Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Uwaga
Ta książka elektroniczna została opublikowana wiosną 2017 r. i od tego czasu nie została zaktualizowana. Jest wiele w książce, która pozostaje cenna, ale niektóre z materiałów są przestarzałe.
Tworzenie aplikacji klienckich serwerów spowodowało skupienie się na tworzeniu aplikacji warstwowych korzystających z określonych technologii w każdej warstwie. Takie aplikacje są często określane jako aplikacje monolityczne i są pakowane na sprzęt wstępnie skalowany pod kątem obciążeń szczytowych. Główne wady tego podejścia programistycznego to ścisłe sprzęganie między składnikami w każdej warstwie, że poszczególne składniki nie mogą być łatwo skalowane i koszt testowania. Prosta aktualizacja może mieć nieprzewidziany wpływ na pozostałą część warstwy, dlatego zmiana składnika aplikacji wymaga ponownego przetestowania i ponownego wdrożenia całej warstwy.
Szczególnie w wieku chmury, jest to, że poszczególne składniki nie mogą być łatwo skalowane. Aplikacja monolityczna zawiera funkcje specyficzne dla domeny i jest zwykle podzielona przez warstwy funkcjonalne, takie jak fronton, logika biznesowa i magazyn danych. Aplikacja monolityczna jest skalowana przez sklonowanie całej aplikacji na wiele maszyn, jak pokazano na rysunku 8-1.
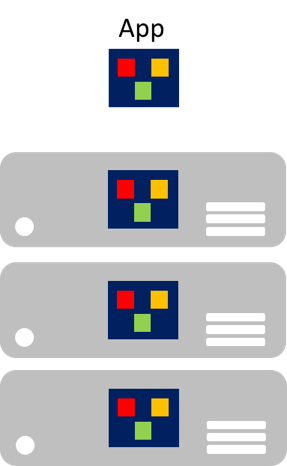
Rysunek 8–1. Podejście do skalowania aplikacji monolitycznych
Mikrousługi
Mikrousługi oferują inne podejście do tworzenia i wdrażania aplikacji, czyli podejścia odpowiedniego do wymagań dotyczących elastyczności, skalowania i niezawodności nowoczesnych aplikacji w chmurze. Aplikacja mikrousług jest rozłożona na niezależne składniki, które współpracują ze sobą w celu zapewnienia ogólnej funkcjonalności aplikacji. Termin mikrousługi podkreśla, że aplikacje powinny składać się z usług wystarczająco małych, aby odzwierciedlały niezależne obawy, dzięki czemu każda mikrousługa implementuje jedną funkcję. Ponadto każda mikrousługa ma dobrze zdefiniowane kontrakty, dzięki czemu inne mikrousługi mogą komunikować się z nimi i udostępniać je. Typowe przykłady mikrousług obejmują koszyki zakupów, przetwarzanie spisu, podsystemy zakupów i przetwarzanie płatności.
Mikrousługi mogą skalować w poziomie niezależnie w porównaniu z gigantycznymi aplikacjami monolitycznymi, które skalują się razem. Oznacza to, że określony obszar funkcjonalny, który wymaga większej mocy obliczeniowej lub przepustowości sieci w celu obsługi zapotrzebowania, można skalować, a nie niepotrzebnie skalować w poziomie inne obszary aplikacji. Rysunek 8–2 ilustruje to podejście, w którym mikrousługi są wdrażane i skalowane niezależnie, tworząc wystąpienia usług na maszynach.
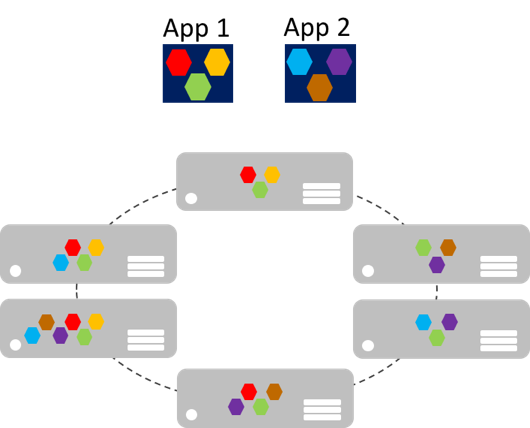
Rysunek 8–2. Podejście do skalowania aplikacji mikrousług
Skalowanie mikrousług w poziomie może być niemal natychmiastowe, dzięki czemu aplikacja może dostosować się do zmieniających się obciążeń. Na przykład pojedyncza mikrousługa w funkcji internetowej aplikacji może być jedyną mikrousługą w aplikacji, która musi być skalowana w poziomie w celu obsługi dodatkowego ruchu przychodzącego.
Klasycznym modelem skalowalności aplikacji jest posiadanie warstwy bezstanowej o zrównoważonym obciążeniu z udostępnionym zewnętrznym magazynem danych do przechowywania trwałych danych. Mikrousługi stanowe zarządzają własnymi trwałymi danymi, zwykle przechowując je lokalnie na serwerach, na których są umieszczone, aby uniknąć obciążenia związanego z dostępem do sieci i złożonością operacji obejmujących wiele usług. Umożliwia to najszybsze przetwarzanie danych i może wyeliminować konieczność buforowania systemów. Ponadto skalowalne mikrousługi stanowe zwykle partycjonują dane między wystąpieniami, aby zarządzać rozmiarem danych i przesyłać przepływność, poza którą może obsługiwać pojedynczy serwer.
Mikrousługi obsługują również niezależne aktualizacje. To luźne sprzężenie między mikrousługami zapewnia szybką i niezawodną ewolucję aplikacji. Ich niezależny, rozproszony charakter obsługuje aktualizacje stopniowe, w których tylko podzbiór wystąpień pojedynczej mikrousługi będzie aktualizowany w danym momencie. W związku z tym w przypadku wykrycia problemu można wycofać aktualizację usterek, zanim wszystkie wystąpienia zostaną zaktualizowane przy użyciu wadliwego kodu lub konfiguracji. Podobnie mikrousługi zwykle używają przechowywania wersji schematu, dzięki czemu klienci widzą spójną wersję po zastosowaniu aktualizacji, niezależnie od tego, z którym wystąpieniem mikrousługi jest komunikowane.
W związku z tym aplikacje mikrousług mają wiele zalet w przypadku aplikacji monolitycznych:
- Każda mikrousługa jest stosunkowo mała, łatwa do zarządzania i rozwoju.
- Każdą mikrousługę można opracowywać i wdrażać niezależnie od innych usług.
- Każdą mikrousługę można skalować w poziomie niezależnie. Na przykład usługa katalogu lub usługa koszyka zakupów może wymagać skalowania w poziomie więcej niż usługa zamawiania. W związku z tym wynikowa infrastruktura będzie wydajniej wykorzystywać zasoby podczas skalowania w górę.
- Każda mikrousługa izoluje wszelkie problemy. Jeśli na przykład występuje problem w usłudze, ma to wpływ tylko na tę usługę. Inne usługi mogą nadal obsługiwać żądania.
- Każda mikrousługa może korzystać z najnowszych technologii. Ponieważ mikrousługi są autonomiczne i uruchamiane obok siebie, mogą być używane najnowsze technologie i struktury, zamiast wymuszać korzystanie ze starszej struktury, która może być używana przez aplikację monolityczną.
Jednak rozwiązanie oparte na mikrousługach ma również potencjalne wady:
- Wybór sposobu partycjonowania aplikacji na mikrousługi może być trudny, ponieważ każda mikrousługa musi być całkowicie autonomiczna, kompleksowa, w tym odpowiedzialność za źródła danych.
- Deweloperzy muszą zaimplementować komunikację między usługami, co zwiększa złożoność i opóźnienie aplikacji.
- Transakcje niepodzielne między wieloma mikrousługami zwykle nie są możliwe. W związku z tym wymagania biznesowe muszą obejmować spójność ostateczną między mikrousługami.
- W środowisku produkcyjnym istnieje złożoność operacyjna wdrażania systemu z naruszonymi zabezpieczeniami wielu niezależnych usług i zarządzania nim.
- Bezpośrednia komunikacja między mikrousługami może utrudnić refaktoryzację kontraktów mikrousług. Na przykład w czasie może być konieczne podzielenie systemu na usługi. Pojedyncza usługa może być podzielona na co najmniej dwie usługi, a dwie usługi mogą zostać scalone. Gdy klienci komunikują się bezpośrednio z mikrousługami, ta refaktoryzacja może przerwać zgodność z aplikacjami klienckimi.
Konteneryzacja
Konteneryzacja to podejście do tworzenia oprogramowania, w którym aplikacja i jej zestaw wersji zależności oraz konfiguracja środowiska abstrakcyjna jako pliki manifestu wdrożenia są pakowane razem jako obraz kontenera, testowane jako jednostka i wdrażane w systemie operacyjnym hosta.
Kontener jest izolowanym, kontrolowanym zasobem i przenośnym środowiskiem operacyjnym, w którym aplikacja może działać bez dotykania zasobów innych kontenerów lub hosta. W związku z tym kontener wygląda i działa jak nowo zainstalowany komputer fizyczny lub maszyna wirtualna.
Istnieje wiele podobieństw między kontenerami i maszynami wirtualnymi, jak pokazano na rysunku 8–3.
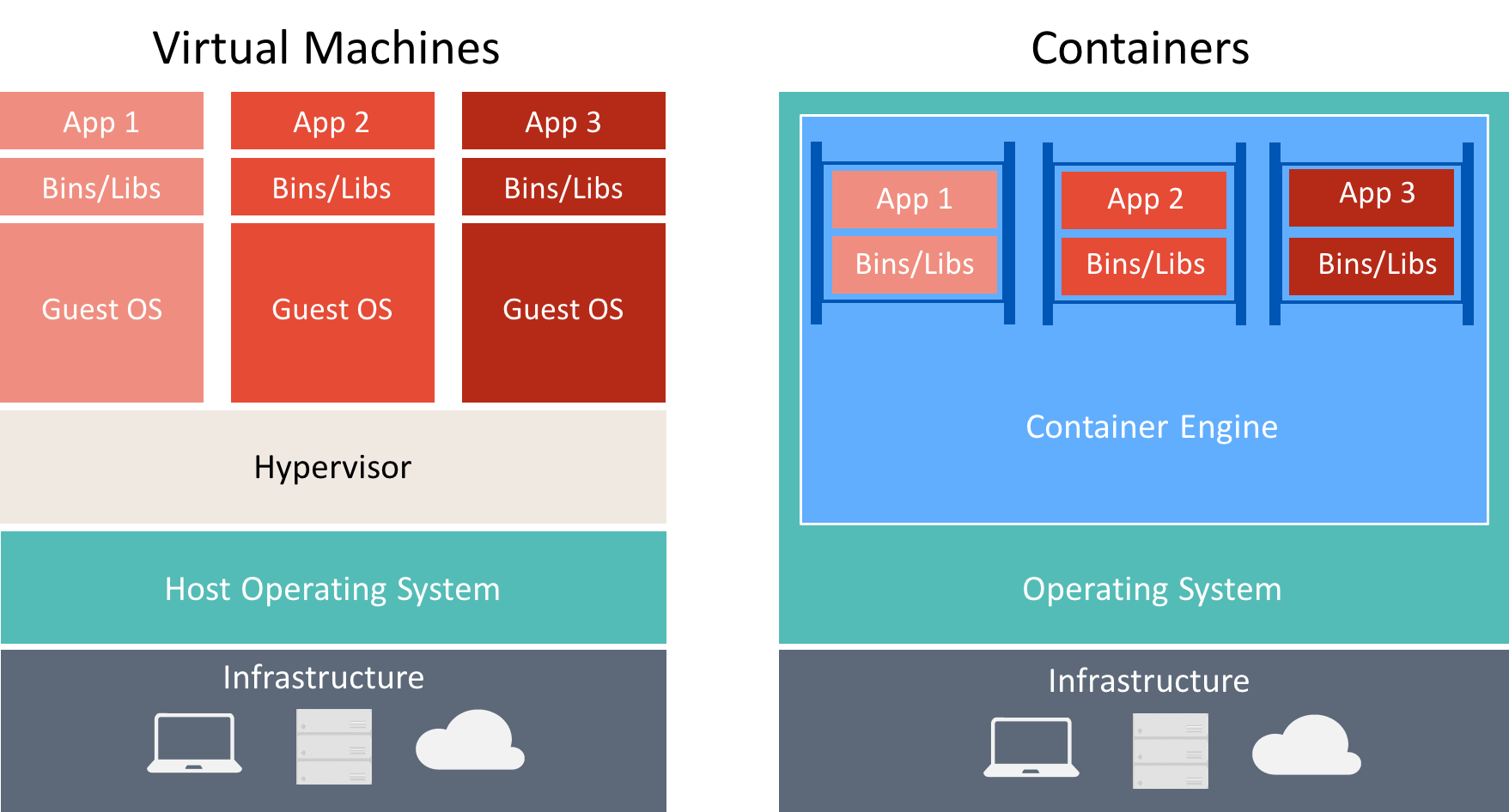
Rysunek 8–3. Porównanie maszyn wirtualnych i kontenerów
Kontener uruchamia system operacyjny, ma system plików i można uzyskać do niego dostęp za pośrednictwem sieci tak, jakby była to maszyna fizyczna lub wirtualna. Jednak technologia i pojęcia używane przez kontenery różnią się zupełnie od maszyn wirtualnych. Maszyny wirtualne obejmują aplikacje, wymagane zależności i pełny system operacyjny gościa. Kontenery obejmują aplikację i jej zależności, ale współużytkować system operacyjny z innymi kontenerami, uruchomione jako izolowane procesy w systemie operacyjnym hosta (oprócz kontenerów funkcji Hyper-V, które działają wewnątrz specjalnej maszyny wirtualnej na kontener). W związku z tym kontenery współdzielą zasoby i zwykle wymagają mniejszej ilości zasobów niż maszyny wirtualne.
Zaletą podejścia do programowania i wdrażania zorientowanego na kontenery jest wyeliminowanie większości problemów wynikających z niespójnych konfiguracji środowiska i problemów, które są z nimi związane. Ponadto kontenery umożliwiają szybkie skalowanie aplikacji w górę przez tworzenie nowych kontenerów zgodnie z potrzebami.
Kluczowe pojęcia dotyczące tworzenia kontenerów i pracy z nimi są następujące:
- Host kontenera: maszyna fizyczna lub wirtualna skonfigurowana do hostowania kontenerów. Host kontenera uruchomi co najmniej jeden kontener.
- Obraz kontenera: obraz składa się z połączenia warstwowych systemów plików skumulowanych nawzajem i jest podstawą kontenera. Obraz nie ma stanu i nigdy nie zmienia się, ponieważ jest wdrażany w różnych środowiskach.
- Kontener: kontener jest wystąpieniem środowiska uruchomieniowego obrazu.
- Obraz systemu operacyjnego kontenera: kontenery są wdrażane z obrazów. Obraz systemu operacyjnego kontenera jest pierwszą warstwą w potencjalnie wielu warstwach obrazów tworzących kontener. System operacyjny kontenera jest niezmienny i nie można go modyfikować.
- Repozytorium kontenerów: za każdym razem, gdy jest tworzony obraz kontenera, obraz i jego zależności są przechowywane w repozytorium lokalnym. Te obrazy można używać wiele razy na hoście kontenera. Obrazy kontenerów mogą być również przechowywane w rejestrze publicznym lub prywatnym, takim jak Docker Hub, dzięki czemu mogą być używane na różnych hostach kontenerów.
Przedsiębiorstwa coraz częściej wdrażają kontenery podczas implementowania aplikacji opartych na mikrousługach, a platforma Docker stała się standardową implementacją kontenerów, która została przyjęta przez większość platform oprogramowania i dostawców usług w chmurze.
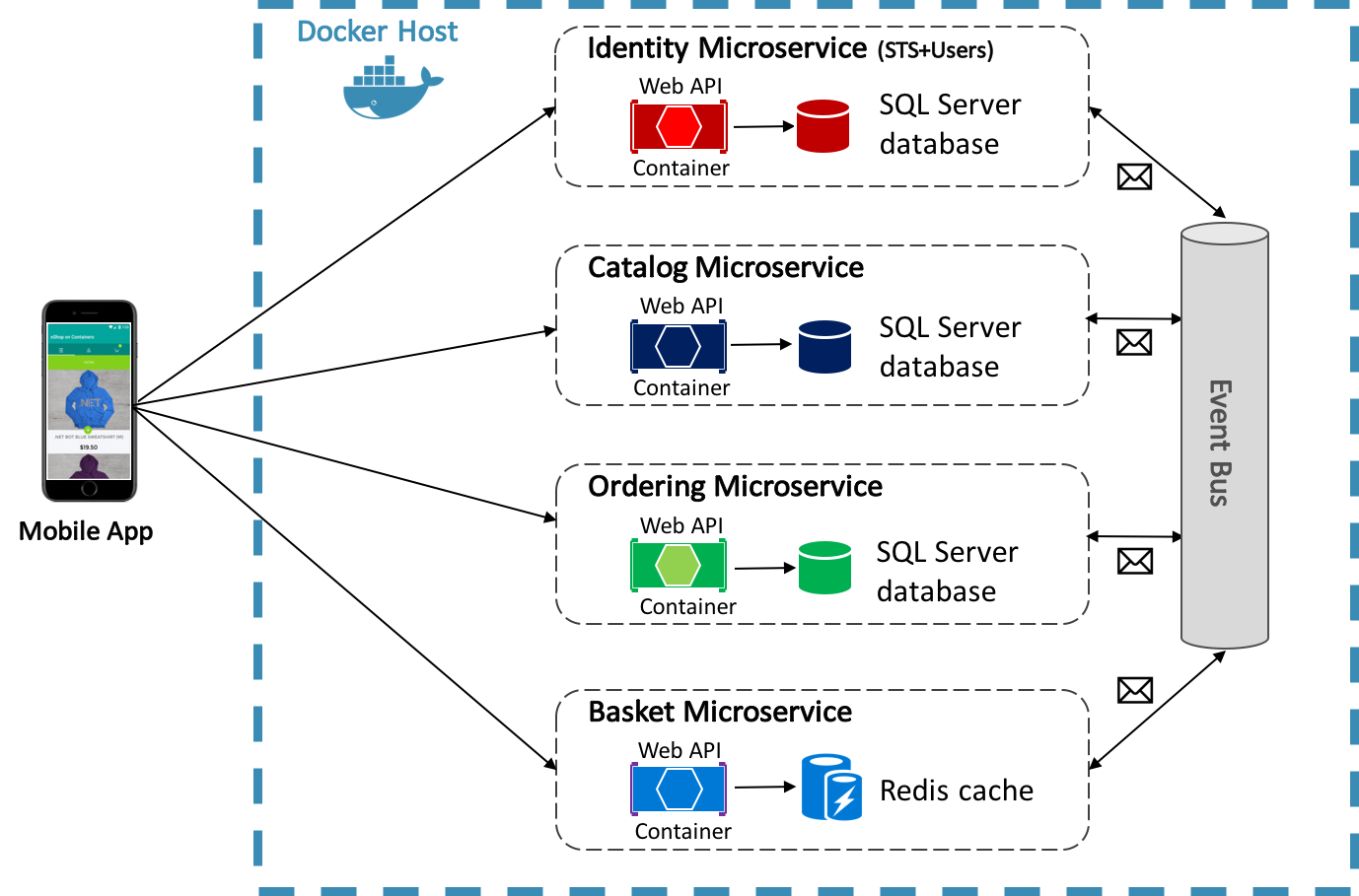
Aplikacja referencyjna eShopOnContainers używa platformy Docker do hostowania czterech konteneryzowanych mikrousług zaplecza, jak pokazano na rysunku 8–4.
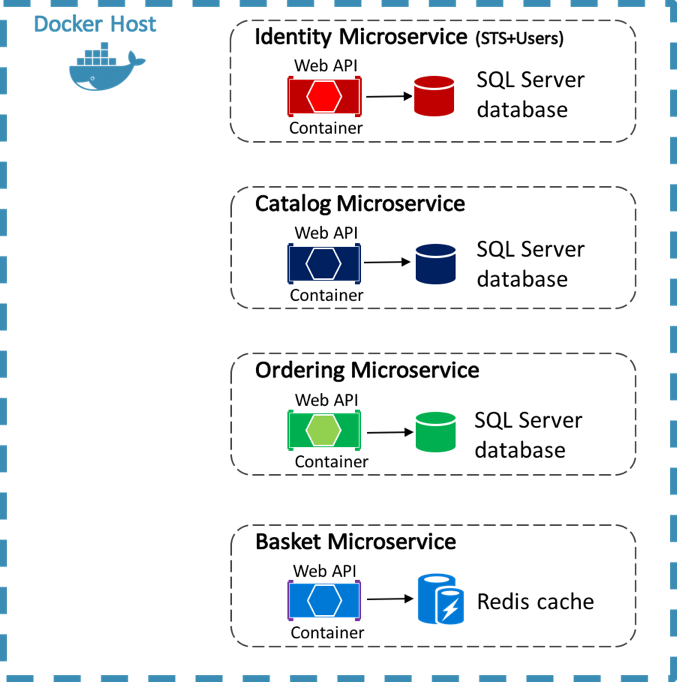
Rysunek 8–4. Mikrousługi zaplecza aplikacji referencyjnej eShopOnContainers
Architektura usług zaplecza w aplikacji referencyjnej jest rozłożona na wiele autonomicznych systemów podrzędnych w postaci współpracujących mikrousług i kontenerów. Każda mikrousługa oferuje jeden obszar funkcjonalności: usługę tożsamości, usługę katalogu, usługę zamawiania i usługę koszyka.
Każda mikrousługa ma własną bazę danych, umożliwiając jej całkowite oddzielenie od innych mikrousług. W razie potrzeby spójność między bazami danych z różnych mikrousług jest osiągana przy użyciu zdarzeń na poziomie aplikacji. Aby uzyskać więcej informacji, zobacz Komunikacja między mikrousługami.
Aby uzyskać więcej informacji na temat aplikacji referencyjnej, zobacz .NET Microservices: Architecture for Containerized .NET Applications (Mikrousługi platformy .NET: architektura konteneryzowanych aplikacji .NET).
Komunikacja między klientem a mikrousługami
Aplikacja mobilna eShopOnContainers komunikuje się z konteneryzowanymi mikrousługami zaplecza przy użyciu bezpośredniej komunikacji klient-mikrousług , która jest pokazana na rysunku 8-5.
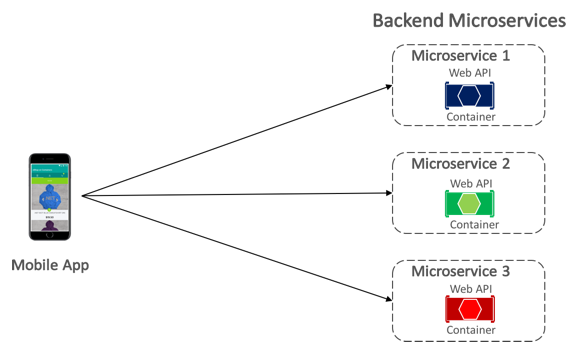
Rysunek 8–5. Bezpośrednia komunikacja między klientem a mikrousługą
Dzięki bezpośredniej komunikacji między klientem a mikrousługą aplikacja mobilna wysyła żądania do każdej mikrousługi bezpośrednio za pośrednictwem publicznego punktu końcowego z innym portem TCP na mikrousługę. W środowisku produkcyjnym punkt końcowy zazwyczaj mapuje się na moduł równoważenia obciążenia mikrousługi, który dystrybuuje żądania między dostępne wystąpienia.
Napiwek
Rozważ użycie komunikacji bramy interfejsu API. Bezpośrednia komunikacja między klientem a mikrousługą może mieć wady podczas kompilowania dużej i złożonej aplikacji opartej na mikrousłudze, ale jest to bardziej niż odpowiednie dla małej aplikacji. Podczas projektowania dużej aplikacji opartej na mikrousłudze z dziesiątkami mikrousług rozważ użycie komunikacji bramy interfejsu API. Aby uzyskać więcej informacji, zobacz .NET Microservices: Architecture for Containerized .NET Applications (Mikrousługi platformy .NET: architektura konteneryzowanych aplikacji .NET).
Komunikacja między mikrousługami
Aplikacja oparta na mikrousługach jest systemem rozproszonym, potencjalnie działającym na wielu maszynach. Każde wystąpienie usługi jest zazwyczaj procesem. W związku z tym usługi muszą korzystać z protokołu komunikacyjnego między procesami, takiego jak HTTP, TCP, Advanced Message Queuing Protocol (AMQP) lub protokoły binarne, w zależności od charakteru każdej usługi.
Dwie typowe podejścia do komunikacji między mikrousługami to komunikacja REST oparta na protokole HTTP podczas wykonywania zapytań dotyczących danych oraz uproszczone komunikaty asynchroniczne podczas komunikacji aktualizacji w wielu mikrousługach.
Komunikacja oparta na zdarzeniach asynchroniczna oparta na komunikatach ma kluczowe znaczenie podczas propagacji zmian w wielu mikrousługach. Dzięki temu mikrousługa publikuje zdarzenie, gdy wystąpi coś, co można zauważyć, na przykład w przypadku aktualizacji jednostki biznesowej. Inne mikrousługi subskrybują te zdarzenia. Następnie, gdy mikrousługa odbiera zdarzenie, aktualizuje własne jednostki biznesowe, co z kolei może prowadzić do opublikowania większej liczby zdarzeń. Ta funkcja publikowania-subskrybowania jest zwykle osiągana za pomocą magistrali zdarzeń.
Magistrala zdarzeń umożliwia komunikację między mikrousługami typu publish-subscribe bez konieczności jawnego informowania składników o sobie, jak pokazano na rysunku 8–6.
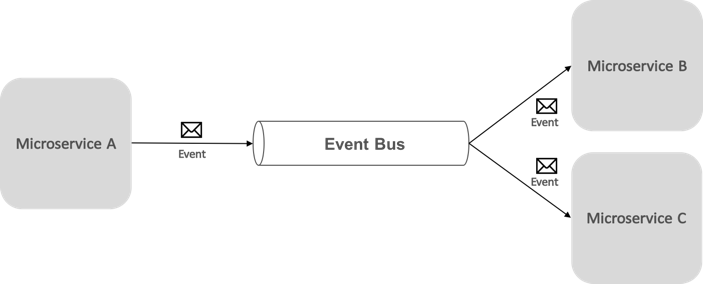
Rysunek 8–6. Publikowanie i subskrybowanie za pomocą magistrali zdarzeń
Z perspektywy aplikacji magistrala zdarzeń jest po prostu kanałem publikowania-subskrybowania udostępnianym za pośrednictwem interfejsu. Jednak sposób implementacji magistrali zdarzeń może się różnić. Na przykład implementacja magistrali zdarzeń może używać bibliotek RabbitMQ, Azure Service Bus lub innych magistrali usług, takich jak NServiceBus i MassTransit. Rysunek 8–7 przedstawia sposób użycia magistrali zdarzeń w aplikacji referencyjnej eShopOnContainers.
Rysunek 8–7. Asynchroniczna komunikacja sterowana zdarzeniami w aplikacji referencyjnej
Magistrala zdarzeń eShopOnContainers zaimplementowana przy użyciu biblioteki RabbitMQ zapewnia asynchroniczne funkcje publikowania-subskrybowania typu jeden do wielu. Oznacza to, że po opublikowaniu zdarzenia może być wielu subskrybentów nasłuchujących tego samego zdarzenia. Rysunek 8–9 ilustruje tę relację.
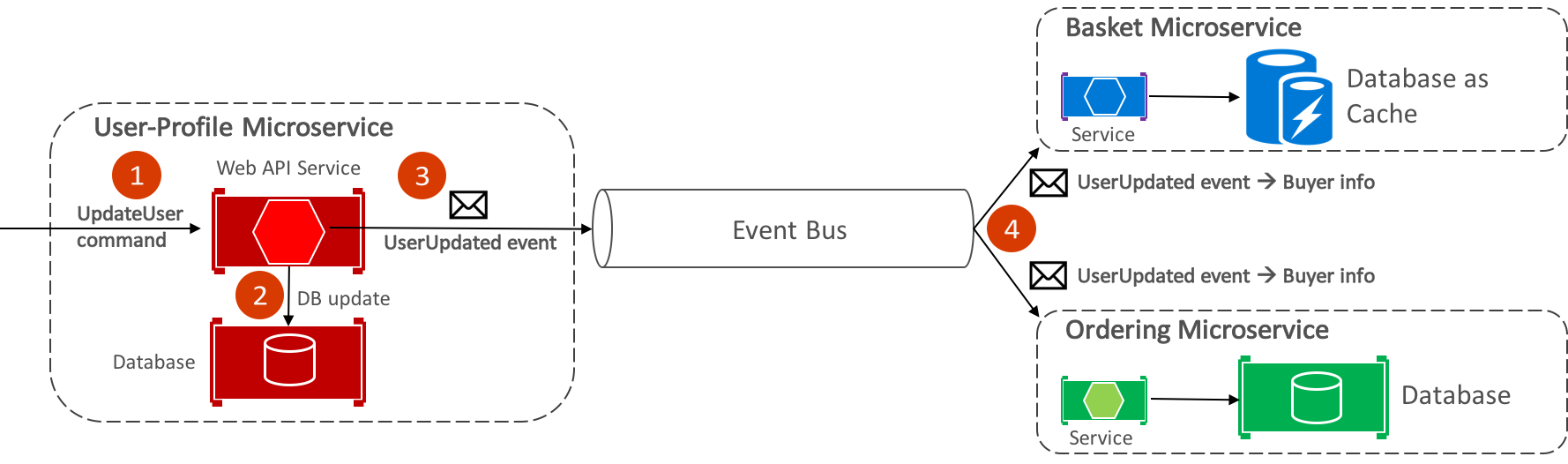
Rysunek 8–9. Komunikacja "jeden do wielu"
To podejście komunikacyjne jeden do wielu używa zdarzeń do implementowania transakcji biznesowych obejmujących wiele usług, zapewniając spójność ostateczną między usługami. Ostateczna transakcja składa się z serii kroków rozproszonych. W związku z tym gdy mikrousługa profilu użytkownika otrzymuje polecenie UpdateUser, aktualizuje szczegóły użytkownika w bazie danych i publikuje zdarzenie UserUpdated w magistrali zdarzeń. Zarówno mikrousługi koszyka, jak i mikrousługi zamawiania zasubskrybowały odbieranie tego zdarzenia, a w odpowiedzi aktualizują informacje o nabywcy w odpowiednich bazach danych.
Uwaga
Magistrala zdarzeń eShopOnContainers, zaimplementowana przy użyciu RabbitMQ, ma być używana tylko jako dowód koncepcji. W przypadku systemów produkcyjnych należy wziąć pod uwagę alternatywne implementacje magistrali zdarzeń.
Aby uzyskać informacje o implementacji magistrali zdarzeń, zobacz .NET Microservices: Architecture for Containerized .NET Applications (Mikrousługi platformy .NET: architektura konteneryzowanych aplikacji .NET).
Podsumowanie
Mikrousługi oferują podejście do tworzenia i wdrażania aplikacji, które jest odpowiednie dla wymagań dotyczących elastyczności, skalowania i niezawodności nowoczesnych aplikacji w chmurze. Jedną z głównych zalet mikrousług jest możliwość niezależnego skalowania ich w poziomie, co oznacza, że można skalować określony obszar funkcjonalny, który wymaga większej mocy obliczeniowej lub przepustowości sieci w celu obsługi zapotrzebowania, bez niepotrzebnego skalowania obszarów aplikacji, które nie mają zwiększonego zapotrzebowania.
Kontener jest izolowanym, kontrolowanym zasobem i przenośnym środowiskiem operacyjnym, w którym aplikacja może działać bez dotykania zasobów innych kontenerów lub hosta. Przedsiębiorstwa coraz częściej wdrażają kontenery podczas implementowania aplikacji opartych na mikrousługach, a platforma Docker stała się standardową implementacją kontenerów, która została przyjęta przez większość platform oprogramowania i dostawców usług w chmurze.