konieczne? Myślę, że z pewnością można utworzyć kilka M, które przekażą wartość SQL do źródła danych OData. Jednak byłoby to zamierzone wycieki danych. Autor mashupu (lub przynajmniej powinien) wiedzieć, że to robi. Dlaczego zatem potrzeba ochrony przed niezamierzonym wyciekiem danych?
Odpowiedź? Składanie.
Składane?
Składanie to termin, który odnosi się do konwertowania wyrażeń w języku M (takich jak filtry, zmiany nazw, sprzężenia itd.) na operacje względem nieprzetworzonego źródła danych (takiego jak SQL, OData itd.). Ogromną częścią mocy dodatku Power Query jest fakt, że dodatek Power Query może konwertować operacje wykonywane przez użytkownika za pośrednictwem interfejsu użytkownika na złożone języki języka SQL lub innych źródeł danych zaplecza, bez konieczności znajomości tych języków przez użytkownika. Użytkownicy uzyskują korzyści z wydajności operacji natywnych źródeł danych, z łatwością korzystania z interfejsu użytkownika, w którym można przekształcić wszystkie źródła danych przy użyciu wspólnego zestawu poleceń.
W ramach składania Power Query czasami może ustalić, że najbardziej efektywnym sposobem wykonania danego mashupu jest pobranie danych z jednego źródła i przekazanie ich do innego. Jeśli na przykład dołączasz mały plik CSV do ogromnej tabeli SQL, prawdopodobnie nie chcesz, aby dodatek Power Query odczytywał plik CSV, odczytywał całą tabelę SQL, a następnie łączył je ze sobą na komputerze lokalnym. Prawdopodobnie chcesz, aby dodatek Power Query uwzględnił dane CSV w instrukcji SQL i poprosił bazę danych SQL o wykonanie sprzężenia.
W ten sposób może wystąpić niezamierzony wyciek danych.
Wyobraź sobie, że łączysz dane SQL zawierające numery ubezpieczenia społecznego pracowników z wynikami zewnętrznego źródła danych OData i nagle odkrywasz, że numery ubezpieczenia społecznego z bazy danych SQL są wysyłane do usługi OData. Zła wiadomość, prawda?
Jest to rodzaj scenariusza, przed którym zapora jest przeznaczona zapobiegać.
Jak to działa?
Zapora istnieje, aby zapobiec przypadkowemu wysyłaniu danych z jednego źródła do innego źródła. Wystarczająco proste.
W jaki sposób realizuje tę misję?
Robi to przez podzielenie zapytań języka M na elementy nazywane partycjami, a następnie wymuszanie następującej reguły:
- Partycja może uzyskiwać dostęp do zgodnych źródeł danych lub odwoływać się do innych partycji, ale nie do obu.
Prosty... ale mylące. Co to jest partycja? Co sprawia, że dwa źródła danych są "zgodne"? ** Dlaczego zapora miałaby się przejmować, jeśli partycja chce uzyskać dostęp do źródła danych i odwołać się do innej partycji?
Przeanalizujmy to i przyjrzyjmy się poprzedniej regule pojedynczo.
Co to jest partycja?
Na najbardziej podstawowym poziomie partycja jest zbiorem jednego lub więcej kroków zapytania. Najbardziej szczegółowa partycja możliwa (przynajmniej w bieżącej implementacji) to jeden krok. Największe partycje mogą czasami obejmować wiele zapytań. (Więcej informacji na ten temat później).
Jeśli nie znasz kroków, możesz je wyświetlić po prawej stronie okna Edytora Power Query po wybraniu zapytania w okienku Zastosowane kroki . Kroki rejestrują wszystkie czynności, które wykonujesz, aby przekształcić dane w ich ostateczny kształt.
Partycje odwołujące się do innych partycji
Gdy zapytanie jest oceniane przy użyciu zapory, zapora dzieli zapytanie i wszystkie jego zależności na partycje (czyli grupy kroków). Za każdym razem, gdy jedna partycja odwołuje się do innej partycji, zapora zastępuje odwołanie wywołaniem specjalnej funkcji o nazwie Value.Firewall. Innymi słowy zapora nie zezwala na bezpośrednie uzyskiwanie dostępu do partycji. Wszystkie odwołania są modyfikowane, aby przechodziły przez zaporę. Myśl o zaporze jako strażniku. Partycja, która odwołuje się do innej partycji, musi uzyskać zezwolenie zapory, aby to zrobić, a zapora kontroluje, czy przywoływane dane są dozwolone w partycji.
To wszystko może wydawać się dość abstrakcyjne, więc przyjrzyjmy się przykładowi.
Załóżmy, że masz zapytanie o nazwie Employees, które ściąga niektóre dane z bazy danych SQL. Załóżmy, że masz również inne zapytanie (EmployeesReference), które po prostu odwołuje się do pracowników.
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Employees
in
Source;
Te zapytania są podzielone na dwie partycje: jedną dla zapytania Employees i jedną dla zapytania EmployeesReference (która odwołuje się do partycji Employees). Po ocenie za pomocą zapory te zapytania zostaną przepisane w następujący sposób:
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Value.Firewall("Section1/Employees")
in
Source;
Zwróć uwagę, że proste odwołanie do zapytania Employees jest zastępowane wywołaniem metody Value.Firewall, której podano pełną nazwę zapytania Employees.
Gdy oceniana jest konstrukcja EmployeesReference, zapora przechwytuje wywołanie Value.Firewall("Section1/Employees"), co daje jej możliwość kontrolowania, czy (i jak) żądane dane przepływają do partycji EmployeesReference. Może wykonywać dowolną liczbę czynności: odmówić żądania, buforować żądane dane (co uniemożliwia wszelkie dalsze odczyty z oryginalnego źródła danych), itd.
W ten sposób zapora ogniowa zachowuje kontrolę nad danymi przepływającymi między partycjami.
Partycje, które uzyskują bezpośredni dostęp do źródeł danych
Załóżmy, że zdefiniujesz zapytanie Query1 za pomocą jednego kroku (należy pamiętać, że to jednoetapowe zapytanie odpowiada jednej partycji Zapory) i że ten pojedynczy krok uzyskuje dostęp do dwóch źródeł danych: tabeli bazy danych SQL i pliku CSV. Jak zapora sobie z tym radzi, skoro nie ma odwołania do partycji, a więc nie ma wywołania do przechwycenia przez Value.Firewall? Przyjrzyjmy się wcześniej podanej regule:
- Partycja może uzyskiwać dostęp do zgodnych źródeł danych lub odwoływać się do innych partycji, ale nie do obu.
Aby zapytanie dotyczące jednej partycji, ale dwóch źródeł danych mogło być uruchomione, jego dwa źródła danych muszą być "zgodne". Innymi słowy, powinno być możliwe współdzielenie danych w obu kierunkach między nimi. Oznacza to, że ustawienia prywatności obu źródeł muszą być publiczne, albo oba muszą być organizacyjne, ponieważ są to jedyne dwie kombinacje, które umożliwiają obustronne udostępnianie. Jeśli oba źródła są oznaczone jako Prywatne lub jeden jest oznaczony jako Publiczny, a jeden jest oznaczony jako Organizacyjny lub jest oznaczony przy użyciu innej kombinacji poziomów prywatności, udostępnianie dwukierunkowe nie jest dozwolone. Nie jest bezpieczne, aby oba te elementy były oceniane w tej samej partycji. Oznaczałoby to, że może wystąpić niebezpieczny wyciek danych (z powodu folding), a firewall nie byłby w stanie temu zapobiec.
Co się stanie, jeśli spróbujesz uzyskać dostęp do niezgodnych źródeł danych w tej samej partycji?
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
Mam nadzieję, że teraz lepiej zrozumiesz jeden z komunikatów o błędach wymienionych na początku tego artykułu.
To wymaganie zgodności ma zastosowanie tylko w ramach danej partycji. Jeśli partycja odwołuje się do innych partycji, źródła danych z przywołynych partycji nie muszą być ze sobą zgodne. Dzieje się tak, ponieważ zapora sieciowa może buforować dane, co uniemożliwia dalsze składanie względem oryginalnego źródła danych. Dane są ładowane do pamięci i traktowane tak, jakby pochodziły znikąd.
Dlaczego nie obie?
Załóżmy, że zdefiniujesz zapytanie z jednym krokiem (który ponownie odpowiada jednej partycji), która uzyskuje dostęp do dwóch innych zapytań (czyli dwóch innych partycji). Co jeśli chciałbyś w tym samym kroku uzyskać bezpośredni dostęp do bazy danych SQL? Dlaczego partycja nie może odwoływać się do innych partycji i bezpośrednio uzyskać dostępu do zgodnych źródeł danych?
Jak pokazano wcześniej, gdy jedna partycja odwołuje się do innej partycji, zapora działa jako strażnik dla wszystkich danych przepływających do partycji. Aby to zrobić, musi mieć możliwość kontrolowania, jakie dane są dozwolone do przyjęcia. Jeśli w partycji są dostępne źródła danych, a dane przepływają z innych partycji, traci ona możliwość pełnienia roli strażnika, ponieważ dane te mogą zostać nieświadomie ujawnione do jednego z wewnętrznie używanych źródeł danych. W związku z tym zapora uniemożliwia partycji, która uzyskuje dostęp do innych partycji, bezpośredni dostęp do jakichkolwiek źródeł danych.
Co się dzieje, jeśli partycja próbuje odwołać się do innych partycji, a także bezpośrednio uzyskać dostęp do źródeł danych?
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Teraz miejmy nadzieję, że lepiej zrozumiesz inny komunikat o błędzie wymieniony na początku tego artykułu.
Dogłębne partycje
Jak można prawdopodobnie wnioskować z poprzednich informacji, sposób partycjonowania zapytań jest niezwykle ważny. Jeśli masz kroki odwołujące się do innych zapytań oraz inne kroki, które uzyskują dostęp do źródeł danych, teraz powinieneś rozpoznać, że rysowanie granic partycji w niektórych miejscach powoduje błędy zapory, podczas gdy rysowanie ich w innych miejscach pozwala na bezproblemowe działanie zapytania.
Jak dokładnie zapytania są partycjonowane?
Ta sekcja jest prawdopodobnie najważniejsza, aby zrozumieć, dlaczego występują błędy zapory i zrozumieć, jak je rozwiązać (tam, gdzie to możliwe).
Poniżej przedstawiono ogólne podsumowanie logiki partycjonowania.
- Partycjonowanie początkowe
- Tworzy partycję danych dla każdego kroku w każdym zapytaniu
- Faza statyczna
- Ta faza nie zależy od wyników oceny. Zamiast tego opiera się na strukturę zapytań.
- Przycinanie parametrów
- Przycina partycje przypominające parametry, to znaczy takie, które:
- Nie odwołuje się do żadnych innych partycji
- Nie zawiera żadnych wywołań funkcji
- Nie jest cykliczny (czyli nie odnosi się do samego siebie)
- Należy pamiętać, że "usunięcie" partycji skutecznie sprawia, że jest uwzględniana w innych partycjach, które ją wykorzystują.
- Przycinanie partycji parametrów sprawia, że odwołania do parametrów używane w wywołaniach funkcji źródła danych (na przykład
Web.Contents(myUrl)) działają poprawnie, zamiast generować błędy „partycja nie może odwoływać się do źródeł danych i innych kroków”.
- Przycina partycje przypominające parametry, to znaczy takie, które:
- Grupowanie (statyczne)
- Partycje są scalane w kolejności od dołu do góry zgodnie z zależnościami. W wynikowych scalonych partycjach następujące elementy są oddzielne:
- Partycje w różnych zapytaniach
- Partycje, które nie odwołują się do innych partycji (i w związku z tym mogą uzyskiwać dostęp do źródła danych)
- Partycje odwołujące się do innych partycji (i w związku z tym nie mogą uzyskiwać dostępu do źródła danych)
- Partycje są scalane w kolejności od dołu do góry zgodnie z zależnościami. W wynikowych scalonych partycjach następujące elementy są oddzielne:
- Przycinanie parametrów
- Ta faza nie zależy od wyników oceny. Zamiast tego opiera się na strukturę zapytań.
- Faza dynamiczna
- Ta faza zależy od wyników oceny, w tym informacji o źródłach danych dostępnych przez różne partycje.
- Przycinanie
- Przycina te partycje, które spełniają wszystkie następujące wymagania:
- Nie uzyskuje dostępu do żadnych źródeł danych
- Nie odwołuje się do żadnych partycji, które uzyskują dostęp do źródeł danych
- Nie jest cykliczne
- Przycina te partycje, które spełniają wszystkie następujące wymagania:
- Grupowanie (dynamiczne)
- Teraz, gdy niepotrzebne partycje są przycinane, spróbuj utworzyć partycje źródłowe, które są tak duże, jak to możliwe. Tworzenie odbywa się przez scalenie partycji przy użyciu tych samych reguł opisanych w poprzedniej fazie grupowania statycznego.
Co to wszystko oznacza?
Przyjrzyjmy się przykładowi, aby zilustrować sposób działania złożonej logiki.
Oto przykładowy scenariusz. Jest to dość proste scalanie pliku tekstowego (kontaktów) z bazą danych SQL (Employees), gdzie serwer SQL jest parametrem (DbServer).
Trzy zapytania
Oto kod języka M dla trzech zapytań używanych w tym przykładzie.
shared DbServer = "MySqlServer" meta [IsParameterQuery=true, Type="Text", IsParameterQueryRequired=true];
shared Contacts = let
Source = Csv.Document(File.Contents(
"C:\contacts.txt"),[Delimiter=" ", Columns=15, Encoding=1252, QuoteStyle=QuoteStyle.None]
),
#"Promoted Headers" = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
#"Changed Type" = Table.TransformColumnTypes(
#"Promoted Headers",
{
{"ContactID", Int64.Type},
{"NameStyle", type logical},
{"Title", type text},
{"FirstName", type text},
{"MiddleName", type text},
{"LastName", type text},
{"Suffix", type text},
{"EmailAddress", type text},
{"EmailPromotion", Int64.Type},
{"Phone", type text},
{"PasswordHash", type text},
{"PasswordSalt", type text},
{"AdditionalContactInfo", type text},
{"rowguid", type text},
{"ModifiedDate", type datetime}
}
)
in
#"Changed Type";
shared Employees = let
Source = Sql.Databases(DbServer),
AdventureWorks = Source{[Name="AdventureWorks"]}[Data],
HumanResources_Employee = AdventureWorks{[Schema="HumanResources",Item="Employee"]}[Data],
#"Removed Columns" = Table.RemoveColumns(
HumanResources_Employee,
{
"HumanResources.Employee(EmployeeID)",
"HumanResources.Employee(ManagerID)",
"HumanResources.EmployeeAddress",
"HumanResources.EmployeeDepartmentHistory",
"HumanResources.EmployeePayHistory",
"HumanResources.JobCandidate",
"Person.Contact",
"Purchasing.PurchaseOrderHeader",
"Sales.SalesPerson"
}
),
#"Merged Queries" = Table.NestedJoin(
#"Removed Columns",
{"ContactID"},
Contacts,
{"ContactID"},
"Contacts",
JoinKind.LeftOuter
),
#"Expanded Contacts" = Table.ExpandTableColumn(
#"Merged Queries",
"Contacts",
{"EmailAddress"},
{"EmailAddress"}
)
in
#"Expanded Contacts";
Oto widok wyższego poziomu przedstawiający zależności.
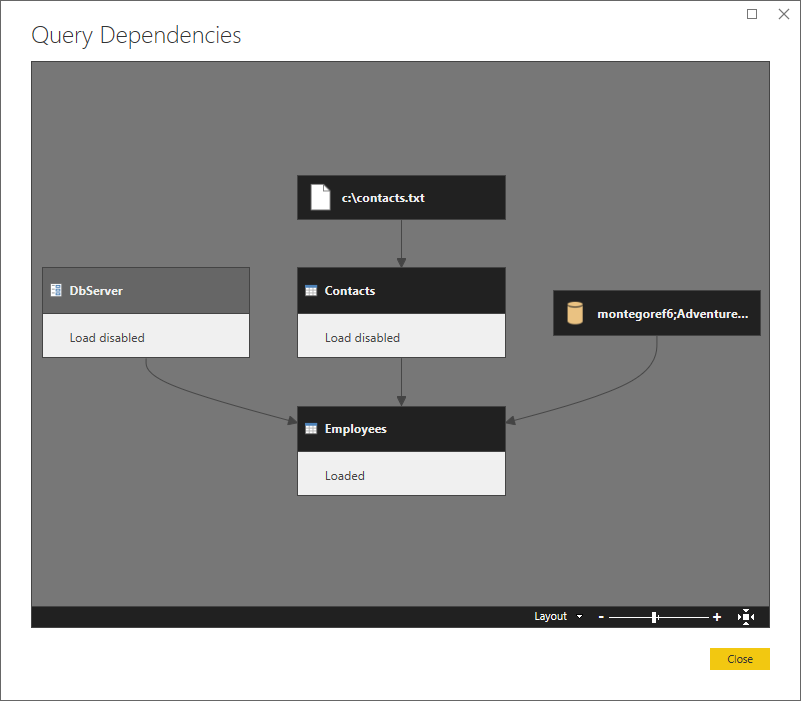
Stwórzmy partycję
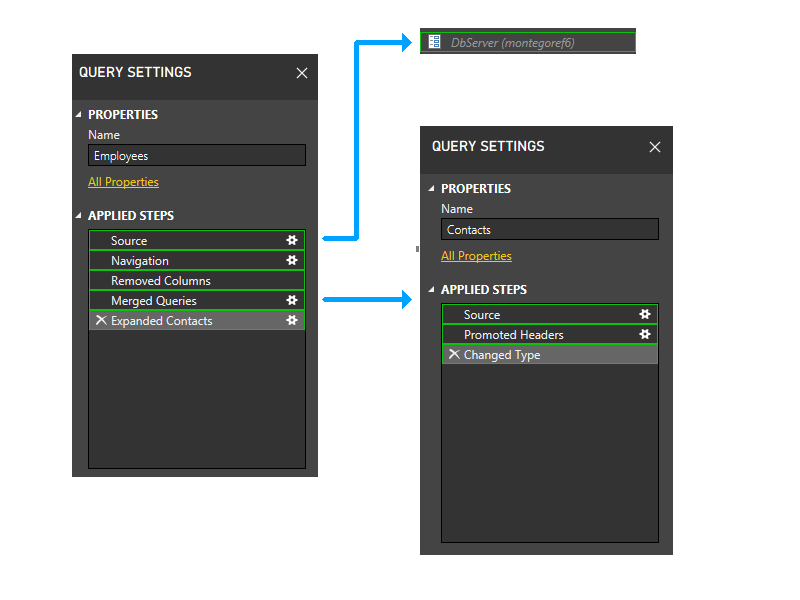
Powiększmy nieco i uwzględnijmy kroki na obrazie, a następnie zacznijmy przechodzić przez logikę partycjonowania. Oto diagram trzech zapytań przedstawiający początkowe partycje zapory w kolorze zielonym. Zwróć uwagę, że każdy krok rozpoczyna się we własnej partycji.
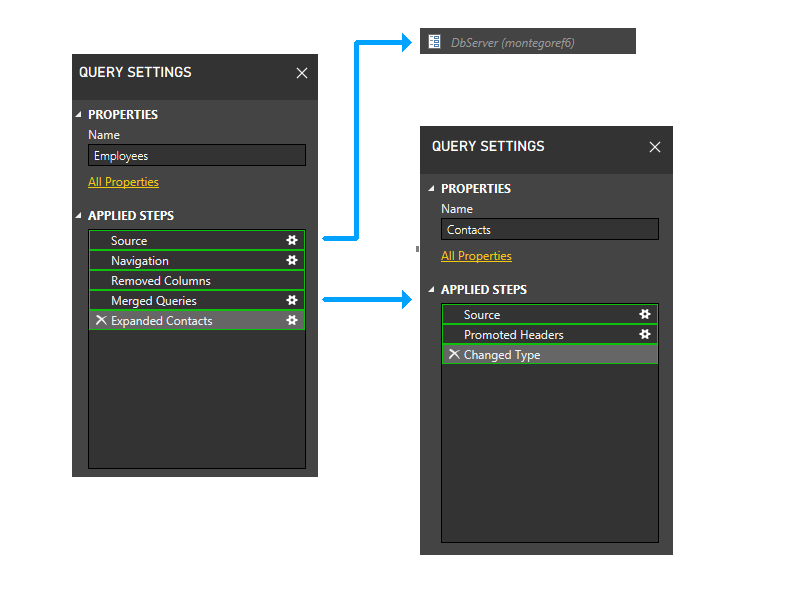
Następnie przycinamy podziały parametrów. W związku z tym serwer DbServer jest niejawnie dołączany do partycji źródłowej.
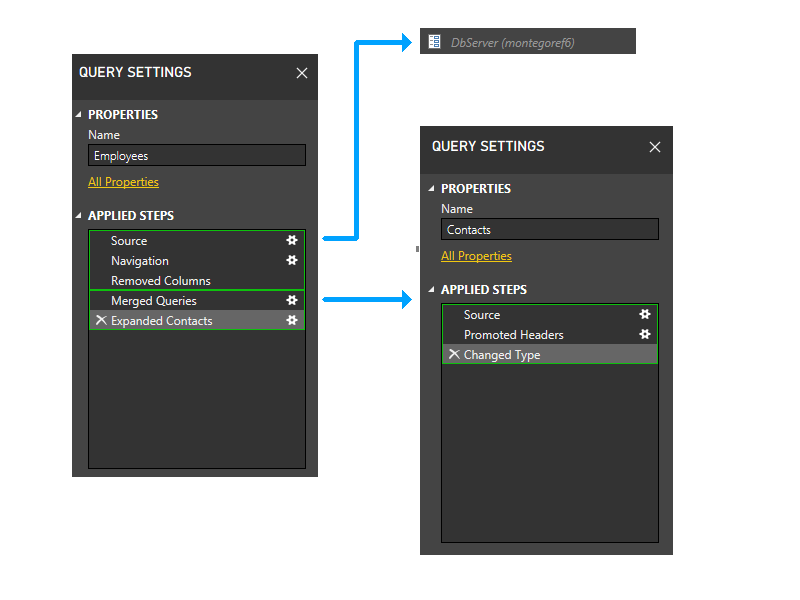
Teraz przeprowadzamy grupowanie statyczne. To grupowanie zapewnia oddzielenie między partycjami w oddzielnych zapytaniach (na przykład należy pamiętać, że dwa ostatnie etapy pracowników nie są połączone z etapami kontaktów) i między partycjami nawiązującymi do innych partycji (takimi jak dwa ostatnie etapy pracowników) i tymi, które tego nie robią (takimi jak pierwsze trzy etapy pracowników).
Teraz wprowadzamy fazę dynamiczną. W tej fazie oceniane są powyższe partycje statyczne. Partycje, które nie uzyskują dostępu do żadnych źródeł danych, są przycinane. Następnie partycje są grupowane w celu utworzenia partycji źródłowych, które są tak duże, jak to możliwe. Jednak w tym przykładowym scenariuszu wszystkie pozostałe partycje uzyskują dostęp do źródeł danych i nie ma dalszego grupowania, które można przeprowadzić. Partycje w naszym przykładzie nie zmieniają się w tej fazie.
Udajmy
Ze względu na ilustrację przyjrzyjmy się jednak temu, co się stanie, jeśli zapytanie Kontakty zamiast pochodzić z pliku tekstowego, było zakodowane w języku M (być może za pośrednictwem okna dialogowego Wprowadzanie danych ).
W takim przypadku zapytanie Kontakty nie będzie uzyskiwać dostępu do żadnych źródeł danych. W ten sposób zostanie ona przycięta w pierwszej części fazy dynamicznej.
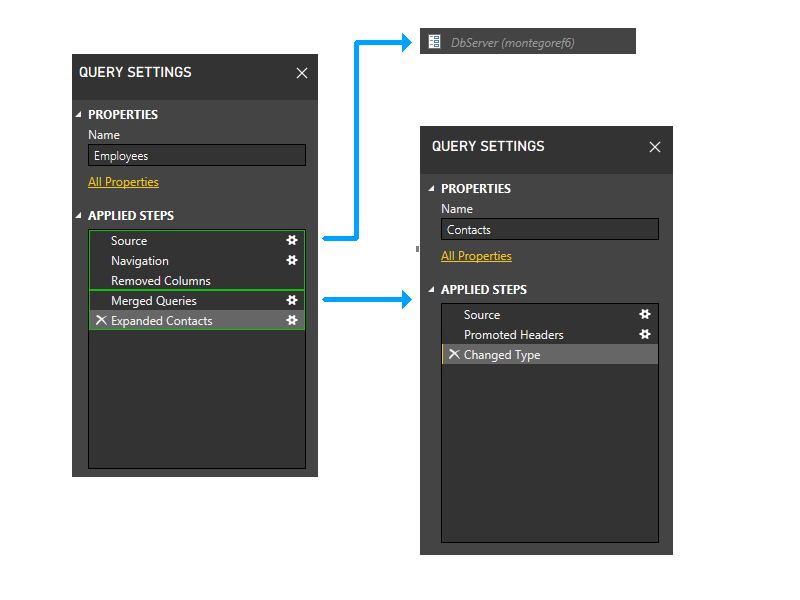
Po usunięciu partycji Kontakty ostatnie dwa kroki pracowników nie będą już odwoływać się do żadnych partycji, oprócz tej, która zawiera pierwsze trzy kroki pracowników. W związku z tym dwie partycje zostaną zgrupowane.
Wynikowa partycja będzie wyglądać następująco.
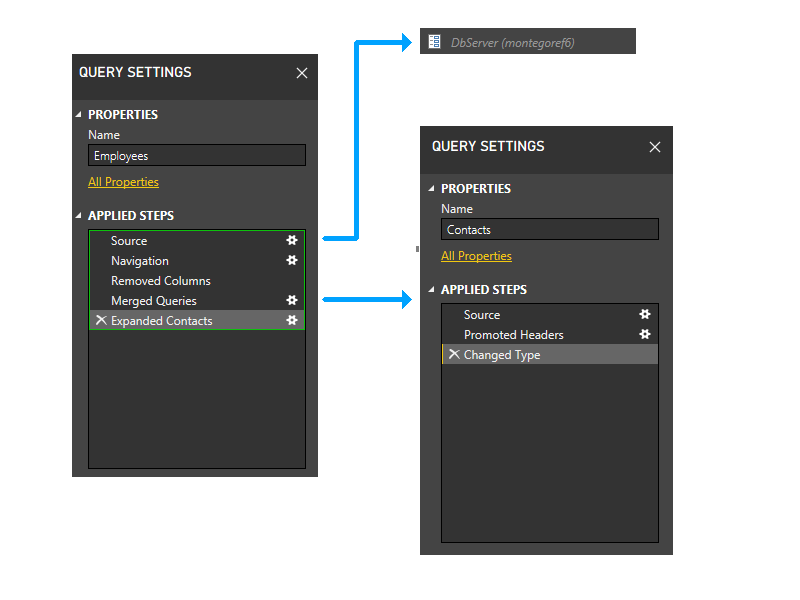
Przykład: przekazywanie danych z jednego źródła danych do innego
Ok, dość tych abstrakcyjnych wyjaśnień. Przyjrzyjmy się typowemu scenariuszowi, w którym prawdopodobnie wystąpi błąd zapory i kroki umożliwiające jego rozwiązanie.
Wyobraź sobie, że chcesz wyszukać nazwę firmy z usługi Northwind OData, a następnie użyć nazwy firmy do wyszukiwania Bing.
Najpierw należy utworzyć zapytanie firmowe w celu pobrania nazwy firmy.
let
Source = OData.Feed(
"https://services.odata.org/V4/Northwind/Northwind.svc/",
null,
[Implementation="2.0"]
),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName]
in
CHOPS
Następnie utworzysz zapytanie wyszukiwania , które odwołuje się do firmy i przekazuje je do usługi Bing.
let
Source = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & Company))
in
Source
W tym momencie napotkasz problemy. Ocena wyszukiwania powoduje błąd zapory.
Formula.Firewall: Query 'Search' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Ten błąd występuje, ponieważ krok Źródło wyszukiwania odwołuje się do źródła danych (bing.com), a także odwołuje się do innej kwerendy/partycji (firma). Narusza ona wcześniej wymienioną regułę ("partycja może uzyskiwać dostęp do zgodnych źródeł danych lub odwoływać się do innych partycji, ale nie obu").
Co robić? Jedną z opcji jest całkowite wyłączenie zapory (za pośrednictwem opcji Prywatność z etykietą Ignoruj poziomy prywatności i potencjalnie poprawić wydajność). Ale co zrobić, jeśli chcesz pozostawić włączoną zaporę?
Aby rozwiązać ten problem bez wyłączania zapory, możesz połączyć aplikację Company i Search w jedno zapytanie, w następujący sposób:
let
Source = OData.Feed(
"https://services.odata.org/V4/Northwind/Northwind.svc/",
null,
[Implementation="2.0"]
),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName],
Search = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & CHOPS))
in
Search
Wszystko dzieje się teraz wewnątrz jednej partycji. Zakładając, że poziomy prywatności dla dwóch źródeł danych są zgodne, zapora powinna teraz działać poprawnie i nie będzie już występować błąd.
To już koniec
Chociaż jest o wiele więcej, które można powiedzieć na ten temat, ten artykuł wprowadzający jest już wystarczająco długi. Mam nadzieję, że otrzymasz lepsze zrozumienie zapory i pomoże Ci zrozumieć i naprawić błędy zapory, gdy napotkasz je w przyszłości.