Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() SQL Server 2017 (14.x) i nowsze wersje
SQL Server 2017 (14.x) i nowsze wersje ![]() usługi Azure SQL Managed Instance
usługi Azure SQL Managed Instance
W trzeciej części tej czteroczęściowej serii samouczków utworzysz model K-Means w Pythonie w celu wykonywania klastrowanie. W następnej części tej serii wdrożysz ten model w bazie danych z usługami SQL Server Machine Learning Services lub w klastrach danych big data.
W trzeciej części tej czteroczęściowej serii samouczków utworzysz model K-Means w języku Python do przeprowadzania klastrowania. W następnej części tej serii wdrożysz ten model w bazie danych za pomocą usług SQL Server Machine Learning Services.
W trzeciej części tej czteroczęściowej serii samouczków utworzysz model K-Means w Pythonie do wykonywania klastrowania. W następnej części tej serii wdrożysz ten model w bazie danych za pomocą usług Azure SQL Managed Instance Machine Learning Services.
W tym artykule dowiesz się, jak:
- Definiowanie liczby klastrów dla algorytmu K-Średnich
- Wykonywanie klastrowania
- Analizowanie wyników
W części 1 zainstalowano wymagania wstępne i przywrócono przykładową bazę danych.
W drugiej części przedstawiono sposób przygotowywania danych z bazy danych do wykonywania klastrowania.
W czwartej części dowiesz się, jak utworzyć procedurę składowaną w bazie danych, która może wykonywać klastrowanie w języku Python na podstawie nowych danych.
Wymagania wstępne
- W trzeciej części tego samouczka przyjęto założenie, że spełniono wymagania wstępne części 1 i wykonano kroki opisane w drugiej części.
Definiowanie liczby klastrów
Aby klasterować dane klientów, użyjesz algorytmu klastrowania K-Średnich, jednego z najprostszych i najbardziej znanych sposobów grupowania danych. Więcej informacji na temat metody K-Średnich można przeczytać w kompletnym przewodniku po algorytmie klastrowania metodą K-średnich.
Algorytm akceptuje dwa dane wejściowe: same dane wejściowe i wstępnie zdefiniowaną liczbę "k" reprezentującą liczbę klastrów do wygenerowania. Dane wyjściowe to k klastry z danymi wejściowymi podzielonymi na partycje między klastrami.
Celem algorytmu K-means jest pogrupowanie elementów w k klastrów w taki sposób, aby wszystkie elementy w tym samym klastrze były jak najbardziej podobne do siebie, a różniły się od elementów w innych klastrach w możliwie największym stopniu.
Aby określić liczbę klastrów używanych przez algorytm, użyj wykresu sumy kwadratów wewnątrz grup w zależności od liczby wyodrębnionych klastrów. Odpowiednia liczba klastrów do użycia znajduje się w zagięciu lub "punkcie zgięcia" wykresu.
################################################################################################
## Determine number of clusters using the Elbow method
################################################################################################
cdata = customer_data
K = range(1, 20)
KM = (sk_cluster.KMeans(n_clusters=k).fit(cdata) for k in K)
centroids = (k.cluster_centers_ for k in KM)
D_k = (sci_distance.cdist(cdata, cent, 'euclidean') for cent in centroids)
dist = (np.min(D, axis=1) for D in D_k)
avgWithinSS = [sum(d) / cdata.shape[0] for d in dist]
plt.plot(K, avgWithinSS, 'b*-')
plt.grid(True)
plt.xlabel('Number of clusters')
plt.ylabel('Average within-cluster sum of squares')
plt.title('Elbow for KMeans clustering')
plt.show()
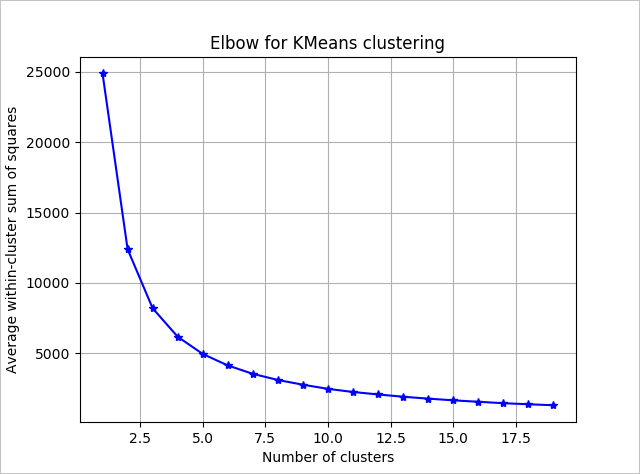
Na podstawie wykresu wygląda na to, że k = 4 byłoby dobrą wartością do wypróbowania. Ta wartość k grupuje klientów na cztery klastry.
Wykonywanie klastrowania
W poniższym skrypcie języka Python użyjesz funkcji KMeans z pakietu sklearn.
################################################################################################
## Perform clustering using Kmeans
################################################################################################
# It looks like k=4 is a good number to use based on the elbow graph.
n_clusters = 4
means_cluster = sk_cluster.KMeans(n_clusters=n_clusters, random_state=111)
columns = ["orderRatio", "itemsRatio", "monetaryRatio", "frequency"]
est = means_cluster.fit(customer_data[columns])
clusters = est.labels_
customer_data['cluster'] = clusters
# Print some data about the clusters:
# For each cluster, count the members.
for c in range(n_clusters):
cluster_members=customer_data[customer_data['cluster'] == c][:]
print('Cluster{}(n={}):'.format(c, len(cluster_members)))
print('-'* 17)
print(customer_data.groupby(['cluster']).mean())
Analizowanie wyników
Po wykonaniu klastrowania metodą K-Średnich, następnym krokiem jest przeanalizowanie wyniku i sprawdzenie, czy można znaleźć jakiekolwiek przydatne informacje.
Przyjrzyj się średnim wartościom klastrów i rozmiarom klastrów wyświetlonym w poprzednim skrypcie.
Cluster0(n=31675):
-------------------
Cluster1(n=4989):
-------------------
Cluster2(n=1):
-------------------
Cluster3(n=671):
-------------------
customer orderRatio itemsRatio monetaryRatio frequency
cluster
0 50854.809882 0.000000 0.000000 0.000000 0.000000
1 51332.535779 0.721604 0.453365 0.307721 1.097815
2 57044.000000 1.000000 2.000000 108.719154 1.000000
3 48516.023845 0.136277 0.078346 0.044497 4.271237
Cztery metody klastra są podane przy użyciu zmiennych zdefiniowanych w części 1:
- orderRatio = współczynnik zamówienia zwrotnego (łączna liczba zamówień częściowo lub w pełni zwrócona w porównaniu z łączną liczbą zamówień)
- itemsRatio = współczynnik elementów zwracanych (łączna liczba zwróconych elementów w porównaniu z liczbą zakupionych elementów)
- monetaryRatio = stosunek kwoty zwrotu (łączna kwota pieniężna elementów zwróconych w porównaniu do zakupionej kwoty)
- frequency = częstotliwość zwrotu
Eksploracja danych przy użyciu metody K-średnich często wymaga dalszej analizy wyników i podejmowania kolejnych kroków w celu lepszego zrozumienia każdego klastra, ale może dostarczyć dobrych wskazówek. Oto kilka sposobów interpretowania tych wyników:
- Klaster 0 wydaje się być grupą klientów, którzy nie są aktywni (wszystkie wartości to zero).
- Klaster 3 wydaje się być grupą, która wyróżnia się pod względem zachowania zwrotnego.
Klaster 0 to zestaw klientów, którzy wyraźnie nie są aktywni. Być może możesz kierować działania marketingowe na tę grupę, aby wyzwolić zainteresowanie zakupami. W następnym kroku wykonasz zapytanie dotyczące bazy danych dla adresów e-mail klientów w klastrze 0, aby można było wysłać do nich wiadomość e-mail marketingową.
Uprzątnij zasoby
Jeśli nie zamierzasz kontynuować pracy z tym samouczkiem, usuń bazę danych tpcxbb_1gb.
Dalsze kroki
W trzeciej części tej serii samouczków wykonano następujące kroki:
- Określenie liczby klastrów w algorytmie k-means
- Wykonywanie klastrowania
- Analizowanie wyników
Aby wdrożyć utworzony model uczenia maszynowego, wykonaj czynności opisane w czwartej części tej serii samouczków: