Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Obsługa programu Machine Learning Studio (wersja klasyczna) zakończy się 31 sierpnia 2024 r. Zalecamy przejście do usługi Azure Machine Learning przed tym terminem.
Od 1 grudnia 2021 r. nie będzie można tworzyć nowych zasobów programu Machine Learning Studio (wersja klasyczna). Do 31 sierpnia 2024 r. można będzie nadal korzystać z istniejących zasobów programu Machine Learning Studio (wersja klasyczna).
- Zobacz informacje na temat przenoszenia projektów uczenia maszynowego z programu ML Studio (wersja klasyczna) do Azure Machine Learning.
- Dowiedz się więcej o Azure Machine Learning.
Dokumentacja programu ML Studio (wersja klasyczna) jest wycofywana i może nie być aktualizowana w przyszłości.
Konwertuje dane tekstowe na funkcje zakodowane jako liczba całkowita przy użyciu biblioteki Vowpal Wabbit
Kategoria: analiza tekstu
Uwaga
Dotyczy: tylko Machine Learning Studio (wersja klasyczna)
Podobne moduły przeciągania i upuszczania są dostępne w projektancie Azure Machine Learning.
Omówienie modułu
W tym artykule opisano sposób używania modułu wyznaczania wartości skrótu funkcji w programie Machine Learning Studio (wersja klasyczna), aby przekształcić strumień tekstu w język angielski na zestaw funkcji reprezentowanych jako liczby całkowite. Następnie można przekazać tę funkcję skrótu do algorytmu uczenia maszynowego w celu wytrenowania modelu analizy tekstu.
Funkcja tworzenia skrótów udostępniona w tym module jest oparta na strukturze Vowpal Wabbit. Aby uzyskać więcej informacji, zobacz Train Vowpal Wabbit 7-4 Model or Train Vowpal Wabbit 7-10 Model (Trenowanie modelu Vowpal Wabbit7-10).
Więcej informacji na temat tworzenia skrótów funkcji
Funkcja skrótów działa przez konwertowanie unikatowych tokenów na liczby całkowite. Działa on na dokładnych ciągach, które podajesz jako dane wejściowe i nie wykonuje żadnej analizy językowej ani przetwarzania wstępnego.
Na przykład weź zestaw prostych zdań, takich jak te, a następnie wynik tonacji. Załóżmy, że chcesz użyć tego tekstu do utworzenia modelu.
| TEKST UŻYTKOWNIKA | SENTYMENT |
|---|---|
| Kochałem tę książkę | 3 |
| Nienawidziłem tej książki | 1 |
| Ta książka była świetna | 3 |
| Uwielbiam książki | 2 |
Wewnętrznie moduł tworzenia skrótów funkcji tworzy słownik n-gramów. Na przykład lista bigramów dla tego zestawu danych będzie podobna do następującej:
| TERM (bigrams) | CZĘSTOTLIWOŚCI |
|---|---|
| Ta książka | 3 |
| Kochałem | 1 |
| Nienawidziłem | 1 |
| Kocham | 1 |
Rozmiar n-gramów można kontrolować za pomocą właściwości N-gramów . W przypadku wybrania bigramów obliczane są również unigramy. W związku z tym słownik zawiera również pojedyncze terminy, takie jak:
| Termin (unigramy) | CZĘSTOTLIWOŚCI |
|---|---|
| książka | 3 |
| I | 3 |
| książki | 1 |
| Został | 1 |
Po skompilowaniu słownika moduł tworzenia skrótów funkcji konwertuje terminy słownika na wartości skrótu i oblicza, czy funkcja została użyta w każdym przypadku. Dla każdego wiersza danych tekstowych moduł zwraca zestaw kolumn, jedną kolumnę dla każdej funkcji skrótu.
Na przykład po dokonaniu skrótu kolumny funkcji mogą wyglądać mniej więcej tak:
| Klasyfikacja | Funkcja tworzenia skrótów 1 | Funkcja tworzenia skrótów 2 | Funkcja tworzenia skrótów 3 |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- Jeśli wartość w kolumnie wynosi 0, wiersz nie zawiera funkcji skrótu.
- Jeśli wartość to 1, wiersz zawierał funkcję.
Zaletą używania skrótów funkcji jest możliwość reprezentowania dokumentów tekstowych o zmiennej długości jako wektorów cech liczbowych o równej długości i zmniejszania wymiarowości. Z kolei jeśli próbujesz użyć kolumny tekstowej do trenowania w taki sposób, będzie ona traktowana jako kolumna cech kategorii z wieloma różnymi wartościami.
Użycie danych wyjściowych jako liczbowych umożliwia również używanie wielu różnych metod uczenia maszynowego z danymi, w tym klasyfikacji, klastrowania lub pobierania informacji. Ponieważ operacje wyszukiwania mogą używać wartości skrótów całkowitych, a nie porównań ciągów, uzyskanie wag funkcji jest również znacznie szybsze.
Jak skonfigurować tworzenie skrótów funkcji
Dodaj moduł tworzenia skrótów funkcji do eksperymentu w programie Studio (wersja klasyczna).
Połączenie zestaw danych zawierający tekst, który chcesz przeanalizować.
Porada
Ponieważ skróty funkcji nie wykonują operacji leksykalnych, takich jak stemming lub obcinanie, czasami można uzyskać lepsze wyniki, wykonując wstępne przetwarzanie tekstu przed zastosowaniem tworzenia skrótów funkcji. Aby uzyskać sugestie, zobacz sekcje Najlepsze rozwiązania i uwagi techniczne .
W obszarze Kolumny docelowe wybierz te kolumny tekstowe, które chcesz przekonwertować na funkcje skrótów.
Kolumny muszą być typem danych ciągu i muszą być oznaczone jako kolumna Cecha .
Jeśli wybierzesz wiele kolumn tekstowych do użycia jako dane wejściowe, może to mieć ogromny wpływ na wymiarowość cech. Jeśli na przykład 10-bitowy skrót jest używany dla pojedynczej kolumny tekstowej, dane wyjściowe zawierają 1024 kolumny. Jeśli 10-bitowy skrót jest używany dla dwóch kolumn tekstowych, dane wyjściowe zawierają kolumny 2048.
Uwaga
Domyślnie program Studio (klasyczny) oznacza większość kolumn tekstowych jako funkcje, więc jeśli wybierzesz wszystkie kolumny tekstowe, może zostać wyświetlonych zbyt wiele kolumn, w tym wiele kolumn, które nie są w rzeczywistości wolnym tekstem. Użyj opcji Wyczyść funkcję w obszarze Edytuj metadane , aby uniemożliwić skrót innych kolumn tekstowych.
Użyj skrótu bitsize , aby określić liczbę bitów do użycia podczas tworzenia tabeli skrótów.
Domyślny rozmiar bitu to 10. W przypadku wielu problemów ta wartość jest większa niż odpowiednia, ale to, czy wystarczające dane zależą od rozmiaru słownictwa n-gramów w tekście treningowym. Przy dużym słownictwie może być potrzebnych więcej miejsca, aby uniknąć kolizji.
Zalecamy wypróbowanie użycia innej liczby bitów dla tego parametru i ocenę wydajności rozwiązania uczenia maszynowego.
W przypadku N-gramów wpisz liczbę, która definiuje maksymalną długość n-gramów do dodania do słownika treningowego. N-gram to sekwencja n słów traktowana jako unikatowa jednostka.
N-gramy = 1: Unigramy lub pojedyncze wyrazy.
N-gramy = 2: Bigrams lub dwie sekwencje wyrazów, plus unigramy.
N-gramy = 3: Trigramy lub trzy wyrazy sekwencje, plus bigrams i unigramy.
Uruchom eksperyment.
Wyniki
Po zakończeniu przetwarzania moduł generuje przekształcony zestaw danych, w którym oryginalna kolumna tekstowa została przekonwertowana na wiele kolumn, z których każda reprezentuje funkcję w tekście. W zależności od wielkości słownika wynikowy zestaw danych może być bardzo duży:
| Nazwa kolumny 1 | Typ kolumny 2 |
|---|---|
| TEKST UŻYTKOWNIKA | Oryginalna kolumna danych |
| SENTYMENT | Oryginalna kolumna danych |
| USERTEXT — funkcja skrótu 1 | Kolumna funkcji skrótu |
| USERTEXT — funkcja skrótu 2 | Kolumna funkcji skrótu |
| USERTEXT — funkcja skrótu n | Kolumna funkcji skrótu |
| USERTEXT — funkcja skrótu 1024 | Kolumna funkcji skrótu |
Po utworzeniu przekształconego zestawu danych można go użyć jako danych wejściowych modułu Train Model (Trenowanie modelu) wraz z dobrym modelem klasyfikacji, takim jak maszyna wektorowa obsługi dwuklasowej.
Najlepsze rozwiązania
Niektóre najlepsze rozwiązania, których można użyć podczas modelowania danych tekstowych, przedstawiono na poniższym diagramie reprezentującym eksperyment
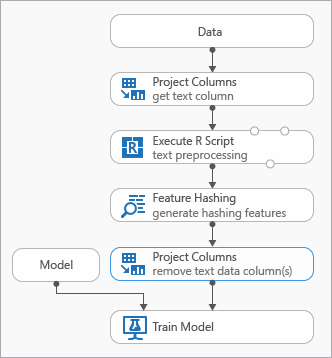
Aby wstępnie przetworzyć tekst wejściowy, może być konieczne dodanie modułu Execute R Script (Wykonywanie skryptu języka R ) przed użyciem skrótu funkcji. W przypadku skryptu języka R masz również elastyczność używania niestandardowych słownictwa lub przekształceń niestandardowych.
Należy dodać moduł Select Columns in Dataset (Wybieranie kolumn w zestawie danych ) po module funkcji skrótów , aby usunąć kolumny tekstowe z wyjściowego zestawu danych. Kolumny tekstowe nie są potrzebne po wygenerowaniu funkcji tworzenia skrótów.
Alternatywnie możesz użyć modułu Edytuj metadane , aby wyczyścić atrybut funkcji z kolumny tekstowej.
Rozważ również użycie tych opcji przetwarzania wstępnego tekstu, aby uprościć wyniki i zwiększyć dokładność:
- niezgodność wyrazów
- zatrzymaj usuwanie wyrazów
- normalizacja przypadku
- usuwanie znaków interpunkcyjnych i znaków specjalnych
- Wynikające.
Optymalny zestaw metod przetwarzania wstępnego do zastosowania w dowolnym rozwiązaniu zależy od domeny, słownictwa i potrzeb biznesowych. Zalecamy eksperymentowanie z danymi, aby zobaczyć, które niestandardowe metody przetwarzania tekstu są najbardziej skuteczne.
Przykłady
Aby zapoznać się z przykładami użycia skrótów funkcji do analizy tekstu, zobacz Galerię sztucznej inteligencji platformy Azure:
Kategoryzacja wiadomości: używa skrótów funkcji do klasyfikowania artykułów w wstępnie zdefiniowanej listy kategorii.
Podobne firmy: używa tekstu artykułów Wikipedii do kategoryzowania firm.
Klasyfikacja tekstu: ten pięcioczęściowy przykład używa tekstu z wiadomości twitterowych do przeprowadzania analizy tonacji.
Uwagi techniczne
Ta sekcja zawiera szczegóły implementacji, porady i odpowiedzi na często zadawane pytania.
Porada
Oprócz używania skrótów funkcji warto użyć innych metod wyodrębniania funkcji z tekstu. Przykład:
- Użyj modułu Preprocess Text (Przetwarzanie wstępne), aby usunąć artefakty, takie jak błędy pisowni, lub uprościć przygotowanie tekstu do tworzenia skrótów.
- Wyodrębnij kluczowe frazy, aby wyodrębnić frazy przy użyciu przetwarzania języka naturalnego.
- Użyj rozpoznawania nazwanych jednostek , aby zidentyfikować ważne jednostki.
Machine Learning Studio (wersja klasyczna) udostępnia szablon klasyfikacji tekstu, który przeprowadzi Cię przez proces wyodrębniania funkcji przy użyciu modułu skrótów funkcji.
Szczegóły implementacji
Moduł skrótów funkcji używa szybkiej struktury uczenia maszynowego o nazwie Vowpal Wabbit, która skróty zawierają wyrazy w indeksach w pamięci, przy użyciu popularnej funkcji skrótu open source o nazwie murmurhash3. Ta funkcja skrótu to nie kryptograficzny algorytm wyznaczania wartości skrótu, który mapuje wprowadzanie tekstu na liczby całkowite i jest popularny, ponieważ działa dobrze w losowym rozkładzie kluczy. W przeciwieństwie do funkcji skrótu kryptograficznego, można go łatwo odwrócić przez przeciwnika, aby był nieodpowiedni do celów kryptograficznych.
Celem skrótu jest konwertowanie dokumentów tekstowych o zmiennej długości na wektory cech liczbowych o równej długości, w celu obsługi redukcji wymiarowości i szybszego wyszukiwania wag funkcji.
Każda funkcja tworzenia skrótów reprezentuje co najmniej jedną cechę tekstu n-gramowego (unigramy lub pojedyncze wyrazy, gramy dwugramów, trzy gramy itp.), w zależności od liczby bitów (reprezentowanych jako k) i liczby n-gramów określonych jako parametry. Projektuje nazwy funkcji do niepodpisanego słowa architektury maszyny przy użyciu algorytmu szemmurhash v3 (tylko 32-bitowy), który następnie jest AND-ed z (2^k)-1. Oznacza to, że wartość skrótu jest przewidywana w dół do pierwszych bitów niższej kolejności k, a pozostałe bity są wyzerowane. Jeśli określona liczba bitów wynosi 14, tabela skrótów może zawierać wpisy 214-1 (lub 16 383).
W przypadku wielu problemów domyślna tabela skrótów (bitsize = 10) jest większa niż odpowiednia; jednak w zależności od rozmiaru słownictwa n-gramów w tekście treningowym może być konieczne więcej miejsca, aby uniknąć kolizji. Zalecamy, aby spróbować użyć innej liczby bitów dla parametru skrótu bitowego i ocenić wydajność rozwiązania uczenia maszynowego.
Oczekiwane dane wejściowe
| Nazwa | Typ | Opis |
|---|---|---|
| Zestaw danych | Tabela danych | Wejściowy zestaw danych |
Parametry modułu
| Nazwa | Zakres | Typ | Domyślny | Opis |
|---|---|---|---|---|
| Kolumny docelowe | Dowolne | KolumnaWybieranie | StringFeature | Wybierz kolumny, do których zostanie zastosowane skróty. |
| Skrót rozmiaru bitowego | [1;31] | Liczba całkowita | 10 | Wpisz liczbę bitów do użycia podczas tworzenia skrótów wybranych kolumn |
| N-gramy | [0;10] | Liczba całkowita | 2 | Określ liczbę N-gramów wygenerowanych podczas tworzenia skrótów. Domyślnie wyodrębniane są zarówno jednogramy, jak i bigramy |
Dane wyjściowe
| Nazwa | Typ | Opis |
|---|---|---|
| Przekształcony zestaw danych | Tabela danych | Wyjściowy zestaw danych z kolumnami skrótów |
Wyjątki
| Wyjątek | Opis |
|---|---|
| Błąd 0001 | Wyjątek występuje, jeśli nie można odnaleźć co najmniej jednej określonej kolumny zestawu danych. |
| Błąd 0003 | Wyjątek występuje, jeśli co najmniej jeden z danych wejściowych ma wartość null lub jest pusty. |
| Błąd 0004 | Wyjątek występuje, jeśli parametr jest mniejszy lub równy określonej wartości. |
| Błąd 0017 | Wyjątek występuje, jeśli co najmniej jedna określona kolumna ma typ nieobsługiwany przez bieżący moduł. |
Aby uzyskać listę błędów specyficznych dla modułów programu Studio (wersja klasyczna), zobacz Machine Learning Kody błędów.
Aby uzyskać listę wyjątków interfejsu API, zobacz Machine Learning kody błędów interfejsu API REST.