Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Wyszukiwanie pełnotekstowe w programie SQL Server i usłudze Azure SQL Database umożliwia użytkownikom i aplikacjom uruchamianie zapytań pełnotekstowych względem danych opartych na znakach w tabelach programu SQL Server.
Istotne zmiany w programie SQL Server 2025
SQL Server 2025 (17.x) wprowadza niezgodne zmiany w wyszukiwaniu pełnotekstowym.
Aby uzyskać więcej informacji, zobacz:
- Istotne zmiany w funkcjach aparatu bazy danych w programie SQL Server 2025
- Uaktualnianie wersji indeksu pełnotekstowego
Podstawowe zadania
Ten artykuł zawiera omówienie Full-Text Search oraz opis składników i architektury. Jeśli wolisz zacząć od razu, oto podstawowe zadania.
- Rozpocznij pracę z usługą Full-Text Search
- Create and Manage Full-Text Catalogs (Tworzenie katalogów pełnotekstowych i zarządzanie nimi)
- Tworzenie indeksów pełnotekstowych i zarządzanie nimi
- Wypełnianie indeksów Full-Text
- Zapytanie z Full-Text Wyszukaj
Full-Text Search jest opcjonalnym składnikiem silnika bazy danych SQL Server. Jeśli podczas instalacji programu SQL Server nie wybierzesz funkcji Wyszukiwanie pełnotekstowe, możesz dodać ją później, ponownie uruchamiając Instalator.
Przegląd
Indeks pełnotekstowy zawiera co najmniej jedną kolumnę opartą na znakach w tabeli. Te kolumny mogą mieć dowolne z następujących typów danych: char, varchar, nchar, nvarchar, text, ntext, image, xml lub varbinary(max) i FILESTREAM. Każdy indeks indeksu pełnotekstowego indeksuje co najmniej jedną kolumnę z tabeli, a każda kolumna może używać określonego języka.
Zapytania pełnotekstowe wykonują wyszukiwania językowe względem danych tekstowych w indeksach pełnotekstowych, wykonując operacje na słowach i frazach na podstawie reguł określonego języka, takich jak angielski lub japoński. Zapytania pełne tekstu mogą zawierać podstawowe słowa i zwroty lub wiele form słowa lub frazy. Zapytanie pełnotekstowe zwraca wszystkie dokumenty zawierające co najmniej jedno dopasowanie (nazywane również trafieniem). Dopasowanie występuje, gdy dokument docelowy zawiera wszystkie terminy określone w kwerendzie pełnotekstowej i spełnia wszelkie inne warunki wyszukiwania, takie jak odległość między pasującymi terminami.
Zapytania wyszukiwania pełnotekstowego
Po dodaniu kolumn do indeksu pełnotekstowego użytkownicy i aplikacje mogą uruchamiać zapytania pełnotekstowe dotyczące tekstu w kolumnach. Te zapytania mogą wyszukiwać dowolne z następujących warunków:
- Co najmniej jeden konkretny wyraz lub frazy (prosty termin)
- Wyraz lub fraza, w której wyrazy zaczynają się od określonego tekstu (termin prefiksu)
- Formy odmiany określonego słowa (termin pokoleniowy)
- Wyraz lub fraza zbliżona do innego wyrazu lub frazy (termin zbliżeniowy)
- Synonimowe formy określonego słowa (tezaurusa)
- Wyrazy lub frazy używające wartości ważonych (termin ważony)
Zapytania pełnotekstowe nie są wrażliwe na wielkość liter. Na przykład wyszukiwanie Aluminum lub aluminum zwraca te same wyniki.
Zapytania pełnotekstowe używają małego zestawu predykatów (Transact-SQL, CONTAINS i FREETEXT) oraz funkcji (CONTAINSTABLE i FREETEXTTABLE). Jednak cele wyszukiwania danego scenariusza biznesowego wpływają na strukturę zapytań pełnotekstowych. Przykład:
Aby wyszukać produkt w witrynie internetowej handlu elektronicznego:
SELECT product_id FROM products WHERE CONTAINS ((product_description), '"Snap Happy 100EZ" OR FORMSOF(THESAURUS,"Snap Happy") OR "100EZ"') AND product_cost < 200;Aby znaleźć kandydatów do pracy, którzy mają doświadczenie w pracy z SQL Server:
SELECT candidate_name, SSN FROM candidates WHERE CONTAINS ((candidate_resume), '"SQL Server"') AND candidate_division = 'DBA';
Aby uzyskać więcej informacji, zobacz Query with Full-Text Search (Wykonywanie zapytań przy użyciu funkcji wyszukiwania Full-Text).
Porównanie zapytań wyszukiwania Full-Text z predykatem LIKE
W przeciwieństwie do wyszukiwania pełnotekstowego predykat LIKE Transact-SQL działa tylko na wzorcach znaków. Ponadto nie można użyć LIKE predykatu do wykonywania zapytań o sformatowane dane binarne. Ponadto LIKE zapytanie względem dużej ilości danych tekstowych bez struktury jest znacznie wolniejsze niż równoważne zapytanie pełnotekstowe względem tych samych danych. Zapytanie LIKE wykonywane na milionach wierszy danych tekstowych może zwrócić wyniki dopiero po kilku minutach. Natomiast pełne zapytanie tekstowe może trwać tylko kilka sekund lub mniej dla tych samych danych, w zależności od liczby zwróconych wierszy.
architektura wyszukiwania Full-Text
Architektura wyszukiwania pełnotekstowego składa się z następujących procesów:
Proces programu SQL Server (
sqlservr.exe).Proces hosta demona filtru (
fdhost.exe).Ze względów bezpieczeństwa filtry i mechanizmy podziału wyrazów są ładowane przez osobny proces o nazwie host demona filtrów. Proces
fdhost.exejest tworzony przez usługę launchera FDHOST (MSSQLFDLauncher). Działa na podstawie danych uwierzytelniających konta FDHOST launcher service. W związku z tym usługa uruchamiania FDHOST musi być uruchomiona, aby indeksowanie pełnotekstowe i wykonywanie zapytań pełnotekstowych działało. Aby uzyskać informacje o konfigurowaniu konta usługi dla tej usługi, zobacz Ustaw konto usługi dla programu uruchamiającego demona filtru pełnotekstowego.
Te dwa procesy zawierają składniki architektury wyszukiwania pełnotekstowego. Poniższa ilustracja zawiera podsumowanie tych składników i ich relacji. Składniki są opisane po ilustracji.
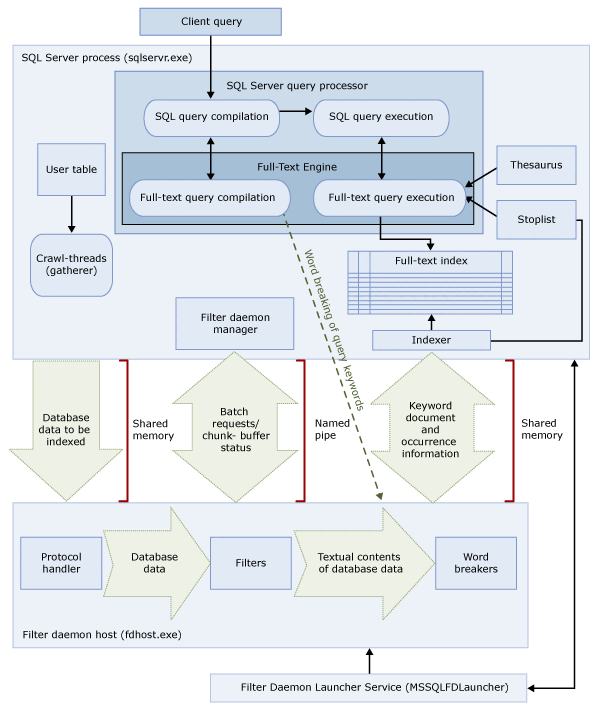
Proces programu SQL Server
Proces Database Engine wykorzystuje następujące komponenty do wyszukiwania pełnego tekstu:
| Składnik | Opis |
|---|---|
| Tabele użytkowników | Te tabele zawierają dane, które mają być indeksowane pełnotekstowo. |
| Zbieracz pełnotekstowy | Agregator pełnotekstu współpracuje z wątkami przeszukiwania pełnotekstu. Jest on odpowiedzialny za planowanie i kierowanie populacji indeksów pełnotekstowych, a także do monitorowania wykazów pełnotekstowych. |
| Pliki tezaurusa | Te pliki zawierają synonimy terminów wyszukiwania. Aby uzyskać więcej informacji, zobacz Configure and Manage Thesaurus Files for Full-Text Search (Konfigurowanie plików thesaurus i zarządzanie nimi na potrzeby wyszukiwania Full-Text). |
| Obiekty listy zatrzymań | Obiekty listy zatrzymań zawierają listę typowych słów, które nie są przydatne w wyszukiwaniu. Aby uzyskać więcej informacji, zobacz Konfigurowanie wyrazów ignorowanych i list wyrazów ignorowanych na potrzeby wyszukiwania pełnotekstowego oraz zarządzanie nimi. |
| Database Engine query processor | Procesor zapytań kompiluje i wykonuje zapytania SQL. Jeśli zapytanie SQL zawiera zapytanie wyszukiwania pełnotekstowego, zapytanie jest wysyłane do aparatu Full-Text, zarówno podczas kompilacji, jak i podczas wykonywania. Wynik zapytania jest zgodny z indeksem pełnotekstowym. |
| SilnikFull-Text | Silnik Full-Text w Database Engine jest w pełni zintegrowany z procesorem zapytań. Aparat Full-Text kompiluje i wykonuje zapytania pełnotekstowe. W ramach wykonywania zapytania silnik Full-Text może odbierać dane wejściowe z tezaurusa i listy stop. |
| Twórca indeksu (indeksator) | Pisarz indeksów buduje strukturę służącą do przechowywania indeksowanych tokenów. |
| Menedżer usługi filtru | Menedżer demona filtru jest odpowiedzialny za monitorowanie stanu hosta demona filtru Full-Text Engine. |
Proces hosta demona filtru
Host demona filtra to proces uruchamiany przez silnik Full-Text. Uruchamia następujące składniki wyszukiwania pełnotekstowego, które są odpowiedzialne za uzyskiwanie dostępu, filtrowanie i dzielenie wyrazów z tabel, a także za dzielenie wyrazów i tworzenie form podstawowych (stemowanie) dla danych wejściowych zapytania.
Składniki hosta demona filtru są następujące:
| Składnik | Opis |
|---|---|
| Obsługiwacz protokołu | Ten składnik pobiera dane z pamięci w celu dalszego przetwarzania i uzyskiwania dostępu do danych z tabeli użytkownika w określonej bazie danych. Jednym z jego zadań jest zbieranie danych z kolumn objętych indeksowaniem pełnotekstowym i przekazywanie ich do hosta demona filtru, który w razie potrzeby stosuje filtrowanie i dzielenie tekstu na wyrazy. |
| Filtry | Niektóre typy danych wymagają filtrowania, zanim dane w dokumencie mogą zostać zindeksowane w pełnym tekście. Te typy danych obejmują dane w kolumnach typu varbinary(max), image lub xml. Filtr używany dla danego dokumentu zależy od typu dokumentu. Na przykład różne filtry są używane dla dokumentów programu Microsoft Word (.doc), dokumentów programu Microsoft Excel (.xls) i dokumentów XML (.xml). Filtr wyodrębnia fragmenty tekstu z dokumentu, usuwa osadzone formatowanie oraz zachowuje tekst oraz potencjalnie informacje o położeniu tekstu. Wynik jest strumieniem informacji tekstowych. Więcej informacji można znaleźć w artykule Konfiguruj i zarządzaj filtrami. |
| Podziałki wyrazów i stemmery | Segmentator wyrazów jest komponentem specyficznym dla języka, który znajduje granice wyrazów na podstawie reguł leksykalnych danego języka (segmentacji wyrazów). Każdy analizator wyrazów jest skojarzony ze składnikiem specyficznym dla języka, który odmienia czasowniki i wykonuje rozszerzenia fleksyjne. Podczas indeksowania host demona filtrującego używa analizatora wyrazów i stemmera w celu przeprowadzenia analizy językowej danych tekstowych z danej kolumny tabeli. Język skojarzony z kolumną tabeli w indeksie pełnotekstowym określa, który segmentator i stemmer są używane do indeksowania kolumny. Aby uzyskać więcej informacji, zobacz Konfigurowanie separatorów wyrazów i stemmerów oraz zarządzanie nimi. |
Program SQL Server 2012 (11.x) instaluje nową wersję analizatorów składniowych i stemmerów dla języka angielskiego (amerykańskiego) (LCID 1033) i języka angielskiego (brytyjskiego) (LCID 2057). Można jednak przełączyć się na poprzednią wersję tych składników, jeśli chcesz zachować poprzednie zachowanie. Aby uzyskać więcej informacji, zobacz Zmienianie podziału wyrazów używanego dla języka angielskiego (Stany Zjednoczone) i języka angielskiego (Wielka Brytania).
Przetwarzanie wyszukiwania pełnotekstowego
Wyszukiwanie pełnotekstowe jest obsługiwane przez silnik Full-Text. Silnik Full-Text ma dwie role: obsługę indeksowania i obsługę zapytań.
Proces indeksowania pełnotekstowego
Gdy inicjujesz pełnotekstową populację (znaną również jako crawl), Full-Text Engine przesyła duże partie danych do pamięci i powiadamia hosta filtrującego demona. Host filtruje i dzieli dane na słowa, a następnie przekształca je w odwrócone listy słów. Następnie indeksator pobiera przekonwertowane dane z list słów, przetwarza je, aby usunąć stopwordy, i utrwala listy słów dla partii w jednym lub więcej odwróconych indeksach.
Podczas indeksowania danych przechowywanych w kolumnie xml, varbinary(max) lub obrazie, filtr, który implementuje interfejs, IFilter wyodrębnia tekst na podstawie określonego formatu pliku dla tych danych (na przykład Microsoft Word). W niektórych przypadkach komponenty filtrujące wymagają, aby dane binarne były zapisywane do folderu FTData\FilterData , zamiast być bezpośrednio przesyłane strumieniowo przez pamięć.
W ramach przetwarzania zebrane dane tekstowe są przekazywane przez moduł dzielenia wyrazów, aby oddzielić tekst do poszczególnych tokenów lub słów kluczowych. Język używany do tokenizacji jest określony na poziomie kolumny lub można go zidentyfikować w obrębie varbinary(max), image lub xml danych według składnika filtru.
Dodatkowe przetwarzanie może być wykonywane w celu usunięcia słów stopowych i normalizacji tokenów przed ich zapisem w pełnym fragmencie indeksu.
Po zakończeniu populacji zostanie wyzwolony końcowy proces scalania, który scala fragmenty indeksu ze sobą w jeden główny indeks pełnotekstowy. Ten proces powoduje zwiększenie wydajności zapytań, ponieważ tylko indeks główny musi być odpytywane, a nie kilka fragmentów indeksu, a lepsze statystyki oceniania mogą być używane do klasyfikowania istotności.
Proces wykonywania zapytań pełnotekstowych
Procesor zapytań przekazuje pełnotekstowe fragmenty zapytania do silnika Full-Text do przetwarzania. Silnik Full-Text wykonuje dzielenie wyrazów oraz, opcjonalnie, rozszerzenia tezaurusa, stemming i słowa stop. Następnie części pełnotekstowe zapytania są reprezentowane w postaci operatorów SQL, głównie jako funkcje wartości tabel przesyłanych strumieniowo (STVFs). Podczas wykonywania zapytania te STVFs mają dostęp do odwróconego indeksu, aby uzyskać poprawne wyniki. Wyniki są zwracane do klienta w tym momencie lub są one dalej przetwarzane przed zwróceniem do klienta.
Architektura indeksu pełnotekstowego
Informacje w indeksach pełnotekstowych są używane przez silnik Full-Text do kompilowania zapytań pełnotekstowych, które mogą szybko wyszukiwać w tabeli określone słowa lub kombinacje słów. Indeks pełnotekstowy przechowuje informacje o znaczących słowach i ich lokalizacji w co najmniej jednej kolumnie tabeli bazy danych. Indeks pełnotekstowy to specjalny typ indeksu funkcjonalnego opartego na tokenach, który jest tworzony i obsługiwany przez silnik Full-Text dla programu SQL Server. Proces tworzenia indeksu pełnotekstowego różni się od tworzenia innych typów indeksów. Zamiast konstruować strukturę drzewa B na podstawie wartości przechowywanej w określonym wierszu, aparat Full-Text tworzy odwróconą, skumulowaną, skompresowaną strukturę indeksu na podstawie poszczególnych tokenów z indeksowanego tekstu. Rozmiar indeksu pełnotekstowego jest ograniczony tylko przez dostępne zasoby pamięci komputera, na którym działa wystąpienie programu SQL Server.
Począwszy od programu SQL Server 2008 (10.0.x), indeksy pełnotekstowe są zintegrowane z aparatem bazy danych, a nie znajdujące się w systemie plików, jak w poprzednich wersjach programu SQL Server. W przypadku nowej bazy danych katalog pełnotekstowy jest teraz obiektem wirtualnym, który nie należy do żadnej grupy plików. To jedynie logiczna koncepcja odnosząca się do grupy indeksów pełnego tekstu. Należy jednak zauważyć, że podczas aktualizacji bazy danych SQL Server 2005 (9.x), dla każdego katalogu pełnego tekstu zawierającego pliki danych tworzona jest nowa grupa plików. Aby uzyskać więcej informacji, zobacz Upgrade Full-Text Search.
Każda tabela może zawierać tylko jeden pełny indeks tekstowy. Aby utworzyć indeks pełnego tekstu w tabeli, tabela musi mieć jedną, unikalną kolumnę nie-null. Możesz zbudować indeks pełnego tekstu na kolumnach typu char, varchar, nchar, nvarchar, text, ntext, image, xml oraz varbinary(max). Gdy tworzysz indeks pełnotekstowy na kolumnie, której typ danych to varbinary(max),obraz lub xml, musisz określić kolumnę typu.
Kolumna typu to kolumna tabeli, w której przechowujesz rozszerzenie pliku (.doc, .pdf, .xlsi tak dalej) dokumentu w każdym wierszu.
Struktura indeksu pełnotekstowego
Dobre zrozumienie struktury indeksu pełnotekstowego pomaga zrozumieć, jak działa silnik Full-Text. W tym artykule użyto następującego fragmentu tabeli Document w AdventureWorks2025 jako tabeli przykładowej. Ten fragment przedstawia tylko dwie kolumny, kolumnę DocumentID i kolumnę Title oraz trzy wiersze z tabeli.
W tym przykładzie załóżmy, że na kolumnie Title utworzono indeks pełnego tekstu.
| Identyfikator dokumentu | Nazwa |
|---|---|
1 |
Crank Arm and Tire Maintenance |
2 |
Front Reflector Bracket and Reflector Assembly 3 |
3 |
Front Reflector Bracket Installation |
Na przykład poniższa tabela, która pokazuje fragment 1, przedstawia zawartość indeksu pełnotekstowego utworzonego na kolumnie Title tabeli Document. Indeksy pełnotekstowe zawierają więcej informacji niż przedstawiono w tej tabeli. Tabela jest logiczną reprezentacją indeksu pełnotekstowego i jest dostarczana tylko do celów demonstracyjnych. Wiersze są przechowywane w formacie skompresowanym, aby zoptymalizować wykorzystanie przestrzeni dyskowej.
Dane są odwrócone w stosunku do oryginalnych dokumentów. Odwrócenie występuje, ponieważ słowa kluczowe są przyporządkowywane do identyfikatorów dokumentów. Z tego powodu indeks pełnotekstowy jest często nazywany indeksem odwróconym.
Zwróć również uwagę, że słowo kluczowe and jest usuwane z indeksu pełnotekstowego, ponieważ and jest to wartość stopword. Usunięcie stopwords z indeksu pełnotekstowego może prowadzić do znacznych oszczędności na dysku, co zwiększa wydajność zapytań. Aby uzyskać więcej informacji o słowach pomijanych, zobacz artykuł Konfigurowanie słów pomijanych i list słów pomijanych na potrzeby wyszukiwania pełnotekstowego.
Fragment 1
| Słowo kluczowe | Identyfikator kolumny | Identyfikator dokumentu | Zdarzenie |
|---|---|---|---|
Crank |
1 | 1 | 1 |
Arm |
1 | 1 | 2 |
Tire |
1 | 1 | 4 |
Maintenance |
1 | 1 | 5 |
Front |
1 | 2 | 1 |
Front |
1 | 3 | 1 |
Reflector |
1 | 2 | 2 |
Reflector |
1 | 2 | 5 |
Reflector |
1 | 3 | 2 |
Bracket |
1 | 2 | 3 |
Bracket |
1 | 3 | 3 |
Assembly |
1 | 2 | 6 |
3 |
1 | 2 | 7 |
Installation |
1 | 3 | 4 |
Kolumna Keyword zawiera reprezentację pojedynczego tokenu wyodrębnionego w czasie indeksowania. Podziały wyrazów określają, co składa się na token.
Kolumna ColId zawiera wartość odpowiadającą określonej kolumnie indeksowanej pełnotekstowo.
Kolumna DocId zawiera wartości dla 8-bajtowej liczby całkowitej, odpowiadającej określonej wartości klucza w tabeli z indeksowaniem pełnotekstowym. To mapowanie jest konieczne, gdy klucz pełnotekstowy nie jest typem danych całkowitych. W takich przypadkach mapowania między wartościami klucza pełnotekstowego oraz wartościami DocId są utrzymywane w oddzielnej tabeli, która jest nazywana tabelą DocId Mapping. Aby wykonać zapytanie dotyczące tych mapowań, użyj systemowej procedury składowanej sp_fulltext_keymappings. Aby spełnić warunek wyszukiwania, DocId należy połączyć wartości z poprzedniej tabeli z tabelą DocId mapowania w celu pobrania wierszy z tabeli bazowej, do których jest wykonywane zapytanie. Jeśli wartość klucza pełnotekstowego tabeli bazowej jest typu całkowitego, wartość bezpośrednio służy jako DocId i nie jest wymagane mapowanie. W związku z tym użycie wartości klucza pełnotekstowego całkowitego może pomóc w optymalizacji zapytań pełnotekstowych.
Kolumna Occurrence zawiera wartość całkowitą. Dla każdej wartości DocId istnieje lista wartości pozycji wystąpień, które odpowiadają względnym pozycjom słów danego słowa kluczowego w obrębie danego DocId. Wartości wystąpień są przydatne podczas określania dopasowań fraz lub zbliżeń, na przykład frazy mają wartości wystąpień sąsiadujących liczbowo. Są też przydatne do obliczania wskaźników trafności. Na przykład liczba wystąpień słowa kluczowego w a DocId może być wykorzystywana w ocenie.
Fragmenty indeksu pełnotekstowego
Logiczny indeks pełnotekstowy jest zwykle podzielony na wiele tabel wewnętrznych. Każda tabela wewnętrzna jest nazywana fragmentem indeksu pełnotekstowego. Niektóre z tych fragmentów mogą zawierać nowsze dane niż inne. Na przykład, jeśli użytkownik zaktualizuje kolejny wiersz, którego DocId wartość wynosi 3, a tabela jest automatycznie śledzona zmianami, tworzy się nowy fragment.
| Identyfikator dokumentu | Nazwa |
|---|---|
3 |
Rear Reflector |
W poniższym przykładzie, w którym pokazano Fragment 2, fragment zawiera nowsze dane dotyczące DocId 3 niż Fragment 1. Dlatego gdy użytkownik zadaje zapytanie o Rear Reflector, dane z fragmentu 2 są używane dla DocId 3. Każdy fragment jest oznaczony znacznikiem czasu tworzenia, który można odczytać przy użyciu widoku katalogu sys.fulltext_index_fragments.
Fragment 2
| Słowo kluczowe | Identyfikator kolumny | Identyfikator dokumentu | Occ |
|---|---|---|---|
Rear |
1 | 3 | 1 |
Reflector |
1 | 3 | 2 |
Jak widać na podstawie fragmentu 2, zapytania pełnotekstowe muszą wykonywać zapytania dotyczące każdego fragmentu wewnętrznie i odrzucać starsze wpisy. W związku z tym zbyt wiele fragmentów indeksu pełnotekstowego w indeksie pełnotekstowym może prowadzić do znacznego obniżenia wydajności zapytań. Aby zmniejszyć liczbę fragmentów, zreorganizuj katalog pełnotekstowy za pomocą opcji REORGANIZE instrukcji ALTER FULLTEXT CATALOG języka Transact-SQL. To polecenie wykonuje scalanie główne, które scala fragmenty w jeden większy fragment i usuwa wszystkie przestarzałe wpisy z indeksu pełnotekstowego.
Po reorganizacji przykładowy indeks będzie zawierać następujące wiersze:
| Słowo kluczowe | Identyfikator kolumny | Identyfikator dokumentu | Occ |
|---|---|---|---|
Crank |
1 | 1 | 1 |
Arm |
1 | 1 | 2 |
Tire |
1 | 1 | 4 |
Maintenance |
1 | 1 | 5 |
Front |
1 | 2 | 1 |
Rear |
1 | 3 | 1 |
Reflector |
1 | 2 | 2 |
Reflector |
1 | 2 | 5 |
Reflector |
1 | 3 | 2 |
Bracket |
1 | 2 | 3 |
Assembly |
1 | 2 | 6 |
3 |
1 | 2 | 7 |
Różnice między indeksami pełnotekstowymi a zwykłymi indeksami programu SQL Server
| Indeksy pełnotekstowe | Regularne indeksy programu SQL Server |
|---|---|
| W tabeli dozwolony jest tylko jeden indeks pełnotekstowy. | Dla każdej tabeli może być kilka regularnych indeksów dozwolonych. |
| Dodanie danych do indeksów pełnotekstowych, nazywanych populacją, może być wymagane za pośrednictwem harmonogramu lub określonego żądania albo może wystąpić automatycznie z dodatkami nowych danych. | Zaktualizowano automatycznie, gdy dane, na których są oparte, są wstawiane, aktualizowane lub usuwane. |
| Pogrupowane w tej samej bazie danych w co najmniej jeden wykaz pełnotekstowy. | Nie pogrupowane. |
Full-Text Wyszukiwanie komponentów językowych i wsparcia językowego
Wyszukiwanie w pełnym tekstie obsługuje ponad 50 różnych języków, takich jak angielski, hiszpański, chiński, japoński, arabski, bengalski i hindi. Aby uzyskać pełną listę obsługiwanych języków pełnotekstowych, zobacz sys.fulltext_languages. Każda z kolumn zawartych w indeksie pełnym tekstem jest powiązana z identyfikatorem Microsoft Windows locale (LCID), który odpowiada językowi obsługiwanemu przez wyszukiwanie pełne tekstu. Na przykład LCID 1033 odpowiada amerykańskiemu angielskiemu, a LCID 2057 brytyjskiemu. Dla każdego obsługiwanego języka pełnotekstowego Database Engine dostarcza komponenty językowe wspierające indeksowanie i zapytania do pełnotekstowych danych przechowywanych w tym języku.
Składniki specyficzne dla języka obejmują następujące elementy:
| Składnik | Opis |
|---|---|
| Podziałki wyrazów i stemmery | Element dzielący wyrazy znajduje granice wyrazów na podstawie reguł leksykalnych danego języka (łamanie wyrazów). Każdy podział wyrazów jest skojarzony z stemmerem, który konjugatuje czasowniki dla tego samego języka. Więcej informacji można znaleźć w artykule Konfiguruj i zarządzaj łamaczami słów i stemmerami. |
| Listy zatrzymań | Dostępna jest lista stopów systemowych, która zawiera podstawowy zestaw wyrazów stopowych (nazywanych również słowami szumowymi).
Stopword to słowo, które nie ułatwia wyszukiwania i jest ignorowane przez zapytania pełnotekstowe. Na przykład dla angielskich słów regionalnych, takich jak a, and, isi the są traktowane jako stopwords. Zazwyczaj należy skonfigurować co najmniej jeden plik tezaurusa i listy zatrzymań. Aby uzyskać więcej informacji, zobacz Konfigurowanie wyrazów ignorowanych i list wyrazów ignorowanych na potrzeby wyszukiwania pełnotekstowego oraz zarządzanie nimi. |
| Pliki tezaurusa | Database Engine instaluje także plik tezaurusa dla każdego pełnotekstowego języka oraz globalny plik tezaurus. Zainstalowane pliki tezaurusa są puste, ale można je edytować, aby zdefiniować synonimy dla określonego języka lub scenariusza biznesowego. Opracowując tezaurusa dostosowane do danych pełnotekstowych, można skutecznie rozszerzyć zakres pełnotekstowych zapytań dotyczących tych danych. Aby uzyskać więcej informacji, zobacz Configure and Manage Thesaurus Files for Full-Text Search (Konfigurowanie plików thesaurus i zarządzanie nimi na potrzeby wyszukiwania Full-Text). |
| Filtry (IFilters) | Indeksowanie dokumentu w kolumnie varbinary(max), image lub xml data type wymaga filtru do wykonania dodatkowego przetwarzania. Filtr musi być specyficzny dla typu dokumentu (.doc, .pdf, .xls, .xmlitd.). Więcej informacji można znaleźć w artykule Konfiguruj i zarządzaj filtrami. |
Treści powiązane
- Rozpocznij pracę z usługą Full-Text Search
- Create and Manage Full-Text Catalogs (Tworzenie katalogów pełnotekstowych i zarządzanie nimi)
- Tworzenie indeksów pełnotekstowych i zarządzanie nimi
- Wypełnianie indeksów Full-Text
- Zapytanie z Full-Text Wyszukaj