Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy do:![]() SQL Server 2016 (13.x) i nowsze wersje
SQL Server 2016 (13.x) i nowsze wersje ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL database in Microsoft Fabric
SQL database in Microsoft Fabric
Wirtualizacja danych umożliwia uruchamianie zapytań Transact-SQL (T-SQL) na danych zewnętrznych bez ładowania ich do bazy danych. PolyBase to funkcja silnika bazy danych, która implementuje wirtualizację danych w serwerze SQL Server i usłudze Azure SQL. Zdefiniujesz zewnętrzne źródło danych, opcjonalny format pliku i tabelę zewnętrzną, a następnie wykonasz zapytanie względem tabeli zewnętrznej, tak SELECT jak każda inna tabela.
Ten przewodnik ułatwia:
- Dowiedz się, które funkcje PolyBase są obsługiwane przez Twoją platformę SQL i wersję.
- Wybierz między
OPENROWSET, tabelami zewnętrznymi lubBULK INSERTna potrzeby wykonywania zapytań lub pozyskiwania danych. - Postępuj krok po kroku, używając dostępnych linków w typowych scenariuszach.
- Zapoznaj się z wydajnością, rozwiązywaniem problemów i najlepszymi rozwiązaniami dotyczącymi obciążeń produkcyjnych.
Typowe przypadki użycia
W poniższej tabeli opisano możliwe scenariusze użycia.
| Scenario | Użyj |
|---|---|
| Eksploracja plików ad hoc | OPENROWSET(BULK ...) |
| Wykonywanie zapytań dotyczących plików wielokrotnego użytku dla analizy biznesowej/raportowania | Tabele zewnętrzne nad plikami |
| Wykonywanie zapytań między bazami danych (SQL Server, Oracle, Teradata, MongoDB, ODBC) | Łączniki polyBase z tabelami zewnętrznymi |
| Eksportowanie wyników zapytania do plików |
CREATE EXTERNAL TABLE AS SELECT (CETAS) |
| Zbiorczy import do tabel |
BULK INSERT lub OPENROWSET(BULK ...) z INSERT ... SELECT |
W jakich miejscach są dostępne funkcje?
W poniższej tabeli przedstawiono podstawowe funkcje technologii PolyBase i wirtualizacji danych dostępne na każdej platformie SQL. Użyj tej tabeli, aby określić, co można zrobić na platformie przed użyciem szczegółowych przewodników.
| Funkcja | SQL Server 2019 | SQL Server 2022 | SQL Server 2025 | Azure SQL Database | Azure SQL Managed Instance | Baza danych SQL w usłudze Microsoft Fabric |
|---|---|---|---|---|---|---|
| Tabele zewnętrzne | Yes | Yes | Yes | Yes | Yes | Yes |
| OPENROWSET (ZBIORCZO) | Tak 1 | Yes | Yes | Yes | Yes | Yes |
| CETAS (eksport) | Nie. | Yes | Yes | Nie. | Yes | Nie. |
| Pliki CSV/pliki rozdzielane separatorem | Tak 2 | Yes | Yes | Yes | Yes | Yes |
| Pliki Parquet | Nie. | Yes | Yes | Yes | Yes | Yes |
| Tabele Delta Lake | Nie. | Yes | Yes | Nie. | Nie. | Nie. |
| Nawiązywanie połączenia z innym programem SQL Server | Yes | Yes | Yes | Nie. | Nie. | Nie. |
| Nawiązywanie połączenia z usługą Azure SQL Database lub usługą Azure SQL Managed Instance | Tak 3 | Tak 3 | Tak 3 | Nie. | Nie. | Nie. |
| Nawiązywanie połączenia z bazą danych Oracle/Teradata/MongoDB | Yes | Yes | Yes | Nie. | Nie. | Nie. |
| Nawiązywanie połączenia z usługą Azure Blob Storage | Yes | Yes | Yes | Yes | Yes | Nie. |
| Nawiązywanie połączenia z usługą ADLS Gen2 | Nie. | Yes | Yes | Yes | Yes | Nie. |
| Połącz się z magazynem zgodnym z usługą S3 | Nie. | Yes | Yes | Nie. | Nie. | Nie. |
| Nawiązywanie połączenia z usługą OneLake (Fabric) | Nie. | Nie. | Nie. | Nie. | Nie. | Yes |
| Obliczenia wypychane | Yes | Yes | Yes | Nie. | Nie. | Nie. |
| Uwierzytelnianie za pomocą tożsamości zarządzanej | Nie. | Nie. | Tak 4 | Yes | Yes | Nie. |
Program SQL Server 2019 (15.x) obsługuje OPENROWSET(BULK...) ścieżki plików lokalnych i sieciowych. W programie SQL Server 2022 (16.x) i nowszych wersjach OPENROWSET(BULK...) obsługuje również odczyt z magazynu w chmurze za pomocą systemów FORMAT = 'PARQUET', FORMAT = DELTAi FORMAT = 'CSV'.
Obsługa CSV w programie SQL Server 2019 (15.x) wymagała usługi Hadoop. W programie SQL Server 2022 (16.x) i nowszych wersjach wolumin CSV jest natywnie obsługiwany bez usługi Hadoop.
3 Używa łącznika programu SQL Server (sqlserver://). Poświadczenie o zakresie bazy danych skierowane jest na punkt końcowy Azure SQL. Stosowane są te same kroki co przy nawiązywaniu połączenia z innym serwerem SQL Server.
4 Uwierzytelnianie tożsamości zarządzanej jest obsługiwane w przypadku nawiązywania połączenia z usługami Azure Blob Storage (ABS) i ADLS Gen2. Wymaga ona programu SQL Server z obsługą usługi Azure Arc lub programu SQL Server na maszynie wirtualnej platformy Azure dla lokalnego programu SQL Server. Jest ona natywnie dostępna w usługach Azure SQL Database i Azure SQL Managed Instance.
Uwaga / Notatka
Począwszy od programu SQL Server 2025 (17.x), wykonywanie zapytań dotyczących plików danych (CSV, Parquet i Delta) w Azure Blob Storage, ADLS Gen2 lub składowaniu zgodnym z S3 jest natywną funkcją aparatu i nie wymaga już instalowania ani uruchamiania usług PolyBase. Łączniki RDBMS (SQL Server, Oracle, Teradata, MongoDB, ODBC) nadal wymagają zainstalowania i uruchomienia usług PolyBase. Program SQL Server 2025 (17.x) dodaje również obsługę systemu Linux dla tych łączników, które były wcześniej dostępne tylko w systemie Windows.
Wykonywanie zapytań o dane zewnętrzne
Przed wybraniem konkretnego scenariusza zapoznaj się z trzema sposobami wykonywania zapytań dotyczących danych zewnętrznych:
| Metoda | Składnia | Użyj, gdy | Uwierzytelnianie | PolyBase wymagany |
|---|---|---|---|---|
| OLE DB zapytania ad hoc | OPENROWSET(provider, connection, query) |
Potrzebujesz szybkiego jednorazowego zapytania bez obiektów trwałych lub potrzebujesz uwierzytelniania identyfikatora Entra firmy Microsoft | Uwierzytelnianie SQL, uwierzytelnianie systemu Windows, Microsoft Entra ID (MSOLEDBSQL) | Nie. |
| Zapytywania ad hoc dotyczące plików | OPENROWSET(BULK ...) |
Chcesz szybko eksplorować dane plików lub testować schematy przed utworzeniem tabeli | Token SAS, klucz dostępu, tożsamość zarządzana, Microsoft Entra ID | Tak dla usług Azure SQL Database i Azure SQL Managed Instance Nie dla wystąpień programu SQL Server |
| Trwałe łączniki danych |
CREATE EXTERNAL TABLE z sqlserver://, oracle://, teradata://, itp. |
Potrzebujesz powtarzającego się dostępu, zarządzania, statystyk i obliczeń przesuwanych na niższy poziom dla środowiska produkcyjnego | Tylko uwierzytelnianie SQL | Yes |
Usługi PolyBase są wymagane do dostępu do plików w chmurze w programie SQL Server 2019 (15.x) i programie SQL Server 2022 (16.x). Programy SQL Server 2025 (17.x) i nowsze mają natywną obsługę formatów CSV, Parquet i Delta bez PolyBase.
Przewodnik po decyzjach
| Scenario | Zalecenie |
|---|---|
| Potrzebuję uwierzytelniania Microsoft Entra ID dla zdalnej usługi SQL lub chcę unikać usług PolyBase. | Używanie OPENROWSET(MSOLEDBSQL, ...) (ad hoc, brak obiektów trwałych) |
| Potrzebuję trwałych tabel, statystyk lub obliczeń wypychanych do zdalnych baz danych | Używaj CREATE EXTERNAL TABLE z łącznikami programu PolyBase (sqlserver://, oracle://, teradata://, mongodb://, odbc://).
OPENROWSET
nie obsługuje łączników |
| Eksploruję nowy plik lub testuję schemat | Użyj OPENROWSET(BULK ...) (szybka iteracja, brak trwałych obiektów) |
| Importuję dane pliku do tabeli z przekształceniami | Użyj INSERT ... SELECT z OPENROWSET(BULK ...) |
| Potrzebuję ładu lub dostępu współdzielonego dla wielu użytkowników lub aplikacji | Użyj CREATE EXTERNAL TABLE, aby uprawnienia i metadane były scentralizowane |
| Pracuję w bazie danych SQL w usłudze Fabric | Użyj OPENROWSET(BULK ...) dla zapytań ad hoc OneLake lub tabel zewnętrznych do wielokrotnego użytku; w przypadku zewnętrznego magazynowania użyj skrótów OneLake |
Wybieranie scenariusza
Teraz, gdy znasz trzy podejścia, użyj jednego z poniższych przewodników, aby zaimplementować konkretny przypadek użycia.
Pliki zapytań (Parquet, CSV lub Delta)
Jeśli dane są w plikach Parquet, CSV lub Delta w usłudze Azure Blob Storage, usłudze ADLS Gen2, magazynie zgodnym z usługą S3 lub oneLake, postępuj zgodnie z jednym z następujących przewodników:
| Scenario | Zalecany przewodnik | Platformy |
|---|---|---|
| Szybkie zapytanie ad hoc dotyczące pliku Parquet lub CSV | Użyj OPENROWSET. Brak wymaganej tabeli zewnętrznej |
SQL Server 2022 (16.x) i nowsze wersje, Azure SQL Database, Azure SQL Managed Instance, SQL Database in Fabric |
| Powtarzające się zapytania dotyczące plików Parquet ze schematem trwałym | Tworzenie tabeli zewnętrznej w formacie Parquet | SQL Server 2022 (16.x) i nowsze wersje, Azure SQL Database, Azure SQL Managed Instance, SQL Database in Fabric |
| Wykonywanie zapytań dotyczących plików CSV przy użyciu tabeli zewnętrznej | Tworzenie tabeli zewnętrznej z formatem pliku dla tekstu rozdzielanego | SQL Server 2019 (15.x) i nowsze wersje, Azure SQL Database, Azure SQL Managed Instance, SQL Database in Fabric |
| Wykonywanie zapytań względem tabel Delta Lake | Tworzenie tabeli zewnętrznej za pomocą polecenia FILE_FORMAT = DeltaLakeFileFormat |
SQL Server 2022 (16.x) i nowsze wersje |
| Eksportowanie wyników zapytania do plików Parquet lub CSV (CETAS) | Użyj CREATE EXTERNAL TABLE AS SELECT |
SQL Server 2022 (16.x) i nowsze wersje, Azure SQL Managed Instance |
Możesz również wykonać jeden z tych samouczków krok po kroku.
| Tutorial | Opis |
|---|---|
| Wprowadzenie do technologii PolyBase w programie SQL Server 2022 | Obejmuje nawigację OPENROWSET między plikami Parquet i CSV, tabelami zewnętrznymi i folderami. |
| Wirtualizuj plik Parquet w magazynie zgodnym z S3 za pomocą technologii PolyBase | Samouczek dotyczący programu SQL Server 2022 (16.x) i nowszych wersji. |
| Wirtualizacja pliku CSV za pomocą technologii PolyBase | Samouczek dotyczący programu SQL Server 2022 (16.x) i nowszych wersji. |
| Wirtualizacja tabeli różnicowej za pomocą technologii PolyBase | Samouczek dotyczący programu SQL Server 2022 (16.x) i nowszych wersji. |
| Wirtualizacja danych za pomocą usługi Azure SQL Database (wersja zapoznawcza) | Przewodnik usługi Azure SQL Database dotyczący plików Parquet i CSV. |
| Wirtualizacja danych za pomocą usługi Azure SQL Managed Instance | Przewodnik po usłudze Azure SQL Managed Instance dla usług Parquet, CSV i CETAS. |
| Wirtualizacja danych w bazie danych SQL w Fabric | Przewodnik dotyczący bazy danych SQL w usłudze Fabric dla plików OneLake. |
Połącz się z innym wystąpieniem SQL Server, bazą danych Azure SQL lub zarządzanym wystąpieniem SQL
W programie SQL Server 2019 (15.x) i nowszych wersjach program PolyBase może wykonywać zapytania o tabele w innym wystąpieniu programu SQL Server, usłudze Azure SQL Database lub usłudze Azure SQL Managed Instance bez używania serwerów połączonych.
Ważna
Łącznik sqlserver:// nie jest obsługiwany w bazie danych SQL w Fabric. Łączniki PolyBase RDBMS używają uwierzytelniania SQL za pośrednictwem CREATE DATABASE SCOPED CREDENTIAL i nie obsługują uwierzytelniania Microsoft Entra ID, tożsamości zarządzanej ani głównego obiektu zabezpieczeń. Ponieważ baza danych SQL w platformie Fabric wymaga uwierzytelniania Microsoft Entra, nie można nawiązać z nią połączenia przy użyciu PolyBase.
| Krok | Co zrobić |
|---|---|
| 1. Zainstaluj program PolyBase | Instalowanie programu PolyBase w systemie Windows lub instalowanie programu PolyBase w systemie Linux |
| 2. Tworzenie poświadczeń |
CREATE DATABASE SCOPED CREDENTIAL z nazwą logowania docelowego |
| 3. Tworzenie zewnętrznego źródła danych | CREATE EXTERNAL DATA SOURCE ... WITH (LOCATION = 'sqlserver://<server>') |
| 4. Tworzenie tabeli zewnętrznej | CREATE EXTERNAL TABLE ... WITH (LOCATION = '<db>.<schema>.<table>') |
| 5. Zapytanie (Kwerenda) | SELECT * FROM <external_table> |
Wskazówka
Łącznik programu SQL Server (sqlserver://) działa również dla usług Azure SQL Database i Azure SQL Managed Instance. Użyj tych samych kroków i ustaw punkt końcowy na LOCATION usługi Azure SQL (na przykład sqlserver://myserver.database.windows.net).
Aby uzyskać szczegółowy przewodnik, zobacz Configure PolyBase to access external data in SQL Server (Konfigurowanie programu PolyBase w celu uzyskania dostępu do danych zewnętrznych w programie SQL Server).
Nawiązywanie połączenia z bazą danych Oracle, Teradata lub MongoDB
Program SQL Server 2019 (15.x) i nowsze wersje mogą wykonywać zapytania do Oracle, Teradata, MongoDB i Cosmos DB za pomocą łączników ODBC PolyBase.
| Źródło danych | Przewodnik | Wymagania |
|---|---|---|
| Oracle | Konfigurowanie programu PolyBase w celu uzyskiwania dostępu do danych zewnętrznych w programie Oracle | SQL Server 2019 (15.x) i nowsze wersje, sterowniki klienta Oracle |
| Teradata | Konfigurowanie programu PolyBase w celu uzyskiwania dostępu do danych zewnętrznych w usłudze Teradata | SQL Server 2019 (15.x) i nowsze wersje, sterownik Teradata ODBC |
| MongoDB / Cosmos DB | Konfigurowanie programu PolyBase w celu uzyskiwania dostępu do danych zewnętrznych w bazie danych MongoDB | SQL Server 2019 (15.x) i nowsze wersje, sterownik OdBC bazy danych MongoDB |
| Dowolne źródło ODBC | Konfigurowanie programu PolyBase w celu uzyskiwania dostępu do danych zewnętrznych przy użyciu typów ogólnych ODBC | SQL Server 2019 (15.x) i nowsze wersje (Windows) (System Linux rozpoczynający się od programu SQL Server 2025 (17.x)) |
Nawiązywanie połączenia z usługą Azure Blob Storage lub ADLS Gen2
| Platforma SQL | Opcje uwierzytelniania | Przewodnik |
|---|---|---|
| SQL Server 2022 (16.x) i nowsze wersje | Token SAS, klucz dostępu, tożsamość zarządzana (począwszy od programu SQL Server 2025 (17.x)) | Konfigurowanie programu PolyBase w celu uzyskiwania dostępu do danych zewnętrznych w usłudze Azure Blob Storage |
| SQL Server 2019 (15.x) | Klucz dostępu (za pośrednictwem łącznika usługi Hadoop) | Konfigurowanie programu PolyBase w celu uzyskiwania dostępu do danych zewnętrznych w usłudze Azure Blob Storage |
| Azure SQL Database | Token SAS, zarządzana tożsamość, przekazywanie bezpośrednie w Microsoft Entra | Wirtualizacja danych za pomocą usługi Azure SQL Database (wersja zapoznawcza) |
| Azure SQL Managed Instance | Token SAS, zarządzana tożsamość | Wirtualizacja danych za pomocą usługi Azure SQL Managed Instance |
W programie SQL Server 2022 (16.x) zmieniono prefiksy identyfikatora URI. Podczas migracji z programu SQL Server 2019 (15.x) lub starszych wersji:
-
Azure Blob Storage: zmień
wasb[s]://naabs:// -
ADLS Gen2: zmiana
abfs[s]://naadls://
Aby uzyskać więcej informacji, zobacz Configure PolyBase to access external data in Azure Blob Storage (Konfigurowanie technologii PolyBase w celu uzyskania dostępu do danych zewnętrznych w usłudze Azure Blob Storage).
Nawiązywanie połączenia z magazynem obiektów zgodnym ze standardem S3
Program SQL Server 2022 (16.x) i nowsze wersje obsługują magazyn zgodny z protokołem S3, takie jak Amazon S3, MinIO i Ceph.
Aby uzyskać więcej informacji, zobacz Configure PolyBase to access external data in S3-compatible object storage (Konfigurowanie programu PolyBase w celu uzyskania dostępu do danych zewnętrznych w magazynie obiektów zgodnym z programem S3).
Eksport danych za pomocą CREATE EXTERNAL TABLE AS SELECT (CETAS)
Funkcja CETAS eksportuje wyniki zapytania do plików zewnętrznych (Parquet lub CSV) w usłudze Azure Blob Storage, usłudze ADLS Gen2 lub magazynie zgodnym z usługą S3.
| Platforma SQL | Wsparte | Formaty eksportu | Notatki |
|---|---|---|---|
| SQL Server 2022 (16.x) i nowsze wersje | Yes | Parquet, CSV | Wymaga konfiguracji serwera: zezwalaj na eksportowanie programu PolyBase |
| Azure SQL Managed Instance | Yes | Parquet, CSV | Domyślnie wyłączone |
| Azure SQL Database | Nie. | Żadne | Niedostępne |
| Baza danych SQL na platformie Fabric | Nie. | Żadne | Niedostępne |
Aby zapoznać się z dokumentacją Transact-SQL, zobacz CREATE EXTERNAL TABLE AS SELECT (CETAS).
Przykłady szybkiego startu
Przykład 1: Zapytanie ad hoc w pliku Parquet (OPENROWSET)
Nie jest wymagana tabela zewnętrzna. Działa w programie SQL Server 2022 (16.x) i nowszych wersjach, usługach Azure SQL Database, Azure SQL Managed Instance i SQL Database w usłudze Fabric.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Przykład 2: Tabela zewnętrzna oparta na CSV w Azure Blob Storage
Ten przykład działa na wszystkich platformach SQL, które obsługują program PolyBase.
Krok 1. Tworzenie klucza głównego bazy danych (DMK). Ten krok jest wymagany, ponieważ magazyn poświadczeń przechowuje sekret tokenu SAS. Ten krok można jednak wykonać, jeśli używasz tożsamości zarządzanej lub uwierzytelniania entra firmy Microsoft.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Krok 2. Tworzenie poświadczeń przy użyciu tokenu SAS. Pomiń początkowe
?.CREATE DATABASE SCOPED CREDENTIAL MyStorageCred WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<your_SAS_token>'; -- omit the leading '?'Krok 3. Tworzenie zewnętrznego źródła danych.
CREATE EXTERNAL DATA SOURCE MyAzureStorage WITH ( LOCATION = 'abs://mycontainer@mystorageaccount.blob.core.windows.net', CREDENTIAL = MyStorageCred );Krok 4. Tworzenie formatu pliku dla pliku CSV.
CREATE EXTERNAL FILE FORMAT CsvFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS ( FIELD_TERMINATOR = ',', STRING_DELIMITER = '"', FIRST_ROW = 2 ) );Krok 5. Tworzenie tabeli zewnętrznej.
CREATE EXTERNAL TABLE dbo.SalesExternal ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer NVARCHAR (100) ) WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/data/sales/', FILE_FORMAT = CsvFormat );Krok 6. Wykonywanie zapytań względem tabeli zewnętrznej.
SELECT * FROM dbo.SalesExternal WHERE OrderDate >= '2025-01-01';
Przykład 3. Wykonywanie zapytań względem tabeli w innym programie SQL Server
Ten przykład działa w programie SQL Server 2019 (15.x) i nowszych wersjach.
Krok 1. Utworzenie klucza głównego bazy danych (wymagane, ponieważ poświadczenia przechowują hasło).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Krok 2: Utwórz poświadczenie dla zdalnego wystąpienia programu SQL Server.
CREATE DATABASE SCOPED CREDENTIAL RemoteSqlCred WITH IDENTITY = 'remote_user', SECRET = '<password>';Krok 3. Tworzenie zewnętrznego źródła danych.
CREATE EXTERNAL DATA SOURCE RemoteSqlServer WITH ( LOCATION = 'sqlserver://remote-server.contoso.com', PUSHDOWN = ON, CREDENTIAL = RemoteSqlCred );Krok 4. Utworzenie tabeli zewnętrznej (trzyczęściowa nazwa w pliku
LOCATION).CREATE EXTERNAL TABLE dbo.RemoteCustomers ( CustomerId INT, CustomerName NVARCHAR (200) COLLATE SQL_Latin1_General_CP1_CI_AS ) WITH ( DATA_SOURCE = RemoteSqlServer, LOCATION = 'SalesDB.dbo.Customers' );Krok 5. Wykonywanie zapytań względem serwerów.
SELECT c.CustomerName, s.Amount FROM dbo.RemoteCustomers AS c INNER JOIN dbo.LocalSales AS s ON c.CustomerId = s.CustomerId;
Przykład 4. Eksportowanie wyników do Parquet poprzez CETAS
Działa w programie SQL Server 2022 (16.x) i nowszych wersjach usługi Azure SQL Managed Instance.
Krok 1: Włącz CETAS (tylko w SQL Server).
EXECUTE sp_configure 'allow polybase export', 1; RECONFIGURE;Krok 2. Tworzenie poświadczeń i źródła danych (ponowne użycie z wcześniejszych przykładów).
Krok 3. Tworzenie formatu pliku dla eksportu Parquet.
CREATE EXTERNAL FILE FORMAT ParquetFormat WITH ( FORMAT_TYPE = PARQUET );Krok 4. Eksportowanie wyników zapytania.
CREATE EXTERNAL TABLE dbo.Sales2025Export WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/exports/sales_2025.parquet', FILE_FORMAT = ParquetFormat ) AS SELECT * FROM Sales.Orders WHERE OrderDate >= '2025-01-01';
Bloki konstrukcyjne języka T-SQL dla technologii PolyBase
Przed zaimplementowaniem dowolnego scenariusza zapoznaj się z podstawowymi obiektami języka T-SQL używanymi przez program PolyBase i sposobem ich dopasowania do siebie:
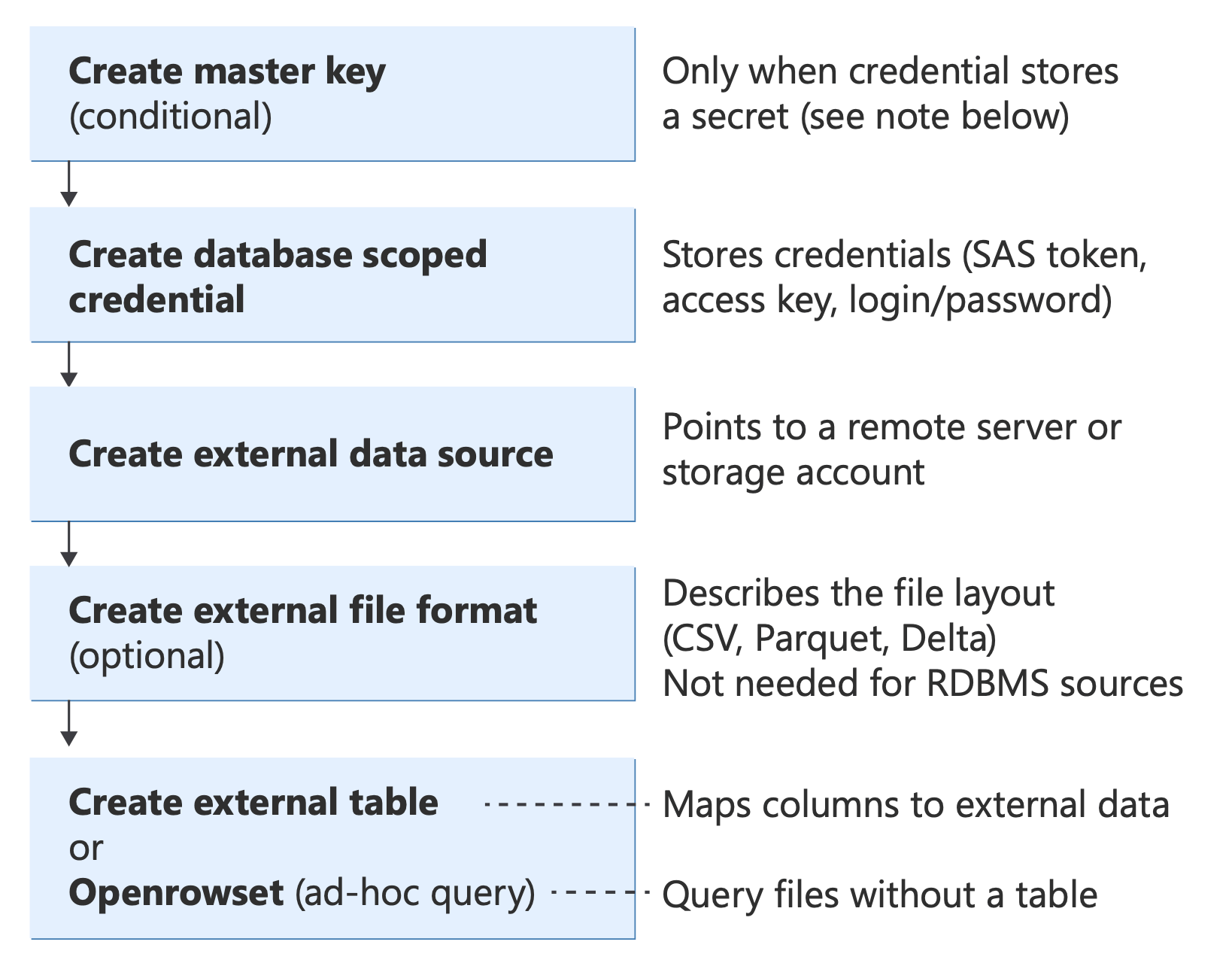
Diagram przedstawiający obiekty T-SQL programu PolyBase i ich relacje od uwierzytelniania (klucz master, poświadczenia) poprzez źródła danych i formaty plików do metod zapytań (Tabela Zewnętrzna, OPENROWSET, BULK INSERT, CETAS).
Aby uzyskać informacje na temat tych instrukcji języka T-SQL, zobacz:
- TWORZENIE ZEWNĘTRZNEGO ŹRÓDŁA DANYCH
- UTWÓRZ ZEWNĘTRZNY FORMAT PLIKU
- UTWÓRZ TABELĘ ZEWNĘTRZNĄ
- OPENROWSET
- UTWÓRZ ZEWNĘTRZNĄ TABELĘ Z WYBOREM (CETAS)
Aby uzyskać pełną dokumentację Transact-SQL dla wszystkich obiektów, zobacz Dokumentacja Transact-SQL technologii PolyBase.
Ważna
Sprawdź mapowanie typów danych dla formatu pliku zewnętrznego. Podczas tworzenia formatu pliku zewnętrznego lub wykonywania zapytań dotyczących plików przy użyciu programu OPENROWSETPolyBase automatycznie mapuje typy danych źródłowych (Parquet, CSV, Delta, Oracle, Teradata, MongoDB) na typy danych programu SQL Server. Niezgodne typy mogą powodować ciche obcinanie, utratę precyzji lub błędy zapytań. Na przykład Parquet DECIMAL(38,18) mapuje na DECIMAL(18,0). Przed zdefiniowaniem kolumn tabeli zewnętrznej lub klauzuli WITH przejrzyj tabele mapowania. Aby uzyskać pełną dokumentację, zobacz Mapowanie typów za pomocą technologii PolyBase.
Kiedy jest wymagane utworzenie klucza głównego?
Klucz główny bazy danych (DMK) jest tworzony przy użyciu CREATE MASTER KEY składni. DMK szyfruje sekrety przechowywane w ramach poświadczeń bazodanowych. Jest to wymagane tylko wtedy, gdy poświadczenie zawiera wartość wpisu tajnego, czyli w przypadku przechowywania hasła, tokenu lub klucza dostępu.
Klucz DMK jest wymagany (poświadczenia przechowują tajne informacje):
Typ uwierzytelniania IDENTITYwartośćPosiada tajemnicę DMK token SAS 'SHARED ACCESS SIGNATURE'Yes Wymagane Klucz dostępu S3 'S3 ACCESS KEY'Yes Wymagane Logowanie SQL / uwierzytelnianie podstawowe '<username>'Yes Wymagane Klucz dostępu do konta przechowywania '<storage_account_name>'Yes Wymagane DMK nie jest wymagany (żaden sekret nie jest przechowywany):
Typ uwierzytelniania IDENTITYwartośćMa tajemnicę DMK Zarządzana Tożsamość 'Managed Identity'Nie. Niewymagane Microsoft Entra ID 'User Identity'lub'Managed Identity'Nie. Niewymagane
Wskazówka
Jeśli w instrukcji CREATE DATABASE SCOPED CREDENTIAL nie ma wpisu tajnego, nie potrzebujesz klucza DMK. Zarządzana tożsamość i uwierzytelnianie Microsoft Entra ID przekazuje zaufanie do platformy. Baza danych nie przechowuje haseł ani tokenów.
Przykłady:
W tym przykładowym zapytaniu wymagany jest DMK (poświadczenie zawiera token SAS).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';
CREATE DATABASE SCOPED CREDENTIAL SasCred
WITH IDENTITY = 'SHARED ACCESS SIGNATURE',
SECRET = '<your_SAS_token>';
W tym przykładowym zapytaniu klucz DMK nie jest wymagany (tożsamość zarządzana, bez hasła).
CREATE DATABASE SCOPED CREDENTIAL ManagedIdentityCred
WITH IDENTITY = 'Managed Identity';
W tym przykładowym zapytaniu klucz DMK nie jest wymagany (przekazywanie w usłudze Microsoft Entra, bez konieczności podawania hasła).
CREATE DATABASE SCOPED CREDENTIAL EntraIdCred
WITH IDENTITY = 'User Identity';
Zdalny dostęp do danych za pomocą zestawu OPENROWSET i tabel zewnętrznych
Program SQL Server oferuje trzy odrębne podejścia do wykonywania zapytań dotyczących danych zdalnych. Możesz wybrać odpowiednie podejście, gdy rozumiesz różnice w składni, uwierzytelnianiu i architekturze.
| Metoda | Składnia | Nawiązuje połączenie z | Uwierzytelnianie | Usługi PolyBase | Platformy |
|---|---|---|---|---|---|
| Zapytania OLE DB | OPENROWSET(provider, connection, query) |
Dowolne źródło OLE DB za pośrednictwem bazy danych MSOLEDBSQL, SQLOLEDB lub innych dostawców | Uwierzytelnianie SQL, uwierzytelnianie systemu Windows, Microsoft Entra ID (MSOLEDBSQL) | Nie. | SQL Server (wszystkie obsługiwane wersje) |
| Zapytania dotyczące plików | OPENROWSET(BULK ...) |
Pliki na dysku lokalnym, sieci lub w chmurze (Azure Blob, ADLS, S3, OneLake) | Token SAS, klucz dostępu, tożsamość zarządzana, Microsoft Entra ID | Tak dla chmury*; Nie dla lokalnego | SQL Server 2005; SQL Server 2022 (16.x) i nowsze wersje (chmura); Azure SQL |
| Łączniki programu PolyBase |
CREATE EXTERNAL TABLEz użyciem CREATE EXTERNAL DATA SOURCE , sqlserver://, oracle://, teradata://, , mongodb://odbc:// |
Zdalne źródła programu SQL Server, Oracle, Teradata, MongoDB, ODBC | Tylko uwierzytelnianie SQL | Yes | SQL Server 2019 (15.x) i nowsze wersje (Windows); SQL Server 2025 (17.x) i nowsze wersje (Linux) |
Usługi PolyBase są wymagane do dostępu do plików w chmurze w programie SQL Server 2019 (15.x) i programie SQL Server 2022 (16.x). Program SQL Server 2025 (17.x) i nowsze wersje mają natywną obsługę plików w chmurze i nie wymagają już PolyBase dla plików CSV, Parquet lub Delta.
Kiedy należy używać każdego podejścia
Użyj OLE DB OPENROWSET dla:
- Szybkie, jednorazowe zapytania ad hoc bez tworzenia obiektów trwałych
- Microsoft Entra ID lub uwierzytelnianie za pomocą zarządzanej tożsamości (za pomocą MSOLEDBSQL)
- Unikanie zależności usługi PolyBase
- Nawiązywanie połączenia z dowolnym źródłem danych za pomocą dostawcy OLE DB
Użyj pliku OPENROWSET(BULK) dla:
- Eksplorowanie plików ad hoc i odnajdywanie schematów
- Szybkie przekształcenia i podglądy przed zatwierdzeniem definicji tabeli
- Elastyczne przekształcenia kolumn bezpośrednio w procesie (rzutowanie, filtrowanie, kolumny obliczeniowe)
- Dane, które nie zmieniają się często i nie wymagają trwałych metadanych
Użyj łączników programu PolyBase z funkcją CREATE EXTERNAL TABLE , aby:
- Trwałe definicje tabel wielokrotnego użytku, do których uzyskuje dostęp wielu użytkowników lub aplikacji
- Obciążenia produkcyjne wymagające statystyk i optymalizacji planu zapytań
- Obliczenia przenoszone do źródeł zdalnych (filtry przenoszone do Oracle, SQL Server itp.)
- Współzarządzanie i zabezpieczenia (po utworzeniu użytkownicy potrzebują tylko
SELECTuprawnień) - Jeśli masz uwierzytelnianie SQL dostępne dla źródła zdalnego
OPENROWSET (OLE DB) — zapytania zdalne ad hoc (brak wymaganych usług PolyBase)
Formularz OPENROWSET OLE DB łączy się ze zdalnym źródłem danych za pośrednictwem dostawcy OLE DB, wykonuje zapytanie przekazywane i zwraca wyniki jako zestaw wierszy. Jest to jednorazowa alternatywa ad hoc dla serwera połączonego. Nie są tworzone trwałe metadane. Ta składnia nie wymaga usług PolyBase i nie obsługuje plików w chmurze ani zewnętrznych źródeł danych.
To przykładowe zapytanie łączy się ze zdalnym programem SQL Server za pośrednictwem ole DB (a nie z technologią PolyBase).
SELECT *
FROM OPENROWSET (
'MSOLEDBSQL',
'Server=remote-server;Database=AdventureWorks;Trusted_Connection=yes;',
'SELECT TOP 10 * FROM AdventureWorks.Sales.SalesOrderHeader'
);
OPENROWSET(BULK) — zapytania oparte na plikach (PolyBase)
Forma BULKOPENROWSET odczytuje dane bezpośrednio z plików. W programie SQL Server 2019 (15.x) i starszych wersjach jest odczytywany ze ścieżek plików lokalnych lub UNC i wymaga pliku formatu. W programie SQL Server 2022 (16.x) i nowszych wersjach można odczytywać z magazynu w chmurze przy użyciu parametrów DATA_SOURCE i FORMAT. To podejście jest zintegrowaną z technologią PolyBase wersją używaną do wirtualizacji danych.
W kontekście technologii PolyBase i wirtualizacji danych, gdy ten przewodnik odwołuje się do OPENROWSET, oznacza to składnię OPENROWSET(BULK ...) z klauzulą FORMAT do zapytań dotyczących plików zewnętrznych.
Przykłady:
To przykładowe zapytanie odczytuje plik Parquet z usługi Azure Blob Storage (SQL Server 2022 i nowsze wersje).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'data/sales/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET'
) AS [result];
To przykładowe zapytanie odczytuje plik Parquet ze ścieżką śródliniową (Azure SQL Database, Azure SQL Managed Instance).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Kiedy należy używać tabel OPENROWSET czy tabel zewnętrznych
Zarówno OPENROWSET(BULK ...), jak i zewnętrzne tabele umożliwiają wykonywanie zapytań dotyczących danych zewnętrznych przy użyciu języka T-SQL, ale są zaprojektowane do różnych przypadków użycia. W poniższej tabeli podsumowano kluczowe różnice, które pomogą Ci zdecydować, które podejście pasuje do danego scenariusza.
| Zdolność | OPENROWSET(BULK ...) |
Tabela zewnętrzna |
|---|---|---|
| Przeznaczenie | Eksploracja ad hoc i jednorazowe zapytania | Trwała, wielokrotnego użytku definicja tabeli |
| Metadane przechowywane w bazie danych | Nie. Nic nie jest zapisywane po uruchomieniu zapytania | Tak. Definicja tabeli, źródło danych i format pliku są przechowywane jako obiekty bazy danych |
| Definicja schematu | Wnioskowane automatycznie z pliku (Parquet) lub określone w tekście z klauzulą WITH |
Zdefiniowano jawnie w oświadczeniu CREATE EXTERNAL TABLE |
| Uprawnienia | Wymaga ADMINISTER BULK OPERATIONS lub ADMINISTER DATABASE BULK OPERATIONS |
Standardowe SELECT uprawnienie do tabeli jest wystarczające po utworzeniu. |
| Obliczone kolumny | Tak. Dodaj wyrażenia i obliczone kolumny na SELECT liście; funkcje metadanych, takie jak filename() i filepath() są dostępne tylko tutaj. |
Nie. Stała lista kolumn; wykonywanie przekształceń w widoku lub w zapytaniu, które odczytuje tabelę zewnętrzną |
| Statystyki | Azure SQL: ręczne statystyki jednokolumnowe za pośrednictwem metody sys.sp_create_openrowset_statistics; SQL Server 2022 (16.x) i nowsze wersje: autotworzenie statystyk dla predykatów (brak ręcznych statystyk w programie SQL Server). Zobacz statystyki ręczne OPENROWSET. |
Pełna CREATE STATISTICS obsługa na wszystkich platformach oraz automatyczne tworzenie w programie SQL Server 2022 (16.x) i nowszych wersjach. Zobacz Tworzenie ręcznych statystyk tabeli zewnętrznej. |
| Wypychanie | Ograniczona obsługa. Silnik może przesyłać filtry do skanowania plików, ale nie dokonuje przesyłania do zdalnych źródeł RDBMS | Tak. Obsługuje obliczenia typu pushdown dla konektorów RDBMS (SQL Server, Oracle, Teradata, MongoDB) |
| Najlepsze dla | Eksploracja danych, odnajdywanie schematów, tworzenie prototypów zapytań, jednorazowe ładowanie danych, elastyczne przekształcenia | Obciążenia produkcyjne, powtarzające się zapytania, dostęp współdzielony przez użytkowników, dashboardy i raporty |
Użyj OPENROWSET, gdy wymagasz elastyczności
Służy OPENROWSET do eksplorowania pliku, testowania różnych schematów lub dodawania obliczonych kolumn i przekształceń bez tworzenia obiektów trwałych. Można na przykład wyodrębnić ścieżkę pliku jako kolumnę, rzutować typy danych w tekście lub filtrować wyrażenia obliczone w jednym zapytaniu.
To przykładowe zapytanie zawiera obliczone kolumny i przekształcenia:
SELECT result.filename() AS [FileName],
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
CAST (OrderDate AS DATE) AS OrderDate,
Amount,
OrderDate
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025';
Wskazówka
Funkcje filepath() i filename() są dostępne w usługach Azure SQL Database, Azure SQL Managed Instance i SQL Server 2022 (16.x) i nowszych wersjach. Umożliwiają one filtrowanie części ścieżki pliku (eliminacja partycji) i uwidocznienie nazwy pliku źródłowego jako kolumny, która nie jest bezpośrednio możliwa w przypadku tabel zewnętrznych.
Używanie tabel zewnętrznych, gdy potrzebujesz trwałości i ładu
Użyj tabel zewnętrznych, gdy wielu użytkowników lub aplikacji musi wielokrotnie wykonywać zapytania dotyczące tych samych danych zewnętrznych. Należy zdefiniować schemat, źródło danych i poświadczenia raz i zapisać je w bazie danych. Konsumenci potrzebują tylko SELECT uprawnień w tabeli.
Tabele zewnętrzne obsługują również statystyki, których optymalizator zapytań używa do tworzenia lepszych planów wykonywania. Statystyki można utworzyć ręcznie lub zezwolić aparatowi na automatyczne tworzenie (SQL Server 2022 (16.x) i nowszych wersjach.
To przykładowe zapytanie tworzy statystyki dotyczące tabeli zewnętrznej w celu uzyskania lepszych planów zapytań.
CREATE STATISTICS Stats_OrderDate
ON dbo.SalesExternal(OrderDate)
WITH FULLSCAN;
Aby uzyskać więcej informacji na temat statystyk obu podejść, zobacz Zagadnienia dotyczące wydajności technologii PolyBase — Statystyki.
BULK INSERT vs OPENROWSET(BULK): Którego należy użyć?
Zarówno BULK INSERT, jak i OPENROWSET(BULK ...) importują dane z plików do programu SQL Server z użyciem tej samej podstawowej mechaniki ładowania zbiorczego. Różnią się one jednak składnią, elastycznością i tym, co można zrobić z wynikami. Poniższa tabela zawiera podsumowanie kluczowych różnic:
Uwaga / Notatka
BULK INSERT nie jest dostępna w SQL database w Fabric. Dla Fabric używaj OPENROWSET(BULK ...) z OneLake.
| Zdolność | BULK INSERT |
OPENROWSET(BULK ...) |
|---|---|---|
| Podstawowy cel | Ładuje dane z pliku bezpośrednio do tabeli docelowej | Zwraca zestaw wierszy, który używasz w instrukcji SELECT lub INSERT ... SELECT |
| Wzorzec użycia | Autonomiczne wyrażenie: BULK INSERT <table> FROM '<file>' |
Należy użyć wewnątrz zapytania: SELECT * FROM OPENROWSET(BULK ...) lub INSERT INTO <table> SELECT * FROM OPENROWSET(BULK ...) |
| Wymaga tabeli docelowej? | Tak. Zawsze zapisuje dane bezpośrednio w tabeli | Nie. Można to SELECT używać bez potrzeby wstawiania, lub wstawić do dowolnej tabeli albo tabeli tymczasowej. |
| Przekształcenia kolumn podczas ładowania | Ograniczona obsługa. Dane przepływa z pliku do tabeli as-is (mapowanie kontrolowane przez format pliku lub kolejność kolumn) | Pełna obsługa. Możesz dodawać wyrażenia, CASTWHERE filtry, JOIN inne tabele i obliczone kolumny w otaczającym środowiskuSELECT |
| Wskazówki dotyczące tabeli | Klauzula zawiera obsługę WITH, BATCHSIZE, CHECK_CONSTRAINTS, FIRE_TRIGGERS, KEEPIDENTITY, KEEPNULLS, TABLOCK i więcej |
Obsługuje podpowiedzi tabeli za pomocą składni INSERT ... SELECT * FROM OPENROWSET(BULK ...) WITH (TABLOCK, IGNORE_CONSTRAINTS, ...) |
| Importowanie pojedynczej wartości dużego obiektu (LOB) | Niewspierane | Tak. Obsługuje SINGLE_BLOB, SINGLE_CLOB, SINGLE_NCLOB w celu zaimportowania całego pliku jako jedną wartość varbinary(max), varchar(max) lub nvarchar(max) |
| Formatowanie plików | Tak. Obsługiwane za pośrednictwem (XML i nie-XML) | Tak. Obsługiwane (XML i inne niż XML) |
| Dostęp do plików w chmurze (Azure Blob Storage, ADLS Gen2, S3) | Tak. Obsługiwane za pomocą DATA_SOURCE parametru (SQL Server 2017 (14.x) i nowszych wersji, Azure SQL) |
Tak. Obsługiwane za pomocą DATA_SOURCE parametru lub wbudowanego adresu URL z klauzulą FORMAT (SQL Server 2022 (16.x) i nowszymi wersjami, Azure SQL) |
| Pliki Parquet lub Delta | Niewspierane. Tylko format CSV lub tekst oddzielany | Tak. Obsługiwane z FORMAT = 'PARQUET' lub FORMAT = 'DELTA' (SQL Server 2022 (16.x) i nowsze wersje, Azure SQL) |
| Wymagane uprawnienie |
ADMINISTER BULK OPERATIONS lub ADMINISTER DATABASE BULK OPERATIONS, plus INSERT w tabeli docelowej |
ADMINISTER BULK OPERATIONS lub ADMINISTER DATABASE BULK OPERATIONS |
| Minimalne logowanie | Tak. Obsługiwane w ramach prostych lub zbiorczych modeli odzyskiwania za pomocą TABLOCK |
Tak. Obsługiwane przy użyciu INSERT ... SELECT i TABLOCK |
Kiedy wybrać opcję BULK INSERT
Użyj BULK INSERT, gdy masz proste załadowanie pliku do tabeli i nie trzeba przekształcać, filtrować ani łączyć danych przy imporcie. Używa prostszej składni dla plików CSV lub innych plików rozdzielonych:
To przykładowe zapytanie ładuje plik CSV z usługi Azure Blob Storage bezpośrednio do tabeli.
BULK INSERT Sales.Invoices
FROM 'invoices/inv-2025-01.csv'
WITH (
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n'
);
To przykładowe zapytanie ładuje plik lokalny z plikiem formatu do mapowania kolumn.
BULK INSERT dbo.Products
FROM 'C:\Data\products.csv'
WITH (
FORMATFILE = 'C:\Data\products.fmt',
FIRSTROW = 2,
TABLOCK
);
Kiedy wybrać opcję OPENROWSET(BULK)
Użyj OPENROWSET(BULK ...) , jeśli potrzebujesz co najmniej jednego z następujących warunków:
- Wykonywanie zapytań lub wyświetlanie podglądu danych pliku bez uprzedniego utworzenia tabeli.
- Przekształcanie, filtrowanie lub łączenie danych podczas importowania.
-
Załaduj pliki Parquet lub Delta (obsługuje tylko
OPENROWSETte formaty). -
Zaimportuj cały plik jako pojedynczą wartość LOB (
SINGLE_BLOB,SINGLE_CLOB,SINGLE_NCLOB).
To przykładowe zapytanie wyświetla podgląd pliku CSV z usługi Azure Blob Storage bez wstawiania danych w dowolnym miejscu.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ','
) AS src;
To przykładowe zapytanie wstawia dane z przekształcaniem i filtrowaniem.
INSERT INTO Sales.Invoices (InvoiceDate, Amount, Customer)
SELECT CAST (InvoiceDate AS DATE),
Amount * 1.1, -- Apply a 10% markup
UPPER(Customer)
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2
) WITH (
InvoiceDate VARCHAR (10),
Amount DECIMAL (18, 2),
Customer VARCHAR (100)
) AS src
WHERE Amount IS NOT NULL;
To przykładowe zapytanie ładuje plik Parquet (jest to niemożliwe z BULK INSERT).
INSERT INTO Sales.Invoices
SELECT *
FROM OPENROWSET (
BULK 'data/invoices/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET') AS src;
To przykładowe zapytanie importuje cały plik XML jako pojedynczą wartość varbinary(max).
INSERT INTO dbo.XmlDocuments (DocContent)
SELECT BulkColumn
FROM OPENROWSET (
BULK 'C:\Data\catalog.xml',
SINGLE_BLOB
) AS x;
Wskazówka
Jednym z podejść jest rozpoczęcie od OPENROWSET(BULK ...) w SELECT w celu eksploracji i weryfikacji danych plików, a następnie przełączenie się do BULK INSERT do końcowego obciążenia produkcyjnego, jeśli nie potrzebujesz przekształceń. Jeśli potrzebujesz obsługi Parquet lub Delta albo filtrowania wbudowanego, pozostań przy OPENROWSET.
Aby uzyskać więcej informacji, zobacz następujące powiązane przewodniki:
- Użyj funkcji BULK INSERT lub OPENROWSET(BULK...), aby zaimportować dane do programu SQL Server: szczegółowy przewodnik równoległy z zagadnieniami dotyczącymi zabezpieczeń.
-
Zbiorcze importowanie i eksportowanie danych (SQL Server): Omówienie wszystkich metod przenoszenia danych zbiorczych (bcp,
BULK INSERT,OPENROWSET). - BULK INSERT (Transact-SQL): pełna dokumentacja języka T-SQL.
- OPENROWSET BULK (Transact-SQL): pełna dokumentacja języka T-SQL.
- Przykłady zbiorczego dostępu do danych w usłudze Azure Blob Storage: przykłady równoległe przy użyciu obu metod w usłudze Azure Storage.
-
Zbiorcze importowanie danych dużych obiektów za pomocą dostawcy zbiorczego zestawu wierszy OPENROWSET (SQL Server):
SINGLE_BLOB,SINGLE_CLOBiSINGLE_NCLOBprzykłady. - Użyj pliku formatu do zbiorczego importowania danych (SQL Server): Używanie pliku formatu w obu metodach.
Przydatne funkcje metadanych
Podczas wykonywania zapytań dotyczących plików zewnętrznych za pomocą OPENROWSET lub tabel zewnętrznych można użyć kilku wbudowanych funkcji i procedur do sprawdzania metadanych plików, odkrywania schematów i implementowania zapytań uwzględniających partycje.
filepath() i nazwa pliku()
Funkcje filepath() i filename() zwracają części ścieżki pliku lub nazwy pliku dla każdego wiersza w zestawie wyników. Są one szczególnie przydatne w następujących celach:
Eliminacja partycji: filtruj według segmentów folderów (na przykład partycji roku/miesiąca/dnia), aby aparat odczytywał tylko pasujące pliki zamiast skanować wszystko.
Uwidacznianie metadanych źródłowych: dołącz nazwę pliku źródłowego lub ścieżkę jako kolumnę w wynikach zapytania, co jest przydatne w przypadku inspekcji lub debugowania.
| Function | Zwroty | Przykład |
|---|---|---|
filename() |
Nazwa pliku źródłowego (w tym rozszerzenie) pliku źródłowego dla każdego wiersza | sales_2025_01.parquet |
filepath(N) |
N-ty segment folderu z symbolu wieloznacznego (*) w ścieżce BULK, gdzie N zaczyna się od 1 |
W przypadku ścieżki sales/2025/01/*.parquetfilepath(1) zwraca wartość 2025, filepath(2) zwraca wartość01 |
Dotyczy: Azure SQL Database, Azure SQL Managed Instance, SQL Server 2022 (16.x) i nowsze wersje, baza danych SQL w sieci szkieletowej.
To przykładowe zapytanie używa filepath() funkcji eliminacji partycji i filename() identyfikowania plików źródłowych. Odczytuje tylko pliki w folderze /2025/ i odczytuje tylko pliki w podfolderze /06/ .
SELECT result.filename() AS SourceFile,
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
*
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025'
AND result.filepath(2) = '06';
Wskazówka
Umieść filtry w klauzuli WHERE, a nie w podzapytaniu lub CTE filepath(). Gdy filtr znajduje się w klauzuli WHERE, silnik może przeprowadzić usunięcie partycji na poziomie skanowania plików, co znacznie zmniejsza operacje wejścia/wyjścia.
sp_describe_first_result_set — odnajdywanie typów kolumn OPENROWSET
Podczas używania OPENROWSET z plikami Parquet, silnik automatycznie wnioskuje typy danych kolumn (wnioskowanie schematu). Wnioskowane typy mogą być większe niż jest to konieczne. Na przykład kolumny znaków są często wnioskowane jako varchar(8000), ponieważ metadane Parquet nie zawierają maksymalnej długości. Ten wybór może obniżyć wydajność i zużywać więcej pamięci.
Użyj sp_describe_first_result_set polecenia , aby sprawdzić wywnioskowany schemat przed zakończeniem zapytania. Po wyświetleniu wywnioskowanych typów określ w klauzuli WITH węższe typy, aby zwiększyć wydajność.
Krok 1. Sprawdzanie wywnioskowanego schematu.
EXECUTE sp_describe_first_result_set N' SELECT * FROM OPENROWSET( BULK ''abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet'', FORMAT = ''PARQUET'' ) AS result';Dane wyjściowe zawierają nazwę każdej kolumny, wywnioskowany typ danych, maksymalną długość, precyzję i skalę. Jeśli zobaczysz varchar(8000), gdzie wystarczy varchar(100), zmień to:
Krok 2. Używanie typów jawnych w celu uzyskania lepszej wydajności.
SELECT TOP 100 * FROM OPENROWSET ( BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet', FORMAT = 'PARQUET' ) WITH ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer VARCHAR (100) -- much narrower than the inferred varchar(8000) ) AS result;
Wnioskowanie schematu działa tylko z plikami Parquet. W przypadku plików CSV zawsze określ definicje kolumn w klauzuli WITH (for OPENROWSET) lub w instrukcji CREATE EXTERNAL TABLE .
sp_describe_first_result_set jest ogólną procedurą SQL Server i Azure SQL, ale jest szczególnie przydatna w przypadku OPENROWSET zapytań. Więcej informacji można znaleźć w sp_describe_first_result_set.
Wydajność, rozwiązywanie problemów i najlepsze rozwiązania
Po zaimplementowaniu wirtualizacji danych skorzystaj z tych przewodników, aby zoptymalizować wydajność, zdiagnozować problemy i zapewnić gotowość produkcyjną:
| Obszar | Artykuł | Szczegóły |
|---|---|---|
| Wydajność technologii PolyBase | zagadnienia dotyczące wydajności w programie PolyBase dla programu SQL Server | Statystyki, wypychanie, równoległość i zarządzanie pamięcią |
| Obliczenia wypychane | Obliczenia przesuwne w PolyBase | Określa, które działania są wypychane do zdalnego źródła |
| Jak sprawdzić, czy wystąpiło przesunięcie w dół | Jak sprawdzić, czy wystąpiło zewnętrzne wypychanie | Plany zapytań i dynamiczne widoki zarządzania |
| Troubleshooting | Monitorowanie i rozwiązywanie problemów z technologią PolyBase | Common errors and resolutions (Typowe błędy i rozwiązania) |
| Łączność protokołu Kerberos | Rozwiązywanie problemów z łącznością Kerberos w PolyBase | |
| Często zadawane pytania | Często zadawane pytania dotyczące technologii PolyBase | |
| Błędy i rozwiązania | błędów technologii PolyBase i możliwych rozwiązań |
Treści powiązane
- Wirtualizacja danych za pomocą technologii PolyBase w programie SQL Server
- Wprowadzenie do technologii PolyBase w programie SQL Server 2022
- PolyBase Transact-SQL dokumentacja
- Mapowanie typów za pomocą technologii PolyBase
- Instalowanie programu PolyBase w systemie Windows
- Instalowanie programu PolyBase w systemie Linux