Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Przez Andrew Marshall, Jugal Parikh, Emre Kiciman i Ram Shankar Siva Kumar
Specjalne podziękowania dla Raul Rojas oraz AETHER Security Engineering Workstream
Listopad 2019 r.
Ten dokument jest dostarczany w ramach praktyk inżynieryjnych AETHER dla grupy roboczej sztucznej inteligencji i uzupełnia istniejące praktyki modelowania zagrożeń SDL, udostępniając nowe wskazówki dotyczące wyliczania zagrożeń i ograniczania ryzyka specyficznego dla przestrzeni sztucznej inteligencji i uczenia maszynowego. Jest ona przeznaczona do użycia jako odwołanie podczas przeglądów projektu zabezpieczeń następujących elementów:
Produkty/usługi współdziałające z usługami lub biorące zależności od usług opartych na sztucznej inteligencji/uczeniu maszynowym
Produkty/usługi tworzone za pomocą sztucznej inteligencji/uczenia maszynowego w ich rdzeniu
Tradycyjne środki zaradcze zagrożeń bezpieczeństwa są ważniejsze niż kiedykolwiek. Wymagania ustanowione przez cykl projektowania zabezpieczeń są niezbędne do ustanowienia podstawy zabezpieczeń produktu, na podstawie których opierają się te wskazówki. Niepowodzenie w rozwiązywaniu tradycyjnych zagrożeń bezpieczeństwa umożliwia ataki specyficzne dla sztucznej inteligencji/uczenia maszynowego, omówione w tym dokumencie zarówno w domenach oprogramowania, jak i w domenach fizycznych, a także czyni naruszenie bezpieczeństwa trywialnym niżej w stosie oprogramowania. Wprowadzenie do nowych zagrożeń bezpieczeństwa w tym obszarze można znaleźć w artykule Zabezpieczanie przyszłości sztucznej inteligencji i uczenia maszynowego w firmie Microsoft.
Zestawy umiejętności inżynierów ds. zabezpieczeń i analityków danych zwykle nie nakładają się na siebie. Te wskazówki umożliwiają obu dyscyplinom prowadzenie ustrukturyzowanych rozmów na temat tych nowych zagrożeń i środków zaradczych bez konieczności, aby inżynierowie ds. zabezpieczeń stawali się analitykami danych lub odwrotnie.
Ten dokument jest podzielony na dwie sekcje:
- "Najważniejsze nowe zagadnienia dotyczące modelowania zagrożeń" koncentruje się na nowych sposobach myślenia i nowych pytaniach, które należy zadać podczas modelowania zagrożeń systemów sztucznej inteligencji/uczenia maszynowego. Zarówno analitycy danych, jak i inżynierowie ds. zabezpieczeń powinni to przejrzeć, ponieważ będzie to podręcznik dyskusji na temat modelowania zagrożeń i priorytetyzacji ograniczania ryzyka.
- "Zagrożenia specyficzne dla sztucznej inteligencji/uczenia maszynowego i ich środki zaradcze" zawierają szczegółowe informacje na temat konkretnych ataków, a także konkretne kroki ograniczania ryzyka używane obecnie w celu ochrony produktów i usług firmy Microsoft przed tymi zagrożeniami. Ta sekcja jest przeznaczona głównie dla naukowców danych, którzy mogą wymagać wdrożenia specyficznych środków zaradczych przed zagrożeniami w wyniku procesu modelowania zagrożeń/przeglądu bezpieczeństwa.
Te wskazówki są zorganizowane wokół taksonomii zagrożeń związanych z uczeniem maszynowym adwersarialnych utworzonej przez Ram Shankara Sivy Kumara, Davida O’Briena, Kendrę Albert, Salome Viljoen i Jeffreya Snovera zatytułowane "Tryby awarii w uczeniu maszynowym". Aby uzyskać wskazówki dotyczące zarządzania incydentami związanymi z klasyfikacją zagrożeń bezpieczeństwa opisanych w tym dokumencie, zapoznaj się z SDL Bug Bar dla zagrożeń AI/ML. Wszystkie te dokumenty są dynamiczne i będą się rozwijać w miarę zmieniającego się krajobrazu zagrożeń.
Najważniejsze nowe zagadnienia dotyczące modelowania zagrożeń: zmiana sposobu wyświetlania granic zaufania
Załóżmy, że dochodzi do kompromisu lub zatrucia danych, zarówno tych, na których się szkolisz, jak i tych od dostawcy danych. Dowiedz się, jak wykrywać nietypowe i złośliwe wpisy danych, a także rozróżniać i odzyskiwać dane od nich
Podsumowanie
Magazyny danych szkoleniowych i systemy, które je hostują, są częścią zakresu modelowania zagrożeń. Obecnie największym zagrożeniem bezpieczeństwa w uczeniu maszynowym jest zatrucie danych ze względu na brak standardowych wykryć i środków zaradczych w tej przestrzeni, w połączeniu z zależnością od niezaufanych/nieocuchanych publicznych zestawów danych jako źródeł danych szkoleniowych. Śledzenie pochodzenia i rodowodu danych jest niezbędne do zapewnienia ich wiarygodności i uniknięcia "śmieci na wejściu, śmieci na wyjściu" w cyklu treningowym.
Pytania do zadania podczas przeglądu zabezpieczeń
Jeśli dane są zatrute lub naruszone, jak byś wiedział?
-Jakie dane telemetryczne masz, aby wykryć odchylenie w jakości danych treningowych?
Czy trenujesz z danych wejściowych dostarczonych przez użytkownika?
-Jakiego rodzaju walidację/sanityzację danych wejściowych wykonujesz na tych danych?
-Czy struktura tych danych jest udokumentowana podobnie jak arkusze danych dla zestawów danych?
W przypadku trenowania modeli z użyciem magazynów danych online, jakie kroki należy wykonać, aby zapewnić bezpieczeństwo połączenia między modelem a danymi?
-Czy mają one sposób raportowania kompromisów dla konsumentów swoich kanałów informacyjnych?
-Czy one są nawet w stanie to zrobić?
Jak poufne są dane, z których trenujesz?
-Czy katalogujesz go lub kontrolujesz dodawanie/aktualizowanie/usuwanie wpisów danych?
Czy model może wyświetlać dane poufne?
-Czy te dane zostały uzyskane za zgodą źródła?
Czy model generuje tylko wyniki niezbędne do osiągnięcia celu?
Czy model zwraca nieprzetworzone wyniki ufności lub inne bezpośrednie dane wyjściowe, które mogą być rejestrowane i zduplikowane?
Jaki jest wpływ danych treningowych odzyskanych przez atakowanie/odwrócenie modelu?
Jeśli poziom ufności danych wyjściowych modelu nagle spadnie, możesz dowiedzieć się, jak/dlaczego, a także dane, które je spowodowały?
Czy zdefiniowano dobrze sformułowane dane wejściowe dla modelu? Co robisz, aby zapewnić, że dane wejściowe spełniają ten format i co zrobić, jeśli nie?
Jeśli dane wyjściowe są nieprawidłowe, ale nie powodują zgłaszania błędów, jak byś wiedział?
Czy wiesz, czy algorytmy trenowania są odporne na niepożądane dane wejściowe na poziomie matematycznym?
Jak można poradzić sobie ze skażeniem o charakterze antagonistycznym danych treningowych?
-Czy można izolować/poddać kwarantannie niepożądanej zawartości i ponownie trenować modele, których dotyczy ten wpływ?
-Czy można wycofać/odzyskać model z poprzedniej wersji na potrzeby ponownego trenowania?
Czy korzystasz z uczenia wzmacniającego dla niezredagowanych treści publicznych?
Zacznij myśleć o rodowodzie swoich danych — gdybyś znalazł problem, czy potrafisz prześledzić jego wprowadzenie do zestawu danych? Jeśli nie, czy jest to problem?
Dowiedz się, skąd pochodzą dane szkoleniowe i zidentyfikuj normy statystyczne, aby rozpocząć zrozumienie, jak wyglądają anomalie
-Jakie elementy danych treningowych są narażone na wpływ zewnętrzny?
-Kto może współtworzyć zestawy danych, z których trenujesz?
-Jak ty zaatakowałbyś swoje źródła danych szkoleniowych, aby zaszkodzić konkurentowi?
Powiązane zagrożenia i środki zaradcze w tym dokumencie
"Zakłócenia przeciwników (wszystkie warianty)"
Zatrucie danych (wszystkie warianty)
Przykładowe ataki
Zmuszanie, by nieszkodliwe wiadomości e-mail były sklasyfikowane jako spam lub powodowanie, że złośliwa wiadomość pozostanie niewykryta
Dane wejściowe spreparowane przez osobę atakującą, które zmniejszają poziom ufności prawidłowej klasyfikacji, szczególnie w scenariuszach o wysokiej konsekwencji
Atakujący losowo wprowadza szum do danych źródłowych, aby zmniejszyć szanse na prawidłową klasyfikację w przyszłości, co skutecznie osłabia model.
Skażenie danych treningowych w celu wymuszenia błędnej klasyfikacji wybranych punktów danych, co powoduje, że określone działania są podejmowane lub pomijane przez system
Identyfikowanie akcji, które mogą być podejmowane przez model lub produkt/usługę, co może spowodować szkodę klienta w trybie online lub w domenie fizycznej
Podsumowanie
Pozostawione bez ograniczeń, ataki na systemy sztucznej inteligencji/uczenia maszynowego mogą przeniknąć do świata fizycznego. Każdy scenariusz, który można zmanipulować, aby psychicznie lub fizycznie zaszkodzić użytkownikom, stanowi katastrofalne zagrożenie dla produktu lub usługi. Obejmuje to wszelkie poufne dane dotyczące klientów wykorzystywane do trenowania i podejmowania decyzji projektowych, które mogą prowadzić do wycieku tych prywatnych danych.
Pytania do zadania podczas przeglądu zabezpieczeń
Czy trenujesz przy użyciu przykładów atakujących? Jaki wpływ mają na dane wyjściowe modelu w domenie fizycznej?
Jak wygląda trolling w kontekście Twojego produktu/usługi? Jak można wykrywać i reagować na nie?
Co należy zrobić, aby model zwrócił wynik, który sprawi, że usługa błędnie odmówi dostępu uprawnionym użytkownikom?
Jaki jest wpływ kopiowania/kradzieży modelu?
Czy model może służyć do wnioskowania o członkostwie pojedynczej osoby w określonej grupie, czy po prostu w danych treningowych?
Czy atakujący może spowodować szkody na reputacji lub reakcję PR wobec Twojego produktu, zmuszając go do wykonywania określonych działań?
Jak radzisz sobie z prawidłowo sformatowanymi, ale wyraźnie stronniczymi danymi, takimi jak od internetowych trolli?
Czy dla każdego sposobu interakcji z modelem lub zadawania zapytań można zbadać tę metodę w celu ujawnienia danych treningowych lub funkcjonalności modelu?
Powiązane zagrożenia i środki zaradcze w tym dokumencie
Wnioskowanie członkostwa
Inwersja modelu
Kradzież modelu
Przykładowe ataki
Rekonstrukcja i wyodrębnianie danych treningowych przez wielokrotne wykonywanie zapytań dotyczących modelu w celu uzyskania maksymalnych wyników ufności
Duplikowanie samego modelu przez wyczerpujące dopasowywanie zapytań/odpowiedzi
Wykonywanie zapytań dotyczących modelu w sposób, który ujawnia konkretny element danych prywatnych, został uwzględniony w zestawie treningowym
Samochód samojeżdżący jest oszukiwany, aby ignorować znaki stop i światła drogowe.
Boty konwersacyjne manipulowane do trollowania łagodnych użytkowników
Zidentyfikuj wszystkie źródła zależności sztucznej inteligencji/uczenia maszynowego oraz warstwy prezentacji frontendowej w łańcuchu dostaw danych/modelu.
Podsumowanie
Wiele ataków na sztuczną inteligencję oraz Uczenie Maszynowe rozpoczyna się od wiarygodnego dostępu do interfejsów API, które są udostępniane, aby umożliwić dostęp do zapytań do modelu. Ze względu na bogate źródła danych i rozbudowane doświadczenia użytkowników, uwierzytelniony, ale "nieodpowiedni" (jest tutaj strefa niejasności) dostęp stron trzecich do swoich modeli stanowi ryzyko ze względu na możliwość działania jako warstwa prezentacyjna nad usługą dostarczaną przez firmę Microsoft.
Pytania do zadania podczas przeglądu zabezpieczeń
Którzy klienci/partnerzy są uwierzytelniani w celu uzyskania dostępu do interfejsów API modelu lub usługi?
-Czy mogą pełnić rolę warstwy prezentacyjnej dla twojej usługi?
-Czy można natychmiast odwołać dostęp w przypadku naruszenia zabezpieczeń?
-Jaka jest strategia odzyskiwania danych w przypadku złośliwego użycia usługi lub zależności systemowych?
Czy strona trzecia może zbudować fasadę wokół twojego modelu, aby zastosować go w innym celu i zaszkodzić firmie Microsoft lub jej klientom?
Czy klienci udostępniają ci dane szkoleniowe bezpośrednio?
-Jak zabezpieczyć te dane?
-Co zrobić, jeśli jest złośliwy, a Twoja usługa jest celem?
Jak wygląda tutaj wynik fałszywie dodatni? Jaki jest wpływ wartości fałszywie ujemnej?
Czy można śledzić i mierzyć odchylenie wyników prawdziwie dodatnich i fałszywie dodatnich w wielu modelach?
Jakiego rodzaju dane telemetryczne są potrzebne, aby udowodnić wiarygodność danych wyjściowych modelu klientom?
Zidentyfikuj wszystkie zależności od stron trzecich w łańcuchu dostaw danych do uczenia maszynowego/treningu – nie tylko oprogramowanie open source, ale także dostawców danych.
-Dlaczego ich używasz i jak zweryfikować ich wiarygodność?
Czy używasz wstępnie utworzonych modeli od podmiotów trzecich lub przesyłasz dane szkoleniowe do dostawców usług MLaaS?
Spis wiadomości na temat ataków na podobne produkty/usługi. Zrozumienie, że wiele zagrożeń związanych ze sztuczną inteligencją i uczeniem maszynowym przenosi się między typami modeli, jaki wpływ te ataki będą miały na własne produkty?
Powiązane zagrożenia i środki zaradcze w tym dokumencie
Reprogramowanie sieci neuronowej
Przykłady antagonistyczne w fizycznej domenie
Złośliwi dostawcy uczenia maszynowego odzyskują dane szkoleniowe
Atakowanie łańcucha dostaw uczenia maszynowego
Model z ukrytym dostępem
Naruszone zależności specyficzne dla uczenia maszynowego
Przykładowe ataki
Złośliwy dostawca usługi MLaaS instaluje trojany w modelu z konkretnym obejściem
Atakujący klient odnajduje lukę w zabezpieczeniach w typowych używanych zależnościach systemu operacyjnego, przekazuje spreparowany ładunek danych szkoleniowych w celu naruszenia zabezpieczeń usługi
Bez skrupułów partner korzysta z interfejsów API rozpoznawania twarzy i tworzy warstwę prezentacyjną wykorzystującą Twoją usługę, aby generować Deep Fakes.
Zagrożenia specyficzne dla sztucznej inteligencji/uczenia maszynowego i ich środki zaradcze
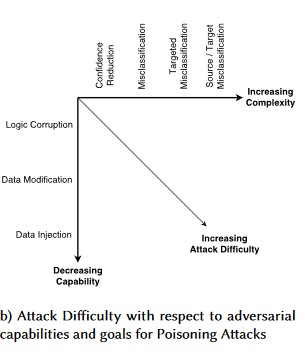
#1: Adwersarialna Perturbacja
Opis
W przypadku ataków w stylu perturbacji atakujący niewidzialnie modyfikuje zapytanie, aby uzyskać żądaną odpowiedź z modelu wdrożonego w środowisku produkcyjnym[1]. Jest to naruszenie integralności danych wejściowych modelu, które prowadzi do ataków typu rozmytego, w przypadku gdy wynik końcowy nie musi być naruszeniem dostępu lub EOP, ale zamiast tego narusza wydajność klasyfikacji modelu. Może to być również manifestowane przez trolle przy użyciu niektórych słów docelowych w sposób, że sztuczna inteligencja będzie je blokować, skutecznie odmawiając usług uprawnionym użytkownikom o nazwie pasującej do słowa "zakazane".
 [24]
[24]
Wariant #1a: Ukierunkowana błędna klasyfikacja
W takim przypadku osoby atakujące generują przykład, który nie znajduje się w klasie wejściowej klasyfikatora docelowego, ale zostaje sklasyfikowany przez model jako określoną klasę danych wejściowych. Niepożądany przykład może wydawać się losowym szumem dla ludzkich oczu, ale osoby atakujące mają pewną wiedzę na temat docelowego systemu uczenia maszynowego w celu wygenerowania białego szumu, który nie jest losowy, ale wykorzystuje niektóre konkretne aspekty modelu docelowego. Przeciwnik podaje próbkę danych wejściowych, która nie jest wiarygodną próbką, ale docelowy system klasyfikuje go jako wiarygodną klasę.
Przykłady
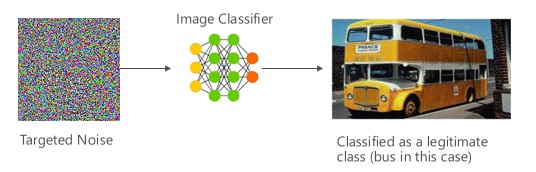 [6]
[6]
Środki łagodzące
Wzmacnianie odporności przeciwnych przy użyciu ufności modelu wywołanej przez trening przeciwny [19]: Autorzy proponują Wysoce Pewny Bliski Sąsiad (HCNN), jako platformę łączącą informacje o ufności i wyszukiwanie najbliższych sąsiadów, aby wzmocnić odporność przeciwną modelu bazowego. Może to pomóc w odróżnieniu pomiędzy prawidłowymi i nieprawidłowymi przewidywaniami modelu w sąsiedztwie punktu próbkowanego z rozkładu bazowego treningu.
Analiza przyczynowa oparta na autorstwie [20]: Autorzy badają związek między odpornością na niepożądane zakłócenia i wyjaśnieniem opartym na autorstwie indywidualnych decyzji generowanych przez modele uczenia maszynowego. Zgłaszają, że niepożądane dane wejściowe nie są niezawodne w przestrzeni przypisania, czyli maskowanie kilku funkcji o wysokim przypisaniu prowadzi do zmiany niezdecydowania modelu uczenia maszynowego na przykładach niepożądanych. Dla porównania, naturalne dane wejściowe są odporne w przestrzeni przypisywania.
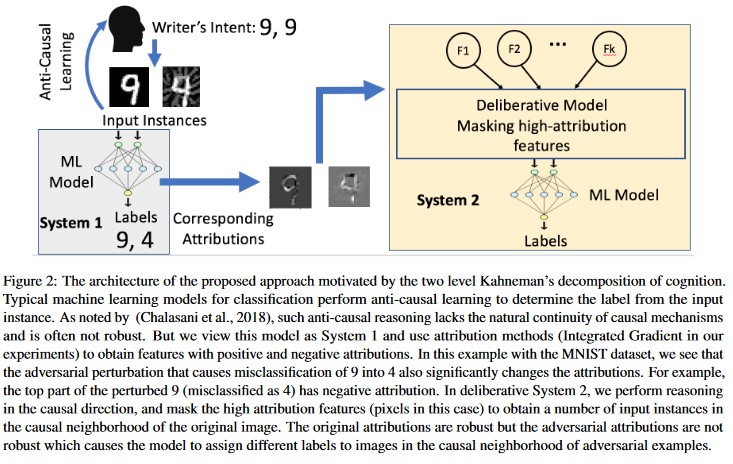 [20]
[20]
Te podejścia mogą sprawić, że modele uczenia maszynowego będą bardziej odporne na ataki niepożądane, ponieważ oszukiwanie tego dwuwarstwowego systemu poznania wymaga nie tylko ataku na oryginalny model, ale także zapewnienie, że przypisanie wygenerowane dla przykładu niepożądanego jest podobne do oryginalnych przykładów. Oba systemy muszą zostać jednocześnie naruszone w celu pomyślnego ataku niepożądanego.
Tradycyjne paralele
Zdalne uzyskanie podwyższonych uprawnień, ponieważ atakujący ma teraz kontrolę nad modelem
Ciężkość
Krytyczny
Wariant 1b: Błędne przypisanie źródła lub celu
Jest to próba osoby atakującej, aby zmusić model do zwrócenia żądanej etykiety dla przedstawionych danych wejściowych. Zwykle wymusza to, aby model zwracał wynik fałszywie dodatni lub fałszywie ujemny. Końcowym rezultatem jest subtelne przejęcie kontroli nad dokładnością klasyfikacji modelu, dzięki czemu atakujący może celowo wywołać określone obejścia.
Chociaż ten atak ma znaczący szkodliwy wpływ na dokładność klasyfikacji, może być również bardziej czasochłonny do przeprowadzenia, ponieważ przeciwnik musi nie tylko manipulować danymi źródłowymi, aby nie były już poprawnie oznaczone, ale także oznaczone konkretnie pożądaną fałszywą etykietą. Te ataki często obejmują wiele kroków/prób wymuszenia błędnej klasyfikacji [3]. Jeśli model jest podatny na ataki uczenia transferowego, które wymuszają nieprawidłową klasyfikację celową, nie może istnieć zauważalny ślad ruchu atakującego, ponieważ ataki sondowania mogą być przeprowadzane w trybie offline.
Przykłady
Powodowanie, że łagodne wiadomości e-mail są klasyfikowane jako spam, lub sprawianie, że złośliwe przykłady pozostają niewykryte. Są one również nazywane uchylaniem się od modelu lub atakami naśladującymi.
Środki łagodzące
Reaktywne/defensywne akcje wykrywania
- Zaimplementuj minimalny próg czasu między wywołaniami interfejsu API dostarczającym wyniki klasyfikacji. Spowalnia to wieloetapowe testowanie ataków, zwiększając całkowity czas wymagany do znalezienia perturbacji sukcesu.
Działania proaktywne/ochronne
Odszumianie cech w celu poprawy odporności na ataki [22]: Autorzy opracowują nową architekturę sieci, która zwiększa odporność na ataki przez odszumianie cech. W szczególności, sieci zawierają bloki, które redukują szum cech przy użyciu metod nielokalnych lub innych filtrów; całe sieci są trenowane od końca do końca. W połączeniu ze szkoleniem z przeciwnikami, sieci odszumiające cechy znacznie poprawiają najnowocześniejszą odporność na ataki zarówno w przypadku ataków białoskrzynkowych, jak i czarnoskrzynkowych.
Trening antagonistyczny i regularyzacja: trenowanie z użyciem znanych próbek antagonistycznych w celu budowania odporności i solidności przeciwko złośliwym danym wejściowym. Można to również postrzegać jako formę regularizacji, która penalizuje normę gradientów wejściowych i sprawia, że funkcja przewidywania klasyfikatora staje się bardziej gładka, co zwiększa margines wejściowy. Obejmuje to prawidłowe klasyfikacje z niższymi współczynnikami ufności.
Zainwestuj w opracowywanie klasyfikacji monotonicznej z wyborem funkcji monotonicznych. Gwarantuje to, że przeciwnik nie będzie mógł uniknąć klasyfikatora przez po prostu dodanie cech z klasy ujemnej [13].
Funkcja ściskania [18] może służyć do wzmacniania zabezpieczeń modeli sieci DNN przez wykrywanie niepożądanych przykładów. Zmniejsza to miejsce wyszukiwania dostępne dla przeciwnika przez łączenie próbek, które odpowiadają wielu różnym wektorom cech w oryginalnej przestrzeni w pojedynczej próbce. Porównując przewidywania modelu DNN na podstawie oryginalnych danych wejściowych z wyciśniętymi danymi wejściowymi, wyciskanie cech może pomóc w wykrywaniu przykładów atakujących. Jeśli oryginalne i skompresowane przykłady generują znacznie różne dane wyjściowe z modelu, dane wejściowe mogą być wrogie. Mierząc niezgodę między przewidywaniami i wybierając wartość progową, system może wygenerować poprawne przewidywanie dla uzasadnionych przykładów i odrzucić niepożądane dane wejściowe.

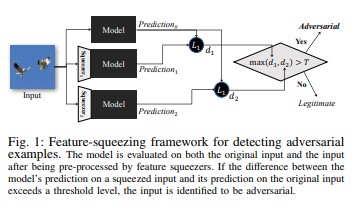 [18]
[18]Certyfikowane zabezpieczenia przed przykładami atakującymi [22]: Autorzy proponują metodę opartą na relaksacji półokreślonej, która generuje certyfikat stwierdzający, że dla danej sieci i danych testowych żaden atak nie może wymusić przekroczenia określonej wartości. Po drugie, ponieważ ten certyfikat jest różnicowalny, autorzy wspólnie optymalizują go wraz z parametrami sieci, zapewniając adaptacyjny regularyzator, który wzmacnia odporność na wszystkie ataki.
Akcje odpowiedzi
- Wystawiaj alerty dotyczące wyników klasyfikacji z wysoką wariancją między klasyfikatorami, zwłaszcza jeśli z jednego użytkownika lub małej grupy użytkowników.
Tradycyjne paralele
Zdalne podniesienie uprawnień
Ciężkość
Krytyczny
Wariant #1c: losowa błędna klasyfikacja
Jest to specjalna odmiana, w której klasyfikacja docelowa osoby atakującej może być niczym innym niż legalna klasyfikacja źródłowa. Atak zazwyczaj polega na losowym wstrzyknięciu szumu do danych źródłowych będących w trakcie klasyfikacji, aby zmniejszyć prawdopodobieństwo używania prawidłowej klasyfikacji w przyszłości [3].
Przykłady
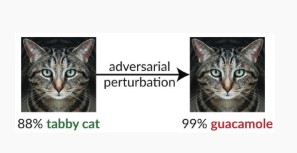
Środki łagodzące
Taki sam jak wariant 1a.
Tradycyjne paralele
Nietrwale odmowa usługi
Ciężkość
Ważne
Wariant #1d: Redukcja Pewności
Osoba atakująca może tworzyć dane wejściowe, aby zmniejszyć poziom ufności prawidłowej klasyfikacji, szczególnie w scenariuszach o wysokiej konsekwencji. Może to również mieć postać dużej liczby wyników fałszywie dodatnich mających na celu przeciążenie administratorów lub systemów monitorowania fałszywymi alertami nie do odróżnienia od wiarygodnych alertów [3].
Przykłady

Środki łagodzące
- Oprócz akcji omówionych w Wariancie #1a, można stosować ograniczanie zdarzeń w celu zmniejszenia liczby alertów z jednego źródła.
Tradycyjne paralele
Nietrwale odmowa usługi
Ciężkość
Ważne
#2a ukierunkowane zatrucie danych
Opis
Celem osoby atakującej jest skażenia modelu maszyny wygenerowanego w fazie trenowania, dzięki czemu przewidywania dotyczące nowych danych zostaną zmodyfikowane w fazie testowania[1]. W przypadku ataków zatrucia ukierunkowanego osoba atakująca chce błędnie sklasyfikować konkretne przykłady, aby spowodować, że konkretne działania zostaną podjęte lub pominięte.
Przykłady
Przesyłanie oprogramowania AV jako złośliwego oprogramowania w celu wymuszenia błędnej klasyfikacji jako złośliwego i wyeliminowania użycia docelowego oprogramowania AV w systemach klienckich.
Środki łagodzące
Zdefiniuj czujniki anomalii, aby codziennie monitorować rozkład danych i alarmować w przypadku odchyleń.
-Codzienne mierzenie zmienności danych treningowych, dane telemetryczne dotyczące odchylenia/dryfu
Sprawdzanie poprawności danych wejściowych, zarówno sanityzacja, jak i weryfikacja integralności
Zatrucie wprowadza anomalne próbki treningowe. Dwie główne strategie przeciwdziałania temu zagrożeniu:
-Sanityzacja danych/ walidacja: usuwanie zatrutych próbek z danych szkoleniowych -Bagging w celu walki z atakami zatruwania [14]
-Odrzuć na- obronaNegative-Impact (RONI) [15]
-Niezawodne uczenie: wybierz algorytmy uczenia, które są niezawodne w obecności próbek zatrucia.
-Jedno z takich podejść zostało opisane w [21], gdzie autorzy rozwiązują problem zanieczyszczenia danych w dwóch krokach: 1) wprowadzając nową niezawodną metodę faktoryzacji macierzy w celu odzyskania prawdziwej podprzestrzeni oraz 2) nowatorską niezawodną regresję głównych składowych w celu przycinania przykładów atakujących na podstawie bazy odzyskanej w kroku (1). Scharakteryzują niezbędne i wystarczające warunki pomyślnego odzyskania prawdziwej podprzestrzeni i przedstawiają miarę oczekiwanej straty przewidywania w porównaniu z wartością rzeczywistą.
Tradycyjne paralele
Host trojański, na którym osoba atakująca utrzymuje się w sieci. Dane trenowania lub konfiguracji są zagrożone i są wykorzystywane/zaufane podczas tworzenia modelu.
Ciężkość
Krytyczny
#2b masowe zatrucie danych
Opis
Celem jest zrujnować jakość/integralność zaatakowanego zestawu danych. Wiele zestawów danych jest publicznych/niezaufanych/nieuprawnionych, dlatego stwarza to dodatkowe obawy dotyczące możliwości wykrycia takich naruszeń integralności danych w pierwszej kolejności. Szkolenie z użyciem nieświadomie naruszonych danych prowadzi do sytuacji, w której niepoprawne dane wejściowe dają niepoprawne wyniki. Po wykryciu należy ocenić zakres danych, które zostały naruszone, oraz przeprowadzić kwarantannę i ponownie trenować.
Przykłady
Firma wyciąga dane z dobrze znanej i zaufanej witryny internetowej, aby uzyskać dane do kontraktów terminowych na ropę naftową w celu wytrenowania modeli. Witryna internetowa dostawcy danych zostanie następnie naruszona przez atak polegający na wstrzyknięciu kodu SQL. Osoba atakująca może zatruć zestaw danych, a trenowany model nie ma pojęcia, że dane są skażone.
Środki łagodzące
Taki sam jak wariant 2a.
Tradycyjne paralele
Uwierzytelniona odmowa usługi względem zasobu o wysokiej wartości
Ciężkość
Ważne
#3 Ataki inwersji modelu
Opis
Prywatne funkcje używane w modelach uczenia maszynowego można odzyskać [1]. Obejmuje to odtworzenie prywatnych danych treningowych, do których atakujący nie ma dostępu. Znane również jako ataki wspinaczkowe w społeczności biometrycznej [16, 17] Jest to realizowane przez znalezienie danych wejściowych, które maksymalizują zwrócony poziom pewności, pod warunkiem, że klasyfikacja pasuje do celu [4].
Przykłady
 [4]
[4]
Środki łagodzące
Interfejsy do modeli wytrenowanych z poufnych danych wymagają silnej kontroli dostępu.
Zapytania dotyczące limitu szybkości dozwolone przez model
Zaimplementuj mechanizmy zabezpieczające między użytkownikami/osobami wywołującymi i rzeczywistym modelem, wykonując walidację danych wejściowych dla wszystkich proponowanych zapytań, odrzucając wszelkie niezgodne elementy i zwracając jedynie niezbędną ilość informacji potrzebną do użyteczności.
Tradycyjne paralele
Ukierunkowane, ukrywane ujawnienie informacji
Ciężkość
Domyślnie jest to uznane za ważne zgodnie z standardowym paskiem błędów SDL, ale wyodrębnienie danych poufnych lub danych osobowych podniosłoby to do poziomu krytycznego.
Atak inferencji członkostwa #4
Opis
Osoba atakująca może określić, czy dany rekord danych był częścią zestawu danych trenowania modelu, czy nie[1]. Naukowcy byli w stanie przewidzieć główną procedurę pacjenta (np. operację, którą przeszedł pacjent) na podstawie atrybutów (np. wiek, płeć, szpital) [1].
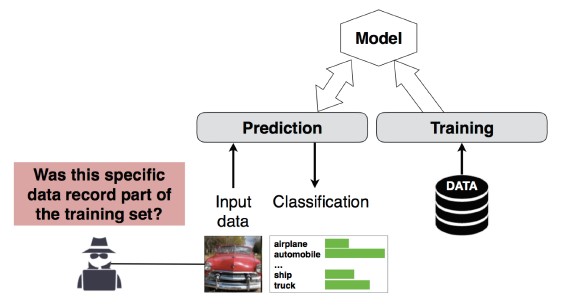 [12]
[12]
Środki łagodzące
Badania przedstawiające rentowność tego ataku wskazują, że prywatność różnicowa [4, 9] byłaby skutecznym ograniczeniem ryzyka. Jest to nadal rodząca się dziedzina w firmie Microsoft i AETHER Security Engineering zaleca inwestowanie w badania w celu rozwijania kompetencji w tej dziedzinie. Te badania musiałyby wyliczyć możliwości Prywatności Różnicowej i ocenić ich praktyczną skuteczność jako środki zaradcze, a następnie zaprojektować sposoby dziedziczenia tych obron w sposób przejrzysty dla naszych platformy usług online, podobnie jak kompilowanie kodu w programie Visual Studio daje on-by— domyślne ustawienia bezpieczeństwa, które są przejrzyste dla deweloperów i użytkowników.
Użycie upuszczania neuronów i warstw modelowych może być skutecznym rozwiązaniem w pewnym zakresie. Użycie odrzucania neuronów nie tylko zwiększa odporność sieci neuronowej na ten atak, ale także poprawia wydajność modelu [4].
Tradycyjne paralele
Prywatność danych. Wnioskowanie jest wykonywane na temat włączenia punktu danych do zestawu treningowego, ale same dane szkoleniowe nie są ujawniane
Ciężkość
Jest to problem z prywatnością, a nie problem z zabezpieczeniami. Ten problem został rozwiązany w wytycznych dotyczących modelowania zagrożeń, ponieważ domeny nakładają się na siebie, ale każda odpowiedź w tym miejscu byłaby oparta na ochronie prywatności, a nie zabezpieczeniach.
Kradzież modelu #5
Opis
Osoby atakujące ponownie tworzą bazowy model, poprzez zadawanie legalnych zapytań dotyczących modelu. Funkcjonalność nowego modelu jest taka sama jak w przypadku modelu bazowego[1]. Po ponownym utworzeniu modelu można go odwrócić w celu odzyskania informacji o cechach lub dokonywania wniosków na podstawie danych treningowych.
Rozwiązywanie równań — w przypadku modelu zwracającego prawdopodobieństwa klas za pośrednictwem danych wyjściowych interfejsu API osoba atakująca może utworzyć zapytania w celu określenia nieznanych zmiennych w modelu.
Znajdowanie ścieżki — atak wykorzystujący specyfikę interfejsu API w celu wyodrębnienia "decyzji" podjętych przez drzewo podczas klasyfikowania danych wejściowych [7].
Atak z możliwością przeniesienia — przeciwnik może wytrenować model lokalny, prawdopodobnie poprzez wydawanie zapytań przewidywania do modelu docelowego, i użyć go do tworzenia przykładów kontratakujących, które przenoszą się do modelu docelowego [8]. Jeśli Twój model zostanie wyodrębniony i okaże się podatny na ataki typu wejścia adwersaryjnego, nowe ataki na wdrożony model produkcyjny mogą być opracowane całkowicie offline przez atakującego, który wyodrębnił kopię modelu.
Przykłady
W ustawieniach, w których model uczenia maszynowego służy do wykrywania niepożądanych zachowań, takich jak identyfikacja spamu, klasyfikacji złośliwego oprogramowania i wykrywania anomalii w sieci, wyodrębnianie modelu może ułatwić ataki uchylające się od opodatkowania [7].
Środki łagodzące
Działania proaktywne/ochronne
Zminimalizuj lub zaciemniaj szczegóły zwrócone w interfejsach API przewidywania, zachowując jednocześnie ich użyteczność dla "uczciwych" aplikacji [7].
Zdefiniuj dobrze sformułowane zapytanie dla danych wejściowych modelu i zwraca tylko wyniki w odpowiedzi na ukończone, dobrze sformułowane dane wejściowe pasujące do tego formatu.
Zwracane wartości ufności są zaokrąglone. Większość prawdziwych rozmówców nie potrzebuje dokładności do wielu miejsc dziesiętnych.
Tradycyjne paralele
Nieautoryzowane manipulowanie danymi systemowymi tylko do odczytu, ukierunkowane ujawnienie cennych informacji?
Ciężkość
Ważne w modelach związanych z bezpieczeństwem, umiarkowane w przeciwnym razie
#6 Reprogramowanie sieci neuronowej
Opis
Za pomocą specjalnie spreparowanego zapytania od przeciwnika systemy uczenia maszynowego można przeprogramować do zadania, które odbiega od oryginalnej intencji twórcy [1].
Przykłady
Słabe mechanizmy kontroli dostępu w interfejsie API rozpoznawania twarzy, dzięki czemu strony trzecie mogą uwzględniać w aplikacjach mających na celu szkodę dla klientów firmy Microsoft, takich jak generator głębokich fałszerstw.
Środki łagodzące
Silne wzajemne uwierzytelnianie klient-serwer i kontrola dostępu do interfejsów modelu
Usuwanie kont przestępczych.
Identyfikowanie i wymuszanie umowy dotyczącej poziomu usług dla interfejsów API. Ustal akceptowalny czas rozwiązania problemu po zgłoszeniu i upewnij się, że problem nie jest już ponownie rozwiązywany po wygaśnięciu umowy SLA.
Tradycyjne paralele
Jest to scenariusz nadużyć. Jest mniej prawdopodobne, że otworzysz zdarzenie zabezpieczeń w takiej sytuacji, niż że po prostu wyłączysz konto sprawcy.
Ciężkość
Od ważnego do krytycznego
#7 Przykład niepożądany w domenie fizycznej (bity-atomy>)
Opis
Przykład przeciwny to dane wejściowe/zapytanie od złośliwej jednostki, przesłane wyłącznie w celu wprowadzenia w błąd systemu uczenia maszynowego [1]
Przykłady
Te przykłady mogą manifestować w domenie fizycznej, jak samochód samojeżdżący jest oszukany do uruchamiania znaku zatrzymania z powodu określonego koloru światła (niepożądanych danych wejściowych) świeci na znaku zatrzymania, zmuszając system rozpoznawania obrazów, aby nie widział już znaku zatrzymania jako znak zatrzymania.
Tradycyjne paralele
Podniesienie uprawnień, zdalne wykonywanie kodu
Środki łagodzące
Te ataki manifestują się, ponieważ problemy w warstwie uczenia maszynowego (warstwa danych i algorytmu poniżej procesu decyzyjnego opartego na sztucznej inteligencji) nie zostały rozwiązane. Podobnie jak w przypadku dowolnego innego oprogramowania *lub* systemu fizycznego, warstwa poniżej celu może być zawsze atakowana za pośrednictwem tradycyjnych wektorów. W związku z tym tradycyjne rozwiązania w zakresie zabezpieczeń są ważniejsze niż kiedykolwiek, zwłaszcza w przypadku warstwy nieimigrowanych luk w zabezpieczeniach (warstwy danych/algo) używanych między sztuczną inteligencją a tradycyjnym oprogramowaniem.
Ciężkość
Krytyczny
#8 Złośliwi dostawcy uczenia maszynowego, którzy mogą odzyskać dane szkoleniowe
Opis
Złośliwy dostawca przedstawia algorytm z celowo wbudowanymi lukami, w którym odzyskiwane są prywatne dane szkoleniowe. Byli w stanie zrekonstruować twarze i teksty, biorąc pod uwagę sam model.
Tradycyjne paralele
Ukierunkowane ujawnienie informacji
Środki łagodzące
Badania przedstawiające rentowność tego ataku wskazują, że szyfrowanie homomorficzne byłoby skutecznym ograniczeniem ryzyka. Jest to obszar z niewielkimi bieżącymi inwestycjami w firmie Microsoft, a AETHER Security Engineering zaleca budowanie wiedzy poprzez inwestycje w badania w tej dziedzinie. Badania te musiałyby wyliczyć zestawy szyfrowania homomorficznego i ocenić ich praktyczną skuteczność jako środki zaradcze w obliczu złośliwych dostawców uczenia maszynowego jako usługi.
Ciężkość
Ważne, jeśli dane są danymi PII, w przeciwnym razie umiarkowane
#9 Atakowanie łańcucha dostaw uczenia maszynowego
Opis
Ze względu na duże zasoby (dane i obliczenia) wymagane do trenowania algorytmów, bieżącą praktyką jest ponowne użycie modeli wytrenowanych przez duże korporacje i nieznaczne zmodyfikowanie ich pod kątem zadań (np. ResNet jest popularnym modelem rozpoznawania obrazów od firmy Microsoft). Te modely są wyselekcjonowane w zoo modeli (Caffe gospodaruje popularnymi modelami rozpoznawania obrazów). W tym ataku osoba atakująca atakuje modele hostowane w Caffe, sabotując tym samym dostęp do nich dla innych użytkowników. [1]
Tradycyjne paralele
Naruszenie zależności niezwiązanych z zabezpieczeniami innych firm
Nieświadome hostowanie złośliwego oprogramowania w sklepie App Store
Środki łagodzące
Zminimalizuj zależności innych firm dla modeli i danych, jeśli to możliwe.
Uwzględnij te zależności w procesie modelowania zagrożeń.
Korzystaj z silnego uwierzytelniania, kontroli dostępu i szyfrowania między systemami pierwszej oraz trzeciej strony.
Ciężkość
Krytyczny
#10 Ukryte Obejście w Uczeniu Maszynowym
Opis
Proces trenowania jest przekazywany do złośliwej strony trzeciej, która manipuluje danymi treningowymi i dostarcza zainfekowany model, który wymusza ukierunkowane błędne klasyfikacje, takie jak klasyfikowanie określonego wirusa jako niezłośliwego[1]. Jest to ryzyko w scenariuszach generowania modelu uczenia maszynowego jako usługi.
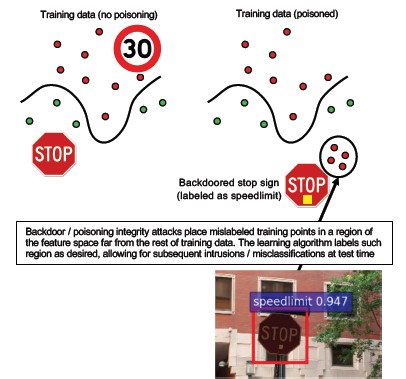 [12]
[12]
Tradycyjne paralele
Naruszenie zależności zabezpieczeń innych firm
Mechanizm aktualizacji oprogramowania zagrożony kompromitacją
Naruszenie zabezpieczeń urzędu certyfikacji
Środki łagodzące
Reaktywne/defensywne akcje wykrywania
- Szkody już zostały wyrządzone, gdy to zagrożenie zostanie wykryte, więc model oraz wszelkie dane szkoleniowe dostarczone przez złośliwego dostawcę nie można ufać.
Działania proaktywne/ochronne
Trenowanie wszystkich poufnych modeli w firmie
Sklasyfikuj dane szkoleniowe lub upewnij się, że pochodzą z zaufanej firmy zewnętrznej z silnymi procedurami ochrony.
Modelowanie zagrożeń interakcji między dostawcą MLaaS a własnymi systemami
Akcje odpowiedzi
- Tak jak w przypadku kompromisu zależności zewnętrznej
Ciężkość
Krytyczny
#11 Wykorzystanie zależności oprogramowania systemu ML
Opis
W tym ataku atakujący nie manipuluje algorytmami. Zamiast tego wykorzystuje luki w zabezpieczeniach oprogramowania, takie jak przepełnienie buforu lub wykonywanie skryptów między witrynami[1]. Nadal łatwiej jest naruszyć bezpieczeństwo warstw oprogramowania pod sztuczną inteligencją/uczeniem maszynowym niż bezpośrednio zaatakować warstwę szkoleniową, dlatego tradycyjne praktyki ograniczania zagrożeń bezpieczeństwa opisane w cyklu projektowania zabezpieczeń są niezbędne.
Tradycyjne paralele
Naruszona zależność oprogramowania typu open source
Luka w zabezpieczeniach serwera internetowego (XSS, CSRF, niepowodzenie weryfikacji danych wejściowych interfejsu API)
Środki łagodzące
Skontaktuj się z zespołem ds. zabezpieczeń, aby postępować zgodnie z odpowiednimi najlepszymi rozwiązaniami dotyczącymi cyklu projektowania zabezpieczeń/zabezpieczeniami operacyjnymi.
Ciężkość
Zmienna; Aż do krytycznej w zależności od rodzaju tradycyjnej luki w zabezpieczeniach oprogramowania.
Bibliografia
[1] Tryby błędów w uczeniu maszynowym, Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen i Jeffrey Snover, https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] Zespół inżynierii bezpieczeństwa AETHER, wirtualny zespół ds. pochodzenia/dziedziczenia danych
[3] Przykłady kontradyktoryjne w uczeniu głębokim: charakterystyka i rozbieżność, Wei, et al, https://arxiv.org/pdf/1807.00051.pdf
[4] ML-Leaks: ataki na wnioskowanie członkostwa niezależne od modelu i danych oraz ich obrona w modelach uczenia maszynowego, Salem, et al. https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha i T. Ristenpart, "Ataki odwrócenia modelu wykorzystujące informacje o pewności oraz podstawowe środki zaradcze", w materiałach z Konferencji ACM SIGSAC dotyczącej Bezpieczeństwa Komputerowego i Komunikacyjnego (CCS) z 2015 roku.
[6] Nicolas Papernot & Patrick McDaniel - Przykłady przeciwstawne w uczeniu maszynowym AIWTB 2017
[7] Kradzież modeli uczenia maszynowego za pośrednictwem interfejsów API przewidywania, Alfred Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, University of North Carolina w Chapel Hill; Thomas Ristenpart, Cornell Tech
[8] Przestrzeń Przenośnych Przykładów Ataków, Florian Tramèr , Nicolas Papernot , Ian Goodfellow , Dan Boneh i Patrick McDaniel
[9] Rozumienie wniosków o członkostwie w modelach uczenia Well-Generalized Yunhui Long1 , Vincent Bindschaedler1 , Lei Wang2 , Diyue Bu2 , Xiaofeng Wang2 , Haixu Tang2 , Carl A. Gunter1 i Kai Chen3,4
[10] Simon-Gabriel i in., wrażliwość na ataki sieci neuronowych wzrasta wraz z wymiarem wejściowym, ArXiv 2018;
[11] Lyu et al., Ujednolicona rodzina regularyzacji gradientu dla przykładów kontradyktoryjnych, ICDM 2015
[12] Dzikie wzorce: Dziesięć lat po powstaniu niepożądanego uczenia maszynowego - NeCS 2019 Battista Biggioa, Fabio Roli
[13] Odporne na ataki wykrywanie złośliwego oprogramowania za pomocą klasyfikacji monotonicznej Inigo Incer et al.
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto i Fabio Roli. Klasyfikatory Bagging w celu przeciwdziałania atakom zatruwającym w przeciwstawnych zadaniach klasyfikacyjnych
[15] Ulepszona Obrona przed Negatywnym Wpływem Hongjiang Li i Patrick P.K. Chan
[16] Adler. Luki w zabezpieczeniach w systemach szyfrowania biometrycznego. 5. Międzynarodowa Konferencja AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel, Ortega-Garcia. Na podatność systemów weryfikacji twarzy na ataki wspinaczkowe. Patt. Rec., 2010
[18] Weilin Xu, David Evans, Yanjun Qi. Funkcja ściskania: wykrywanie niepożądanych przykładów w głębokich sieciach neuronowych. Sympozjum zabezpieczeń sieci i systemu rozproszonego 2018. 18-21 lutego.
[19] Wzmocnienie odporności niepożądanej przy użyciu zaufania modelu wywołanego przez szkolenie niepożądane - Xi Wu, Ujong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Analiza przyczynowa oparta na autorstwie na potrzeby wykrywania niepożądanych przykładów, Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Bha
[21] Niezawodna regresja liniowa przed zatruciem danych treningowych — Chang Liu i in.
[22] Odszumianie cech dla poprawy odporności na ataki, Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
[23] Certyfikowane obrony przed adwersarialnymi przykładami - Aditi Raghunathan, Jacob Steinhardt, Percy Liang