Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Baza danych SQL w usłudze Microsoft Fabric
Baza danych SQL w usłudze Microsoft Fabric
Aparat bazy danych programu SQL Server przetwarza zapytania dotyczące różnych architektur magazynu danych, takich jak tabele lokalne, tabele partycjonowane i tabele rozproszone na wielu serwerach. W poniższych sekcjach opisano, jak program SQL Server przetwarza zapytania i optymalizuje ponowne użycie zapytań za pomocą buforowania planu wykonywania.
Tryby wykonywania
Silnik bazy danych programu SQL Server może przetwarzać instrukcje Transact-SQL przy użyciu dwóch odrębnych trybów przetwarzania:
- Wykonywanie trybu wierszowego
- Wykonywanie w trybie wsadowym
Wykonywanie trybu wierszowego
Wykonanie w trybie wiersza to metoda przetwarzania zapytań używana z tradycyjnymi tabelami RDBMS, gdzie dane są przechowywane w postaci wierszy. Gdy zapytanie jest wykonywane i uzyskuje dostęp do danych w tabelach z magazynowaniem wierszy, operatory drzewa wykonywania i operatory podrzędne odczytują każdy wymagany wiersz we wszystkich kolumnach określonych w schemacie tabeli. Z każdego odczytywanego wiersza program SQL Server pobiera następnie kolumny wymagane dla zestawu wyników, do których odwołuje się instrukcja SELECT, predykat JOIN lub predykat filtru.
Uwaga / Notatka
Wykonywanie trybu wiersza jest bardzo wydajne w scenariuszach OLTP, ale może być mniej wydajne podczas skanowania dużych ilości danych, na przykład w scenariuszach magazynowania danych.
Wykonywanie w trybie wsadowym
Wykonywanie w trybie wsadowym to metoda przetwarzania zapytań używana do przetwarzania wielu wierszy jednocześnie (stąd termin wsad). Każda kolumna w partii jest przechowywana jako wektor w osobnym obszarze pamięci, więc przetwarzanie w trybie wsadowym jest oparte na wektorach. Przetwarzanie w trybie wsadowym używa również algorytmów zoptymalizowanych pod kątem procesorów wielordzeniowych i zwiększonej przepływności pamięci, które znajdują się na nowoczesnym sprzęcie.
Po pierwszym wprowadzeniu wykonywanie trybu wsadowego zostało ściśle zintegrowane i zoptymalizowane pod kątem formatu magazynu kolumn. Jednak począwszy od SQL Server 2019 (15.x) oraz w usłudze Azure SQL Database, wykonywanie w trybie wsadowym nie wymaga już indeksów kolumnowych. Aby uzyskać więcej informacji, zobacz Tryb usługi Batch w magazynie wierszy.
Przetwarzanie w trybie wsadowym działa na skompresowanych danych, jeśli to możliwe, i eliminuje operator wymiany używany przez wykonywanie trybu wiersza. Rezultatem jest lepsza równoległość i szybsza wydajność.
Gdy zapytanie jest wykonywane w trybie wsadowym i uzyskuje dostęp do danych w indeksach kolumnowych, operatory drzewa i podrzędne odczytują wiele wierszy naraz w segmentach kolumnowych. Program SQL Server odczytuje tylko kolumny wymagane dla wyniku, do których odwołuje się instrukcja SELECT, predykat JOIN lub predykat filtru. Aby uzyskać więcej informacji na temat indeksów magazynu kolumn, zobacz Architektura indeksu magazynu kolumn.
Uwaga / Notatka
Wykonywanie trybu wsadowego to bardzo wydajne scenariusze magazynowania danych, w których duże ilości danych są odczytywane i agregowane.
Przetwarzanie instrukcji SQL
Przetwarzanie pojedynczej instrukcji Transact-SQL jest najbardziej podstawowym sposobem, w jaki program SQL Server wykonuje instrukcje Transact-SQL. Kroki używane do przetwarzania pojedynczej SELECT instrukcji, która odwołuje się tylko do lokalnych tabel bazowych (bez widoków lub tabel zdalnych) ilustruje podstawowy proces.
Pierwszeństwo operatora logicznego
Jeśli w instrukcji jest używany więcej niż jeden operator logiczny, NOT jest oceniany najpierw, następnie AND, a na koniec OR. Operatory arytmetyczne i bitowe są obsługiwane przed operatorami logicznymi. Aby uzyskać więcej informacji, zobacz Pierwszeństwo operatora.
W poniższym przykładzie warunek koloru dotyczy modelu produktu 21, a nie modelu produktu 20, ponieważ AND ma pierwszeństwo przed OR.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
Znaczenie zapytania można zmienić, dodając nawiasy, aby wymusić wykonanie OR jako pierwszego. Poniższe zapytanie znajduje tylko produkty w modelach 20 i 21, które są czerwone.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
Używanie nawiasów, nawet jeśli nie są wymagane, może zwiększyć czytelność zapytań i zmniejszyć prawdopodobieństwo popełnienia subtelnego błędu z powodu pierwszeństwa operatora. Używanie nawiasów nie wpływa znacząco na wydajność. Poniższy przykład jest bardziej czytelny niż oryginalny przykład, chociaż są one składniowo takie same.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
Optymalizowanie instrukcji SELECT
Instrukcja SELECT nie jest proceduralna; nie określa dokładnych kroków, których serwer bazy danych powinien użyć do pobrania żądanych danych. Oznacza to, że serwer bazy danych musi przeanalizować instrukcję, aby określić najbardziej wydajny sposób wyodrębniania żądanych danych. Jest to określane jako optymalizacja instrukcji SELECT . Składnik, który to robi, jest nazywany optymalizatorem zapytań. Dane wejściowe optymalizatora zapytań składają się z zapytania, schematu bazy danych (definicji tabeli i indeksu) oraz statystyk bazy danych. Dane wyjściowe optymalizatora zapytań to plan wykonywania zapytań, czasami określany jako plan zapytania lub plan wykonania. Zawartość planu wykonania została opisana bardziej szczegółowo w dalszej części tego artykułu.
Dane wejściowe i wyjściowe optymalizatora zapytań podczas optymalizacji pojedynczej SELECT instrukcji przedstawiono na poniższym diagramie:
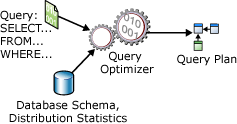
Instrukcja SELECT definiuje tylko następujące elementy:
- Format zestawu wyników. Jest to określane głównie na liście wyboru. Jednak inne klauzule, takie jak
ORDER BYiGROUP BYrównież wpływają na ostateczną formę zestawu wyników. - Tabele zawierające dane źródłowe. Jest to określone w klauzuli
FROM. - Sposób, w jaki tabele są logicznie powiązane na potrzeby instrukcji
SELECT. Jest to zdefiniowane w specyfikacjach sprzężeń, które mogą pojawić się w klauzuliWHERElub w klauzuli następującej poON:FROM. - Warunki, które muszą spełniać wiersze w tabelach źródłowych, aby kwalifikować się do instrukcji
SELECT. Określone są w klauzulachWHEREiHAVING.
Plan wykonywania zapytania to definicja następujących elementów:
Sekwencja, w której uzyskuje się dostęp do tabel źródłowych.
Zazwyczaj istnieje wiele sekwencji, w których serwer bazy danych może uzyskać dostęp do tabel bazowych w celu skompilowania zestawu wyników. Na przykład, jeśli instrukcjaSELECTodwołuje się do trzech tabel, serwer bazy danych może najpierw uzyskać dostęp doTableA, użyć danych zTableA, aby wyodrębnić pasujące wiersze zTableB, a następnie użyć danych zTableB, aby wyodrębnić dane zTableC. Inne sekwencje, w których serwer bazy danych może uzyskać dostęp do tabel, to:
TableC,TableB,TableAlub
TableB,TableA,TableClub
TableB,TableC,TableAlub
TableC,TableATableBMetody używane do wyodrębniania danych z każdej tabeli.
Ogólnie rzecz biorąc, istnieją różne metody uzyskiwania dostępu do danych w każdej tabeli. Jeśli wymagane jest tylko kilka wierszy z określonymi wartościami klucza, serwer bazy danych może użyć indeksu. Jeśli wszystkie wiersze w tabeli są wymagane, serwer bazy danych może zignorować indeksy i wykonać skanowanie tabeli. W przypadku gdy wymagane są wszystkie wiersze w tabeli, a istnieje indeks, którego kluczowe kolumny znajdują się wORDER BY, wykonanie skanowania indeksu zamiast skanowania tabeli może pomóc uniknąć oddzielnego sortowania zestawu wyników. Jeśli tabela jest bardzo mała, skanowanie tabel może być najbardziej wydajną metodą niemal całego dostępu do tabeli.Metody używane do obliczania obliczeń oraz sposób filtrowania, agregowania i sortowania danych z każdej tabeli.
W miarę uzyskiwania dostępu do danych z tabel istnieją różne metody wykonywania obliczeń na danych, takich jak wartości skalarne obliczeniowe, oraz agregowanie i sortowanie danych zgodnie z definicją w tekście zapytania, na przykład w przypadku używania klauzuliGROUP BYlubORDER BYoraz sposobu filtrowania danych, na przykład w przypadku używania klauzuliWHERElubHAVING.
Proces wybierania jednego planu wykonania z potencjalnie wielu możliwych planów jest określany jako optymalizacja. Optymalizator zapytań jest jednym z najważniejszych składników aparatu bazy danych. Chociaż proces analizy zapytania i wyboru planu przez optymalizator zapytań wiąże się z pewnym obciążeniem, jest ono zwykle redukowane kilkukrotnie, gdy optymalizator zapytań wybiera efektywny plan wykonania. Na przykład dwie firmy budowlane mogą mieć identyczne strategie dla domu. Jeśli jedna firma spędzi kilka dni na początku, aby zaplanować sposób budowy domu, a druga firma rozpocznie budowę bez planowania, firma, która zajmuje czas na zaplanowanie projektu prawdopodobnie zakończy się jako pierwsza.
Optymalizator zapytań programu SQL Server jest optymalizatorem opartym na kosztach. Każdy możliwy plan wykonania ma skojarzony koszt pod względem ilości używanych zasobów obliczeniowych. Optymalizator zapytań musi przeanalizować możliwe plany i wybrać ten z najniższym szacowanymi kosztami. Niektóre złożone SELECT instrukcje mają tysiące możliwych planów wykonania. W takich przypadkach optymalizator zapytań nie analizuje wszystkich możliwych kombinacji. Zamiast tego używa złożonych algorytmów do znalezienia planu wykonania, który ma koszt rozsądnie zbliżony do minimalnego możliwego kosztu.
Optymalizator zapytań programu SQL Server nie wybiera tylko planu wykonywania z najniższym kosztem zasobów; wybiera plan, który zwraca wyniki użytkownikowi z rozsądnym kosztem zasobów i zwraca wyniki najszybciej. Na przykład przetwarzanie zapytania równolegle zwykle zużywa więcej zasobów niż przetwarzanie seryjne, ale wykonuje zapytanie szybciej. Optymalizator zapytań programu SQL Server użyje równoległego planu wykonywania, aby zwrócić wyniki, jeśli obciążenie na serwerze nie zostanie naruszone.
Optymalizator zapytań programu SQL Server opiera się na statystykach dystrybucji, gdy szacuje koszty zasobów różnych metod wyodrębniania informacji z tabeli lub indeksu. Statystyki dystrybucji są przechowywane dla kolumn i indeksów oraz zawierają informacje o gęstości1 danych bazowych. Służy do wskazywania selektywności wartości w określonym indeksie lub kolumnie. Na przykład w tabeli reprezentującej samochody wiele samochodów ma tego samego producenta, ale każdy samochód ma unikatowy numer identyfikacyjny pojazdu (VIN). Indeks dotyczący VIN jest bardziej selektywny niż indeks dotyczący producenta, ponieważ VIN ma niższą gęstość niż producent. Jeśli statystyki indeksu nie są aktualne, optymalizator zapytań może nie dokonać najlepszego wyboru dla bieżącego stanu tabeli. Aby uzyskać więcej informacji na temat gęstości, zobacz Statystyki.
1 Gęstość definiuje rozkład unikatowych wartości, które istnieją w danych, lub średnią liczbę zduplikowanych wartości dla danej kolumny. W miarę spadku gęstości wybór wartości zwiększa się.
Optymalizator zapytań programu SQL Server jest ważny, ponieważ umożliwia serwerowi bazy danych dynamiczne dostosowywanie się do zmieniających się warunków w bazie danych bez konieczności wprowadzania danych od programisty lub administratora bazy danych. Dzięki temu programiści mogą skupić się na opisywaniu końcowego wyniku zapytania. Mogą ufać, że optymalizator zapytań programu SQL Server utworzy wydajny plan wykonywania dla stanu bazy danych za każdym razem, gdy instrukcja zostanie uruchomiona.
Uwaga / Notatka
Program SQL Server Management Studio ma trzy opcje wyświetlania planów wykonywania:
- Szacowany plan wykonania, który jest skompilowanym planem utworzonym przez optymalizator zapytań.
- Rzeczywisty plan wykonania, który jest taki sam jak skompilowany plan oraz jego kontekst wykonania. Obejmuje to informacje w czasie wykonywania dostępne po zakończeniu wykonywania, takie jak ostrzeżenia podczas wykonywania, lub w nowszych wersjach silnika bazy danych, czas, który upłynął oraz czas CPU używany podczas wykonywania.
- Statystyka zapytań na żywo, która jest taka sama jak skompilowany plan oraz kontekst wykonywania. Obejmuje to informacje o postępie wykonania programu w czasie rzeczywistym, które są aktualizowane co sekundę. Informacje o środowisku uruchomieniowym obejmują na przykład rzeczywistą liczbę wierszy przepływających przez operatory.
Przetwórz instrukcję SELECT
Podstawowe kroki używane przez program SQL Server do przetwarzania pojedynczej instrukcji SELECT obejmują następujące elementy:
- Analizator skanuje instrukcję
SELECTi dzieli ją na jednostki logiczne, takie jak słowa kluczowe, wyrażenia, operatory i identyfikatory. - Drzewo zapytań, czasami nazywane drzewem sekwencji, jest tworzone opisujące kroki logiczne wymagane do przekształcenia danych źródłowych w format wymagany przez zestaw wyników.
- Optymalizator zapytań analizuje różne sposoby uzyskiwania dostępu do tabel źródłowych. Następnie wybiera serię kroków, które zwracają wyniki najszybciej podczas korzystania z mniejszej liczby zasobów. Drzewo zapytań jest aktualizowane w celu zarejestrowania tej dokładnej serii kroków. Ostateczna, zoptymalizowana wersja drzewa zapytań jest nazywana planem wykonywania.
- Aparat relacyjny rozpoczyna wykonywanie planu wykonania. W miarę przetwarzania kroków wymagających danych z tabel podstawowych silnik relacyjny żąda, aby silnik pamięci przekazał dane z zestawów wierszy zamówionych przez silnik relacyjny.
- Silnik relacyjny przetwarza dane zwrócone przez silnik magazynowania w zdefiniowanym formacie dla zestawu wyników i zwraca zestaw wyników do klienta.
Stałe składanie i obliczanie wyrażeń
Program SQL Server ocenia niektóre wyrażenia stałe na wczesnym etapie w celu zwiększenia wydajności zapytań. Ta technika optymalizacji używana przez optymalizator zapytań ma na celu uproszczenie wyrażeń w czasie kompilacji, a nie w czasie wykonywania. Obejmuje to obliczanie wyrażeń stałych podczas kompilacji zapytań, dzięki czemu wynikowy plan wykonania jest bardziej wydajny. Jest to nazywane ciągłym składaniem. Stała jest literałem Transact-SQL, takim jak 3, , 'ABC''2005-12-31', 1.0e3lub 0x12345678. Na przykład wykonaj następujące zapytanie:
SELECT * FROM Orders WHERE OrderDate < DATEADD(day, 30 * 12, '2020-01-01');
Tutaj 30 * 12 jest wyrażeniem stałym. Program SQL Server może ocenić to podczas kompilacji i ponownie napisać zapytanie wewnętrznie jako:
SELECT * FROM Orders WHERE OrderDate < DATEADD(day, 360, '2020-01-01');
Wyrażenia składane
Program SQL Server używa stałego składania z następującymi typami wyrażeń:
- Wyrażenia arytmetyczne, takie jak
1 + 1i5 / 3 * 2, zawierają tylko stałe. - Wyrażenia logiczne, takie jak
1 = 1i1 > 2 AND 3 > 4, zawierające tylko stałe. - Wbudowane funkcje, które są uważane za składane przez serwer SQL, w tym
CASTiCONVERT. Ogólnie rzecz biorąc, funkcja wewnętrzna jest składana, jeśli jest funkcją tylko jego danych wejściowych, a nie innych informacji kontekstowych, takich jak opcje SET, ustawienia języka, opcje bazy danych i klucze szyfrowania. Funkcje niedeterministyczne nie są składane. Deterministyczne funkcje wbudowane są zawijalne, z pewnymi wyjątkami. - Deterministyczne metody typów definiowanych przez użytkownika CLR i deterministyczne funkcje skalarnych wartości zdefiniowane przez użytkownika CLR (począwszy od programu SQL Server 2012 (11.x)). Aby uzyskać więcej informacji, zobacz Constant Folding for CLR User-Defined Functions and Methods (Stałe składanie dla funkcji i metod CLR User-Defined).
Uwaga / Notatka
Wyjątek dotyczy dużych typów obiektów. Jeśli typ danych wyjściowych procesu składania jest dużym typem obiektu (tekst, ntext, obraz, nvarchar(max), varchar(max), varbinary(max) lub XML), program SQL Server nie składa wyrażenia.
Wyrażenia niefoldowalne
Wszystkie inne typy wyrażeń nie są składane. W szczególności następujące typy wyrażeń nie są składane:
- Wyrażenia niezdecydowane, takie jak wyrażenie, którego wynik zależy od wartości kolumny.
- Wyrażenia, których wyniki zależą od zmiennej lokalnej lub parametru, na przykład @x.
- Funkcje nieokreślone.
- Funkcje Transact-SQL zdefiniowane przez użytkownika1.
- Wyrażenia, których wyniki zależą od ustawień języka.
- Wyrażenia, których wyniki zależą od opcji SET.
- Wyrażenia, których wyniki zależą od opcji konfiguracji serwera.
1 Przed SQL Server 2012 (11.x) deterministyczne funkcje CLR zdefiniowane przez użytkownika zwracające wartości skalarne oraz metody typów CLR zdefiniowanych przez użytkownika nie podlegały optymalizacji składania.
Przykłady składanych i niefoldowalnych wyrażeń stałych
Rozważ następujące zapytanie:
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
PARAMETERIZATION Jeśli opcja bazy danych nie jest ustawiona na FORCED dla tego zapytania, wyrażenie 117.00 + 1000.00 jest oceniane i zastępowane przez jego wynik , 1117.00przed skompilowanie zapytania. Zalety tego stałego składania obejmują następujące elementy:
- Wyrażenie nie musi być obliczane wielokrotnie podczas wykonywania.
- Wartość wyrażenia po jego obliczeniu jest używana przez Optymalizator zapytań do oszacowania rozmiaru zestawu wyników części zapytania
TotalDue > 117.00 + 1000.00.
Z drugiej strony, jeśli dbo.f jest funkcją zdefiniowaną przez użytkownika skalarną, wyrażenie nie jest składane, ponieważ program SQL Server nie składa wyrażeń dbo.f(100) obejmujących funkcje zdefiniowane przez użytkownika, nawet jeśli są deterministyczne. Aby uzyskać więcej informacji na temat parametryzacji, zobacz Wymuszone parametryzacja w dalszej części tego artykułu.
Ocena wyrażeń
Ponadto niektóre wyrażenia, które nie są stałe złożone, ale których argumenty są znane w czasie kompilacji, niezależnie od tego, czy argumenty są parametrami lub stałymi, są oceniane przez narzędzie do szacowania rozmiaru zestawu wyników (kardynalności), który jest częścią optymalizatora podczas optymalizacji.
W szczególności następujące wbudowane funkcje i specjalne operatory są oceniane w czasie kompilacji, jeśli wszystkie ich dane wejściowe są znane: UPPER, LOWER, RTRIM, DATEPART( YY only ), GETDATE, CAST, i CONVERT. Następujące operatory są również oceniane w czasie kompilacji, jeśli wszystkie ich dane wejściowe są znane:
- Operatory arytmetyczne: +, -, *, /, jednoargumentowe —
- Operatory logiczne:
AND, ,ORNOT - Operatory porównania: <, >, <=, >=, <>,
LIKE,IS NULL,IS NOT NULL
Żadne inne funkcje lub operatory nie są oceniane przez optymalizator zapytań podczas szacowania kardynalności.
Przykłady obliczania wyrażeń w czasie kompilacji
Rozważ tę procedurę przechowywaną:
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
Podczas optymalizacji instrukcji SELECT w procedurze optymalizator zapytań próbuje ocenić oczekiwaną kardynalność zestawu wyników dla warunku OrderDate > @d+1. Wyrażenie @d+1 nie jest składane na stałe, ponieważ @d jest parametrem. Jednak w czasie optymalizacji jest znana wartość parametru. Dzięki temu optymalizator zapytań dokładnie oszacował rozmiar zestawu wyników, co pomaga wybrać dobry plan zapytania.
Teraz rozważmy przykład podobny do poprzedniego, z tą różnicą, że lokalna zmienna @d2 zastępuje @d+1 w zapytaniu, a wyrażenie jest ewaluowane w instrukcji SET zamiast w zapytaniu.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
Gdy instrukcja SELECT jest zoptymalizowana w SQL Server, wartość MyProc2 nie jest znana. pl-PL: W związku z tym optymalizator zapytań używa domyślnego oszacowania selektywności OrderDate > @d2, (w tym przypadku 30 procent).
Przetwarzanie innych oświadczeń
Podstawowe kroki opisane do przetwarzania SELECT instrukcji dotyczą innych instrukcji Transact-SQL, takich jak INSERT, UPDATEi DELETE.
UPDATE i DELETE instrukcje muszą być przeznaczone dla zestawu wierszy, które mają być modyfikowane lub usuwane. Proces identyfikowania tych wierszy jest tym samym procesem używanym do identyfikowania wierszy źródłowych, które przyczyniają się do zestawu wyników instrukcji SELECT . Instrukcje UPDATE i INSERT mogą zawierać instrukcje SELECT zawarte, które dostarczają wartości danych do zaktualizowania lub wstawienia.
Nawet instrukcje języka DDL (Data Definition Language), takie jak CREATE PROCEDURE lub ALTER TABLE, są ostatecznie przekształcane w serię operacji relacyjnych na tabelach katalogów systemowych, a czasami (na przykład ALTER TABLE ADD COLUMN) na tabelach danych.
Stoły robocze
Aparat relacyjny może wymagać utworzenia tabeli roboczej, aby wykonać operację logiczną określoną w instrukcji Transact-SQL. Tabele robocze to tabele wewnętrzne używane do przechowywania wyników pośrednich. Tabele robocze są generowane dla niektórych zapytań GROUP BY, ORDER BY lub UNION. Jeśli na przykład klauzula ORDER BY odwołuje się do kolumn, które nie są objęte żadnymi indeksami, aparat relacyjny może wymagać wygenerowania tabeli roboczej w celu sortowania zestawu wyników w żądanej kolejności. Tabele robocze są czasami używane jako szpule, które tymczasowo przechowują wynik wykonywania części planu zapytania. Stoły robocze są tworzone w tempdb i są usuwane automatycznie, gdy nie są już potrzebne.
Wyświetlanie rozdzielczości
Procesor zapytań programu SQL Server traktuje indeksowane i nieindeksowane widoki inaczej:
- Wiersze indeksowanego widoku są przechowywane w bazie danych w tym samym formacie co tabela. Jeśli optymalizator zapytań zdecyduje się użyć widoku indeksowanego w planie zapytania, widok indeksowany jest traktowany tak samo jak tabela podstawowa.
- Przechowywana jest tylko definicja widoku nieindeksowanego, a nie wierszy widoku. Optymalizator zapytań uwzględnia logikę z definicji widoku do planu wykonywania, który jest kompilowany dla instrukcji Transact-SQL odwołującej się do widoku nieindeksowanego.
Logika używana przez optymalizator zapytań programu SQL Server do decydowania, kiedy należy używać widoku indeksowanego, jest podobna do logiki używanej do decydowania, kiedy używać indeksu w tabeli. Jeśli dane w widoku indeksowanym obejmują wszystkie lub część instrukcji Transact-SQL, a optymalizator zapytań określa, że indeks w widoku jest ścieżką dostępu o niskich kosztach, optymalizator zapytań wybierze indeks niezależnie od tego, czy widok jest przywoływane według nazwy w zapytaniu.
Gdy instrukcja Transact-SQL odwołuje się do widoku nieindeksowanego, analizator i optymalizator zapytań analizują źródło zarówno instrukcji Transact-SQL, jak i widoku, a następnie rozpoznają je w jednym planie wykonywania. Nie ma jednego planu dla instrukcji Transact-SQL i oddzielnego planu dla widoku.
Rozważmy na przykład następujący widok:
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
Na podstawie tego widoku obie te instrukcje Transact-SQL wykonują te same operacje w tabelach podstawowych i generują te same wyniki:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
Funkcja showplan programu SQL Server Management Studio pokazuje, że aparat relacyjny tworzy ten sam plan wykonywania dla obu tych SELECT instrukcji.
Korzystanie ze wskazówek w widokach
Wskazówki umieszczone w widokach w zapytaniu mogą powodować konflikt z innymi wskazówkami, które są wykrywane po rozwinięciu widoku w celu uzyskania dostępu do tabel podstawowych. W takim przypadku zapytanie zwraca błąd. Rozważmy na przykład następujący widok, który zawiera wskazówkę tabeli w definicji:
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
Teraz załóżmy, że wprowadzisz to zapytanie:
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
Zapytanie kończy się niepowodzeniem, ponieważ wskazówka SERIALIZABLE zastosowana w widoku Person.AddrState w zapytaniu jest propagowana do tabel Person.Address i Person.StateProvince w widoku po rozwinięciu. Jednak rozszerzenie widoku również ujawnia NOLOCK wskazówkę dotyczącą elementu Person.Address. Ponieważ wskazówki SERIALIZABLE i NOLOCK są sprzeczne, wynikowe zapytanie jest niepoprawne.
Niektóre wskazówki tabeli (PAGLOCK, NOLOCK, ROWLOCK, TABLOCK, TABLOCKX) z sobą kolidują, podobnie jak wskazówki tabeli (HOLDLOCK, NOLOCK, READCOMMITTED, REPEATABLEREAD, SERIALIZABLE).
Wskazówki mogą propagować się przez poziomy zagnieżdżonych widoków. Na przykład załóżmy, że zapytanie stosuje wskazówkę HOLDLOCK w widoku v1. Po rozwinięciu v1 odkrywamy, że widok v2 jest częścią jego struktury.
v2Definicja zawiera wskazówkę NOLOCK dotyczącą jednej z jej tabel podstawowych. Jednak ta tabela także dziedziczy wskazówkę z zapytania w widoku HOLDLOCK. Ponieważ element NOLOCK i HOLDLOCK wskazuje konflikt, zapytanie kończy się niepowodzeniem.
Gdy wskazówka FORCE ORDER jest używana w zapytaniu zawierającym widok, kolejność łączenia tabel w widoku jest określana przez położenie widoku w uporządkowanej konstrukcji. Na przykład następujące zapytanie wybiera spośród trzech tabel i widoku:
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
Element View1 jest zdefiniowany w następujący sposób:
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
Kolejność sprzężenia w planie zapytania to Table1, Table2, TableA, TableB, Table3.
Rozwiązywanie problemów z indeksami w widokach
Podobnie jak w przypadku dowolnego indeksu, program SQL Server decyduje się na użycie widoku indeksowanego w planie zapytania tylko wtedy, gdy optymalizator zapytań określi, że jest to korzystne.
Indeksowane widoki można tworzyć w dowolnej wersji programu SQL Server. W niektórych wersjach niektórych starszych wersji programu SQL Server optymalizator zapytań automatycznie uwzględnia widok indeksowany. W niektórych wersjach starszych wersji programu SQL Server do korzystania z widoku NOEXPAND indeksowanego należy użyć wskazówki tabeli. Automatyczne używanie widoku indeksowanego przez optymalizator zapytań jest obsługiwane tylko w określonych wersjach programu SQL Server. Usługi Azure SQL Database i Azure SQL Managed Instance obsługują również automatyczne korzystanie z indeksowanych widoków bez określania wskazówki NOEXPAND.
Optymalizator zapytań programu SQL Server używa widoku indeksowanego, gdy spełnione są następujące warunki:
- Te opcje sesji są ustawione na :
ONANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
- Opcja
NUMERIC_ROUNDABORTsesji jest ustawiona na WYŁĄCZONE. - Optymalizator zapytań znajduje dopasowanie między kolumnami indeksu widoku i elementami w zapytaniu, na przykład:
- Predykaty warunku wyszukiwania w klauzuli WHERE
- Operacje sprzężenia
- Funkcje agregujące
-
GROUP BYKlauzule - Odwołania do tabel
- Szacowany koszt użycia indeksu ma najniższy koszt wszelkich mechanizmów dostępu uwzględnionych przez optymalizator zapytań.
- Każda tabela przywoływana w zapytaniu (bezpośrednio lub poprzez rozszerzenie widoku w celu uzyskania dostępu do jego bazowych tabel), która odpowiada odwołaniu do tabeli w widoku indeksowanym, musi mieć zastosowany ten sam zestaw wskazówek w zapytaniu.
Uwaga / Notatka
Wskazówki READCOMMITTED i READCOMMITTEDLOCK są zawsze traktowane jako różne wskazówki w tym kontekście, niezależnie od bieżącego poziomu izolacji transakcji.
Oprócz wymagań dotyczących SET opcji i wskazówek tabeli są to te same reguły, których używa Optymalizator zapytań w celu określenia, czy indeks tabeli obejmuje zapytanie. Nie trzeba określać żadnych innych elementów w zapytaniu, aby można było użyć indeksowanego widoku.
Zapytanie nie musi jawnie odwoływać się do widoku indeksowanego w FROM klauzuli optymalizatora zapytań w celu korzystania z widoku indeksowanego. Jeśli zapytanie zawiera odwołania do kolumn w tabelach bazowych, które są również obecne w widoku indeksowanym, a optymalizator zapytań szacuje, że przy użyciu indeksowanego widoku zapewnia najniższy mechanizm dostępu do kosztów, Optymalizator zapytań wybiera widok indeksowany, podobnie jak w przypadku wybierania indeksów tabel bazowych, gdy nie są bezpośrednio przywoływane w zapytaniu. Optymalizator zapytań może wybrać widok zawierający kolumny, do których nie odwołuje się zapytanie, o ile widok oferuje najniższą opcję kosztu obejmującą co najmniej jedną kolumnę określoną w zapytaniu.
Optymalizator zapytań traktuje widok indeksowany przywoływany w klauzuli FROM jako widok standardowy. Optymalizator zapytań rozszerza definicję widoku do zapytania na początku procesu optymalizacji. Następnie jest wykonywane dopasowywanie indeksowanego widoku. Widok indeksowany może być używany w końcowym planie wykonywania wybranym przez Optymalizator zapytań lub zamiast tego plan może zmaterializować niezbędne dane z widoku, korzystając z tabel bazowych, do których odwołuje się widok. Optymalizator zapytań wybiera alternatywę najniższego kosztu.
Używanie wskazówek z indeksowanymi widokami
Można zapobiec używaniu indeksów widoku dla zapytania przy użyciu EXPAND VIEWS wskazówki zapytania lub użyć NOEXPAND wskazówki tabeli, aby wymusić użycie indeksu dla indeksowanego widoku określonego w FROM klauzuli zapytania. Należy jednak umożliwić optymalizatorowi zapytań dynamiczne określenie najlepszych metod dostępu do użycia dla każdego zapytania. Ogranicz użycie elementów EXPAND i NOEXPAND do konkretnych przypadków, w których testowanie wykazało, że znacznie poprawi wydajność.
Opcja
EXPAND VIEWSokreśla, że Optymalizator zapytań nie używa żadnych indeksów widoku dla całego zapytania.Gdy
NOEXPANDjest określony dla widoku, optymalizator zapytań rozważa użycie wszystkich indeksów zdefiniowanych w widoku.NOEXPANDokreślony z klauzulą opcjonalnąINDEX()wymusza optymalizator zapytań do używania określonych indeksów.NOEXPANDmożna określić tylko dla widoku indeksowanego i nie można go określić dla widoku, który nie jest indeksowany. Automatyczne używanie widoku indeksowanego przez optymalizator zapytań jest obsługiwane tylko w określonych wersjach programu SQL Server. Usługi Azure SQL Database i Azure SQL Managed Instance obsługują również automatyczne korzystanie z indeksowanych widoków bez określania wskazówkiNOEXPAND.
Jeśli ani NOEXPAND ani EXPAND VIEWS nie zostanie określona w zapytaniu zawierającym widok, widok zostanie rozszerzony, aby uzyskać dostęp do bazowych tabel. Jeśli zapytanie tworzące widok zawiera jakiekolwiek wskazówki dotyczące tabeli, te wskazówki są propagowane do bazowych tabel. (Ten proces wyjaśniono bardziej szczegółowo w Rozdzielczość widoku). Jeśli zestaw wskazówek, które istnieją w podstawowych tabelach widoku, jest identyczny, zapytanie można dopasować do widoku indeksowanego. W większości przypadków te wskazówki pasują do siebie, ponieważ są dziedziczone bezpośrednio z widoku. Jeśli jednak zapytanie odwołuje się do tabel zamiast widoków, a wskazówki zastosowane bezpośrednio w tych tabelach nie są identyczne, takie zapytanie nie kwalifikuje się do dopasowania do widoku indeksowanego.
INDEXJeśli wskazówki , PAGLOCK, ROWLOCKTABLOCKXUPDLOCKlub XLOCK dotyczą tabel, do których odwołuje się zapytanie po rozszerzeniu widoku, zapytanie nie kwalifikuje się do dopasowania indeksowanego widoku.
Jeżeli wskazówka tabeli w postaci INDEX (index_val[ ,...n] ) odnosi się do widoku w zapytaniu i nie określisz również wskazówki NOEXPAND, to wskazówka indeksu jest ignorowana. Aby określić użycie określonego indeksu, użyj polecenia NOEXPAND.
Ogólnie rzecz biorąc, gdy optymalizator zapytań dopasowuje widok indeksowany do zapytania, dowolne podpowiedzi określone na tabelach lub widokach w zapytaniu są stosowane bezpośrednio do widoku indeksowanego. Jeśli optymalizator zapytań nie wybierze używania widoku indeksowanego, wszelkie wskazówki są propagowane bezpośrednio do tabel, do których odwołuje się widok. Aby uzyskać więcej informacji, zobacz Rozdzielczość ekranu. Ta propagacja nie ma zastosowania do wskazówek dotyczących łączeń. Są one stosowane tylko w ich pierwotnej pozycji w zapytaniu. Wskazówki dotyczące łączenia nie są brane pod uwagę przez optymalizator zapytań przy dopasowywaniu zapytań do widoków indeksowanych. Jeśli plan zapytania używa widoku indeksowanego, który odpowiada części zapytania zawierającej wskazówkę sprzężenia, to wskazówka sprzężenia nie jest używana w planie.
Wskazówki nie są dozwolone w definicjach indeksowanych widoków. W trybie zgodności 80 lub nowszym program SQL Server ignoruje wskazówki wewnątrz indeksowanych definicji widoku podczas ich obsługi lub podczas wykonywania zapytań korzystających z indeksowanych widoków. Chociaż używanie wskazówek w definicjach widoku indeksowanego nie spowoduje wystąpienia błędu składni w trybie zgodności 80, są one ignorowane.
Aby uzyskać więcej informacji, zobacz Wskazówki dotyczące tabel (Transact-SQL).
Rozwiązywanie problemów z rozproszonymi widokami podzielonymi na partycje
Procesor zapytań programu SQL Server optymalizuje wydajność rozproszonych widoków partycjonowanych. Najważniejszym aspektem wydajności widoku rozproszonego partycjonowanego jest zminimalizowanie ilości danych przesyłanych między serwerami członkowskimi.
Program SQL Server tworzy inteligentne, dynamiczne plany, które umożliwiają wydajne korzystanie z zapytań rozproszonych w celu uzyskiwania dostępu do danych z zdalnych tabel składowych:
- Procesor zapytań najpierw używa OLE DB do pobierania definicji ograniczeń sprawdzających z każdej tabeli składowej. Dzięki temu procesor zapytań może mapować rozkład wartości kluczy w tabelach składowych.
- Procesor zapytań porównuje zakresy kluczy określone w klauzuli instrukcji
WHERETransact-SQL z mapą, która pokazuje sposób dystrybucji wierszy w tabelach składowych. Następnie procesor zapytań tworzy plan wykonywania zapytań, który używa zapytań rozproszonych do pobierania tylko tych zdalnych wierszy, które są wymagane do ukończenia instrukcji Transact-SQL. Plan realizacji jest również skonstruowany w taki sposób, aby każdy dostęp do zdalnych tabel członków, zarówno dla danych, jak i metadanych, był opóźniany do momentu, aż informacje będą potrzebne.
Rozważmy na przykład system, w Customers którym tabela jest partycjonowana na serwerze Server1 (CustomerID od 1 do 3299999), Server2 (CustomerID od 3300000 do 6599999) i Server3 (CustomerID od 6600000 do 9999999).
Rozważ plan wykonania utworzony dla tego zapytania wykonanego na serwerze Server1:
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
Plan wykonywania dla tego zapytania wyodrębnia wiersze z wartościami CustomerID klucza z zakresu od 3200000 do 3299999 z lokalnej tabeli członkowskiej i wystawia zapytanie rozproszone w celu pobrania wierszy z wartościami kluczy z zakresu od 3300000 do 3400000 z Server2.
Procesor zapytań programu SQL Server może również tworzyć dynamiczną logikę w planach wykonywania zapytań dla instrukcji Transact-SQL, w których wartości kluczy nie są znane podczas tworzenia planu. Rozważmy na przykład tę procedurę przechowywaną:
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
Program SQL Server nie może przewidzieć, jaka wartość klucza będzie dostarczana przez @CustomerIDParameter parametr za każdym razem, gdy procedura zostanie wykonana. Ponieważ nie można przewidzieć wartości klucza, procesor zapytań również nie może przewidzieć, do której tabeli składowej będzie trzeba uzyskać dostęp. Aby obsłużyć ten przypadek, program SQL Server tworzy plan wykonywania, który ma logikę warunkową, nazywaną filtrami dynamicznymi, w celu kontrolowania, do której tabeli składowej uzyskuje się dostęp, na podstawie wartości parametru wejściowego. Przy założeniu, GetCustomer że procedura składowana została wykonana na serwerze Server1, logika planu wykonywania może być reprezentowana w następujący sposób:
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
Program SQL Server czasami tworzy te typy dynamicznych planów wykonywania nawet w przypadku zapytań, które nie są sparametryzowane. Optymalizator zapytań może sparametryzować zapytanie, aby można było ponownie użyć planu wykonywania. Jeśli optymalizator zapytań sparametryzuje zapytanie odwołujące się do widoku partycjonowanego, optymalizator zapytań nie może już zakładać, że wymagane wiersze pochodzą z określonej tabeli podstawowej. Następnie będzie musiał używać filtrów dynamicznych w planie wykonywania.
Procedura składowana i wykonywanie wyzwalacza
Program SQL Server przechowuje tylko źródło procedur składowanych i wyzwalaczy. Po pierwszym wykonaniu procedury składowanej lub wyzwalacza źródło jest kompilowane w planie wykonywania. Jeśli procedura składowana lub wyzwalacz zostanie ponownie wykonany, zanim plan wykonywania stanie się przestarzały w pamięci, aparat relacyjny wykryje istniejący plan i ponownie go użyje. Jeśli plan wypadnie z pamięci, zostanie opracowany nowy plan. Ten proces jest podobny do tego, którego używa SQL Server do obsługi wszystkich instrukcji Transact-SQL. Główną zaletą wydajności, jaką mają procedury składowane i wyzwalacze w programie SQL Server w porównaniu z partiami dynamicznych Transact-SQL jest to, że ich instrukcje Transact-SQL są zawsze takie same. Dlatego silnik relacyjny łatwo dopasowuje je do istniejących planów wykonywania. Procedury składowane i plany wyzwalaczy są łatwo ponownie wykorzystywane.
Plan wykonywania procedur składowanych i wyzwalaczy jest wykonywany oddzielnie od planu wykonywania dla partii wywołującej procedurę składowaną lub wyzwalacza. Umożliwia to większe ponowne użycie procedury składowanej i wyzwalanie planów wykonywania.
Buforowanie i ponowne używanie planu wykonywania
Program SQL Server ma pulę pamięci, która jest używana do przechowywania zarówno planów wykonywania, jak i danych. Procent puli przydzielony do planów wykonawczych lub buforów danych zmienia się dynamicznie, w zależności od stanu systemu. Część puli pamięci wykorzystywana do przechowywania planów wykonania nazywana jest pamięcią podręczną planów.
Pamięć podręczna dla planów ma dwa przechowalniki dla wszystkich skompilowanych planów.
- Magazyn pamięci podręcznej planów obiektów (OBJCP) jest używany do planowania związanego z obiektami trwałymi (procedury składowane, funkcje i wyzwalacze).
- Pamięć podręczna planów SQL (SQLCP) służy do planów związanych z zapytaniami autoparametryzowanymi, dynamicznymi lub przygotowanymi.
Poniższe zapytanie zawiera informacje o użyciu pamięci dla tych dwóch magazynów pamięci podręcznej:
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
Uwaga / Notatka
Pamięć podręczna dla planów ma dwa dodatkowe zasoby, które nie są używane do przechowywania planów.
- Magazyn pamięci podręcznej Bound Trees (PHDR) służy do przechowywania struktur danych używanych podczas kompilacji planu dla widoków, ograniczeń i wartości domyślnych. Te struktury są nazywane drzewami powiązanymi lub drzewami algebrizatora.
- Magazyn pamięci podręcznej rozszerzonych procedur składowanych (XPROC) używany jest do wcześniej zdefiniowanych procedur systemowych, takich jak lub
sp_executeSql, które są zdefiniowane z użyciem biblioteki DLL, a nie za pomocą instrukcji Transact-SQL. Buforowana struktura zawiera tylko nazwę funkcji i nazwę biblioteki DLL, w której zaimplementowano procedurę.
Plany wykonywania programu SQL Server mają następujące główne składniki:
Skompilowany plan (lub plan zapytania)
Plan zapytania utworzony przez proces kompilacji jest głównie reentrancyjną strukturą danych tylko do odczytu, używaną przez nieograniczoną liczbę użytkowników. Przechowuje informacje o:Operatory fizyczne implementujące operację opisaną przez operatory logiczne.
Kolejność tych operatorów, która określa kolejność uzyskiwania dostępu do danych, filtrowania i agregowania.
Liczba szacowanych wierszy przechodzących przez operatorów.
Uwaga / Notatka
W nowszych wersjach silnika bazy danych przechowywane są również informacje o obiektach statystyk wykorzystywanych do szacowania kardynalności.
Należy utworzyć obiekty obsługi, takie jak tabele robocze lub pliki robocze w
tempdb. W planie zapytania nie są przechowywane żadne informacje dotyczące kontekstu użytkownika ani środowiska uruchomieniowego. Nigdy nie ma więcej niż jednej lub dwóch kopii planu zapytania w pamięci: jedna kopia dla wszystkich wykonań szeregowych i druga dla wszystkich równoległych wykonań. Kopia równoległa obejmuje wszystkie równoległe wykonania, niezależnie od stopnia równoległości.
Kontekst wykonywania
Każdy użytkownik, który aktualnie wykonuje zapytanie, ma strukturę danych, która przechowuje dane specyficzne dla ich wykonywania, takie jak wartości parametrów. Ta struktura danych jest określana jako kontekst wykonywania. Struktury danych kontekstu wykonywania są ponownie używane, ale ich zawartość nie jest. Jeśli inny użytkownik wykonuje to samo zapytanie, struktury danych są ponownie inicjowane z kontekstem dla nowego użytkownika.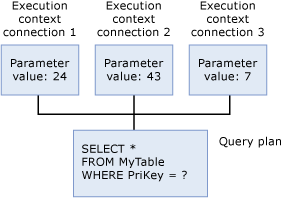
Po wykonaniu dowolnej instrukcji Transact-SQL w programie SQL Server aparat bazy danych najpierw przegląda pamięć podręczną planu, aby sprawdzić, czy istnieje istniejący plan wykonania dla tej samej instrukcji Transact-SQL. Instrukcja Transact-SQL kwalifikuje się jako istniejąca, jeśli dosłownie pasuje, znak po znaku, do wcześniej wykonanej instrukcji Transact-SQL z planem zapisanym w pamięci podręcznej. Program SQL Server ponownie używa istniejącego znalezionego planu, co pozwala zaoszczędzić koszty ponownego komkompilowania instrukcji Transact-SQL. Jeśli plan wykonania nie istnieje, program SQL Server generuje nowy plan wykonania zapytania.
Uwaga / Notatka
Plany wykonywania niektórych instrukcji Transact-SQL nie są utrwalane w pamięci podręcznej planu, takie jak instrukcje operacji zbiorczej uruchomione w magazynie wierszy lub instrukcje zawierające literały ciągu większe niż 8 KB rozmiaru. Te plany istnieją tylko podczas wykonywania zapytania.
Program SQL Server ma wydajny algorytm do znajdowania wszelkich istniejących planów wykonywania dla dowolnej konkretnej instrukcji Transact-SQL. W większości systemów minimalne zasoby używane przez to skanowanie są mniejsze niż zasoby oszczędzane dzięki możliwości ponownego wykorzystania istniejących planów zamiast kompilowania każdej instrukcji Transact-SQL.
Algorytmy do dopasowania nowych instrukcji Transact-SQL do istniejących, nieużywanych planów wykonywania w pamięci podręcznej planu wymagają, aby wszystkie odwołania do obiektów były w pełni kwalifikowane. Załóżmy na przykład, że Person jest to domyślny schemat dla użytkownika wykonującego poniższe SELECT instrukcje. Chociaż w tym przykładzie nie jest wymagane, aby Person tabela była w pełni kwalifikowana do wykonania, oznacza to, że druga instrukcja nie jest zgodna z istniejącym planem, ale trzecia jest zgodna:
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
Zmiana dowolnej z następujących opcji SET dla danego wykonania będzie mieć wpływ na możliwość wielokrotnego użycia planów, ponieważ aparat bazy danych wykonuje stałe składanie i te opcje wpływają na wyniki takich wyrażeń.
ANSI_NULL_DFLT_OFF
FORCEPLAN
ARITHABORT
DATEFIRST
ANSI_PADDING
ZAOKRĄGLENIE_NUMERYCZNE_ANULOWANE
ANSI_NULL_DFLT_ON
JĘZYK
CONCAT_NULL_YIELDS_NULL (łączenie z wartością NULL daje NULL)
Format daty
ANSI_WARNINGS (ostrzeżenia ANSI)
IDENTYFIKATOR W CUDZYSŁOWIE
ANSI_NULLS (ustawienie w SQL Server dotyczące obsługi wartości NULL)
NO_BROWSETABLE
ANSI_USTAWIENIA_DOMYŚLNE
Buforowanie wielu planów dla tego samego zapytania
Zapytania i plany wykonania mogą być jednoznacznie zidentyfikowane w aparacie bazy danych, podobnie jak odcisk palca.
- Skrót planu zapytania to binarna wartość skrótu obliczana dla planu wykonywania dla danego zapytania i używana do unikatowego identyfikowania podobnych planów wykonywania.
- Skrót zapytania jest wartością skrótu binarnego obliczaną na Transact-SQL tekście zapytania i służy do unikatowego identyfikowania zapytań.
Skompilowany plan można pobrać z pamięci podręcznej planu przy użyciu uchwytu planu, który jest identyfikatorem przejściowym, który pozostaje stały tylko wtedy, gdy plan pozostaje w pamięci podręcznej. Uchwyt planu jest wartością skrótu pochodzącą z skompilowanego planu całej partii. Uchwyt planu dla skompilowanego planu pozostaje niezmieniony, nawet jeśli jedna lub więcej instrukcji w zbiorze zostanie ponownie skompilowanych.
Uwaga / Notatka
Jeśli plan został skompilowany dla zestawu zamiast pojedynczej instrukcji, plan dla poszczególnych instrukcji w zestawie można pobrać przy użyciu uchwytu planu i przesunięć instrukcji.
Widok sys.dm_exec_requests DMV zawiera kolumny statement_start_offset i statement_end_offset dla każdego rekordu, które odwołują się do aktualnie wykonywanej instrukcji wsadowej lub utrwalonego obiektu. Aby uzyskać więcej informacji, zobacz sys.dm_exec_requests (Transact-SQL).
Widok sys.dm_exec_query_stats DMV zawiera również te kolumny dla każdego rekordu, które odwołują się do położenia instrukcji w partii lub utrwalonego obiektu. Aby uzyskać więcej informacji, zobacz sys.dm_exec_query_stats (Transact-SQL).
Rzeczywisty tekst partii Transact-SQL jest przechowywany w oddzielnej przestrzeni pamięci w stosunku do pamięci podręcznej planu, nazywanej pamięcią podręczną SQL Manager (SQLMGR). Tekst Transact-SQL dla skompilowanego planu można pobrać z pamięci podręcznej programu SQL Manager przy użyciu dojścia SQL, który jest identyfikatorem przejściowym, który pozostaje stały tylko wtedy, gdy co najmniej jeden plan, który odwołuje się do niego, pozostaje w pamięci podręcznej planu. Uchwyt SQL jest wartością skrótu pochodzącą z całego tekstu wsadowego, co gwarantuje unikalność dla każdej partii.
Uwaga / Notatka
Podobnie jak w przypadku skompilowanego planu, tekst Transact-SQL jest przechowywany dla każdej partii, wraz z komentarzami. Uchwyt SQL zawiera skrót MD5 całego tekstu wsadowego i jest unikalny dla każdej partii.
Poniższe zapytanie zawiera informacje o użyciu pamięci dla pamięci podręcznej programu SQL Manager:
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
Istnieje relacja 1:N między uchwytem SQL a uchwytami planu. Taki warunek występuje, gdy klucz pamięci podręcznej dla skompilowanych planów jest inny. Może się to zdarzyć z powodu zmiany opcji ZESTAWU między dwoma wykonaniami tej samej partii.
Rozważ następującą procedurę przechowywaną:
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
Sprawdź, co można znaleźć w pamięci podręcznej planu, korzystając z poniższego zapytania:
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
Oto zestaw wyników.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Teraz wykonaj procedurę składowaną z innym parametrem, bez innych zmian w kontekście wykonania.
EXEC usp_SalesByCustomer 8
GO
Sprawdź ponownie, co można znaleźć w pamięci podręcznej planu. Oto zestaw wyników.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Zwróć uwagę, że wartość parametru usecounts wzrosła do 2, co oznacza, że ten sam plan buforowany został ponownie użyty as-is, ponieważ struktury danych kontekstu wykonywania zostały ponownie użyte. Teraz zmień SET ANSI_DEFAULTS opcję i wykonaj procedurę składowaną przy użyciu tego samego parametru.
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
Sprawdź ponownie, co można znaleźć w pamięci podręcznej planu. Oto zestaw wyników.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Zwróć uwagę, że w danych wyjściowych sys.dm_exec_cached_plans dmv są teraz dwa wpisy:
- Kolumna
usecountspokazuje wartość1w pierwszym rekordzie, który jest planem wykonanym raz za pomocąSET ANSI_DEFAULTS OFF. - Kolumna
usecountspokazuje wartość2w drugim rekordzie, który jest planem wykonanym zSET ANSI_DEFAULTS ON, ponieważ został uruchomiony dwukrotnie. - Odmienne
memory_object_addressodnoszą się na inny wpis planu wykonania w pamięci podręcznej planu. Jednak wartośćsql_handlejest taka sama dla obu wpisów, ponieważ odwołują się one do tej samej partii.- Wykonanie z ustawioną wartością
ANSI_DEFAULTSna OFF ma nowyplan_handle, który jest dostępny do ponownego użycia dla wywołań z tym samym zestawem opcji SET. Nowa obsługa planu jest niezbędna, ponieważ kontekst wykonywania został ponownie zainicjowany, z powodu zmienionych opcji SET. Nie powoduje to jednak ponownego kompilowania: oba wpisy odnoszą się do tego samego planu i zapytania, co jest dowodem na te samequery_plan_hashwartości iquery_hash.
- Wykonanie z ustawioną wartością
Oznacza to, że mamy dwa wpisy planu w pamięci podręcznej odpowiadające temu samemu wsadowi, co podkreśla znaczenie upewnienia się, że opcje SET wpływające na pamięć podręczną planu są takie same, gdy te same zapytania są wykonywane wielokrotnie, aby zoptymalizować ponowne użycie planu i utrzymać rozmiar pamięci podręcznej na wymaganym poziomie minimalnym.
Wskazówka
Typowe pułapki polegają na tym, że różni klienci mogą mieć różne wartości domyślne dla opcji SET. Na przykład połączenie nawiązane za pośrednictwem narzędzia SQL Server Management Studio automatycznie ustawia QUOTED_IDENTIFIER na WŁ., a SQLCMD ustawia QUOTED_IDENTIFIER na WYŁ. Wykonanie tych samych zapytań z tych dwóch klientów spowoduje powstanie wielu planów, jak opisano w powyższym przykładzie.
Usuń plany wykonania z pamięci podręcznej planu
Plany wykonywania pozostają w pamięci podręcznej planu tak długo, jak jest wystarczająca ilość pamięci do ich przechowywania. Gdy występuje presja pamięciowa, aparat bazy danych programu SQL Server używa podejścia opartego na kosztach, aby określić, które plany wykonania usunąć z pamięci podręcznej planu. Aby podjąć decyzję opartą na kosztach, aparat bazy danych programu SQL Server zwiększa i zmniejsza bieżącą zmienną kosztową dla każdego planu wykonania zgodnie z następującymi czynnikami.
Gdy proces użytkownika wstawia plan wykonania do pamięci podręcznej, proces użytkownika ustawia bieżący koszt równy pierwotnemu kosztowi kompilacji zapytania; w przypadku planów wykonywania ad hoc proces użytkownika ustawia bieżący koszt na zero. Następnie za każdym razem, gdy proces użytkownika odwołuje się do planu wykonania, resetuje bieżący koszt do pierwotnego kosztu kompilacji; w przypadku planów wykonywania ad hoc proces użytkownika zwiększa bieżący koszt. Dla wszystkich planów maksymalna wartość bieżącego kosztu to oryginalny koszt kompilacji.
Kiedy występuje nacisk na pamięć, aparat bazy danych SQL Server reaguje poprzez usuwanie planów wykonania z pamięci podręcznej planu. Aby określić, które plany mają być usunięte, aparat bazy danych programu SQL Server wielokrotnie sprawdza stan każdego planu wykonania i usuwa plany, gdy ich bieżący koszt wynosi zero. Plan wykonywania z zerowym bieżącym kosztem nie jest usuwany automatycznie, gdy istnieje wykorzystanie pamięci; Jest on usuwany tylko wtedy, gdy aparat bazy danych programu SQL Server sprawdza plan, a bieżący koszt wynosi zero. Podczas badania planu wykonania silnik bazy danych SQL Server zmniejsza bieżący koszt do zera, jeżeli zapytanie nie korzysta obecnie z tego planu.
Aparat bazy danych programu SQL Server wielokrotnie sprawdza plany wykonywania, dopóki nie zostanie usunięta wystarczająca ilość, aby spełnić wymagania dotyczące pamięci. Istniejący nacisk na pamięć może spowodować, że plan wykonania będzie miał wielokrotnie zwiększony i zmniejszony koszt. Gdy nacisk na pamięć już nie istnieje, silnik bazy danych SQL Server przestaje zmniejszać bieżący koszt nieużywanych planów wykonania, a wszystkie plany wykonania pozostają w pamięci podręcznej planów, nawet jeśli ich koszt wynosi zero.
Silnik bazy danych SQL Server używa wątków monitora zasobów i wątków roboczych użytkownika do zwalniania pamięci z pamięci podręcznej planów w odpowiedzi na presję pamięci. Wątki monitora zasobów i pracownika użytkownika mogą badać plany uruchamiane współbieżnie, aby obniżyć obecne koszty każdego niewykorzystanego planu wykonania. Monitor zasobów usuwa plany wykonywania z pamięci podręcznej planu w sytuacji globalnego obciążenia pamięci. Zwalnia pamięć, aby wymusić zasady dotyczące pamięci systemowej, pamięci procesów, pamięci puli zasobów oraz maksymalnego rozmiaru wszystkich pamięci podręcznych.
Maksymalny rozmiar wszystkich pamięci podręcznych jest funkcją rozmiaru puli i nie może przekroczyć maksymalnej pamięci serwera. Aby uzyskać więcej informacji na temat konfigurowania maksymalnej pamięci serwera, zobacz ustawienie max server memory w sp_configure.
Gdy występuje nacisk na pamięć podręczną, wątki robocze użytkownika usuwają plany wykonawcze z pamięci podręcznej planu. Wymuszają one zasady maksymalnego rozmiaru pojedynczej pamięci podręcznej i maksymalnej liczby wpisów pojedynczej pamięci podręcznej.
Poniższe przykłady ilustrują, które plany realizacji zostaną usunięte z pamięci podręcznej planu.
- Plan wykonania jest często odwoływany, aby jego koszt nigdy nie osiągał zera. Plan pozostaje w pamięci podręcznej i nie jest usuwany, chyba że istnieje zapotrzebowanie na pamięć i bieżący koszt wynosi zero.
- Plan wykonywania ad hoc jest wstawiany i nie jest odwoływany ponownie, dopóki nie pojawi się problem z brakiem pamięci. Ponieważ plany ad hoc są inicjowane z bieżącym kosztem zerowym, gdy aparat bazy danych programu SQL Server sprawdza plan wykonania, zobaczy zerowy bieżący koszt i usunie plan z pamięci podręcznej planu. Plan wykonywania ad hoc pozostaje w pamięci podręcznej planu z zerowym bieżącym kosztem, gdy wykorzystanie pamięci nie istnieje.
Aby ręcznie usunąć pojedynczy plan lub wszystkie plany z pamięci podręcznej, użyj DBCC FREEPROCCACHE.
DbCC FREESYSTEMCACHE może również służyć do czyszczenia dowolnej pamięci podręcznej, w tym pamięci podręcznej planu. Począwszy od programu SQL Server 2016 (13.x), ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE można użyć do wyczyszczenia pamięci podręcznej procedury (planu) w kontekście danej bazie danych.
Zmiana niektórych ustawień konfiguracji za pośrednictwem sp_configure i ponownej konfiguracji spowoduje również usunięcie planów z pamięci podręcznej planu. Listę tych ustawień konfiguracji można znaleźć w sekcji Uwagi artykułu DBCC FREEPROCCACHE . Taka zmiana konfiguracji spowoduje zarejestrowanie następującego komunikatu informacyjnego w dzienniku błędów:
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
Ponowne kompiluj plany wykonywania
Niektóre zmiany w bazie danych mogą spowodować, że plan wykonywania będzie nieefektywny lub nieprawidłowy na podstawie nowego stanu bazy danych. Program SQL Server wykrywa zmiany, które unieważniają plan wykonywania i oznaczają plan jako nieprawidłowy. Następnie należy ponownie skompilować nowy plan dla następnego połączenia, które wykonuje zapytanie. Warunki, które unieważniają plan, obejmują następujące elementy:
- Zmiany wprowadzone w tabeli lub widoku, do których odwołuje się zapytanie (
ALTER TABLEiALTER VIEW). - Zmiany wprowadzone w jednej procedurze sprawią, że wszystkie plany tej procedury zostaną usunięte z pamięci podręcznej (
ALTER PROCEDURE). - Zmiany w indeksach używanych w ramach planu wykonywania.
- Aktualizacje statystyk używanych przez plan wykonywania, generowane bezpośrednio z instrukcji, takiej jak
UPDATE STATISTICS, lub generowane automatycznie. - Usunięcie indeksu używanego przez plan wykonawczy.
- Jawne wywołanie do
sp_recompile. - Duża liczba zmian kluczy (generowanych przez instrukcje
INSERTlubDELETEod innych użytkowników, którzy modyfikują tabelę przywoływaną przez zapytanie). - W przypadku tabel z wyzwalaczami, jeśli liczba wierszy w wstawionych lub usuniętych tabelach znacznie się zwiększa.
- Wykonywanie procedury składowanej przy użyciu opcji
WITH RECOMPILE.
Większość ponownych kompilacji jest wymagana w przypadku poprawności instrukcji lub uzyskania potencjalnie szybszych planów wykonywania zapytań.
W wersjach programu SQL Server wcześniejszych niż 2005, za każdym razem, gdy instrukcja w pakiecie powoduje ponowne skompilowanie, cały pakiet, niezależnie od tego, czy został przesłany za pomocą procedury składowanej, wyzwalacza, wsadu ad hoc lub przygotowanej instrukcji, został ponownie skompilowany. Począwszy od programu SQL Server 2005 (9.x), tylko instrukcja wewnątrz partii, która wyzwala ponowną kompilację, jest ponownie skompilowana. Ponadto istnieją dodatkowe typy ponownych kompilacji w programie SQL Server 2005 (9.x) i nowszym ze względu na rozszerzony zestaw funkcji.
Rekompilacja zapytań na poziomie instrukcji przynosi korzyści dla wydajności, ponieważ w większości przypadków niewielka liczba instrukcji powoduje ponowne skompilowanie i związane z nimi koszty pod względem zużycia czasu CPU i występowania blokad. Te kary są zatem unikane dla innych instrukcji w zestawie, które nie muszą być ponownie skompilowane.
Zdarzenie sql_statement_recompile rozszerzone (XEvent) zgłasza ponowne kompilacje na poziomie instrukcji. Ten XEvent występuje, gdy ponowna kompilacja na poziomie instrukcji jest wymagana przez dowolny rodzaj serii. Obejmuje to procedury przechowywane, wyzwalacze, partie ad hoc i zapytania. Partie można przesyłać za pośrednictwem kilku interfejsów, w tym sp_executesql, dynamicznych metod SQL, Prepare lub Execute.
Kolumna recompile_causesql_statement_recompile XEvent zawiera kod całkowity, który wskazuje przyczynę ponownej kompilacji. Poniższa tabela zawiera możliwe przyczyny:
Zmieniono schemat
Zmieniono statystyki
Odroczona kompilacja
Opcja SET została zmieniona
Zmieniono tabelę tymczasową
Zmieniono zdalny zestaw rekordów
FOR BROWSE zmieniono uprawnienia
Zmieniono środowisko powiadomień o zapytaniach
Zmieniony widok partycjonowany
Zmieniono opcje kursora
OPTION (RECOMPILE) Poproszono
Wyczyszczono sparametryzowany plan.
Zmiana wersji bazy danych wpłynęła na plan
Plan magazynu zapytań wymusza zmianę zasad
Wymuszenie planu sklepu zapytań nie powiodło się
Brakuje planu w Query Store
Uwaga / Notatka
W wersjach programu SQL Server, w których zdarzenia XEvents nie są dostępne, można użyć zdarzenia śledzenia SP:Recompile programu SQL Server Profiler do raportowania ponownych kompilacji na poziomie instrukcji.
Zdarzenie śledzenia SQL:StmtRecompile zgłasza również rekompilacje na poziomie instrukcji, a ponadto może być używane do śledzenia i debugowania tych rekompilacji.
Podczas gdy SP:Recompile generuje tylko dla procedur składowanych i wyzwalaczy, SQL:StmtRecompile generuje dla procedur składowanych, wyzwalaczy, partii wykonywanych jednorazowo, partii wykonywanych przy użyciu sp_executesql, przygotowanych zapytań i dynamicznego SQL.
Kolumna EventSubClass elementu SP:Recompile i SQL:StmtRecompile zawiera kod całkowity wskazujący przyczynę ponownej kompilacji. Kody są opisane w klasie zdarzeń SQL:StmtRecompile.
Uwaga / Notatka
AUTO_UPDATE_STATISTICS Gdy opcja bazy danych jest ustawiona na ON, zapytania są ponownie kompilowane, gdy są przeznaczone dla tabel lub indeksowanych widoków, których statystyki zostały zaktualizowane lub których kardynalność znacząco się zmieniła od ostatniego wykonania.
To zachowanie dotyczy standardowych tabel zdefiniowanych przez użytkownika, tabel tymczasowych oraz wstawionych i usuniętych tabel utworzonych przez wyzwalacze DML. Jeśli wydajność zapytań jest zakłócona przez nadmierne ponowne kompilacje, rozważ zmianę tego ustawienia na OFF. Gdy opcja bazy danych AUTO_UPDATE_STATISTICS jest ustawiona na wartość OFF, nie są wykonywane ponowne kompilacje na podstawie zmian w statystykach lub kardynalności, z wyjątkiem wstawionych i usuniętych tabel, które są tworzone przez wyzwalacze DML INSTEAD OF. Ponieważ te tabele są tworzone w tempdb, ponowna kompilacja zapytań, które uzyskują do nich dostęp, zależy od ustawienia AUTO_UPDATE_STATISTICS w tempdb.
W programie SQL Server przed 2005 r. zapytania nadal są ponownie kompilowane na podstawie zmian kardynalności tabel wstawionych i usuniętych przez wyzwalacz DML, nawet jeśli to ustawienie ma wartość OFF.
Ponowne użycie parametrów i planu realizacji
Użycie parametrów, w tym znaczników parametrów w aplikacjach ADO, OLE DB i ODBC, może zwiększyć ponowne użycie planów wykonywania.
Ostrzeżenie
Używanie parametrów lub znaczników parametrów do przechowywania wartości wprowadzanych przez użytkowników końcowych jest bezpieczniejsze niż łączenie tych wartości w ciąg, który jest następnie wykonywany przy użyciu metody API dostępu do danych, instrukcji EXECUTE lub procedury składowanej sp_executesql.
Jedyną różnicą między następującymi dwoma SELECT wyrażeniami są wartości, które są porównywane w klauzuli WHERE :
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Jedyną różnicą między planami wykonywania dla tych zapytań jest wartość przechowywana dla porównania z kolumną ProductSubcategoryID . Chociaż celem jest, aby SQL Server zawsze rozpoznawał, że instrukcje generują zasadniczo te same plany i ponownie je używał, SQL Server czasami nie rozpoznaje tego w złożonych instrukcjach Transact-SQL.
Oddzielenie stałych od instrukcji Transact-SQL przy użyciu parametrów ułatwia silnikowi relacyjnemu rozpoznawanie zduplikowanych planów. Parametry można używać na następujące sposoby:
W Transact-SQL użyj
sp_executesql:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParmTa metoda jest zalecana w przypadku skryptów Transact-SQL, procedur składowanych lub wyzwalaczy, które dynamicznie generują instrukcje SQL.
ADO, OLE DB i ODBC używają znaczników parametrów. Znaczniki parametrów to znaki zapytania (?), które zastępują stałą w instrukcji SQL i są powiązane ze zmienną programową. Na przykład w aplikacji ODBC należy wykonać następujące czynności:
Użyj
SQLBindParameteraby związać zmienną całkowitą z pierwszym znacznikiem parametru w instrukcji SQL.Umieść wartość całkowitą w zmiennej.
Wykonaj instrukcję, określając znacznik parametru (?):
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
Dostawca OLE DB natywnego klienta programu SQL Server i sterownik ODBC klienta natywnego programu SQL Server dołączony do programu SQL Server służy
sp_executesqldo wysyłania instrukcji do programu SQL Server, gdy znaczniki parametrów są używane w aplikacjach.Aby zaprojektować procedury składowane, które z założenia używają parametrów.
Jeśli nie kompilujesz jawnie parametrów w projekcie aplikacji, możesz również polegać na optymalizatorze zapytań programu SQL Server w celu automatycznego sparametryzowania niektórych zapytań przy użyciu domyślnego zachowania prostego parametryzacji. Alternatywnie możesz wymusić, aby optymalizator zapytań rozważył sparametryzowanie wszystkich zapytań w bazie danych, ustawiając PARAMETERIZATION opcję ALTER DATABASE instrukcji na FORCED.
Po włączeniu wymuszonej parametryzacji nadal można wykonywać proste parametryzacje. Na przykład następujące zapytanie nie może być sparametryzowane zgodnie z regułami wymuszonej parametryzacji:
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
Można go jednak sparametryzować zgodnie z prostymi regułami parametryzacji. Gdy wymuszona parametryzacja jest podejmowana, ale kończy się niepowodzeniem, prosta parametryzacja jest nadal podejmowana.
Prosta parametryzacja
W programie SQL Server użycie parametrów lub znaczników parametrów w instrukcjach Transact-SQL zwiększa zdolność silnika relacyjnego do dopasowania nowych instrukcji Transact-SQL z istniejącymi, wcześniej skompilowanymi planami wykonywania.
Ostrzeżenie
Używanie parametrów lub znaczników parametrów do przechowywania wartości wpisywanych przez użytkowników końcowych jest bezpieczniejsze niż umieszczanie tych wartości w ciągu tekstowym i wykonywanie go za pomocą metody API dostępu do danych, instrukcji EXECUTE lub procedury składowanej sp_executesql.
Jeśli instrukcja Transact-SQL jest wykonywana bez parametrów, program SQL Server sparametryzuje instrukcję wewnętrznie, aby zwiększyć możliwość dopasowania jej do istniejącego planu wykonania. Ten proces jest nazywany prostą parametryzacją. W wersjach programu SQL Server wcześniejszych niż 2005 proces był określany jako autoparametryzację.
Rozważ to stwierdzenie:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
Wartość 1 na końcu instrukcji można określić jako parametr. Aparat relacyjny kompiluje plan wykonywania dla tej partii tak, jakby parametr został określony zamiast wartości 1. Z powodu tej prostej parametryzacji program SQL Server rozpoznaje, że następujące dwie instrukcje generują zasadniczo ten sam plan wykonania i ponownie używają pierwszego planu dla drugiej instrukcji:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Podczas przetwarzania złożonych instrukcji Transact-SQL aparat relacyjny może mieć trudności z ustaleniem, które wyrażenia mogą być sparametryzowane. Aby zwiększyć zdolność silnika relacyjnego do dopasowania złożonych instrukcji Transact-SQL do istniejących, nieużywanych planów wykonania, jawnie określ parametry, używając znaczników sp_executesql lub markerów parametrów.
Uwaga / Notatka
Gdy operatory arytmetyczne +, -, *, / lub % są używane do wykonywania niejawnej lub jawnej konwersji stałej wartości int, smallint, tinyint lub bigint na typy danych float, real, decimal lub numeric, program SQL Server stosuje określone reguły do obliczania typu i dokładności wyników wyrażenia. Jednak te reguły różnią się w zależności od tego, czy zapytanie jest sparametryzowane, czy nie. W związku z tym podobne wyrażenia w zapytaniach mogą w niektórych przypadkach generować różne wyniki.
W ramach domyślnego zachowania prostego parametryzacji program SQL Server sparametryzuje stosunkowo małą klasę zapytań. Można jednak określić, że wszystkie zapytania w bazie danych mają być sparametryzowane, z zastrzeżeniem pewnych ograniczeń, ustawiając PARAMETERIZATION opcję ALTER DATABASE polecenia na FORCED. Dzięki temu można zwiększyć wydajność baz danych, które mają duże ilości współbieżnych zapytań, zmniejszając częstotliwość kompilacji zapytań.
Alternatywnie można określić, że pojedyncze zapytanie i inne, które są składniowo równoważne, ale różnią się tylko w ich wartości parametrów, mają być sparametryzowane.
Wskazówka
W przypadku korzystania z rozwiązania Object-Relational Mapping (ORM), takiego jak Entity Framework (EF), zapytania aplikacji, takie jak ręczne drzewa zapytań LINQ lub niektóre nieprzetworzone zapytania SQL, mogą nie być sparametryzowane, co ma wpływ na ponowne użycie planu i możliwość śledzenia zapytań w magazynie zapytań. Aby uzyskać więcej informacji, zobacz buforowanie i parametryzację zapytań w EF oraz zapytania Raw SQL.
Wymuszona parametryzacja
Można zastąpić domyślne proste zachowanie parametryzacji programu SQL Server, określając, że wszystkie instrukcje zawierające SELECT, INSERT, UPDATE i DELETE w bazie danych mają być sparametryzowane, przy pewnych ograniczeniach. Parametryzacja wymuszona jest włączana poprzez ustawienie opcji PARAMETERIZATION na FORCED w instrukcji ALTER DATABASE. Wymuszona parametryzacja może zwiększyć wydajność niektórych baz danych, zmniejszając częstotliwość kompilacji zapytań i ponowne kompilowania. Bazy danych, które mogą korzystać z wymuszonej parametryzacji, to zazwyczaj te, które korzystają z dużych ilości współbieżnych zapytań ze źródeł, takich jak aplikacje do obsługi punktów sprzedaży.
PARAMETERIZATION Gdy opcja jest ustawiona na FORCED, każda wartość literału pojawiająca się w instrukcji SELECT, INSERT, UPDATE lub DELETE, przesłana w dowolnym formularzu, jest konwertowana na parametr podczas kompilacji zapytania. Wyjątki są literałami, które są wyświetlane w następujących konstrukcjach zapytania:
-
INSERT...EXECUTEOświadczenia. - Instrukcje wewnątrz treści procedur składowanych, wyzwalaczy lub funkcji zdefiniowanych przez użytkownika. Program SQL Server już ponownie używa planów zapytań dla tych procedur.
- Przygotowane instrukcje, które zostały już sparametryzowane w aplikacji po stronie klienta.
- Instrukcje, które zawierają wywołania metody XQuery, gdzie metoda pojawia się w kontekście, w którym argumenty zwykle będą sparametryzowane, takie jak klauzula
WHERE. Jeśli metoda pojawi się w kontekście, w którym jej argumenty nie będą sparametryzowane, pozostała część instrukcji zostanie sparametryzowana. - Instrukcje wewnątrz kursora Transact-SQL. (
SELECTinstrukcje wewnątrz kursorów interfejsu API są sparametryzowane). - Przestarzałe konstrukcje zapytań.
- Każda instrukcja, uruchamiana w kontekście
ANSI_PADDINGlubANSI_NULLS, jest ustawiona jakoOFF. - Instrukcje zawierające więcej niż 2097 dosłownych wartości, które kwalifikują się do parametryzacji.
- Wyrażenia odwołujące się do zmiennych, na przykład
WHERE T.col2 >= @bb. - Instrukcje zawierające
RECOMPILEwskazówkę zapytania. - Zdania zawierające klauzulę
COMPUTE. - Zdania zawierające klauzulę
WHERE CURRENT OF.
Ponadto następujące klauzule zapytania nie są sparametryzowane. W takich przypadkach tylko klauzule nie są sparametryzowane. Inne klauzule w ramach tego samego zapytania mogą kwalifikować się do wymuszonej parametryzacji.
- select_list <> dowolnego wyrażenia
SELECT. To obejmuje listy podzapytaniaSELECTi listySELECTwewnątrz wyrażeńINSERT. - Instrukcje podzapytania
SELECT, które pojawiają się wewnątrz instrukcjiIF. - Klauzule
TOP,TABLESAMPLE,HAVING,GROUP BY,ORDER BY,OUTPUT...INTOlubFOR XMLzapytania. - Argumenty, bezpośrednie lub jako podwyrażenia, do
OPENROWSET,OPENQUERY,OPENDATASOURCE,OPENXML, lub dowolnegoFULLTEXToperatora. - Wzorzec i parametry escape_character klauzuli
LIKE. - Styl argumentu klauzuli
CONVERT. - Stałe całkowite wewnątrz klauzuli
IDENTITY. - Stałe określone przy użyciu składni rozszerzenia ODBC.
- Wyrażenia składane na stałe, które są argumentami operatorów
+,-,*,/i%. Podczas rozważania uprawnień do wymuszonej parametryzacji program SQL Server uznaje wyrażenie za stałe składane, gdy spełniony jest jeden z następujących warunków:- W wyrażeniu nie są wyświetlane żadne kolumny, zmienne ani podzapytania.
- Wyrażenie zawiera klauzulę
CASE.
- Argumenty dotyczące klauzul wskazówek zapytania. Obejmują one argument number_of_rows wskazówki zapytania, argument
FASTwskazówki zapytania oraz argument number wskazówki zapytania.
Parametryzacja występuje na poziomie poszczególnych instrukcji Transact-SQL. Innymi słowy, poszczególne zapytania w zbiorze są sparametryzowane. Po skompilowaniu zapytanie sparametryzowane jest wykonywane w kontekście partii, w której została pierwotnie przesłana. Jeśli plan wykonywania zapytania jest buforowany, możesz określić, czy zapytanie zostało sparametryzowane, odwołując się do kolumny SQL widoku dynamicznego sys.syscacheobjects zarządzania. Jeśli zapytanie jest sparametryzowane, nazwy i typy danych parametrów pochodzą przed tekstem przesłanej partii w tej kolumnie, na przykład (@1 tinyint).
Uwaga / Notatka
Nazwy parametrów są dowolne. Użytkownicy lub aplikacje nie powinni polegać na określonej kolejności nazewnictwa. Ponadto następujące elementy mogą zmieniać się między wersjami SQL Server i aktualizacjami zbiorczymi (CU): Nazwy parametrów, wybór literałów, które są sparametryzowane, oraz odstępy w sparametryzowanym tekście.
Typy danych parametrów
Gdy program SQL Server sparametryzuje literały, parametry są konwertowane na następujące typy danych:
- Literały liczb całkowitych, których rozmiar mieściłby się w typie danych int, są parametryzowane jako int. Literały liczb całkowitych większe, które są częścią predykatu obejmującego dowolny operator porównania (w tym
<,<=,=,!=,>,>=,!<,!>,<>,ALL,ANY,SOME,BETWEEN, iIN) są parametryzowane jako numeric(38,0). Większe literały, które nie są częścią predykatów z operatorami porównania, są parametryzowane do typu numerycznego, którego precyzja jest wystarczająco duża, aby obsłużyć ich rozmiar, a skala wynosi 0. - Literały numeryczne o stałym punkcie, które są częścią predykatów z operatorami porównania, parametryzują do liczb o precyzji 38 i skali wystarczająco dużej, aby obsługiwać ich rozmiar. Literały numeryczne o stałym punkcie, które nie należą do predykatów zawierających operatory porównania, są parametryzowane do liczb o precyzji i skali wystarczająco dużej, aby obsługiwać ich rozmiar.
- Literały liczbowe zmiennoprzecinkowe są konfigurowane do typu zmiennoprzecinkowego o precyzji 53 bitów.
- Literały ciągów innych niż Unicode są przekształcane na varchar(8000), jeśli literał mieści się w granicach 8000 znaków, oraz na varchar(max), jeśli przekracza 8000 znaków.
- Literały w ciągu Unicode są parametryzowane jako nvarchar(4000), jeśli literał zawiera się w 4,000 znakach Unicode, oraz jako nvarchar(max), jeśli literał jest większy niż 4,000 znaków.
- Literały binarne przyjmują typ varbinary(8000), jeśli mieszczą się w 8000 bajtach. Jeśli jest on większy niż 8000 bajtów, jest konwertowany na wartość varbinary(max).
- Literały typu monetarnego przekształcają na wartość monetarną.
Wskazówki dotyczące używania wymuszonej parametryzacji
Przy ustawianiu PARAMETERIZATION opcji WYMUSZONE należy wziąć pod uwagę następujące kwestie:
- Wymuszona parametryzacja zmienia stałe dosłowne w zapytaniu na parametry podczas kompilacji zapytania. W związku z tym optymalizator zapytań może wybrać nieoptymalne plany zapytań. W szczególności optymalizator zapytań jest mniej prawdopodobny na dopasowanie zapytania do widoku z indeksem lub indeksu na kolumnie obliczonej. Można również wybrać nieoptymalne plany zapytań dotyczących tabel partycjonowanych i rozproszonych widoków partycjonowanych. Wymuszona parametryzacja nie powinna być używana w środowiskach, które w dużym stopniu korzystają z indeksowanych widoków i indeksów w kolumnach obliczeniowych. Ogólnie rzecz biorąc,
PARAMETERIZATION FORCEDopcja powinna być używana tylko przez doświadczonych specjalistów ds. baz danych po ustaleniu, że nie ma to negatywnego wpływu na wydajność. - Zapytania rozproszone odwołujące się do więcej niż jednej bazy danych kwalifikują się do wymuszonej parametryzacji, o ile opcja
PARAMETERIZATIONjest ustawiona naFORCEDw bazie danych, której kontekstem jest uruchomione zapytanie. - Ustawienie opcji
PARAMETERIZATIONnaFORCEDpowoduje opróżnianie wszystkich planów zapytań z pamięci podręcznej planów w bazie danych, z wyjątkiem tych, które są obecnie kompilowane, ponownie kompilowane lub uruchamiane. Plany dotyczące zapytań kompilujących lub uruchomionych podczas zmiany ustawienia są sparametryzowane przy następnym wykonaniu zapytania. -
PARAMETERIZATIONUstawienie opcji jest operacją online, która nie wymaga blokad wyłącznych na poziomie bazy danych. - Bieżące ustawienie
PARAMETERIZATIONopcji jest zachowywane podczas ponownego dołączenia lub przywracania bazy danych.
Możesz zastąpić zachowanie wymuszonej parametryzacji, określając, że na pojedynczym zapytaniu ma być podjęta próba przeprowadzenia prostej parametryzacji, oraz na innych, które są składniowo równoważne, ale różnią się tylko wartościami parametrów. Z drugiej strony można określić, że wymuszona parametryzacja ma być podejmowana tylko na zestawie zapytań równoważnych składniowo, nawet jeśli wymuszona parametryzacja jest wyłączona w bazie danych. Przewodniki dotyczące planu są używane w tym celu.
Uwaga / Notatka
Kiedy opcja PARAMETERIZATION jest ustawiona na FORCED, raportowanie komunikatów o błędach może różnić się od sytuacji, gdy opcja PARAMETERIZATION jest ustawiona na SIMPLE: w ramach parametryzacji wymuszonej może być zgłaszanych wiele komunikatów o błędach, podczas gdy w ramach prostej parametryzacji zgłaszanych będzie mniej komunikatów, a numery wierszy, w których występują błędy, mogą być raportowane niepoprawnie.
Przygotowywanie instrukcji SQL
Aparat relacyjny programu SQL Server wprowadza pełną obsługę przygotowywania instrukcji Transact-SQL przed ich wykonaniem. Jeśli aplikacja musi wykonać instrukcję Transact-SQL kilka razy, może użyć interfejsu API bazy danych, aby wykonać następujące czynności:
- Przygotuj oświadczenie raz. To kompiluje instrukcję Transact-SQL w plan wykonania.
- Za każdym razem, gdy zachodzi potrzeba wykonania instrukcji, wykonaj wstępnie skompilowany plan wykonawczy. Zapobiega to konieczności ponownego kompilowania instrukcji Transact-SQL dla każdego wykonania po raz pierwszy. Przygotowywanie i wykonywanie instrukcji jest kontrolowane przez funkcje i metody interfejsu API. Nie jest częścią języka Transact-SQL. Model przygotowywania/wykonywania instrukcji Transact-SQL jest obsługiwany przez dostawcę OLE DB natywnego klienta SQL Server i sterownik ODBC natywnego klienta SQL Server. Na żądanie przygotowania dostawca lub sterownik wysyła instrukcję do programu SQL Server z żądaniem przygotowania instrukcji. Serwer SQL kompiluje plan wykonania i zwraca wskaźnik do tego planu dostawcy lub sterownika. Na żądanie wykonania dostawca lub sterownik wysyła do serwera żądanie wykonania planu skojarzonego z uchwytem.
Nie można używać instrukcji przygotowanych do tworzenia obiektów tymczasowych w programie SQL Server. Przygotowane instrukcje nie mogą odwoływać się do systemowych procedur składowanych, które tworzą obiekty tymczasowe, takie jak tabele tymczasowe. Te procedury muszą być wykonywane bezpośrednio.
Nadmierne użycie modelu przygotowywania/wykonywania może obniżyć wydajność. Jeśli instrukcja jest wykonywana tylko raz, bezpośrednie wykonanie wymaga tylko jednej komunikacji sieciowej na serwerze. Przygotowywanie i wykonywanie instrukcji Transact-SQL wykonywanej tylko raz wymaga dodatkowej komunikacji sieciowej; jedna podróż, aby przygotować instrukcję i jedną podróż, aby ją wykonać.
Przygotowywanie instrukcji jest bardziej efektywne, jeśli są używane znaczniki parametrów. Załóżmy na przykład, że aplikacja jest od czasu do czasu proszona o pobranie informacji o produkcie z przykładowej AdventureWorks bazy danych. Istnieją dwa sposoby, w jaki aplikacja może to zrobić.
Korzystając z pierwszego sposobu, aplikacja może wykonać oddzielne zapytanie dla każdego żądanego produktu:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
Korzystając z drugiej metody, aplikacja wykonuje następujące czynności:
Przygotowuje zapytanie zawierające znacznik parametru (?):
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;Wiąże zmienną programową ze znacznikiem parametru.
Za każdym razem, gdy potrzebne są informacje o produkcie, wypełnia zmienną powiązaną wartością klucza i wykonuje instrukcję .
Drugi sposób jest bardziej wydajny, gdy instrukcja jest wykonywana więcej niż trzy razy.
W programie SQL Server model przygotowywania/wykonywania nie ma znaczącej przewagi wydajności nad bezpośrednim wykonywaniem ze względu na sposób ponownego użycia planów wykonywania programu SQL Server. Program SQL Server ma wydajne algorytmy do dopasowywania bieżących instrukcji Transact-SQL z planami wykonywania, które są generowane na potrzeby wcześniejszych wykonań tej samej instrukcji Transact-SQL. Jeśli aplikacja wykonuje instrukcję Transact-SQL ze znacznikami parametrów wiele razy, program SQL Server ponownie użyje planu wykonawczego z pierwszego wykonania dla drugiego i kolejnych wykonań (chyba że plan usunie się z pamięci podręcznej planu). Model przygotowywania/wykonywania nadal ma następujące korzyści:
- Znalezienie planu wykonania za pomocą uchwytu identyfikującego jest bardziej wydajne niż algorytmy stosowane do dopasowania polecenia Transact-SQL do istniejących planów wykonania.
- Aplikacja może kontrolować, kiedy jest tworzony plan wykonania i kiedy jest ponownie używany.
- Model przygotowywania/wykonywania jest przenośny do innych baz danych, w tym wcześniejszych wersji programu SQL Server.
Czułość parametrów
Czułość parametrów, znana również jako "analiza parametrów", odnosi się do procesu, w którym SQL Server analizuje bieżące wartości parametrów podczas kompilacji lub ponownej kompilacji i przekazuje je do optymalizatora zapytań, aby umożliwić generowanie potencjalnie bardziej wydajnych planów wykonywania zapytań.
Wartości parametrów są wykrywane podczas kompilacji lub ponownej kompilacji dla następujących typów partii:
- Procedury przechowywane
- Zapytania przesłane za pośrednictwem
sp_executesql - Przygotowane zapytania
Aby uzyskać więcej informacji na temat rozwiązywania problemów związanych z wąchaniem parametrów, sprawdź:
- Badanie i rozwiązywanie problemów z uwzględnieniem parametrów
- Ponowne użycie parametrów i planu wykonania
- Optymalizacja planów wrażliwych na parametry
- Rozwiązywanie problemów z zapytaniami dotyczącymi planu wykonywania zapytań wrażliwego na parametry w usłudze Azure SQL Database
- Rozwiązywanie problemów z zapytaniami dotyczących parametrów w planie wykonywania zapytań w usłudze Azure SQL Managed Instance
Gdy zapytanie w SQL Server używa OPTION (RECOMPILE) podpowiedzi, optymalizator zapytań zamienia parametry i zmienne lokalne w stałe czasów kompilacji, które mogą być złożone i zmniejszone do literałów. Oznacza to, że podczas kompilacji optymalizator zna i może wykorzystać aktualne wartości parametrów i zmiennych lokalnych w środowisku uruchomieniowym, jakie istnieją bezpośrednio przed wykonaniem tej instrukcji. Opcja (RECOMPILE) umożliwia optymalizatorowi wygenerowanie bardziej optymalnego planu zapytania dostosowanego do określonych wartości i wykorzystania najlepszych indeksów bazowych w czasie wykonywania. W przypadku parametrów ten proces odwołuje się nie do wartości pierwotnie przekazanych do partii lub procedury składowanej, ale do ich wartości w czasie ponownej kompilacji. Te wartości mogły zostać zmodyfikowane w ramach procedury przed dotarciem do instrukcji zawierającej RECOMPILE. To zachowanie może zwiększyć wydajność zapytań z wysoce zmiennymi lub niesymetrycznymi danymi wejściowymi.
Zmienne lokalne
Gdy zapytanie używa zmiennych lokalnych, SQL Server nie może przewidywać ich wartości w czasie kompilacji, więc szacuje kardynalność, korzystając z dostępnych statystyk lub heurystyk. Jeśli istnieją statystyki, zazwyczaj używa wartości All Density (znanej również jako średnia gęstość) z histogramu statystycznego, aby oszacować, ile wierszy pasuje do predykatu. Jeśli jednak dla kolumny nie są dostępne żadne statystyki, program SQL Server powraca do oszacowań heurystycznych, takich jak przy założeniu 10% selektywności predykatów równości i 30% dla nierówności i zakresów, co może prowadzić do mniej dokładnych planów wykonania. Oto przykład zapytania, które używa zmiennej lokalnej.
DECLARE @ProductId INT = 100;
SELECT * FROM Products WHERE ProductId = @ProductId;
W takim przypadku program SQL Server nie używa wartości 100 do optymalizacji zapytania. Używa ona ogólnego oszacowania.
Równoległe przetwarzanie zapytań
Program SQL Server udostępnia zapytania równoległe w celu optymalizacji wykonywania zapytań i operacji indeksowania dla komputerów, które mają więcej niż jeden mikroprocesor (procesor CPU). Ponieważ program SQL Server może równolegle wykonać operację zapytania lub indeksu przy użyciu kilku wątków procesu roboczego systemu operacyjnego, operację można wykonać szybko i wydajnie.
Podczas optymalizacji zapytań program SQL Server szuka zapytań lub operacji indeksowania, które mogą korzystać z równoległego wykonywania. W przypadku tych zapytań program SQL Server wstawia operatory wymiany do planu wykonywania zapytań w celu przygotowania zapytania do równoległego wykonywania. Operator wymiany to operator w planie wykonywania zapytań, który zapewnia zarządzanie procesami, redystrybucję danych i sterowanie przepływem. Operator wymiany zawiera Distribute Streams, Repartition Streams oraz Gather Streams jako podtypy, z których co najmniej jeden może pojawić się w danych wyjściowych planu zapytania programu Showplan dla zapytania równoległego.
Ważne
Niektóre konstrukcje uniemożliwiają SQL Serverowi zdolność równoległego wykonywania całego planu wykonawczego lub jego części.
Konstrukcje hamujące równoległość obejmują:
Skalarne funkcje zdefiniowane przez użytkownika
Aby uzyskać więcej informacji na temat funkcji zdefiniowanych przez użytkownika skalarnych, zobacz Create User-defined Functions (Tworzenie funkcji zdefiniowanych przez użytkownika). Począwszy od programu SQL Server 2019 (15.x), aparat bazy danych programu SQL Server ma możliwość inlinowania tych funkcji i wykorzystania równoległości podczas przetwarzania zapytań. Aby uzyskać więcej informacji na temat tworzenia wbudowanych funkcji UDF skalarnych, zobacz Inteligentne przetwarzanie zapytań w bazach danych SQL.Zapytanie zdalne
Aby uzyskać więcej informacji na temat zapytania zdalnego, zobacz Showplan Logical and Physical Operators Reference (Dokumentacja operatorów logicznych i fizycznych programu Showplan).Dynamiczne kursory
Aby uzyskać więcej informacji na temat kursorów, zobacz DEKLAROWANIE KURSORA.Zapytania cykliczne
Aby uzyskać więcej informacji na temat rekursji, zobacz Wytyczne dotyczące definiowania i używania cyklicznych wspólnych wyrażeń tabel i rekursji w języku T-SQL.Funkcje z wieloma instrukcjami w tabeli (MSTVFs)
Aby uzyskać więcej informacji na temat funkcji MSTVF, zobacz Create User-defined Functions (Database Engine).SŁOWO kluczowe TOP
Aby uzyskać więcej informacji, zobacz TOP (Transact-SQL).
Plan wykonywania zapytania może zawierać atrybut NonParallelPlanReason w elemecie QueryPlan , który opisuje, dlaczego równoległość nie była używana. Wartości tego atrybutu to:
| Wartość NonParallelPlanReason | Opis |
|---|---|
| MaxDOPSetToOne | Maksymalny stopień równoległości ustawiony na 1. |
| SzacowanyDOPJestJeden | Szacowany stopień równoległości wynosi 1. |
| Brak równoległości z zapytaniem zdalnym | Równoległość nie jest obsługiwana w przypadku zapytań zdalnych. |
| BrakRównoległegoDynamicznegoKursora | Plany równoległe nie są obsługiwane w przypadku kursorów dynamicznych. |
| KursorBrakRównoległegoSzybkiegoPrzewijaniaNaprzód | Plany równoległe nie są obsługiwane w przypadku szybkich kursorów do przodu. |
| NoParallelCursorFetchByBookmark | Plany równoległe nie są obsługiwane w przypadku kursorów pobieranych przy użyciu zakładki. |
| Brak równoległego tworzenia indeksu w wersji nie-enterprise | Równoległe tworzenie indeksu nie jest obsługiwane w przypadku wersji innej niż Enterprise. |
| BrakPlanówRównoległychWDesktopLubeWersjiExpress | Plany równoległe nie są obsługiwane w przypadku edycji Desktop i Express. |
| Funkcja Nierównoległa Wewnętrzna | Zapytanie odwołuje się do funkcji wewnętrznej, która nie może być równoległa. |
| Funkcja zdefiniowana przez użytkownika CLR wymaga dostępu do danych | Przetwarzanie równoległe nie można użyć w przypadku funkcji UDF w CLR, która wymaga dostępu do danych. |
| Funkcje użytkownika TSQL nie mogą być równoległe | Zapytanie odwołuje się do funkcji zdefiniowanej przez użytkownika języka T-SQL, która nie była równoległa. |
| Transakcje na zmiennych tabelarycznych nie obsługują równoległych zagnieżdżonych transakcji | Transakcje zmiennych typu tabeli nie obsługują równoległych transakcji zagnieżdżonych. |
| ZapytanieDMLZwrociWyjscieDoKlienta | Zapytanie DML zwraca dane wyjściowe do klienta i nie może być wykonywane równolegle. |
| Mieszane cięgi i równoległe budowanie indeksów online nie są obsługiwane | Nieobsługiwana kombinacja planów szeregowych i równoległych dla pojedynczej kompilacji indeksu online. |
| Nie można wygenerować prawidłowego planu równoległego | Weryfikacja planu równoległego nie powiodła się, przejście do szeregowego. |
| Brak Równoległości dla Tabel z Optymalizacją Pamięci | Równoległość nie jest obsługiwana dla referencyjnych tabel OLTP In-Memory. |
| NoParallelForDmlNaTabeliZoptymalizowanejPodWzględemPamięci | Równoległe przetwarzanie nie jest obsługiwane dla DML w tabeli OLTP In-Memory. |
| Brak Równoległości w Natralnie Skompilowanym Module | Równoległość nie jest obsługiwana w przypadku natywnie skompilowanych modułów. |
| BrakZakresówWznawialneTworzenie | Generowanie zakresu nie powiodło się w przypadku operacji tworzenia możliwej do wznowienia. |
Po wstawieniu operatorów wymiany powstaje plan wykonania zapytań równoległych. Plan wykonywania zapytań równoległych może używać więcej niż jednego wątku roboczego. Plan wykonania szeregowego, używany przez zapytanie nie równoległe (szeregowe), wykorzystuje tylko jeden wątek wykonawczy do jego realizacji. Rzeczywista liczba wątków roboczych używanych przez zapytanie równoległe jest określana podczas inicjowania wykonywania planu zapytania i jest określana przez złożoność planu i stopień równoległości.
Stopień równoległości (DOP) określa maksymalną liczbę używanych procesorów CPU; nie oznacza to liczby używanych wątków roboczych. Limit DOP jest ustawiany dla zadania. Nie jest to ograniczenie na żądanie lub ograniczenie na zapytanie. Oznacza to, że podczas równoległego wykonywania zapytania pojedyncze żądanie może uruchomić wiele zadań przypisanych do harmonogramisty. Więcej procesorów niż określono w ustawieniu MAXDOP może być używanych równocześnie w dowolnym momencie wykonywania zapytania, gdy równocześnie wykonuje się różne zadania. Aby uzyskać więcej informacji, zobacz przewodnik po architekturze wątków i zadań .
Optymalizator zapytań programu SQL Server nie używa równoległego planu wykonywania dla zapytania, jeśli spełniony jest jeden z następujących warunków:
- Plan wykonywania szeregowego jest trywialny lub nie przekracza progu kosztów dla ustawienia równoległego przetwarzania.
- Plan wykonywania szeregowego ma niższy całkowity szacowany koszt poddrzewa niż jakikolwiek równoległy plan wykonywania rozważany przez optymalizator.
- Zapytanie zawiera operatory skalarne lub relacyjne, których nie można uruchomić równolegle. Niektóre operatory mogą spowodować uruchomienie sekcji planu zapytania w trybie seryjnym lub uruchomienie całego planu w trybie seryjnym.
Uwaga / Notatka
Łączny szacowany koszt poddrzewa planu równoległego może być niższy niż próg kosztów ustawienia równoległości. Oznacza to, że łączny szacowany koszt poddrzewa planu szeregowego został przekroczony, a wybrano plan zapytania z niższym łącznym szacowanym kosztem poddrzewa.
Stopień równoległości (DOP)
Program SQL Server automatycznie wykrywa najlepszy stopień równoległości dla każdego wystąpienia równoległego wykonywania zapytań lub operacji języka definicji danych indeksu (DDL). Jest to oparte na następujących kryteriach:
Niezależnie od tego, czy program SQL Server jest uruchomiony na komputerze z więcej niż jednym mikroprocesorem, czy procesorem CPU, takim jak symetryczny komputer wieloprocesorowy (SMP). Tylko komputery z więcej niż jednym procesorem CPU mogą używać zapytań równoległych.
Czy są dostępne wystarczające wątki robocze. Każda operacja zapytania lub indeksu wymaga wykonania określonej liczby wątków roboczych. Wykonanie planu równoległego wymaga więcej wątków roboczych niż plan seryjny, a liczba wymaganych wątków roboczych zwiększa się wraz ze stopniem równoległości. Gdy nie można spełnić wymagania wątku roboczego planu równoległego dla określonego stopnia równoległości, aparat bazy danych programu SQL Server automatycznie zmniejsza ten stopień lub całkowicie porzuca plan równoległy w kontekście określonego obciążenia. Następnie wykonuje plan seryjny (jeden wątek procesu roboczego).
Wykonany typ operacji zapytania lub indeksu. Operacje indeksowania, które tworzą lub ponownie kompilują indeks, usuwają indeks klastrowany, oraz zapytania intensywnie korzystające z cykli CPU, są najlepszymi kandydatami do planu równoległego. Na przykład łączenia dużych tabel, duże agregacje i sortowanie wyników z dużych zestawów są dobrymi kandydatami. Proste zapytania, często spotykane w aplikacjach przetwarzania transakcji, doświadczają, że dodatkowa koordynacja wymagana do równoległego wykonywania zapytania przewyższa potencjalne korzyści wydajnościowe. Aby odróżnić zapytania, które korzystają z równoległości i tych, które nie przynoszą korzyści, aparat bazy danych programu SQL Server porównuje szacowany koszt wykonywania operacji zapytania lub indeksu z progiem kosztu dla wartości równoległości . Użytkownicy mogą zmienić wartość domyślną 5 przy użyciu sp_configure , jeśli odpowiednie testy wykazały, że inna wartość jest lepiej odpowiednia dla uruchomionego obciążenia.
Czy istnieje wystarczająca liczba wierszy do przetworzenia. Jeśli optymalizator zapytań ustali, że liczba wierszy jest zbyt mała, nie wprowadza operatorów wymiany w celu dystrybucji wierszy. W związku z tym operatory są wykonywane szeregowo. Wykonywanie operatorów w serialnym planie pozwala uniknąć scenariuszy, gdy koszty uruchamiania, dystrybucji i koordynacji przewyższają zyski osiągnięte dzięki równoległemu wykonywaniu operatorów.
Czy są dostępne bieżące statystyki dystrybucji. Jeśli najwyższy stopień równoległości nie jest możliwy, niższe stopnie są brane pod uwagę przed porzuceniem planu równoległego. Na przykład podczas tworzenia klastrowanego indeksu w widoku nie można ocenić statystyk dystrybucji, ponieważ indeks klastrowany jeszcze nie istnieje. W takim przypadku aparat bazy danych programu SQL Server nie może zapewnić najwyższego stopnia równoległości dla operacji indeksowania. Jednak niektóre operatory, takie jak sortowanie i skanowanie, mogą nadal korzystać z równoległego wykonywania.
Uwaga / Notatka
Równoległe operacje indeksowania są dostępne tylko w wersjach SQL Server Enterprise, Developer i Evaluation.
W czasie wykonywania aparat bazy danych programu SQL Server określa, czy bieżące obciążenie systemu i informacje o konfiguracji opisane wcześniej umożliwiają równoległe wykonywanie. Jeśli wykonywanie równoległe jest uzasadnione, aparat bazy danych programu SQL Server określa optymalną liczbę wątków roboczych i rozkłada wykonywanie planu równoległego w tych wątkach roboczych. Gdy operacja zapytania lub indeksu rozpoczyna wykonywanie na wielu wątkach roboczych na potrzeby wykonywania równoległego, ta sama liczba wątków procesów roboczych jest używana do momentu ukończenia operacji. Aparat bazy danych programu SQL Server ponownie sprawdza optymalną liczbę decyzji wątku roboczego za każdym razem, gdy plan wykonania jest pobierany z pamięci podręcznej planu. Na przykład jedno wykonanie zapytania może spowodować użycie planu szeregowego, późniejsze wykonanie tego samego zapytania może spowodować równoległe użycie trzech wątków roboczych, a trzecie wykonanie może spowodować równoległe użycie czterech wątków roboczych.
Operatory aktualizacji i usuwania w równoległym planie wykonania zapytań są wykonywane sekwencyjnie, ale klauzula instrukcji WHERE lub UPDATE może być wykonywana równolegle. Rzeczywiste zmiany danych są następnie szeregowo stosowane do bazy danych.
Do programu SQL Server 2012 (11.x) operator wstawiania jest również wykonywany szeregowo. Jednak część SELECT instrukcji INSERT może być wykonywana równolegle. Rzeczywiste zmiany danych są następnie szeregowo stosowane do bazy danych.
Począwszy od programu SQL Server 2014 (12.x) i poziomu zgodności bazy danych 110, instrukcję SELECT ... INTO można wykonać równolegle. Inne formy operatorów wstawiania działają tak samo jak w przypadku programu SQL Server 2012 (11.x).
Począwszy od programu SQL Server 2016 (13.x) i poziomu zgodności bazy danych 130, instrukcję INSERT ... SELECT można wykonać równolegle podczas wstawiania do sterty lub klastrowanych indeksów magazynu kolumn (CCI) i przy użyciu wskazówki TABLOCK. Funkcja wstawiania do lokalnych tabel tymczasowych (zidentyfikowanych przez prefiks #) oraz globalnych tabel tymczasowych (zidentyfikowanych przez prefiksy ##) jest również włączona dla równoległego przetwarzania przy użyciu wskazówki TABLOCK. Aby uzyskać więcej informacji, zobacz INSERT (Transact-SQL).
Statyczne i oparte na zestawie kluczy kursory mogą być wypełniane przez równoległe plany wykonywania. Jednak zachowanie kursorów dynamicznych może być udostępniane tylko przez wykonywanie szeregowe. Optymalizator zapytań zawsze generuje plan wykonywania szeregowego dla zapytania będącego częścią kursora dynamicznego.
Przesłanianie stopni równoległości
Stopień równoległości określa liczbę procesorów do użycia w równoległym wykonywaniu planu. Tę konfigurację można ustawić na różnych poziomach:
Poziom serwera przy użyciu opcji konfiguracji serwera max degree of parallelism (MAXDOP).
SQL ServerUwaga / Notatka
Program SQL Server 2019 (15.x) wprowadza automatyczne zalecenia dotyczące ustawiania opcji konfiguracji serwera MAXDOP podczas procesu instalacji. Interfejs użytkownika konfiguracji umożliwia akceptowanie zalecanych ustawień lub wprowadzanie własnej wartości. Aby uzyskać więcej informacji, zobacz Stronę Konfiguracja aparatu bazy danych — MaxDOP.
Poziom obciążenia przy użyciu opcji konfiguracji grupy obciążeń MAX_DOPZarządca zasobów.
Dotyczy: SQL ServerPoziom bazy danych przy użyciu konfiguracji o zakresie bazy danychMAXDOP.
Dotyczy: SQL Server i Azure SQL DatabasePoziom instrukcji zapytania lub indeksu przy użyciu wskazówki zapytaniaMAXDOP lub opcji indeksu MAXDOP. Na przykład można użyć opcji MAXDOP, aby kontrolować, zwiększając lub zmniejszając liczbę procesorów dedykowanych operacji indeksowania online. W ten sposób można zrównoważyć zasoby używane przez operację indeksu z równoczesnymi użytkownikami.
Dotyczy: SQL Server i Azure SQL Database
Ustawienie maksymalnego stopnia równoległości na 0 (wartość domyślna) umożliwia programowi SQL Server używanie wszystkich dostępnych procesorów do maksymalnie 64 procesorów w równoległym wykonywaniu planu. Mimo że SQL Server ustawia docelową wartość 64 procesorów logicznych, gdy opcja MAXDOP jest ustawiona na 0, można ręcznie ustawić inną wartość, jeśli to konieczne. Ustawienie parametru MAXDOP na 0 dla zapytań i indeksów umożliwia programowi SQL Server używanie wszystkich dostępnych procesorów do maksymalnie 64 procesorów dla danych zapytań lub indeksów w równoległym wykonaniu planu. PARAMETR MAXDOP nie jest wymuszaną wartością dla wszystkich zapytań równoległych, ale raczej wstępnym celem dla wszystkich zapytań kwalifikujących się do równoległości. Oznacza to, że jeśli w czasie wykonywania nie ma wystarczającej liczby wątków roboczych, zapytanie może zostać wykonane z niższym stopniem równoległości niż opcja konfiguracji serwera MAXDOP.
Wskazówka
Aby uzyskać więcej informacji, zobacz ZALECENIA DOTYCZĄCE OPCJI MAXDOP , aby uzyskać wskazówki dotyczące konfigurowania opcji MAXDOP na poziomie serwera, bazy danych, zapytań lub wskazówek.
Przykład zapytania równoległego
Poniższe zapytanie zlicza liczbę zamówień złożonych w określonym kwartale, począwszy od 1 kwietnia 2000 r., i w których co najmniej jeden wiersz zamówienia został odebrany przez klienta później niż data zatwierdzenia. To zapytanie zawiera listę liczby takich zamówień pogrupowanych według każdego priorytetu zamówienia i posortowanych w kolejności rosnącego priorytetu.
W tym przykładzie użyto teoretycznych nazw tabel i kolumn.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
Załóżmy, że następujące indeksy są zdefiniowane w tabelach lineitem i :orders
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
Poniżej przedstawiono jeden możliwy plan równoległy wygenerowany dla wcześniej pokazanego zapytania:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
Na poniższej ilustracji przedstawiono plan zapytania wykonany ze stopniem równoległości równym 4 i obejmujący połączenie dwóch tabel.
Plan równoległy zawiera trzy operatory równoległości. Zarówno operator Wyszukiwania Indeksu o_datkey_ptr, jak i operator Skanowania Indeksu l_order_dates_idx są wykonywane równolegle. Tworzy to kilka ekskluzywnych strumieni. Można to określić na podstawie najbliższych operatorów równoległości powyżej operatorów skanowania indeksu i wyszukiwania indeksów, odpowiednio. Oba dotyczą repartycjonowania rodzaju wymiany. Oznacza to, że po prostu przetasowują dane między strumieniami i generują taką samą liczbę strumieni na wyjściu, jak na wejściu. Ta liczba strumieni jest równa stopniowi równoległości.
Operator obsługujący równoległe przetwarzanie nad operatorem skanowania indeksu l_order_dates_idx przeszeregowuje swoje strumienie wejściowe, używając wartości L_ORDERKEY jako klucza. W ten sposób te same wartości L_ORDERKEY są wyświetlane w tym samym strumieniu wyjściowym. Jednocześnie strumienie wyjściowe utrzymują kolejność w L_ORDERKEY kolumnie, aby spełnić wymagania wejściowe operatora scalania sprzężenia.
Operator równoległości nad operatorem Index Seek repartycjonuje swoje strumienie wejściowe, wykorzystując wartość O_ORDERKEY. Ponieważ jego dane wejściowe nie są sortowane według wartości kolumny O_ORDERKEY i będąca kolumną łączenia w operatorze Merge Join, operator Sort między operatorom równoległości i scalania upewnia się, że dane wejściowe są posortowane dla operatora Merge Join na kolumnach łączenia. Operator Sort, podobnie jak operator łączenia przez scalanie, jest wykonywany równolegle.
Najwyższy operator równoległości zbiera wyniki z kilku strumieni w jeden strumień. Częściowe agregacje wykonywane przez operator Agregacji Strumienia poniżej operatora równoległości są następnie kumulowane do jednej SUM wartości dla każdej unikalnej wartości O_ORDERPRIORITY przez operator Agregacji Strumienia powyżej operatora równoległości. Ponieważ ten plan ma dwa segmenty wymiany, z stopniem równoległości równym 4, używa ośmiu wątków roboczych.
Aby uzyskać więcej informacji na temat operatorów używanych w tym przykładzie, zobacz Dokumentację operatorów logicznych i fizycznych programu Showplan.
Równoległe operacje indeksowania
Plany zapytań utworzone na potrzeby operacji indeksowania, które tworzą lub ponownie kompilują indeks lub usuwają indeks klastrowany, umożliwiają równoległe operacje wątkowe obejmujące wiele procesów roboczych na komputerach z wieloma mikroprocesorami.
Uwaga / Notatka
Operacje indeksowania równoległego są dostępne tylko w wersji Enterprise Edition, począwszy od programu SQL Server 2008 (10.0.x).
Program SQL Server używa tych samych algorytmów, aby określić stopień równoległości (łączna liczba oddzielnych wątków roboczych do uruchomienia) dla operacji indeksowania, tak jak w przypadku innych zapytań. Maksymalny stopień równoległości dla operacji indeksowania zależy od opcji konfiguracyjnej serwera max degree of parallelism. Możesz zastąpić maksymalny stopień równoległości dla poszczególnych operacji indeksowania, ustawiając opcję indeksu MAXDOP w instrukcjach CREATE INDEX, ALTER INDEX, DROP INDEX i ALTER TABLE.
Gdy aparat bazy danych programu SQL Server skompiluje plan wykonywania indeksu, liczba operacji równoległych jest ustawiana na najniższą wartość spośród następujących:
- Liczba mikroprocesorów lub procesorów CPU na komputerze.
- Liczba określona w maksymalnym stopniu równoległości opcji konfiguracji serwera.
- Liczba procesorów CPU nie przekroczyła jeszcze progu pracy wykonywanej dla wątków roboczych programu SQL Server.
Na przykład na komputerze z ośmioma procesorami CPU, ale gdy maksymalny stopień równoległości jest ustawiony na 6, nie więcej niż sześć równoległych wątków roboczych jest generowanych dla operacji indeksowania. Jeśli pięć procesorów CPU na komputerze przekroczy próg pracy programu SQL Server podczas tworzenia planu wykonywania indeksu, plan wykonywania określa tylko trzy równoległe wątki procesu roboczego.
Główne fazy operacji indeksu równoległego obejmują następujące elementy:
- Koordynujący wątek roboczy szybko i losowo skanuje tabelę, aby oszacować rozkład kluczy indeksu. Koordynujący wątek procesu roboczego ustanawia granice kluczy, które spowodują utworzenie wielu zakresów kluczy równych stopniom operacji równoległych, w których każdy zakres kluczy jest szacowany na pokrycie podobnej liczby wierszy. Jeśli na przykład w tabeli znajdują się cztery miliony wierszy, a stopień równoległości wynosi 4, koordynujący wątek procesu roboczego określi kluczowe wartości rozdzielające cztery zestawy wierszy z 1 milionami wierszy w każdym zestawie. Jeśli nie można ustanowić wystarczającej liczby zakresów kluczowych, aby użyć wszystkich procesorów, stopień równoległości jest odpowiednio zredukowany.
- Koordynujący wątek roboczy uruchamia liczbę wątków roboczych równą liczbie równoległych operacji i czeka na zakończenie przez nie pracy. Każdy wątek roboczy skanuje tabelę podstawową przy użyciu filtru, który pobiera tylko wiersze z wartościami klucza w zakresie przypisanym do wątku roboczego. Każdy wątek roboczy tworzy strukturę indeksu dla wierszy w swoim zakresie kluczy. W przypadku indeksu partycjonowanego każdy wątek procesu roboczego tworzy określoną liczbę partycji. Partycje nie są dzielone przez wątki robocze.
- Po zakończeniu wszystkich równoległych wątków roboczych, koordynujący wątek roboczy integruje podjednostki indeksu w pojedynczy indeks. Ta faza dotyczy tylko operacji indeksowania w trybie offline.
Poszczególne CREATE TABLE wyrażenia lub ALTER TABLE mogą mieć wiele ograniczeń, które wymagają utworzenia indeksu. Te operacje tworzenia wielu indeksów są wykonywane w serii, chociaż każda pojedyncza operacja tworzenia indeksu może być operacją równoległą na komputerze, który ma wiele procesorów CPU.
Architektura zapytań rozproszonych
Program Microsoft SQL Server obsługuje dwie metody odwoływania się do heterogenicznych źródeł danych OLE DB w instrukcjach Transact-SQL:
Nazwy serwerów połączonych
Procedury składowane systemowesp_addlinkedserverisp_addlinkedsrvloginsłużą do przypisania nazwy serwera źródłu danych OLE DB. Obiekty na połączonych serwerach można odnosić w instrukcjach Transact-SQL przy użyciu czteroczęściowych nazw. Na przykład, jeśli nazwa połączonego serweraDeptSQLSrvrjest zdefiniowana dla innego wystąpienia SQL Server, następujące polecenie odwołuje się do tabeli na tym serwerze:SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;Nazwę serwera połączonego można również określić w instrukcji
OPENQUERY, aby otworzyć zestaw wierszy ze źródła danych OLE DB. Ten zestaw wierszy może być następnie przywoływany jak tabela w instrukcjach Transact-SQL.Nazwy łączników ad hoc
W przypadku rzadkich odwołań do źródła danych funkcjeOPENROWSETlubOPENDATASOURCEsą wyznaczane przy użyciu informacji potrzebnych do nawiązania połączenia z serwerem powiązanym. Zestaw wierszy może następnie odwoływać się do tego samego sposobu, w jaki tabela jest przywoływana w instrukcjach Transact-SQL:SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
Program SQL Server używa OLE DB do komunikacji między silnikiem relacyjnym a silnikiem magazynującym. Silnik relacyjny rozdziela każdą instrukcję Transact-SQL na serie operacji na prostych zestawach wierszy OLE DB, otwartych przez silnik magazynujący z tabel podstawowych. Oznacza to, że aparat relacyjny może również otwierać proste zestawy wierszy OLE DB w dowolnym źródle danych OLE DB.
Aparat relacyjny używa interfejsu programowania aplikacji OLE DB (API) do otwierania zestawów wierszy na serwerach połączonych, pobierania wierszy i zarządzania transakcjami.
Dla każdego źródła danych OLE DB dostępnego jako serwer połączony dostawca OLE DB musi znajdować się na serwerze z uruchomionym programem SQL Server. Zestaw operacji Transact-SQL, które mogą być używane względem określonego źródła danych OLE DB, zależy od możliwości dostawcy OLE DB.
Dla każdego wystąpienia programu SQL Server, członkowie stałej roli serwera sysadmin mogą włączać lub wyłączać używanie nazw łączników ad hoc dla dostawcy OLE DB przy użyciu właściwości DisallowAdhocAccess programu SQL Server. Po włączeniu dostępu ad hoc każdy użytkownik zalogowany do tego wystąpienia może wykonywać instrukcje Transact-SQL, które zawierają nazwy łączników ad hoc, odwołując się do dowolnego źródła danych w sieci, do którego można uzyskać dostęp za pomocą tego dostawcy OLE DB. Aby kontrolować dostęp do źródeł danych, członkowie sysadmin roli mogą wyłączyć dostęp ad hoc dla tego dostawcy OLE DB, ograniczając w ten sposób użytkowników tylko do tych źródeł danych, do których odwołuje się połączona nazwa serwera zdefiniowana przez administratorów. Domyślnie dostęp ad hoc jest włączony dla dostawcy OLE DB programu SQL Server i wyłączony dla wszystkich innych dostawców OLE DB.
Zapytania rozproszone mogą zezwalać użytkownikom na dostęp do innego źródła danych (na przykład plików, źródeł danych nierelacyjnych, takich jak usługa Active Directory itd.), przy użyciu kontekstu zabezpieczeń konta systemu Microsoft Windows, w ramach którego jest uruchomiona usługa SQL Server. Program SQL Server przyjmuje tożsamość loginu odpowiednio dla loginów Windows; jednak nie jest to możliwe dla loginów SQL Server. Może to potencjalnie umożliwić użytkownikowi zapytania rozproszonego dostęp do innego źródła danych, dla którego nie mają uprawnień, ale konto, na którym działa usługa SQL Server, ma uprawnienia. Użyj sp_addlinkedsrvlogin do zdefiniowania konkretnych identyfikatorów logowania, które są autoryzowane do uzyskiwania dostępu do odpowiedniego serwera połączonego. Ta kontrolka nie jest dostępna dla nazw ad hoc, dlatego należy zachować ostrożność podczas włączania dostawcy OLE DB na potrzeby dostępu ad hoc.
Jeśli to możliwe, SQL Server przekazuje operacje relacyjne, takie jak łączenia, ograniczenia, projekcje, sortowania i operacje grupowania do źródła danych OLE DB. SQL Server domyślnie nie skanuje tabeli bazowej ani nie wykonuje operacji relacyjnych samodzielnie. Program SQL Server wysyła zapytanie do dostawcy OLE DB w celu określenia poziomu obsługiwanej przez niego gramatyki SQL i, na podstawie tych informacji, wypycha jak najwięcej operacji relacyjnych do dostawcy.
Program SQL Server określa mechanizm dla dostawcy OLE DB w celu zwrócenia statystyk wskazujących, jak wartości kluczy są dystrybuowane w źródle danych OLE DB. Dzięki temu optymalizator zapytań programu SQL Server lepiej analizuje wzorzec danych w źródle danych pod kątem wymagań każdej instrukcji Transact-SQL, zwiększając możliwość optymalizatora zapytań w celu generowania optymalnych planów wykonywania.
Ulepszenia przetwarzania zapytań dotyczące partycjonowanych tabel i indeksów
Program SQL Server 2008 (10.0.x) poprawił wydajność przetwarzania zapytań w tabelach partycjonowanych dla wielu planów równoległych, zmienia sposób reprezentowania równoległych i szeregowych planów oraz ulepszono informacje o partycjonowaniu udostępniane zarówno w planach wykonywania w czasie kompilacji, jak i w czasie wykonywania. W tym artykule opisano te ulepszenia, przedstawiono wskazówki dotyczące interpretowania planów wykonywania zapytań dla partycjonowanych tabel i indeksów oraz zawiera najlepsze rozwiązania dotyczące poprawy wydajności zapytań dotyczących partycjonowanych obiektów.
Uwaga / Notatka
Do wersji SQL Server 2014 (12.x) tabele i indeksy partycjonowane są obsługiwane tylko w wersjach SQL Server Enterprise, Developer i Evaluation. Począwszy od programu SQL Server 2016 (13.x) SP1, tabele partycjonowane i indeksy są również obsługiwane w wersji SQL Server Standard.
Nowa funkcja wyszukiwania uwzględniająca partycje
W programie SQL Server wewnętrzna reprezentacja tabeli partycjonowanej jest zmieniana tak, że tabela wydaje się procesorowi zapytań jakby była wielokolumnowym indeksem, z PartitionID jako kolumną wiodącą.
PartitionID jest ukrytą kolumną obliczeniową używaną wewnętrznie do reprezentowania ID partycji zawierającej określony wiersz. Załóżmy na przykład, że tabela T, zdefiniowana jako T(a, b, c), jest podzielona na partycje w kolumnie a i ma indeks klastrowany w kolumnie b. W programie SQL Server ta tabela partycjonowana jest traktowana wewnętrznie jako niepartycjonowana tabela ze schematem T(PartitionID, a, b, c) i indeksem klastrowanym na kluczu złożonym (PartitionID, b). Dzięki temu optymalizator zapytań może wykonywać operacje wyszukiwania na podstawie PartitionID dowolnej partycjonowanej tabeli lub indeksu.
Eliminacja partycji jest teraz wykonywana w tej operacji wyszukiwania.
Ponadto optymalizator zapytań jest rozszerzony tak, aby można było wykonać operację wyszukiwania lub skanowania na PartitionID (jako logicznej kolumnie wiodącej) z jednym warunkiem, a także ewentualnie na innych kolumnach klucza indeksu. Następnie można przeprowadzić wyszukiwanie drugiego poziomu, z innym warunkiem, na jednej lub więcej dodatkowych kolumnach dla każdej odrębnej wartości, która spełnia warunki operacji wyszukiwania pierwszego poziomu. Oznacza to, że ta operacja, nazywana skanowaniem pomijania, umożliwia optymalizatorowi zapytań wykonywanie operacji wyszukiwania lub skanowania na podstawie jednego warunku w celu określenia partycji, do których ma być uzyskiwany dostęp, oraz operacji wyszukiwania indeksu drugiego poziomu w ramach tego operatora w celu zwrócenia wierszy z tych partycji spełniających inny warunek. Rozważmy na przykład następujące zapytanie.
SELECT * FROM T WHERE a < 10 and b = 2;
W tym przykładzie załóżmy, że tabela T, zdefiniowana jako T(a, b, c), jest podzielona na partycje w kolumnie a i ma indeks klastrowany w kolumnie b. Granice partycji dla tabeli T są definiowane przez następującą funkcję partycji:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
Aby rozwiązać zapytanie, procesor zapytań wykonuje operację wyszukiwania pierwszego poziomu, aby znaleźć każdą partycję zawierającą wiersze spełniające warunek T.a < 10. Spowoduje to zidentyfikowanie partycji, do których mają być uzyskiwane dostęp. W ramach każdej zidentyfikowanej partycji procesor wykonuje następnie wyszukiwanie drugiego poziomu w indeksie klastrowanym w kolumnie b w celu znalezienia wierszy spełniających warunek T.b = 2 i T.a < 10.
Poniższa ilustracja przedstawia logiczną reprezentację operacji pomijania skanowania. Przedstawia tabelę T z danymi w kolumnach a i b. Partycje są numerowane od 1 do 4 z granicami partycji wyświetlanymi przez kreskowane linie pionowe. Operacja wyszukiwania pierwszego poziomu dla partycji (nie pokazana na ilustracji) ustaliła, że partycje 1, 2 i 3 spełniają warunek wyszukiwania implikowany przez partycjonowanie zdefiniowane dla tabeli i predykatu w kolumnie a. Oznacza to, T.a < 10. Ścieżka przebywana przez drugopoziomową część wyszukiwania w operacji skanowania z pomijaniem jest ilustrowana krzywą linią. Zasadniczo operacja pomijania skanowania wyszukuje w każdej z tych partycji wiersze, które spełniają warunek b = 2. Całkowity koszt operacji pomijania skanowania jest taki sam jak w przypadku trzech oddzielnych wyszukiwań indeksów.
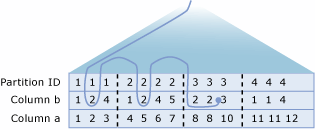
Wyświetlanie informacji o partycjonowaniu w planach wykonywania zapytań
Plany wykonywania zapytań na partycjonowanych tabelach i indeksach można zbadać za pomocą instrukcji Transact-SQL SET, SET SHOWPLAN_XML lub SET STATISTICS XML, albo korzystając z danych wyjściowych graficznego planu wykonywania w programie SQL Server Management Studio. Możesz na przykład wyświetlić plan wykonywania w czasie kompilacji, wybierając pozycję Wyświetl szacowany plan wykonania na pasku narzędzi Edytora zapytań i plan czasu wykonywania, wybierając pozycję Uwzględnij rzeczywisty plan wykonania.
Korzystając z tych narzędzi, można ustalić następujące informacje:
- Operacje, takie jak
scans,seeks,inserts,updates,mergesideletes, uzyskują dostęp do partycjonowanych tabel lub indeksów. - Partycje, do których uzyskuje dostęp zapytanie. Na przykład łączna liczba partycji, do których uzyskiwano dostęp, oraz ciągłe zakresy partycji, do których uzyskuje się dostęp, są dostępne w planach wykonawczych w czasie działania.
- Gdy operacja pomijania skanowania jest używana w operacji wyszukiwania lub skanowania w celu pobrania danych z co najmniej jednej partycji.
Ulepszenia informacji o partycji
Program SQL Server udostępnia rozszerzone informacje o partycjonowaniu zarówno dla planów wykonywania w czasie kompilacji, jak i w czasie wykonywania. Plany wykonywania zawierają teraz następujące informacje:
- Opcjonalny
Partitionedatrybut wskazujący, że operator, taki jakseek,scan,insert,updatemergelubdelete, jest wykonywany w tabeli partycjonowanej. - Nowy element
SeekPredicateNewz podelementemSeekKeys, który zawieraPartitionIDjako kolumnę klucza indeksu wiodącego i warunki filtrowania, które określają wyszukiwanie zakresowe naPartitionID. Obecność dwóchSeekKeyspodelementów wskazuje, że została użyta operacja skanowania z pominięciemPartitionID. - Podsumowanie informacji, które zawierają łączną liczbę partycji, do których uzyskiwano dostęp. Te informacje są dostępne tylko w planach czasu wykonywania.
Aby zademonstrować sposób wyświetlania tych informacji zarówno w danych wyjściowych graficznego planu wykonywania, jak i danych wyjściowych programu XML Showplan, rozważ następujące zapytanie w tabeli fact_salespartycjonowanej . To zapytanie aktualizuje dane w dwóch partycjach.
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
Poniższa ilustracja przedstawia właściwości operatora Clustered Index Seek w planie wykonywania środowiska uruchomieniowego dla tego zapytania. Aby wyświetlić definicję fact_sales tabeli i definicji partycji, zobacz "Przykład" w tym artykule.

Atrybut partycjonowany
Gdy operator taki jak "Index Seek" jest wykonywany na partycjonowanej tabeli lub indeksie, atrybut Partitioned pojawia się w planie czasu kompilacji i wykonania, i jest ustawiony na wartość True (1). Atrybut nie jest wyświetlany, gdy jest ustawiony na False wartość (0).
Atrybut Partitioned może pojawić się w następujących operatorach fizycznych i logicznych:
- Skanowanie tabeli
- Skanowanie indeksu
- Wyszukiwanie indeksu
- Wstawiać
- Aktualizacja
- Usuń
- Połącz
Jak pokazano na poprzedniej ilustracji, ten atrybut jest wyświetlany we właściwościach operatora, w którym jest zdefiniowany. W danych wyjściowych programu Showplan XML ten atrybut jest wyświetlany jako Partitioned="1" w RelOp węźle operatora, w którym jest zdefiniowany.
Nowy predykat wyszukiwania
W danych wyjściowych programu Showplan XML, element SeekPredicateNew jest wyświetlany w operatorze, w którym jest zdefiniowany. Może zawierać maksymalnie dwa wystąpienia podelementu SeekKeys . Pierwszy SeekKeys element określa operację wyszukiwania pierwszego poziomu na poziomie identyfikatora partycji indeksu logicznego. Oznacza to, że funkcja wyszukiwania określa partycje, do których należy uzyskać dostęp, aby spełnić warunki zapytania. Drugi SeekKeys element określa część wyszukiwania drugiego poziomu operacji pomijania skanowania, która występuje w każdej partycji zidentyfikowanej w wyszukiwaniu pierwszego poziomu.
Podsumowanie partycji
W planach wykonawczych podczas działania, informacje podsumowujące dotyczące partycji zawierają liczbę partycji, do których uzyskano dostęp, oraz identyfikację rzeczywistych partycji, do których uzyskano dostęp. Te informacje umożliwiają sprawdzenie, czy dostęp do poprawnych partycji jest uzyskiwany w zapytaniu i czy wszystkie inne partycje zostały wyeliminowane z uwagi.
Podano następujące informacje: Actual Partition Count, i Partitions Accessed.
Actual Partition Count jest całkowitą liczbą partycji, do których uzyskuje dostęp zapytanie.
Partitions Accessed, w wynikach programu Showplan XML jest informacją podsumowującą partycje, wyświetlaną w nowym elemencie RuntimePartitionSummary w węźle RelOp operatora, gdzie jest zdefiniowana. W poniższym przykładzie pokazano zawartość RuntimePartitionSummary elementu wskazującą, że są dostępne dwie łączne partycje (partycje 2 i 3).
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
Wyświetlanie informacji o partycji przy użyciu innych metod programu Showplan
Metody Showplan SHOWPLAN_ALL, SHOWPLAN_TEXT i STATISTICS PROFILE nie zgłaszają informacji o partycjonowaniu opisanej w tym artykule, z następującym wyjątkiem. W ramach predykatu SEEK, partycje, do których należy uzyskać dostęp, są identyfikowane przez predykat zakresu w obliczonej kolumnie reprezentującej identyfikator partycji. Poniższy przykład pokazuje SEEK predykat dla Clustered Index Seek operatora. Uzyskuje się dostęp do partycji 2 i 3, a operator wyszukiwania filtruje wiersze spełniające warunek date_id BETWEEN 20080802 AND 20080902.
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
Interpretowanie planów wykonywania dla partycjonowanych stert
Sterta partycjonowana jest traktowana jako indeks logiczny na identyfikatorze partycji. Eliminacja partycji na partycjonowanej stercie jest reprezentowana w planie wykonawczym jako operator z predykatem Table ScanSEEK dotyczącym identyfikatora partycji. W poniższym przykładzie przedstawiono podane informacje o programie Showplan:
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
Interpretowanie planów wykonywania dla sprzężeń współlokowanych
Kollokacja łączenia może wystąpić, gdy dwie tabele są partycjonowane przy użyciu tej samej lub równoważnej funkcji partycjonowania, a kolumny partycjonowania z obu stron łączenia są określone w warunku łączenia zapytania. Optymalizator zapytań może wygenerować plan, w którym partycje każdej tabeli z równymi identyfikatorami partycji są łączone oddzielnie. Połączone sprzężenia mogą być szybsze niż sprzężenia niezwiązane, ponieważ mogą wymagać mniej pamięci i czasu przetwarzania. Optymalizator zapytań wybiera plan nieskorelowany lub skorelowany na podstawie szacunków kosztów.
W zaplanowanym planie Nested Loops sprzężenie odczytuje co najmniej jedną sprzężonej tabeli lub partycji indeksu po stronie wewnętrznej. Liczby w operatorach Constant Scan reprezentują numery partycji.
Gdy generowane są plany równoległe dla pokrywających się sprzężeń partycjonowanych tabel lub indeksów, operator Równoległości pojawia się między operatorami sprzężeń Constant Scan i Nested Loops. W tym przypadku wiele wątków roboczych po zewnętrznej stronie sprzężenia odczytuje i pracuje na różnych partycjach.
Na poniższej ilustracji przedstawiono równoległy plan zapytania dla sprzężenia posuwanego.
Strategia równoległego wykonywania zapytań dla partycjonowanych obiektów
Procesor zapytań używa strategii wykonywania równoległego dla zapytań wybranych z partycjonowanych obiektów. W ramach strategii wykonywania procesor zapytań określa partycje tabeli wymagane dla zapytania oraz proporcje wątków procesów roboczych do przydzielenia do każdej partycji. W większości przypadków procesor zapytań przydziela równą lub prawie równą liczbę wątków roboczych do każdej partycji, a następnie wykonuje zapytanie równolegle w partycjach. W poniższych akapitach wyjaśniono bardziej szczegółowo alokację wątków roboczych.
Jeśli liczba wątków roboczych jest mniejsza niż liczba partycji, procesor zapytań przypisuje każdy wątek procesu roboczego do innej partycji, początkowo pozostawiając co najmniej jedną partycję bez przypisanego wątku roboczego. Gdy wątek procesu roboczego zakończy wykonywanie na partycji, procesor zapytań przypisuje go do następnej partycji, dopóki każda partycja nie zostanie przypisana do pojedynczego wątku roboczego. Jest to jedyny przypadek, w którym procesor zapytań przenosi wątki robocze do innych partycji.
Pokazuje wątek procesu roboczego ponownie przydzielony po zakończeniu. Jeśli liczba wątków roboczych jest równa liczbie partycji, procesor zapytań przypisuje jeden wątek procesu roboczego do każdej partycji. Po zakończeniu wątku roboczego nie zostanie on ponownie przeniesiony do innej partycji.

Jeśli liczba wątków roboczych jest większa niż liczba partycji, procesor zapytań przydziela taką samą liczbę wątków roboczych do każdej partycji. Jeśli liczba wątków procesu roboczego nie jest dokładną wielokrotną liczbą partycji, procesor zapytań przydziela jeden dodatkowy wątek procesu roboczego do niektórych partycji w celu użycia wszystkich dostępnych wątków procesu roboczego. Jeśli istnieje tylko jedna partycja, wszystkie wątki procesu roboczego zostaną przypisane do tej partycji. Na przedstawionym poniżej diagramie znajdują się cztery partycje oraz 14 wątków roboczych. Każda partycja ma przypisane 3 wątki robocze, a dwie partycje mają dodatkowy wątek roboczy dla łącznie 14 przypisań wątków roboczych. Wątek roboczy, po zakończeniu pracy, nie jest ponownie przypisywany do innej partycji.

Mimo że powyższe przykłady sugerują prosty sposób przydzielania wątków roboczych, rzeczywista strategia jest bardziej złożona i uwzględnia inne zmienne występujące podczas wykonywania zapytania. Jeśli na przykład tabela jest podzielona na partycje i ma indeks klastrowany w kolumnie A, a zapytanie ma klauzulę WHERE A IN (13, 17, 25)predykatu, procesor zapytań przydzieli jeden lub więcej wątków roboczych do każdego z tych trzech wartości wyszukiwania (A=13, A=17 i A=25) zamiast każdej partycji tabeli. Konieczne jest wykonanie zapytania tylko w partycjach, które zawierają te wartości, a jeśli wszystkie te predykaty wyszukiwania znajdują się w tej samej partycji tabeli, wtedy wszystkie wątki robocze zostaną przypisane do tej samej partycji tabeli.
Aby podjąć inny przykład, załóżmy, że tabela ma cztery partycje w kolumnie A z punktami granic (10, 20, 30), indeksem w kolumnie B, a zapytanie ma klauzulę WHERE B IN (50, 100, 150)predykatu . Ponieważ partycje tabeli są oparte na wartościach A, wartości B mogą występować w dowolnej partycji tabeli. W związku z tym procesor zapytań będzie szukać dla każdej z trzech wartości B (50, 100, 150) w każdej z czterech partycji tabeli. Procesor zapytań przypisze wątki robocze proporcjonalnie, aby umożliwić równoległe wykonywanie każdego z tych 12 skanowań zapytań.
| Partycje tabeli na podstawie kolumny A | Szuka kolumny B w każdej partycji tabeli |
|---|---|
| Partycja tabeli 1: A < 10 | B=50, B=100, B=150 |
| Partycja tabeli 2: A >= 10 I < 20 | B=50, B=100, B=150 |
| Partycja tabeli 3: A >= 20 ORAZ A < 30 | B=50, B=100, B=150 |
| Tabela partycji 4: A >= 30 | B=50, B=100, B=150 |
Najlepsze rozwiązania
Aby zwiększyć wydajność zapytań, które uzyskują dostęp do dużej ilości danych z dużych partycjonowanych tabel i indeksów, zalecamy następujące najlepsze rozwiązania:
- Rozebraj każdą partycję na wiele dysków. Jest to szczególnie istotne w przypadku korzystania z dysków wirujących.
- Jeśli to możliwe, użyj serwera z wystarczającą ilością pamięci głównej, aby zmieścić często używane partycje lub wszystkie partycje w pamięci, aby zmniejszyć koszt operacji we/wy.
- Jeśli zapytania dotyczące danych nie mieszczą się w pamięci, skompresuj tabele i indeksy. Spowoduje to zmniejszenie kosztów operacji we/wy.
- Użyj serwera z szybkimi procesorami i dowolną liczbą rdzeni procesora, na które można sobie pozwolić, aby skorzystać z możliwości przetwarzania zapytań równoległych.
- Upewnij się, że serwer ma wystarczającą przepustowość kontrolera we/wy.
- Utwórz indeks klastrowany w każdej dużej tabeli podzielonej na partycje, aby skorzystać z optymalizacji skanowania drzewa B.
- Postępuj zgodnie z zaleceniami dotyczącymi najlepszych rozwiązań w białej księdze , Przewodnik po wydajności ładowania danych podczas zbiorczego ładowania danych do tabel partycjonowanych.
Przykład
Poniższy przykład tworzy testową bazę danych zawierającą jedną tabelę z siedmioma partycjami. Użyj narzędzi opisanych wcześniej podczas wykonywania zapytań w tym przykładzie, aby wyświetlić informacje o partycjonowaniu dla planów czasu kompilacji i czasu wykonywania.
Uwaga / Notatka
Ten przykład wstawia do tabeli ponad 1 milion wierszy. Uruchomienie tego przykładu może potrwać kilka minut w zależności od sprzętu. Przed wykonaniem tego przykładu sprawdź, czy masz więcej niż 1,5 GB dostępnego miejsca na dysku.
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
Treści powiązane
- Odwołanie do operatora logicznego i fizycznego planu wykonania
- Omówienie zdarzeń rozszerzonych
- Najlepsze rozwiązania dotyczące monitorowania obciążeń za pomocą magazynu zapytań
- Estymacja kardynalności (SQL Server)
- inteligentne przetwarzanie zapytań w bazach danych SQL
- Pierwszeństwo operatora (Transact-SQL)
- Omówienie planu wykonania
- Performance Center dla aparatu bazy danych SQL Server i usługi Azure SQL Database