Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() SQL Server 2016 (13.x) i nowsze wersje
SQL Server 2016 (13.x) i nowsze wersje ![]() usługi Azure SQL Managed Instance
usługi Azure SQL Managed Instance
W tym artykule wyjaśniono, jak skonfigurować przykładową bazę danych składającą się z danych publicznych z Nowojorskiej Komisji Taksówki i Limuzyny. Te dane są używane w kilku samouczkach języka R i Python na potrzeby analizy w bazie danych w programie SQL Server. Aby przyspieszyć uruchamianie przykładowego kodu, utworzyliśmy 1-procentową reprezentatywną próbkę danych. W systemie plik kopii zapasowej bazy danych jest nieco ponad 90 MB, zapewniając 1,7 miliona wierszy w podstawowej tabeli danych.
Aby ukończyć to ćwiczenie, należy mieć program SQL Server Management Studio (SSMS) lub inne narzędzie, które może przywrócić plik kopii zapasowej bazy danych i uruchomić zapytania T-SQL.
Samouczki i szybkie starty, korzystające z tego zestawu danych, zawierają następujące artykuły:
- Poznaj analizę w bazie danych przy użyciu języka R w programie SQL Server
- Nauka analizy w bazie danych przy użyciu języka Python w programie SQL Server
Pobieranie plików
Przykładowa baza danych to plik kopii zapasowej programu SQL Server 2016 (.bak) hostowany przez firmę Microsoft. Można przywrócić je w programie SQL Server 2016 lub nowszym. Pobieranie pliku rozpoczyna się natychmiast po otwarciu linku.
Rozmiar pliku wynosi około 90 MB.
Uwaga / Notatka
Aby przywrócić przykładową bazę danych w klastrach danych big data programu SQL Server, pobierz NYCTaxi_Sample.bak i postępuj zgodnie z instrukcjami w temacie Przywracanie bazy danych do wystąpienia głównego klastra danych big data programu SQL Server.
Uwaga / Notatka
Aby przywrócić przykładową bazę danych w Machine Learning Services w Azure SQL Managed Instance, postępuj zgodnie z instrukcjami w przewodniku Szybki start: Przywracanie bazy danych do usługi Azure SQL Managed Instance przy użyciu pliku .bak demonstracyjnej bazy danych NYC Taxi: https://aka.ms/sqlmldocument/NYCTaxi_Sample.bak.
Pobierz plik kopii zapasowej bazy danych NYCTaxi_Sample.bak .
Skopiuj plik do
C:\Program files\Microsoft SQL Server\MSSQL-instance-name\MSSQL\Backuplub podobnej ścieżki dla domyślnegoBackupfolderu wystąpienia.W programie SSMS kliknij prawym przyciskiem myszy pozycję Bazy danych i wybierz polecenie Przywróć pliki i grupy plików.
Wprowadź
NYCTaxi_Samplejako nazwę bazy danych.Wybierz pozycję Z urządzenia , a następnie otwórz stronę wyboru pliku, aby wybrać plik kopii zapasowej
NYCTaxi_Sample.bak. Wybierz pozycję Dodaj , aby wybrać pozycjęNYCTaxi_Sample.bak.Zaznacz pole wyboru Przywróć i wybierz przycisk OK , aby przywrócić bazę danych.
Przegląd obiektów bazy danych
Upewnij się, że obiekty bazy danych istnieją w wystąpieniu programu SQL Server przy użyciu programu SQL Server Management Studio. Powinna zostać wyświetlona baza danych, tabele, funkcje i procedury składowane.
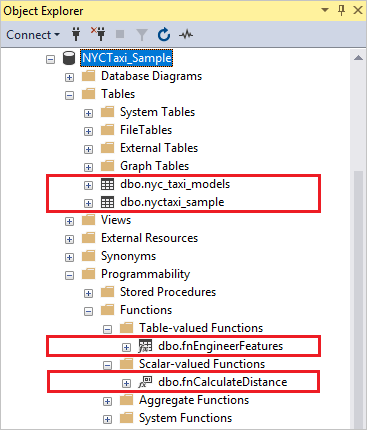
Obiekty w bazie danych NYCTaxi_Sample
W poniższej tabeli podsumowano obiekty utworzone w bazie danych demonstracyjnej NYC Taxi.
| Nazwa obiektu | Typ obiektu | Opis |
|---|---|---|
| NYCTaxi_Sample | baza danych | Tworzy bazę danych i dwie tabele:dbo.nyctaxi_sample tabela: zawiera główny zestaw danych nowojorskich taksówek. Indeks sklepu kolumnowego z klastrowaniem jest dodawany do tabeli w celu zwiększenia wydajności przechowywania i przetwarzania zapytań. Do tej tabeli wstawiono 1% próbek zestawu danych NYC Taxi.dbo.nyc_taxi_models tabela: służy do utrwalania wytrenowanego zaawansowanego modelu analizy. |
| fnCalculateDistance | funkcja skalarna | Oblicza bezpośrednią odległość między lokalizacjami odbioru a miejscami docelowymi. Ta funkcja jest używana w obszarze Tworzenie funkcji danych, Trenowanie i zapisywanie modelu oraz operacjonalizacja modelu języka R. |
| fnEngineerFeatures | funkcja zwracająca tabelę | Tworzy nowe funkcje danych na potrzeby trenowania modelu. Ta funkcja jest używana w artykule Tworzenie funkcji danych i operacjonalizacja modelu języka R. |
Procedury składowane są tworzone przy użyciu skryptów w językach R i Python, które można znaleźć w różnych samouczkach. Poniższa tabela zawiera podsumowanie procedur składowanych, które można opcjonalnie dodać do bazy danych demonstracyjnej NYC Taxi podczas uruchamiania skryptu z różnych lekcji.
| Procedura składowana | Język | Opis |
|---|---|---|
| RxPlotHistogram | R | Wywołuje funkcję RevoScaleR rxHistogram , aby wykreślić histogram zmiennej, a następnie zwraca wykres jako obiekt binarny. Ta procedura składowana jest używana w Eksplorowanie i wizualizowanie danych. |
| RPlotRHist | R | Tworzy grafikę przy użyciu Hist funkcji i zapisuje dane wyjściowe jako lokalny plik PDF. Ta procedura składowana jest używana w Eksplorowanie i wizualizowanie danych. |
| RxTrainLogitModel | R | Trenuje model regresji logistycznej, wywołując pakiet języka R. Model przewiduje wartość tipped kolumny i jest trenowany przy użyciu losowo wybranej 70% danych. Dane wyjściowe procedury składowanej to wytrenowany model, który jest zapisywany w tabeli dbo.nyc_taxi_models. Ta procedura składowana jest używana do trenowania i zapisywania modelu. |
| RxPredictBatchOutput | R | Wywołuje wytrenowany model w celu utworzenia przewidywań przy użyciu modelu. Procedura składowana akceptuje zapytanie jako parametr wejściowy i zwraca kolumnę wartości liczbowych zawierających wyniki dla wierszy wejściowych. Ta procedura składowana jest używana w funkcji Przewidywanie potencjalnych wyników. |
| RxPredictSingleRow | R | Wywołuje wytrenowany model w celu utworzenia przewidywań przy użyciu modelu. Ta procedura składowana akceptuje nową obserwację jako dane wejściowe, z poszczególnymi wartościami cech przekazanymi jako parametry wbudowane i zwraca wartość, która przewiduje wynik nowej obserwacji. Ta procedura składowana jest używana w funkcji Przewidywanie potencjalnych wyników. |
Zapytaj dane
W ramach kroku weryfikacji uruchom zapytanie, aby potwierdzić przekazanie danych.
W Eksploratorze obiektów w obszarze Bazy danych kliknij prawym przyciskiem myszy bazę danych NYCTaxi_Sample i uruchom nowe zapytanie.
Uruchom kilka podstawowych zapytań:
SELECT TOP(10) * FROM dbo.nyctaxi_sample; SELECT COUNT(*) FROM dbo.nyctaxi_sample;
Baza danych zawiera 1,7 miliona wierszy.
W bazie danych znajduje
dbo.nyctaxi_samplesię tabela zawierająca zestaw danych. Tabela została zoptymalizowana pod kątem obliczeń zbiorczych poprzez dodanie indeksu columnstore. Uruchom tę instrukcję, aby wygenerować szybkie podsumowanie w tabeli.SELECT DISTINCT [passenger_count] , ROUND (SUM ([fare_amount]),0) as TotalFares , ROUND (AVG ([fare_amount]),0) as AvgFares FROM [dbo].[nyctaxi_sample] GROUP BY [passenger_count] ORDER BY AvgFares DESC
Wyniki powinny być podobne do tych wyświetlanych na poniższym zrzucie ekranu.

Dalsze kroki
Przykładowe dane dotyczące taksówek w Nowym Jorku są teraz dostępne do nauki praktycznej.