Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() SQL Server 2016 (13.x) SQL Server 2017 (14.x)
SQL Server 2016 (13.x) SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x) ![]() w systemie Linux
w systemie Linux
Integracja języka Python jest dostępna w programie SQL Server 2017 lub nowszym, jeśli opcja języka Python zostanie uwzględniona w instalacji usług Machine Learning Services (In-Database).
Uwaga / Notatka
Obecnie ten artykuł dotyczy programów SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) i SQL Server 2019 (15.x) tylko dla systemu Linux.
Aby opracowywać i wdrażać rozwiązania języka Python dla programu SQL Server, zainstaluj biblioteki revoscalepy firmy Microsoft i inne biblioteki języka Python na stacji roboczej deweloperskiej. Biblioteka revoscalepy, która znajduje się też na zdalnym wystąpieniu SQL Server, koordynuje żądania obliczeniowe między obydwoma systemami.
Z tego artykułu dowiesz się, jak skonfigurować stację roboczą deweloperów języka Python, aby umożliwić interakcję ze zdalnym programem SQL Server włączonym na potrzeby uczenia maszynowego i integracji języka Python. Po wykonaniu kroków opisanych w tym artykule będziesz mieć te same biblioteki języka Python co te w programie SQL Server. Dowiesz się również, jak wypychać obliczenia z lokalnej sesji języka Python do zdalnej sesji języka Python w programie SQL Server.
Diagram komponentów architektury klient-serwer.
Aby zweryfikować instalację, możesz użyć wbudowanych notesów Jupyter Notebook zgodnie z opisem w tym artykule lub połączyć biblioteki z narzędziem PyCharm lub innym środowiskiem IDE, którego zwykle używasz.
Wskazówka
Aby zapoznać się z pokazem wideo z tych ćwiczeń, zobacz Zdalne uruchamianie języków R i Python w programie SQL Server z poziomu notesów Jupyter Notebook.
Powszechnie używane narzędzia
Niezależnie od tego, czy jesteś deweloperem języka Python nowym użytkownikiem SQL, czy deweloperem SQL nowym w Pythonie i analizach w bazie danych, potrzebujesz zarówno narzędzia programistycznego Python, jak i edytora zapytań T-SQL, takiego jak SQL Server Management Studio (SSMS), aby w pełni wykorzystać wszystkie możliwości analiz w bazie danych.
W przypadku programowania w języku Python można użyć notesów Jupyter Notebook, które są dołączone do dystrybucji Anaconda zainstalowanej przez program SQL Server. W tym artykule wyjaśniono, jak uruchomić notesy Jupyter Notebook, aby można było uruchamiać kod języka Python lokalnie i zdalnie w programie SQL Server.
Program SSMS jest oddzielnym pobieraniem, przydatnym do tworzenia i uruchamiania procedur składowanych w programie SQL Server, w tym zawierających kod języka Python. Niemal każdy kod języka Python, który piszesz w notesach Jupyter Notebook, można osadzić w procedurze składowanej. Możesz przejść przez inne przewodniki Szybki start, aby dowiedzieć się więcej o programie SSMS i osadzonym języku Python.
1 — Instalowanie pakietów języka Python
Lokalne stacje robocze muszą mieć takie same wersje pakietów języka Python jak w programie SQL Server, w tym podstawowe pakiety Anaconda 4.2.0 z dystrybucją języka Python 3.5.2 i pakietami specyficznymi dla firmy Microsoft.
Skrypt instalacyjny dodaje do klienta języka Python trzy biblioteki specyficzne dla firmy Microsoft. Skrypt instaluje:
- Revoscalepy służy do definiowania obiektów źródła danych i kontekstu obliczeniowego.
- microsoftml udostępnia algorytmy uczenia maszynowego.
- usługa azureml ma zastosowanie do zadań operacjonalizacji skojarzonych z autonomicznym kontekstem serwera i może być ograniczona do analizy w bazie danych.
Pobierz skrypt instalacji. Na odpowiedniej poniższej stronie usługi GitHub wybierz pozycję Pobierz nieprzetworzone pliki.
Install-PyForMLS.ps1 instaluje wersję 9.2.1 pakietów języka Microsoft Python. Ta wersja odpowiada domyślnemu wystąpieniu programu SQL Server.
Install-PyForMLS.ps1 instaluje wersję 9.3 pakietów języka Microsoft Python.
Otwórz okno programu PowerShell z podwyższonym poziomem uprawnień administratora (kliknij prawym przyciskiem myszy pozycję Uruchom jako administrator).
Przejdź do folderu, w którym pobrano instalator i uruchom skrypt. Dodaj argument wiersza polecenia,
-InstallFolderaby określić lokalizację folderu bibliotek. Przykład:cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
Jeśli pominięto folder instalacji, wartość domyślna to %ProgramFiles%\Microsoft\PyForMLS.
Ukończenie instalacji zajmuje trochę czasu. Postęp można monitorować w oknie programu PowerShell. Po zakończeniu instalacji masz kompletny zestaw pakietów.
Wskazówka
Zalecamy Python for Windows FAQ jako źródło ogólnych informacji dotyczących uruchamiania programów Python w systemie Windows.
2 — Lokalizowanie plików wykonywalnych
Nadal w programie PowerShell wyświetl listę zawartości folderu instalacyjnego, aby potwierdzić, że Python.exe, skrypty i inne pakiety są zainstalowane.
Wprowadź
cd \, aby przejść do dysku głównego, a następnie wprowadź ścieżkę określoną przez ciebie dla-InstallFolderw poprzednim kroku. Jeśli ten parametr zostanie pominięty podczas instalacji, wartość domyślna tocd %ProgramFiles%\Microsoft\PyForMLS.Wprowadź ,
dir *.exeaby wyświetlić listę plików wykonywalnych. Powinny zostać wyświetlone python.exe, pythonw.exei uninstall-anaconda.exe.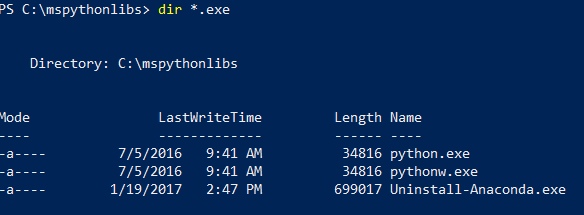
W systemach z wieloma wersjami języka Python pamiętaj, aby użyć tego konkretnego Python.exe, jeśli chcesz załadować pakiet revoscalepy i inne pakiety firmy Microsoft.
Uwaga / Notatka
Skrypt instalacji nie modyfikuje zmiennej środowiskowej PATH na komputerze, co oznacza, że nowo zainstalowany interpreter języka Python i moduły nie są automatycznie dostępne dla innych narzędzi, które mogą być dostępne. Aby uzyskać pomoc dotyczącą łączenia interpretera języka Python i bibliotek z narzędziami, zobacz Instalowanie środowiska IDE.
3 — Otwieranie notesów Jupyter Notebook
Anaconda zawiera Jupyter Notebooks. W następnym kroku utwórz notes i uruchom kod języka Python zawierający właśnie zainstalowane biblioteki.
W wierszu polecenia programu PowerShell, wciąż w
%ProgramFiles%\Microsoft\PyForMLSkatalogu, otwórz notesy Jupyter z folderu Scripts..\Scripts\jupyter-notebookNotatnik powinien się otworzyć w domyślnej przeglądarce pod adresem
https://localhost:8889/tree.Innym sposobem rozpoczęcia jest dwukrotne kliknięcie jupyter-notebook.exe.
Wybierz pozycję Nowy , a następnie wybierz pozycję Python 3.
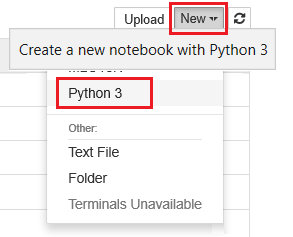
Wprowadź
import revoscalepyi uruchom polecenie , aby załadować jedną z bibliotek specyficznych dla firmy Microsoft.Wprowadź i uruchom polecenie
print(revoscalepy.__version__), aby zwrócić informacje o wersji. Powinna zostać wyświetlona wersja 9.2.1 lub 9.3.0. Na serwerze można użyć jednej z tych wersji z wersją revoscalepy.Wprowadź bardziej złożoną serię instrukcji. W tym przykładzie są generowane statystyki podsumowania przy użyciu rx_summary za pośrednictwem lokalnego zestawu danych. Inne funkcje pobierają lokalizację przykładowych danych i tworzą obiekt źródła danych dla lokalnego pliku xdf.
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
Poniższy zrzut ekranu przedstawia dane wejściowe i część danych wyjściowych przyciętą do zwięzłości.

4 — Uzyskiwanie uprawnień SQL
Aby nawiązać połączenie z wystąpieniem programu SQL Server w celu uruchamiania skryptów i przekazywania danych, musisz mieć prawidłowy identyfikator logowania na serwerze bazy danych. Możesz użyć logowania SQL lub zintegrowanego uwierzytelniania Windows. Ogólnie zaleca się użycie zintegrowanego uwierzytelniania systemu Windows, ale użycie logowania SQL jest prostsze w niektórych scenariuszach, szczególnie w przypadku, gdy skrypt zawiera parametry połączenia z danymi zewnętrznymi.
Co najmniej konto używane do uruchamiania kodu musi mieć uprawnienia do odczytu z baz danych, z którymi pracujesz, oraz specjalne uprawnienie WYKONAJ DOWOLNY SKRYPT ZEWNĘTRZNY. Większość programistów wymaga również uprawnień do tworzenia procedur składowanych oraz do zapisywania danych w tabelach zawierających dane treningowe lub dane oceniane.
Poproś administratora bazy danych o skonfigurowanie następujących uprawnień dla konta w bazie danych, w której używasz języka Python:
- WYKONAJ DOWOLNY SKRYPT ZEWNĘTRZNY , aby uruchomić język Python na serwerze.
- db_datareader uprawnienia do uruchamiania zapytań używanych do trenowania modelu.
- db_datawriter do zapisywania danych treningowych lub danych z przypisanymi ocenami.
- db_owner do tworzenia obiektów, takich jak procedury składowane, tabele, funkcje. Potrzebujesz również db_owner do utworzenia przykładowych i testowych baz danych.
Jeśli Twój kod wymaga pakietów, które nie są instalowane domyślnie z programem SQL Server, skoordynuj to z administratorem bazy danych, aby pakiety zostały zainstalowane wraz z wystąpieniem SQL Server. Program SQL Server jest zabezpieczonym środowiskiem i istnieją ograniczenia dotyczące miejsca instalowania pakietów. Instalacja ad hoc pakietów w ramach kodu nie jest zalecana, nawet jeśli masz prawa. Ponadto przed zainstalowaniem nowych pakietów w bibliotece serwerów należy zawsze dokładnie rozważyć implikacje dotyczące zabezpieczeń.
5 — Tworzenie danych testowych
Jeśli masz uprawnienia do tworzenia bazy danych na serwerze zdalnym, możesz uruchomić następujący kod, aby utworzyć demonstracyjną bazę danych Iris używaną do pozostałych kroków w tym artykule.
5–1 — Zdalne tworzenie bazy danych irissql
from mssql_python import connect
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
conn = connect(connection_string.format("master"))
conn.setautocommit(True)
conn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}".format(new_db_name))
conn.cursor().execute("CREATE DATABASE " + new_db_name)
conn.close()
print("Database created")
5–2 — Importowanie przykładu irysów ze środowiska SkLearn
from sklearn import datasets
import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
5–3 — Użyj Revoscalepy API, aby utworzyć tabelę i załadować dane dotyczące irysów
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with mssql-python
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
6 — Testowanie połączenia zdalnego
Przed wypróbowaniem tego następnego kroku upewnij się, że masz uprawnienia do instancji SQL Server i ciąg połączenia do przykładowej bazy danych Iris. Jeśli baza danych nie istnieje i masz wystarczające uprawnienia, możesz utworzyć bazę danych, korzystając z tych instrukcji wbudowanych.
Zastąp parametry połączenia prawidłowymi wartościami. Przykładowy kod używa "Server=localhost;Database=irissql;Trusted_Connection=Yes;", ale twój kod powinien określać zdalny serwer, prawdopodobnie z nazwą wystąpienia, oraz opcję poświadczeń, które mapują na identyfikator logowania bazy danych.
6–1 Definiowanie funkcji
Poniższy kod definiuje funkcję, która zostanie wysłana do programu SQL Server w późniejszym kroku. Kiedy zostanie wykonana, używa danych i bibliotek (revoscalepy, pandas, matplotlib) na serwerze zdalnym do tworzenia wykresów punktowych danych dotyczących irysów. Zwraca strumień bajtów z pliku .png z powrotem do notebooków Jupyter, aby wyświetlić go w przeglądarce.
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6–2 Wysyłanie funkcji do programu SQL Server
W tym przykładzie utwórz zdalny kontekst obliczeniowy, a następnie wyślij wykonanie funkcji do programu SQL Server przy użyciu rx_exec. Funkcja rx_exec jest przydatna, ponieważ akceptuje kontekst obliczeniowy jako argument. Każda funkcja, którą chcesz wykonać zdalnie, musi mieć argument kontekstu obliczeniowego. Niektóre funkcje, takie jak rx_lin_mod obsługują ten argument bezpośrednio. Dla operacji, które nie spełniają wymagań, można użyć rx_exec do wdrożenia kodu w zdalnym kontekście obliczeniowym.
W tym przykładzie żadne nieprzetworzone dane nie musiały być przesyłane z programu SQL Server do notesu Jupyter Notebook. Wszystkie obliczenia są wykonywane w bazie danych Iris i zwracany jest tylko plik obrazu do klienta.
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client. All data remained secure and was manipulated in my db.
display.Image(data=image)
Poniższy zrzut ekranu przedstawia dane wejściowe i wykres punktowy jako dane wyjściowe.

7 — Uruchamianie języka Python z poziomu narzędzi
Ponieważ deweloperzy często pracują z wieloma wersjami języka Python, proces instalacji nie dodaje języka Python do zmiennej środowiskowej PATH. Aby użyć pliku wykonywalnego i bibliotek języka Python zainstalowanych przez konfigurację, połącz środowisko IDE z Python.exe w ścieżce, która udostępnia również revoscalepy i microsoftml.
Wiersz polecenia
Po uruchomieniu Python.exe z %ProgramFiles%\Microsoft\PyForMLS (lub dowolnej lokalizacji określonej dla instalacji biblioteki klienta języka Python) masz dostęp do pełnej dystrybucji Anaconda oraz modułów języka Microsoft Python, revoscalepy i microsoftml.
- Przejdź do
%ProgramFiles%\Microsoft\PyForMLSstrony i wykonaj Python.exe. - Otwórz interaktywną pomoc:
help(). - Wpisz nazwę modułu w wierszu polecenia pomocy:
help> revoscalepy. Pomoc zwraca nazwę, zawartość pakietu, wersję i lokalizację pliku. - Zwróć informacje o wersji i pakiecie w monicie pomocy> :
revoscalepy. Naciśnij Enter kilka razy, aby zamknąć pomoc. - Zaimportuj moduł:
import revoscalepy.
Notatniki Jupyter
W tym artykule użyto wbudowanych notatników Jupyter Notebook do zademonstrowania wywołań funkcji w revoscalepy. Jeśli dopiero zaczynasz korzystać z tego narzędzia, na poniższym zrzucie ekranu pokazano, jak elementy pasują do siebie i dlaczego wszystko "po prostu działa".
Folder %ProgramFiles%\Microsoft\PyForMLS nadrzędny zawiera pakiet Anaconda oraz pakiety firmy Microsoft. Notesy Jupyter Notebook są zawarte w aplikacji Anaconda w folderze Scripts, a pliki wykonywalne języka Python są autoregisterowane za pomocą notesów Jupyter Notebook. Pakiety znajdujące się w katalogu site-packages można zaimportować do notesu, w tym trzy pakiety firmy Microsoft używane do nauki o danych oraz uczenia maszynowego.
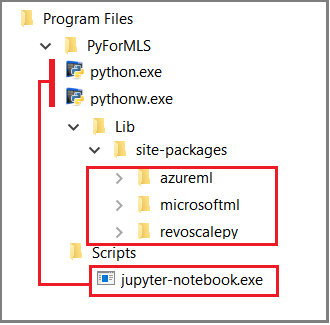
Jeśli używasz innego środowiska IDE, musisz połączyć pliki wykonywalne i biblioteki funkcji języka Python z narzędziem. Poniższe sekcje zawierają instrukcje dotyczące powszechnie używanych narzędzi.
Visual Studio
Jeśli masz język Python w programie Visual Studio, użyj następujących opcji konfiguracji, aby utworzyć środowisko języka Python, które zawiera pakiety języka Microsoft Python.
| Ustawienie konfiguracji | value |
|---|---|
| Ścieżka prefiksu | %ProgramFiles%\Microsoft\PyForMLS |
| Ścieżka interpretera | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| Interpreter okienny | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
Aby uzyskać pomoc dotyczącą konfigurowania środowiska języka Python, zobacz Zarządzanie środowiskami języka Python w programie Visual Studio.
PyCharm
W pliku PyCharm ustaw interpreter na zainstalowany plik wykonywalny języka Python.
W nowym projekcie w obszarze Ustawienia wybierz pozycję Dodaj lokalnie.
Wprowadź
%ProgramFiles%\Microsoft\PyForMLS\.
Teraz możesz zaimportować moduły revoscalepy, microsoftml lub azureml . Możesz również wybrać pozycję Narzędzia>Konsola języka Python , aby otworzyć interaktywne okno.