Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Baza danych SQL w usłudze Microsoft Fabric
Baza danych SQL w usłudze Microsoft Fabric
Projektowanie wydajnych indeksów jest kluczem do osiągnięcia dobrej wydajności bazy danych i aplikacji. Brak indeksów, nadmierne indeksowanie lub źle zaprojektowane indeksy są głównymi źródłami problemów z wydajnością bazy danych.
W tym przewodniku opisano architekturę i podstawy indeksu oraz przedstawiono najlepsze rozwiązania ułatwiające projektowanie efektywnych indeksów spełniających potrzeby aplikacji.
Aby uzyskać więcej informacji na temat dostępnych typów indeksów, zobacz Indeksy.
W tym przewodniku omówiono następujące typy indeksów:
| Podstawowy format przechowywania | Typ indeksu |
|---|---|
| Magazyn wierszy oparty na dysku | |
| Clustered | |
| Nonclustered | |
| Unique | |
| Filtered | |
| Columnstore | |
| Klastrowany magazyn kolumn | |
| Nieklastrowany magazyn kolumnowy | |
| Memory-optimized | |
| Hash | |
| Zoptymalizowane pod kątem pamięci nieklastrowane |
Aby uzyskać informacje o indeksach XML, zobacz Indeksy XML (SQL Server) i Selektywne indeksy XML (SXI).
Aby uzyskać informacje o indeksach przestrzennych, zobacz Omówienie indeksów przestrzennych.
Aby uzyskać informacje o indeksach pełnotekstowych, zobacz Wypełnianie indeksów Full-Text.
Podstawy indeksu
Pomyśl o regularnej książce: na końcu książki znajduje się indeks, który pomaga szybko zlokalizować informacje w książce. Indeks jest posortowaną listą słów kluczowych, a obok każdego słowa kluczowego jest zestaw numerów stron wskazujących strony, na których można znaleźć każde słowo kluczowe.
Indeks rekordu jest podobny: to uporządkowana lista wartości, a dla każdej wartości istnieją wskaźniki do stron danych, gdzie te wartości są umieszczone. Sam indeks jest również przechowywany na stronach nazywanych stronami indeksu. W regularnej książce, jeśli indeks obejmuje wiele stron i musisz znaleźć wskaźniki do wszystkich stron, które zawierają słowo SQL na przykład, musisz przejść od początku indeksu do momentu zlokalizowania strony indeksu zawierającej słowo kluczowe SQL. Stamtąd podążasz za wskazówkami do wszystkich stron książki. Można to dodatkowo zoptymalizować, jeśli na samym początku indeksu utworzysz jedną stronę zawierającą alfabetyczną listę miejsc, w których można znaleźć każdą literę. Na przykład: "Od A do D - strona 121", "Od E do G - strona 122" itd. Ta dodatkowa strona wyeliminowałaby etap przeglądania indeksu w celu znalezienia miejsca rozpoczęcia. Taka strona nie istnieje w zwykłych książkach, ale istnieje w indeksie rowstore. Ta pojedyncza strona jest nazywana stroną główną indeksu. Strona główna to strona początkowa struktury drzewa używanej przez indeks. Podążając za analogią drzewa, strony końcowe zawierające wskaźniki do rzeczywistych danych są określane jako "strony liściowe" drzewa.
Indeks jest strukturą na dysku lub w pamięci skojarzona z tabelą lub widokiem, która przyspiesza pobieranie wierszy z tabeli lub widoku. Indeks magazynu wierszy zawiera klucze utworzone na podstawie wartości w co najmniej jednej kolumnie w tabeli lub widoku. W przypadku indeksów wierszowych te klucze są przechowywane w strukturze drzewa (drzewo B+), która umożliwia Silnikowi bazy danych szybkie i wydajne znajdowanie wierszy skojarzonych z wartościami kluczy.
Indeks rowstore przechowuje dane logicznie zorganizowane jako tabelę z wierszami i kolumnami, a fizycznie przechowywane w formacie danych wierszy o nazwie rowstore1. Istnieje alternatywny sposób przechowywania kolumn danych o nazwie magazyn kolumn.
Projekt odpowiednich indeksów dla bazy danych i jej obciążenia to złożony akt równoważenia między szybkością zapytań, kosztem aktualizacji indeksu i kosztem magazynu. Wąskie indeksy magazynu wierszy oparte na dysku lub indeksy z kilkoma kolumnami w kluczu indeksu wymagają mniejszej ilości miejsca do magazynowania i mniejszego obciążenia aktualizacji. Z drugiej strony szerokie indeksy mogą poprawić więcej zapytań. Może być konieczne eksperymentowanie z kilkoma różnymi projektami przed znalezieniem najbardziej wydajnego zestawu indeksów. W miarę rozwoju aplikacji indeksy mogą wymagać zmiany w celu zachowania optymalnej wydajności. Indeksy można dodawać, modyfikować i usuwać bez wpływu na schemat bazy danych lub projekt aplikacji. W związku z tym nie należy wahać się eksperymentować z różnymi indeksami.
Optymalizator zapytań w aparacie silnika bazy danych zwykle wybiera najbardziej efektywne indeksy do wykonania zapytania. Aby sprawdzić, które indeksy są używane przez optymalizator zapytań dla określonego zapytania, w programie SQL Server Management Studio w menu Zapytanie wybierz pozycję Wyświetl szacowany plan wykonania lub Uwzględnij rzeczywisty plan wykonania.
Nie zawsze utożsamiaj użycie indeksu z dobrą wydajnością i dobrą wydajnością przy wydajnym użyciu indeksu. Jeśli użycie indeksu zawsze pomogło uzyskać najlepszą wydajność, zadanie optymalizatora zapytań byłoby proste. W rzeczywistości nieprawidłowy wybór indeksu może spowodować mniej niż optymalną wydajność. W związku z tym zadaniem optymalizatora zapytań jest wybranie indeksu lub kombinacji indeksów, tylko wtedy, gdy poprawia wydajność i aby uniknąć indeksowanego pobierania, gdy utrudnia wydajność.
Typowym błędem projektowym jest utworzenie wielu indeksów spekulacyjnych w celu "nadania optymalizatorowi wyborów". Wynikowe przeindeksowanie spowalnia modyfikacje danych i może powodować problemy ze współbieżnością.
1 Przechowywanie wierszowe to tradycyjny sposób przechowywania danych relacyjnej tabeli. Rowstore odnosi się do tabeli, w której bazowy format magazynu danych to tablica stertowa, drzewo B+ (indeks klastrowany) lub tabela zoptymalizowana dla pamięci. Rejestr wierszy bazujący na dysku wyklucza tabele zoptymalizowane pod kątem pamięci.
Zadania projektowania indeksu
Następujące zadania składają się na naszą zalecaną strategię projektowania indeksów:
Poznaj cechy bazy danych i aplikacji.
Na przykład w bazie danych przetwarzania transakcji online (OLTP) z częstymi modyfikacjami danych, które muszą zapewniać wysoką przepustowość, kilka wąskich indeksów typu rowstore przeznaczonych dla najbardziej krytycznych zapytań stanowiłoby dobrą początkową konstrukcję indeksu. W przypadku bardzo wysokiej przepływności rozważ tabele i indeksy zoptymalizowane pod kątem pamięci, które zapewniają konstrukcję bez blokady i zatrzaśnięć. Aby uzyskać więcej informacji, zobacz Wytyczne dotyczące projektowania indeksu nieklastrowanego zoptymalizowane pod kątem pamięci i wskazówki dotyczące projektowania indeksu skrótów w tym przewodniku.
Z drugiej strony w przypadku bazy danych analizy lub magazynowania danych (OLAP), która musi przetwarzać bardzo duże zestawy danych szybko, użycie klastrowanych indeksów magazynu kolumn byłoby szczególnie odpowiednie. Aby uzyskać więcej informacji, zobacz Indeksy magazynu kolumn: omówienie lub Architektura indeksu magazynu kolumn w tym przewodniku.
Poznaj cechy najczęściej używanych zapytań.
Na przykład wiedząc, że często używane zapytanie łączy co najmniej dwie tabele, pomaga określić zestaw indeksów dla tych tabel.
Omówienie dystrybucji danych w kolumnach używanych w predykatach zapytania.
Na przykład indeks może być przydatny w przypadku kolumn z wieloma unikatowymi wartościami danych, ale mniej w przypadku kolumn z wieloma zduplikowanymi wartościami. W przypadku kolumn z wieloma listami NUL lub tymi, które mają dobrze zdefiniowane podzestawy danych, można użyć filtrowanego indeksu. Aby uzyskać więcej informacji, zobacz Wytyczne dotyczące projektowania filtrowanego indeksu w tym przewodniku.
Określ, które opcje indeksu mogą zwiększyć wydajność.
Na przykład utworzenie indeksu klastrowanego w istniejącej dużej tabeli może skorzystać z opcji indeksu
ONLINE. OpcjaONLINEumożliwia równoczesne działanie danych bazowych w czasie tworzenia lub odbudowy indeksu. Użycie kompresji danych wierszowej lub stronicowej może zwiększyć wydajność, zmniejszając obciążenie operacji we/wy i pamięci indeksu. Aby uzyskać więcej informacji, zobacz CREATE INDEX.Sprawdź istniejące indeksy w tabeli, aby zapobiec tworzeniu zduplikowanych lub bardzo podobnych indeksów.
Często lepiej zmodyfikować istniejący indeks niż utworzyć nowy, ale głównie zduplikowany indeks. Rozważ na przykład dodanie jednej lub dwóch dodatkowych dołączonych kolumn do istniejącego indeksu zamiast tworzenia nowego indeksu z tymi kolumnami. Jest to szczególnie istotne w przypadku dostrajania indeksów nieklastrowanych przy użyciu sugestii dotyczących brakujących indeksów lub w przypadku korzystania z Doradcy Optymalizacji Silnika Baz Danych, w którym mogą być proponowane podobne warianty indeksów na tych samych tabelach i kolumnach.
Ogólne wytyczne dotyczące projektowania indeksów
Zrozumienie cech bazy danych, zapytań i kolumn tabeli może pomóc w początkowym zaprojektowaniu optymalnych indeksów i zmodyfikowaniu projektu w miarę rozwoju aplikacji.
Zagadnienia dotyczące bazy danych
Podczas projektowania indeksu należy wziąć pod uwagę następujące wytyczne dotyczące bazy danych:
Duża liczba indeksów w tabeli wpływa na wydajność instrukcji
INSERT,UPDATE,DELETEiMERGE, ponieważ dane w indeksach mogą się zmieniać wraz ze zmianą danych w tabeli. Jeśli na przykład kolumna jest używana w kilku indeksach i wykonujesz instrukcję modyfikującąUPDATEdane tej kolumny, każdy indeks zawierający kolumnę musi zostać również zaktualizowany.Unikaj nadmiernego indeksowania mocno zaktualizowanych tabel i zachowaj wąskie indeksy, czyli z jak najmniejszą liczbą kolumn.
Możesz mieć więcej indeksów w tabelach, które mają kilka modyfikacji danych, ale duże ilości danych. W przypadku takich tabel różne indeksy mogą pomóc w wydajności zapytań, podczas gdy obciążenie aktualizacji indeksu pozostaje akceptowalne. Nie twórz jednak indeksów spekulacyjnie. Monitoruj użycie indeksów i usuwaj nieużywane indeksy w czasie.
Indeksowanie małych tabel może nie być optymalne, ponieważ mechanizm bazy danych może potrzebować więcej czasu na przeszukanie indeksu niż na wykonanie pełnego skanowania tabeli podstawowej. W związku z tym indeksy w małych tabelach nigdy nie mogą być używane, ale muszą być nadal aktualizowane w miarę aktualizowania danych w tabeli.
Indeksy w widokach mogą zapewnić znaczne wzrosty wydajności, gdy widok zawiera agregacje i/lub sprzężenia. Aby uzyskać więcej informacji, zobacz Tworzenie indeksowanych widoków.
Bazy danych na replikach podstawowych w usłudze Azure SQL Database automatycznie generują zalecenia dotyczące wydajności doradcy bazy danych dla indeksów. Opcjonalnie możesz włączyć automatyczne dostrajanie indeksów.
Magazyn zapytań pomaga identyfikować zapytania o nieoptymalną wydajność i zapewnia historię planów wykonywania zapytań , które umożliwiają wyświetlanie indeksów wybranych przez optymalizator. Za pomocą tych danych można wprowadzać zmiany dostrajania indeksu najbardziej wpływające, koncentrując się na najczęściej używanych zapytaniach i zużywaniu zasobów.
Uwagi dotyczące zapytań
Podczas projektowania indeksu należy wziąć pod uwagę następujące wytyczne dotyczące zapytań:
Utwórz indeksy nieklastrowane na kolumnach, które są często używane w predykatach i wyrażeniach złączeń w zapytaniach. Są to kolumny SARGable . Należy jednak unikać dodawania niepotrzebnej kolumny do indeksów. Dodanie zbyt wielu kolumn indeksu może negatywnie wpłynąć na wydajność miejsca na dysku i aktualizacji indeksu.
Termin SARGable w relacyjnych bazach danych oznacza predykat Search ARGumentable, który może wykorzystywać indeks do przyspieszenia wykonywania zapytania. Aby uzyskać więcej informacji, zobacz Sql Server i Azure SQL index architecture and design guide (Architektura i projektowanie indeksów usługi Azure SQL).
Tip
Zawsze upewnij się, że utworzone indeksy są rzeczywiście używane przez obciążenie zapytania. Upuść nieużywane indeksy.
Statystyki użycia indeksu są dostępne w sys.dm_db_index_usage_stats i sys.dm_db_index_operational_stats.
Pokrycie indeksów może zwiększyć wydajność zapytań, ponieważ wszystkie dane potrzebne do spełnienia wymagań zapytania istnieją w samym indeksie. Oznacza to, że tylko strony indeksu, a nie strony danych tabeli lub indeksu klastrowanego, są wymagane do pobrania żądanych danych; w związku z tym zmniejszenie ogólnej liczby operacji we/wy dysku. Na przykład zapytanie o kolumny
AiBw tabeli zawierającej indeks złożony utworzony w kolumnachA,BiCmoże pobrać określone dane z samego indeksu.Note
Indeks obejmujący jest indeksem nieklastrowanym , który spełnia cały dostęp do danych bezpośrednio przez zapytanie bez uzyskiwania dostępu do tabeli podstawowej.
Takie indeksy mają wszystkie niezbędne kolumny SARGable w kluczu indeksu i kolumny inne niż SARGable jako dołączone kolumny. Oznacza to, że wszystkie kolumny wymagane przez zapytanie, zarówno w klauzulach
WHERE,JOIN, iGROUP BY, jak i w klauzulachSELECTlubUPDATE, znajdują się w indeksie.Potencjalnie znacznie zmniejsza się liczba operacji I/O potrzebnych do wykonania zapytania, jeśli indeks jest wystarczająco wąski w porównaniu do wszystkich kolumn w tabeli, co oznacza, że obejmuje niewielki podzbiór tych kolumn.
Rozważ stosowanie indeksów podczas pobierania małej części dużej tabeli, gdzie ta mała część jest definiowana przez ustalony warunek.
Unikaj tworzenia indeksu pokrywającego zbyt wielu kolumn, ponieważ zmniejsza to jego korzyści, zwiększając obciążenie magazynu bazy danych, operacji we/wy oraz zużycie pamięci.
Napisz zapytania, które wstawią lub modyfikują jak najwięcej wierszy w jednej instrukcji, zamiast używać wielu zapytań do aktualizowania tych samych wierszy. Zmniejsza to obciążenie związane z aktualizacją indeksu.
Zagadnienia dotyczące kolumn
Podczas projektowania indeksu należy wziąć pod uwagę następujące wytyczne dotyczące kolumn:
Zachowaj krótki czas trwania klucza indeksu, szczególnie w przypadku indeksów klastrowanych.
Kolumny, które są typu danych ntext, text, image, varchar(max), nvarchar(max), varbinary(max), json i vector nie mogą być określone jako kolumny klucza indeksu. Jednak kolumny z tymi typami danych można dodawać do indeksu nieklastrowanego jako kolumny indeksu typu "dołączone bez klucza". Aby uzyskać więcej informacji, zobacz sekcję Use included columns in nonclustered indexes (Używanie dołączonych kolumn w indeksach nieklastrowanych ) w tym przewodniku.
Sprawdź unikatowość kolumn. Unikatowy indeks zamiast indeksu niepowiązanego w tych samych kolumnach kluczy zawiera dodatkowe informacje dla optymalizatora zapytań, który sprawia, że indeks jest bardziej przydatny. Aby uzyskać więcej informacji, zobacz Unikatowe wytyczne dotyczące projektowania indeksów w tym przewodniku.
Sprawdź rozkład danych w kolumnie. Tworzenie indeksu na kolumnie z wieloma wierszami, ale z niewielką liczbą unikalnych wartości, może nie poprawić wydajności zapytań, nawet jeśli indeks jest używany przez optymalizator zapytań. Jako analogia, fizyczny katalog telefoniczny posortowany alfabetycznie na imię rodziny nie przyspiesza lokalizowania osoby, jeśli wszystkie osoby w mieście są nazwane Smith lub Jones. Aby uzyskać więcej informacji na temat dystrybucji danych, zobacz Statystyki.
Rozważ użycie filtrowanych indeksów w kolumnach, które mają dobrze zdefiniowane podzestawy, na przykład kolumny z wieloma listami NUL, kolumnami z kategoriami wartości i kolumnami z odrębnymi zakresami wartości. Dobrze zaprojektowany filtrowany indeks może poprawić wydajność zapytań, zmniejszyć koszty aktualizacji indeksu i zmniejszyć koszty magazynowania, przechowując niewielki podzestaw wszystkich wierszy w tabeli, jeśli ten podzestaw jest odpowiedni dla wielu zapytań.
Rozważ kolejność kolumn klucza indeksu, jeśli klucz zawiera wiele kolumn. Kolumna używana w predykacie zapytania w równości (
=), nierówności (>,>=,<,<=) lub wyrażeniuBETWEEN, lub uczestnicząca w sprzężeniu, powinna zostać umieszczona jako pierwsza. Dodatkowe kolumny powinny być uporządkowane na podstawie ich poziomu odrębności, czyli od najbardziej odrębnych do najmniej odrębnych.Jeśli na przykład indeks jest zdefiniowany jako
LastName,FirstNameindeks jest przydatny, gdy predykat zapytania w klauzuliWHEREtoWHERE LastName = 'Smith'lubWHERE LastName = Smith AND FirstName LIKE 'J%'. Jednak optymalizator zapytań nie używa indeksu dla kwerendy, która wyszukiwała tylko wWHERE FirstName = 'Jane'parametrze , lub indeks nie poprawi wydajności takiego zapytania.Rozważ indeksowanie obliczonych kolumn, jeśli są one uwzględnione w predykatach zapytań. Aby uzyskać więcej informacji, zobacz Indeksy na obliczanych kolumnach.
Właściwości indeksu
Po ustaleniu, że indeks jest odpowiedni dla zapytania, możesz wybrać typ indeksu, który najlepiej pasuje do twojej sytuacji. Cechy indeksu obejmują:
- Klastrowane lub nieklastrowane
- Unikatowy lub nieunikatowy
- Pojedyncza kolumna lub kolumna wielokolumnowa
- Kolejność rosnąca lub malejąca dla kolumn kluczy w indeksie
- Wszystkie wiersze lub przefiltrowane, w przypadku indeksów nieklastrowanych
- Sklep kolumnowy lub sklep wierszowy
- Mieszanie lub indeks nieklastrowany dla tabel zoptymalizowanych pod kątem pamięci
Umieszczanie indeksów w grupach plików lub schematach partycji
Podczas opracowywania strategii projektowania indeksu należy rozważyć umieszczenie indeksów w grupach plików skojarzonych z bazą danych.
Domyślnie indeksy są przechowywane w tej samej grupie plików co tabela podstawowa (indeks klastrowany lub sterta), na której jest tworzony indeks. Możliwe są inne konfiguracje, w tym:
Utwórz indeksy nieklastrowane w grupie plików innej niż grupa plików tabeli podstawowej.
Partycjonuj klastrowane i nieklastrowane indeksy, aby obejmowały wiele grup plików.
W przypadku tabel innych niż partycjonowane najprostsze podejście jest zwykle najlepsze: utwórz wszystkie tabele w tej samej grupie plików i dodaj tyle plików danych do grupy plików, co jest niezbędne do korzystania ze wszystkich dostępnych magazynów fizycznych.
Bardziej zaawansowane podejścia do umieszczania indeksów można rozważyć, gdy magazyn warstwowy jest dostępny. Można na przykład utworzyć grupę plików dla często używanych tabel z plikami na szybszych dyskach oraz grupę plików dla tabel archiwum na wolniejszych dyskach.
Tabelę z klastrowanym indeksem można przenieść z jednej grupy plików do innej, przenosząc indeks klastrowany oraz określając nową grupę plików lub schemat partycji w klauzuli MOVE TO instrukcji DROP INDEX lub używając instrukcji CREATE INDEX z klauzulą DROP_EXISTING.
Partycjonowane indeksy
Można również rozważyć partycjonowanie stosów opartych na dyskach, indeksów klastrowanych i nieklastrowanych w różnych grupach plików. Partycjonowane indeksy są podzielone poziomo (według wierszy) na podstawie funkcji partycji. Funkcja partycji definiuje sposób mapowania każdego wiersza na partycję na podstawie wartości określonej kolumny nazywanej kolumną partycjonowania. Schemat partycji określa mapowanie zestawu partycji na grupę plików.
Partycjonowanie indeksu może zapewnić następujące korzyści:
Zwiększenie możliwości zarządzania dużymi bazami danych. Na przykład systemy OLAP mogą implementować etL z obsługą partycji, co znacznie upraszcza dodawanie i usuwanie danych zbiorczo.
Upewnij się, że niektóre typy zapytań, takie jak długotrwałe zapytania analityczne, są wykonywane szybciej. Gdy zapytania używają indeksu partycjonowanego, aparat bazy danych może przetwarzać wiele partycji jednocześnie i pomijać (wyeliminować) partycje, które nie są wymagane przez zapytanie.
Ostrzeżenie
Partycjonowanie rzadko poprawia wydajność zapytań w systemach OLTP, ale może wprowadzić znaczne obciążenie, jeśli zapytanie transakcyjne musi uzyskać dostęp do wielu partycji.
Aby uzyskać więcej informacji, zobacz Partycjonowane tabele i indeksy.
Wskazówki dotyczące projektowania kolejności sortowania indeksów
Podczas definiowania indeksów należy rozważyć, czy każda kolumna klucza indeksu powinna być przechowywana w kolejności rosnącej lub malejącej. Rosnąco jest wartością domyślną. Składnia instrukcji CREATE INDEX, CREATE TABLEi ALTER TABLE obsługuje słowa kluczowe ASC (rosnąco) i DESC (malejąco) dla poszczególnych kolumn w indeksach i ograniczeniach.
Określenie kolejności przechowywania wartości kluczy w indeksie jest przydatne, gdy zapytania odwołujące się do tabeli zawierają ORDER BY klauzule określające różne kierunki dla kolumny klucza lub kolumn w tym indeksie. W takich przypadkach indeks może usunąć potrzebę operatorasortowania w planie zapytania.
Na przykład kupujący w dziale zakupów Adventure Works Cycles muszą ocenić jakość produktów, które kupują od dostawców. Kupujący są najbardziej zainteresowani znalezieniem produktów od dostawców z wysokim wskaźnikiem odrzucenia.
Jak pokazano w poniższym zapytaniu względem przykładowej bazy danych AdventureWorks, pobieranie danych w celu spełnienia tych kryteriów wymaga RejectedQty sortowania kolumny w Purchasing.PurchaseOrderDetail tabeli w kolejności malejącej (od dużej do małej) i ProductID sortowania kolumny w kolejności rosnącej (od małej do dużej).
SELECT RejectedQty,
((RejectedQty / OrderQty) * 100) AS RejectionRate,
ProductID,
DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
Poniższy plan wykonania dla tego zapytania pokazuje, że optymalizator zapytań użył operatora sortowania , aby zwrócić zestaw wyników w kolejności określonej przez klauzulę ORDER BY .

Jeśli indeks magazynu wierszy na dysku jest tworzony z kolumnami kluczy, które pasują do tych w klauzuli ORDER BY zapytania, to w planie zapytania operator Sort zostaje wyeliminowany, co sprawia, że plan zapytania jest bardziej wydajny.
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
Po ponownym wykonaniu zapytania poniższy plan wykonywania pokazuje, że operator sortowania nie jest już obecny, a nowo utworzony indeks nieklastrowany jest używany.
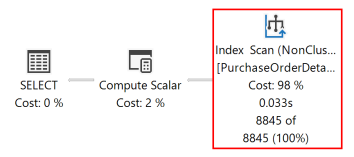
Aparat bazy danych może skanować indeks w obu kierunkach. Indeks zdefiniowany jako RejectedQty DESC, ProductID ASC nadal może być używany dla zapytania, w którym kierunku sortowania kolumn w ORDER BY klauzuli są odwracane. Na przykład zapytanie z klauzulą ORDER BYORDER BY RejectedQty ASC, ProductID DESC może używać tego samego indeksu.
Kolejność sortowania można określić tylko dla kolumn kluczy w indeksie. Widok wykazu sys.index_columns raportuje, czy kolumna indeksu jest przechowywana w kolejności rosnącej lub malejącej.
Wytyczne dotyczące projektowania indeksu klastrowanego
Indeks klastrowany przechowuje wszystkie wiersze i wszystkie kolumny tabeli. Wiersze są sortowane w kolejności wartości klucza indeksu. W każdej tabeli może istnieć tylko jeden indeks klastrowany.
Termin tabela bazowa może odnosić się do indeksu klastrowanego lub stosu. Sterta to niesortowana struktura danych na dysku zawierająca wszystkie wiersze i wszystkie kolumny tabeli.
Z kilkoma wyjątkami każda tabela powinna mieć indeks klastrowany. Pożądane właściwości indeksu klastrowanego to:
| Majątek | Description |
|---|---|
| Wąski | Klucz indeksu klastrowanego jest częścią dowolnego indeksu nieklastrowanego w tej samej tabeli podstawowej. Wąski klucz lub klucz, w którym łączna długość kolumn kluczy jest mała, zmniejsza obciążenie magazynowania, operacji wejścia/wyjścia i pamięci dla wszystkich indeksów w tabeli. Aby obliczyć długość klucza, dodaj rozmiary pamięci dla typów danych używanych przez kolumny klucza. Aby uzyskać więcej informacji, zobacz Kategorie typów danych. |
| Niepowtarzalny | Jeśli indeks klastrowany nie jest unikatowy, 4-bajtowa wewnętrzna kolumna unikatowości zostanie automatycznie dodana do klucza indeksu w celu zapewnienia unikatowości. Dodanie istniejącej unikatowej kolumny do klastrowanego klucza indeksu pozwala uniknąć obciążenia przestrzeni magazynowej, operacji we/wy oraz pamięci związanych z kolumną unikatowości we wszystkich indeksach w tabeli. Ponadto optymalizator zapytań może generować bardziej wydajne plany zapytań, gdy indeks jest unikatowy. |
| Stale rosnące | W stale rosnącym indeksie dane są zawsze dodawane na ostatniej stronie indeksu. Pozwala to uniknąć podziałów stron w środku indeksu, co zmniejsza gęstość stron i zmniejsza wydajność. |
| Niezmienialny | Klucz indeksu klastrowanego jest częścią dowolnego indeksu nieklastrowanego. Po zmodyfikowaniu kolumny klucza indeksu klastrowanego należy również wprowadzić zmianę we wszystkich indeksach nieklastrowanych, co powoduje narzut na obciążenie CPU, rejestrowanie, operacje I/O i pamięć. Obciążenie jest unikane, jeśli kluczowe kolumny indeksu klastrowanego są niezmienne. |
| Ma tylko kolumny niedopuszczające wartości null | Jeśli wiersz zawiera kolumny, w których wartość może być null, musi zawierać wewnętrzną strukturę o nazwie Blok NULL, który dodaje 3–4 bajty przechowywania na wiersz w indeksie. Ustawienie, że wszystkie kolumny indeksu klastrowanego nie są dopuszczane do wartości null, pozwala uniknąć tego obciążenia. |
| Ma tylko kolumny o stałej szerokości | Kolumny korzystające z typów danych o zmiennej szerokości, takich jak varchar lub nvarchar , używają dodatkowych 2 bajtów na wartość w porównaniu z typami danych o stałej szerokości. Użycie typów danych o stałej szerokości, takich jak int, pozwala uniknąć tego obciążenia we wszystkich indeksach w tabeli. |
Spełnienie jak największej liczby tych właściwości podczas projektowania indeksu klastrowanego sprawia, że zarówno on sam, jak i wszystkie indeksy nieklastrowane w tej samej tabeli stają się bardziej wydajne. Wydajność jest zwiększana dzięki unikaniu obciążeń związanych z przechowywaniem, operacjami wejścia/wyjścia oraz pamięcią.
Na przykład klucz indeksu klastrowanego z pojedynczą kolumną int lub bigint nienulowalną ma wszystkie te właściwości, jeśli jest wypełniany klauzulą IDENTITY lub domyślnego ograniczenia z użyciem sekwencji i nie jest aktualizowany po wstawieniu wiersza.
Z drugiej strony, klasterowany klucz indeksu z jedną kolumną z typem uniqueidentifier jest szerszy, ponieważ używa 16 bajtów pamięci zamiast 4 bajtów dla int i 8 bajtów dla bigint, i nie spełnia właściwości zwiększającej się w sposób ciągły, chyba że wartości są generowane sekwencyjnie.
Tip
Podczas tworzenia PRIMARY KEY ograniczenia tworzony jest unikatowy indeks obsługujący ograniczenie automatycznie. Domyślnie ten indeks jest klasterowany; Jeśli jednak ten indeks nie spełnia żądanych właściwości indeksu klastrowanego, możesz utworzyć ograniczenie jako nieklastrowane i utworzyć inny indeks klastrowany.
Jeśli nie utworzysz indeksu klastrowanego, tabela jest przechowywana jako sterta, która zwykle nie jest zalecana.
Architektura indeksu klastrowanego
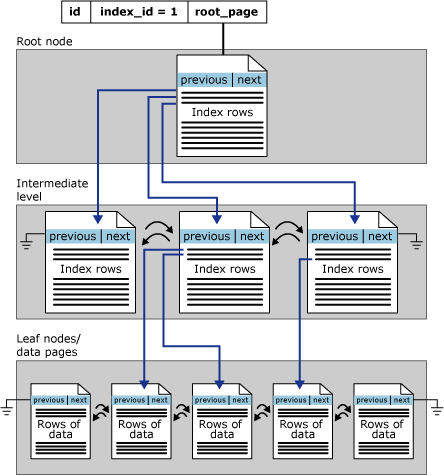
Indeksy Rowstore są zorganizowane jako drzewa B+. Każda strona w drzewie indeksu B+ jest nazywana węzłem indeksu. Górny węzeł drzewa B+ jest nazywany węzłem głównym. Węzły dolne w indeksie są nazywane węzłami liścia. Wszystkie poziomy indeksu między węzłami głównymi i węzłami liścia są wspólnie znane jako poziomy pośrednie. W indeksie klastrowanym węzły liścia zawierają strony danych tabeli bazowej. Węzły na poziomie głównym i pośrednim zawierają strony indeksu zawierające wiersze indeksu. Każdy wiersz indeksu zawiera wartość klucza i wskaźnik do strony poziomu pośredniego w drzewie B+ lub wiersza danych na poziomie liścia indeksu. Strony na każdym poziomie indeksu są połączone na podwójnie połączonej liście.
Indeksy klastrowane mają jeden wiersz w pliku sys.partitions dla każdej partycji używanej przez indeks z elementem index_id = 1. Domyślnie indeks klastrowany ma jedną partycję. Gdy indeks klastrowany ma wiele partycji, każda partycja ma oddzielną strukturę drzewa B+ zawierającą dane dla tej konkretnej partycji. Jeśli na przykład indeks klastrowany ma cztery partycje, istnieją cztery struktury drzewa B+, po jednym w każdej partycji.
W zależności od typów danych w indeksie klastrowanym każda struktura indeksu klastrowanego ma co najmniej jedną jednostki alokacji, w których mają być przechowywane dane dla określonej partycji i zarządzać nimi. Co najmniej każdy indeks klastrowany ma jedną IN_ROW_DATA jednostkę alokacji na partycję. Indeks klastrowany zawiera również jedną LOB_DATA jednostkę alokacji na partycję, jeśli zawiera kolumny dużego obiektu (LOB), takie jak nvarchar(max). Ma również jedną ROW_OVERFLOW_DATA jednostkę alokacji na partycję, jeśli zawiera kolumny o zmiennej długości, które przekraczają limit rozmiaru wiersza 8060 bajtów.
Strony w strukturze drzewa B+ są uporządkowane na wartości klucza indeksu klastrowanego. Wszystkie wstawki są wykonywane na stronie, na której wartość klucza w wstawionym wierszu mieści się w kolejności między istniejącymi stronami. Na stronie wiersze nie muszą być przechowywane w żadnej kolejności fizycznej. Jednak strona utrzymuje logiczne porządkowanie wierszy przy użyciu wewnętrznej struktury nazywanej tablicą gniazd. Wpisy w tablicy slotów są utrzymywane w kolejności klucza indeksu.
Na tej ilustracji przedstawiono strukturę indeksu klastrowanego w pojedynczej partycji.
Nieklastrowane wytyczne dotyczące projektowania indeksów
Główną różnicą między klastrowanym i nieklastrowanym indeksem jest to, że indeks nieklastrowany zawiera podzbiór kolumn w tabeli, zwykle sortowany inaczej niż indeks klastrowany. Opcjonalnie indeks nieklastrowany można filtrować, co oznacza, że zawiera podzbiór wszystkich wierszy w tabeli.
Indeks nieklastrowany magazynu wierszy oparty na dysku zawiera lokalizatory wierszy wskazujące lokalizację magazynu wiersza w tabeli bazowej. Można utworzyć wiele indeksów nieklastrowanych w tabeli lub w widoku indeksowanym. Ogólnie rzecz biorąc, indeksy nieklastrowane powinny być zaprojektowane tak, aby zwiększyć wydajność często używanych zapytań, które musiałyby przeskanować tabelę podstawową w przeciwnym razie.
Podobnie jak w przypadku użycia indeksu w książce, optymalizator zapytań wyszukuje wartość danych, wyszukując nieklastrowany indeks, aby znaleźć lokalizację wartości danych w tabeli, a następnie pobiera dane bezpośrednio z tej lokalizacji. Dzięki temu indeksy nieklastrowane są optymalnym wyborem dla dokładnie dopasowanych zapytań, ponieważ indeks zawiera wpisy opisujące dokładną lokalizację w tabeli wartości danych wyszukiwanych w zapytaniach.
Na przykład, aby wysłać zapytanie do tabeli HumanResources.Employee dla wszystkich pracowników, którzy zgłaszają się do określonego menedżera, optymalizator zapytań może używać indeksu nieklastrowanego IX_Employee_ManagerID; co ma ManagerID jako pierwszą kolumnę klucza.
ManagerID Ponieważ wartości są uporządkowane w indeksie nieklastrowanym, optymalizator zapytań może szybko znaleźć wszystkie wpisy w indeksie, które są zgodne z określoną ManagerID wartością. Każdy wpis indeksu wskazuje dokładną stronę i wiersz w tabeli podstawowej, w której można pobrać odpowiednie dane ze wszystkich innych kolumn. Gdy optymalizator zapytań znajdzie wszystkie wpisy w indeksie, może przejść bezpośrednio do dokładnej strony i wiersza, aby pobrać dane zamiast skanować całą tabelę bazową.
Architektura indeksu nieklastrowanego
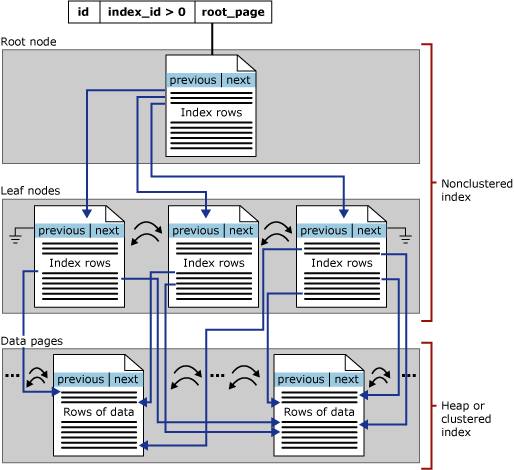
Indeksy nieklastrowane magazynu wierszy opartego na dysku mają taką samą strukturę drzewa B+ jak indeksy klastrowane, z wyjątkiem następujących różnic:
Indeks nieklastrowany nie musi zawierać wszystkich kolumn i wierszy tabeli.
Poziom liści indeksu nieklastrowanego składa się ze stron indeksu zamiast stron danych. Strony indeksu na poziomie liścia indeksu nieklastrowanego zawierają kolumny kluczy. Opcjonalnie mogą również zawierać podzbiór innych kolumn w tabeli jako dołączone kolumny, aby uniknąć pobierania ich z tabeli bazowej.
Lokalizatory wierszy w nieklastrowanych wierszach indeksu są wskaźnikiem do wiersza lub są kluczem indeksu klastrowanego dla wiersza opisanego w następujący sposób:
Jeśli tabela ma indeks klastrowany lub indeks znajduje się w widoku indeksowanym, lokalizator wierszy jest kluczem indeksu klastrowanego dla wiersza.
Jeśli tabela jest stertą, co oznacza, że nie ma indeksu klastrowanego, lokalizator wierszy jest wskaźnikiem do wiersza. Wskaźnik jest kompilowany na podstawie identyfikatora pliku (ID), numeru strony i numeru wiersza na stronie. Cały wskaźnik jest nazywany identyfikatorem wiersza (RID).
Lokalizatory wierszy zapewniają również unikatowość dla nieklastrowanych wierszy indeksu. W poniższej tabeli opisano, jak aparat bazy danych dodaje lokalizatory wierszy do indeksów nieklastrowanych:
| Typ tabeli podstawowej | Typ indeksu nieklastrowanego | Lokalizator wiersza |
|---|---|---|
| Heap | ||
| Nonunique | Identyfikator RID dodany do kluczowych kolumn | |
| Unique | RID dodany do dołączonych kolumn | |
| Unikatowy indeks klastrowany | ||
| Nonunique | Klucze indeksu klastrowanego dodane do kolumn kluczowych | |
| Unique | Klucze indeksu klastrowanego dodane do dołączonych kolumn | |
| Nieunikatowy indeks klastrowany | ||
| Nonunique | Klucze indeksu klastrowanego i identyfikator unikatowości (jeśli są obecne) zostały dodane do kolumn kluczy | |
| Unique | Klucze indeksu klastrowanego i dodatkowy identyfikator unikatowy (jeśli jest obecny) dodane do dołączonych kolumn |
Aparat bazy danych nigdy nie przechowuje danej kolumny więcej niż raz w indeksie nieklastrowanym. Kolejność klucza indeksu określona przez użytkownika podczas tworzenia indeksu nieklastrowanego jest zawsze honorowana: wszystkie kolumny lokalizatora wierszy, które należy dodać do klucza indeksu nieklastrowanego, są dodawane na końcu klucza, zgodnie z kolumnami określonymi w definicji indeksu. Lokalizatory wierszy kluczy indeksu klastrowanego w indeksie nieklastrowanym mogą być używane w przetwarzaniu zapytań, niezależnie od tego, czy są jawnie określone w definicji indeksu, czy dodawane niejawnie.
W poniższych przykładach pokazano, jak lokalizatory wierszy są implementowane w indeksach nieklastrowanych:
| Indeks klastrowany | Definicja indeksu nieklastrowanego | Definicja indeksu nieklastrowanego z lokalizatorami wierszy | Explanation |
|---|---|---|---|
Unikatowy indeks klastrowany z kolumnami kluczy (A, B, C) |
Nieunikalny nieklastrowany indeks z kolumnami klucza (B, A) i kolumnami dołączonymi (E, G) |
Kolumny kluczy (B, A, C) i dołączone kolumny (E, G) |
Indeks nieklastrowany jest nieunikalny, więc lokalizator wierszy musi znajdować się w kluczach indeksu. Kolumny B i A z lokalizatora wierszy są już obecne, więc dodawana jest tylko kolumna C. Kolumna C jest dodawana na końcu listy kolumn kluczy. |
Unikatowy indeks klastrowany z kolumną klucza (A) |
Indeks nieklastrowany, nieunikalny z kolumnami kluczy (B, C) i dołączoną kolumną (A) |
Kolumny kluczy (B, C, A) |
Indeks nieklastrowany jest nieunikalny, więc lokalizator wierszy jest dodawany do klucza. Kolumna A nie jest jeszcze określona jako kolumna klucza, dlatego jest dodawana na końcu listy kolumn kluczy. Kolumna A znajduje się teraz w kluczu, więc nie ma potrzeby przechowywania jej jako dołączonej kolumny. |
Unikatowy indeks klastrowany z kolumną klucza (A, B) |
Unikatowy indeks nieklastrowany z kolumną klucza (C) |
Kolumna klucza (C) i dołączone kolumny (A, B) |
Indeks nieklastrowany jest unikatowy, więc lokalizator wierszy jest dodawany do uwzględnionych kolumn. |
Indeksy nieklastrowane mają jeden wiersz w pliku sys.partitions dla każdej partycji używanej przez indeks z elementem index_id > 1. Domyślnie indeks nieklastrowany ma jedną partycję. Gdy indeks nieklastrowany ma wiele partycji, każda partycja ma strukturę drzewa B+ zawierającą wiersze indeksu dla tej konkretnej partycji. Jeśli na przykład indeks nieklastrowany ma cztery partycje, istnieją cztery struktury drzewa B+, po jednym w każdej partycji.
W zależności od typów danych w indeksie nieklastrowanym każda nieklastrowana struktura indeksu ma co najmniej jedną jednostki alokacji, w których mają być przechowywane dane dla określonej partycji i zarządzać nimi. Co najmniej każdy indeks nieklastrowany ma jedną IN_ROW_DATA jednostkę alokacji na partycję, która przechowuje strony drzewa indeksu B+. Indeks nieklastrowany ma również jedną LOB_DATA jednostkę alokacji na partycję, jeśli zawiera kolumny dużego obiektu (LOB), takie jak nvarchar(max). Ponadto ma jedną ROW_OVERFLOW_DATA jednostkę alokacji na partycję, jeśli zawiera kolumny o zmiennej długości, które przekraczają limit rozmiaru wiersza 8060 bajtów.
Poniższa ilustracja przedstawia strukturę indeksu nieklastrowanego w jednej partycji.
Używanie uwzględnionych kolumn w indeksach nieklastrowanych
Oprócz kolumn kluczowych indeks nieklastrowany może również zawierać kolumny inne niż kluczowe przechowywane na poziomie liścia. Te kolumny niebędące kluczami są nazywane dołączonymi kolumnami i są określone w INCLUDE klauzuli instrukcji CREATE INDEX .
Indeks z dołączonymi kolumnami niekluczowymi może znacznie poprawić wydajność zapytań, gdy obejmuje zapytanie, czyli wtedy, gdy wszystkie kolumny używane w zapytaniu znajdują się w indeksie jako kolumny klucza lub nieklucza. Wzrost wydajności jest osiągany, ponieważ aparat bazy danych może zlokalizować wszystkie wartości kolumn w indeksie; tabela podstawowa nie jest dostępna, co powoduje mniej operacji we/wy dysku.
Jeśli kolumna musi zostać pobrana przez zapytanie, ale nie jest używana w predykatach zapytań, agregacjach i sortowaniu, dodaj ją jako dołączona kolumna, a nie jako kolumnę klucza. Ma to następujące zalety:
Kolumny uwzględnione mogą używać typów danych, które nie są dozwolone jako typy danych dla kolumn klucza indeksu.
Uwzględnione kolumny nie są brane pod uwagę przez aparat bazy danych podczas obliczania liczby kolumn klucza indeksu lub rozmiaru klucza indeksu. W przypadku dołączonych kolumn nie jesteś ograniczony maksymalnym rozmiarem klucza wynoszącym 900 bajtów. Możesz utworzyć szersze indeksy, które obejmują więcej zapytań.
Przeniesienie kolumny z klucza indeksu do dołączonych kolumn trwa krócej, ponieważ operacja sortowania indeksu staje się szybsza.
Jeśli tabela ma indeks klastrowany, kolumna lub kolumny zdefiniowane w kluczu indeksu klastrowanego są automatycznie dodawane do każdego indeksu nieklastrowanego w tabeli. Nie trzeba ich określać w nieklastrowanym kluczu indeksu lub jako dołączone kolumny.
Wskazówki dotyczące indeksów z dołączonymi kolumnami
Podczas projektowania indeksów nieklastrowanych z dołączonymi kolumnami należy wziąć pod uwagę następujące wskazówki:
Uwzględnione kolumny można definiować tylko w indeksach nieklastrowanych w tabelach lub widokach indeksowanych.
Wszystkie typy danych są dozwolone z wyjątkiem tekstu, ntexti obrazu.
Kolumny obliczane, które są deterministyczne i mogą być zarówno precyzyjne, jak i nieprecyzyjne, mogą być kolumnami dołączonymi. Aby uzyskać więcej informacji, zobacz Indeksy na obliczanych kolumnach.
Podobnie jak w przypadku kolumn kluczowych, obliczone kolumny pochodzące z typów danych image, ntext i text mogą być dołączonymi kolumnami, o ile typ danych obliczonej kolumny jest dozwolony w kolumnie dołączonej.
Nie można określić nazw kolumn zarówno na
INCLUDEliście, jak i na liście kolumn kluczy.Nazwy kolumn nie mogą być powtarzane na
INCLUDEliście.Co najmniej jedna kolumna klucza musi być zdefiniowana w indeksie. Maksymalna liczba dołączonych kolumn to 1023. Jest to maksymalna liczba kolumn tabeli minus 1.
Niezależnie od obecności dołączonych kolumn kolumn kolumny klucza indeksu muszą być zgodne z istniejącymi ograniczeniami rozmiaru indeksu wynoszącymi maksymalnie 16 kolumn kluczowych i łącznym rozmiarem klucza indeksu wynoszącym 900 bajtów.
Projektowanie zaleceń dotyczących indeksów z dołączonymi kolumnami
Rozważ przeprojektowanie indeksów nieklastrowanych z dużym rozmiarem klucza indeksu, aby kolumny używane tylko w predykatach zapytań, agregacjach i sortowaniu były kolumnami kluczowymi. Oznacz wszystkie inne kolumny, które obejmują zapytanie, jako kolumny inne niż kluczowe. W ten sposób masz wszystkie kolumny potrzebne do pokrycia zapytania, ale sam klucz indeksu jest mały i wydajny.
Załóżmy na przykład, że chcesz zaprojektować indeks, aby obejmował następujące zapytanie.
SELECT AddressLine1,
AddressLine2,
City,
StateProvinceID,
PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
Aby pokryć zapytanie, każda kolumna musi być zdefiniowana w indeksie. Chociaż można zdefiniować wszystkie kolumny jako kolumny klucza, rozmiar klucza będzie wynosić 334 bajty. Ponieważ jedyną kolumną używaną jako kryteria wyszukiwania jest PostalCode kolumna, która ma długość 30 bajtów, lepszym projektem indeksu będzie zdefiniowana PostalCode jako kolumna klucza i dołączenia wszystkich innych kolumn jako kolumn niekluczowych.
Poniższa instrukcja tworzy indeks z dołączonymi kolumnami w celu pokrycia zapytania.
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Aby sprawdzić, czy indeks obejmuje zapytanie, utwórz indeks, a następnie wyświetl szacowany plan wykonania. Jeśli plan wykonywania pokazuje operator wyszukiwania indeksu dla indeksu IX_Address_PostalCode , zapytanie jest objęte indeksem.
Zagadnienia dotyczące wydajności indeksów z dołączonymi kolumnami
Unikaj tworzenia indeksów z bardzo dużą liczbą dołączonych kolumn. Mimo że indeks może obejmować więcej zapytań, jego korzyść z wydajności została zmniejszona, ponieważ:
Mniej wierszy indeksu zmieści się na stronie. Zwiększa to wydajność operacji we/wy dysku i zmniejsza wydajność pamięci podręcznej.
Do przechowywania indeksu jest wymagana większa ilość miejsca na dysku. W szczególności dodanie varchar(max), nvarchar(max), varbinary(max), lub xml w kolumnach dołączonych może znacznie zwiększyć wymagania dotyczące miejsca na dysku. Dzieje się tak, ponieważ wartości kolumn są kopiowane na poziom liścia indeksu. W związku z tym znajdują się one zarówno w indeksie, jak i w tabeli podstawowej.
Wydajność modyfikacji danych zmniejsza się, ponieważ wiele kolumn musi być modyfikowanych zarówno w tabeli opartej, jak i w indeksie nieklastrowanym.
Należy określić, czy wzrost wydajności zapytań przewyższa spadek wydajności modyfikacji danych i wzrost wymagań dotyczących miejsca na dysku.
Unikatowe wytyczne dotyczące projektowania indeksu
Unikatowy indeks gwarantuje, że klucz indeksu nie zawiera zduplikowanych wartości. Tworzenie unikatowego indeksu jest możliwe tylko wtedy, gdy unikatowość jest cechą samych danych. Jeśli na przykład chcesz upewnić się, że wartości w kolumnie NationalIDNumber tabeli HumanResources.Employee są unikalne, gdy klucz podstawowy to EmployeeID, utwórz ograniczenie UNIQUE w kolumnie NationalIDNumber. Ograniczenie odrzuca wszelkie próby wprowadzenia wierszy ze zduplikowanymi numerami identyfikatorów krajowych.
W przypadku indeksów unikatowych wielokolumnowych indeks gwarantuje, że każda kombinacja wartości w kluczu indeksu jest unikatowa. Jeśli na przykład unikatowy indeks jest tworzony w kombinacji LastNamekolumn , FirstNamei MiddleName , żadne dwa wiersze w tabeli nie mogą mieć tych samych wartości dla tych kolumn.
Indeksy klastrowane i nieklastrowane mogą być unikatowe. Możesz utworzyć unikatowy indeks klastrowany i wiele unikatowych indeksów nieklastrowanych w tej samej tabeli.
Zalety unikatowych indeksów obejmują:
- Reguły biznesowe, które wymagają unikatowości danych, są wymuszane.
- Dodatkowe informacje pomocne w optymalizatorze zapytań są udostępniane.
Utworzenie ograniczenia PRIMARY KEY lub UNIQUE powoduje automatyczne utworzenie unikatowego indeksu w określonych kolumnach. Nie ma znaczących różnic między tworzeniem UNIQUE ograniczenia a tworzeniem unikatowego indeksu niezależnie od ograniczenia. Walidacja danych odbywa się w taki sam sposób, a optymalizator zapytań nie rozróżnia unikatowego indeksu utworzonego przez ograniczenie ani ręcznie utworzonego. Należy jednak utworzyć ograniczenie w kolumnie UNIQUE lub PRIMARY KEY, gdy celem jest wymuszanie reguł biznesowych. Dzięki temu cel indeksu jest jasny.
Zagadnienia dotyczące indeksu unikatowego
Nie można utworzyć unikatowego indeksu,
UNIQUEograniczenia lubPRIMARY KEYograniczenia, jeśli w danych istnieją zduplikowane wartości klucza.Jeśli dane są unikatowe i chcesz wymusić unikatowość, utworzenie unikatowego indeksu zamiast indeksu innego w tej samej kombinacji kolumn zawiera dodatkowe informacje dla optymalizatora zapytań, które mogą tworzyć bardziej wydajne plany wykonywania. W tym przypadku zaleca się utworzenie
UNIQUEograniczenia lub unikatowego indeksu.Unikatowy indeks nieklastrowany może zawierać dołączone kolumny inne niż kluczowe. Aby uzyskać więcej informacji, zobacz Use included columns in nonclustered indexes (Używanie dołączonych kolumn w indeksach nieklastrowanych).
W przeciwieństwie do ograniczenia
PRIMARY KEY, można utworzyć ograniczenieUNIQUElub unikatowy indeks z kolumną, która dopuszcza wartości null w kluczu indeksu. Do celów wymuszania unikatowości, dwa NULL są uznawane za równe. Oznacza to na przykład, że w unikatowym indeksie z jedną kolumną kolumna może mieć wartość NULL tylko dla jednego wiersza w tabeli.
Wytyczne dotyczące projektowania filtrowanego indeksu
Indeks filtrowany to zoptymalizowany indeks nieklastrowany, szczególnie odpowiedni dla zapytań wymagających małego podzbioru danych w tabeli. Używa predykatu filtru w definicji indeksu, aby indeksować część wierszy w tabeli. Dobrze zaprojektowany indeks filtrowany może poprawić wydajność zapytań, zmniejszyć koszty aktualizacji indeksu i zmniejszyć koszty magazynowania indeksów w porównaniu z indeksem pełnej tabeli.
Przefiltrowane indeksy mogą zapewnić następujące korzyści w stosunku do indeksów w pełnej tabeli:
Zwiększona wydajność zapytań i jakość planu
Dobrze zaprojektowany indeks filtrowany zwiększa wydajność zapytań i jakość planu wykonywania, ponieważ jest mniejszy niż indeks nieklastrowany w pełnej tabeli. Filtrowany indeks zawiera przefiltrowane statystyki, które są dokładniejsze niż statystyki pełnej tabeli, ponieważ obejmują tylko wiersze w filtrowanym indeksie.
Obniżone koszty aktualizacji indeksu
Indeks jest aktualizowany tylko wtedy, gdy instrukcje języka manipulowania danymi (DML) wpływają na dane w indeksie. Filtrowany indeks zmniejsza koszty aktualizacji indeksu w porównaniu z indeksem nieklastrowanym obejmującym całą tabelę, ponieważ jest mniejszy i jest aktualizowany tylko wtedy, gdy dane zawarte w indeksie są zmieniane. Istnieje możliwość posiadania dużej liczby filtrowanych indeksów, zwłaszcza gdy zawierają one dane, które są rzadko modyfikowane. Podobnie, jeśli filtrowany indeks zawiera tylko często dotknięte dane, mniejszy rozmiar indeksu zmniejsza koszt aktualizowania statystyk.
Obniżone koszty magazynowania indeksów
Utworzenie filtrowanego indeksu może zmniejszyć magazyn dysków dla indeksów nieklastrowanych, gdy indeks pełnej tabeli nie jest konieczny. Możesz zamienić nieklastrowany indeks obejmujący całą tabelę na wiele indeksów filtrowanych bez znacznego zwiększenia wymagań dotyczących przechowywania.
Indeksy filtrowane są przydatne, gdy kolumny zawierają dobrze zdefiniowane podzestawy danych. Przykłady to:
Kolumny zawierające wiele wartości NULL.
Heterogeniczne kolumny zawierające kategorie danych.
Kolumny zawierające zakresy wartości, takie jak ilości, godzina i daty.
Obniżone koszty aktualizacji dla filtrowanych indeksów są najbardziej zauważalne, gdy liczba wierszy w indeksie jest niewielka w porównaniu z indeksem pełnej tabeli. Jeśli filtrowany indeks zawiera większość wierszy w tabeli, może to kosztować więcej niż indeks pełnej tabeli. W takim przypadku należy użyć indeksu pełnej tabeli zamiast filtrowanego indeksu.
Indeksy filtrowane są definiowane w jednej tabeli i obsługują tylko proste operatory porównania. Jeśli potrzebujesz wyrażenia filtru, które ma złożoną logikę lub odwołuje się do wielu tabel, należy utworzyć indeksowaną kolumnę obliczeniową lub widok indeksowany.
Zagadnienia dotyczące projektowania filtrowanego indeksu
Aby zaprojektować efektywne indeksy filtrowane, ważne jest, aby zrozumieć, jakie zapytania są używane przez aplikację i jak odnoszą się do podzestawów danych. Niektóre przykłady danych, które mają dobrze zdefiniowane podzestawy, to kolumny zawierające wiele NULLs, kolumny z heterogenicznymi kategoriami wartości i kolumn z odrębnymi zakresami wartości.
Poniższe zagadnienia dotyczące projektowania dają kilka scenariuszy, w których filtrowany indeks może zapewnić korzyści w stosunku do indeksów w pełnej tabeli.
Przefiltrowane indeksy dla podzestawów danych
Jeśli kolumna zawiera tylko kilka odpowiednich wartości dla zapytań, można utworzyć filtrowany indeks w podzestawie wartości. Jeśli na przykład kolumna ma wartość NULL, a zapytanie wymaga tylko wartości innych niż NULL, można utworzyć filtrowany indeks zawierający wiersze inne niż NULL.
Na przykład przykładowa baza danych AdventureWorks zawiera tabelę Production.BillOfMaterials z 2679 wierszami. Kolumna EndDate zawiera tylko 199 wierszy, które zawierają wartość inną niż NULL, a pozostałe 2480 wierszy zawierają wartość NULL. Poniższy filtrowany indeks obejmuje zapytania zwracające kolumny zdefiniowane w indeksie i wymagające tylko wierszy z wartością inną niż NULL dla elementu EndDate.
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
Filtrowany indeks FIBillOfMaterialsWithEndDate jest prawidłowy dla tego zapytania.
Wyświetl szacowany plan wykonywania , aby określić, czy optymalizator zapytań użył filtrowanego indeksu.
SELECT ProductAssemblyID,
ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
Aby uzyskać więcej informacji na temat tworzenia filtrowanych indeksów i sposobu definiowania filtrowanego wyrażenia predykatu indeksu, zobacz Tworzenie filtrowanych indeksów.
Przefiltrowane indeksy dla danych heterogenicznych
Gdy tabela zawiera heterogeniczne wiersze danych, można utworzyć filtrowany indeks dla co najmniej jednej kategorii danych.
Na przykład produkty wymienione w Production.Product tabeli są przypisane do elementu ProductSubcategoryID, które są z kolei skojarzone z kategoriami produktów Rowery, Składniki, Odzież lub Akcesoria. Te kategorie są heterogeniczne, ponieważ ich wartości kolumn w Production.Product tabeli nie są ściśle skorelowane. Na przykład kolumny Color, , ReorderPointListPrice, Weight, Classi Style mają unikatowe cechy dla każdej kategorii produktów. Załóżmy, że istnieją częste zapytania dotyczące akcesoriów, które mają podkategorie z zakresu od 27 do 36 włącznie. Wydajność zapytań dotyczących akcesoriów można poprawić, tworząc filtrowany indeks podkategorii akcesoriów, jak pokazano w poniższym przykładzie.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
INCLUDE (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
Filtrowany indeks FIProductAccessories obejmuje następujące zapytanie, ponieważ wyniki zapytania są zawarte w indeksie, a plan zapytania nie wymaga dostępu do tabeli podstawowej. Na przykład wyrażenie predykatu zapytania ProductSubcategoryID = 33 jest podzbiorem predykatu filtrowanego indeksu ProductSubcategoryID >= 27 i ProductSubcategoryID <= 36, kolumny ProductSubcategoryID i ListPrice w predykacie zapytania są zarówno kolumnami kluczowymi w indeksie, a nazwa jest przechowywana na poziomie liścia indeksu jako dołączona kolumna.
SELECT Name,
ProductSubcategoryID,
ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33
AND ListPrice > 25.00;
Kluczowe i uwzględnione kolumny w filtrowanych indeksach
Najlepszym rozwiązaniem jest dodanie niewielkiej liczby kolumn w filtrowanej definicji indeksu, tylko w razie potrzeby, aby optymalizator zapytań wybrał filtrowany indeks dla planu wykonywania zapytania. Optymalizator zapytań może wybrać filtrowany indeks dla zapytania, niezależnie od tego, czy indeks ten obejmuje zapytanie, czy nie. Jednak optymalizator zapytań jest bardziej skłonny do wyboru filtrowanego indeksu, jeśli indeks obejmuje zapytanie.
W niektórych przypadkach filtrowany indeks obejmuje zapytanie bez uwzględniania kolumn w filtrowanym wyrażeniu indeksu jako klucza lub uwzględnionych kolumn w filtrowanej definicji indeksu. Poniższe wskazówki wyjaśniają, kiedy kolumna w filtrowanym wyrażeniu indeksu powinna być kluczem lub dołączona kolumna w definicji filtrowanego indeksu. Przykłady odnoszą się do filtrowanego indeksu, FIBillOfMaterialsWithEndDate który został utworzony wcześniej.
Kolumna w filtrowanym wyrażeniu indeksu nie musi być kluczem ani uwzględniona kolumną w filtrowanej definicji indeksu, jeśli filtrowane wyrażenie indeksu jest równoważne predykatowi zapytania, a zapytanie nie zwraca kolumny w filtrowanym wyrażeniu indeksu z wynikami zapytania. Na przykład obejmuje następujące zapytanie, FIBillOfMaterialsWithEndDate ponieważ predykat zapytania jest odpowiednikiem wyrażenia filtru i EndDate nie jest zwracany z wynikami zapytania. Indeks FIBillOfMaterialsWithEndDate nie musi być EndDate kluczem ani kolumną uwzględnioną w definicji filtrowanego indeksu.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Kolumna w wyrażeniu indeksu filtrowanego powinna być kluczem lub kolumną dołączoną w definicji indeksu filtrowanego, jeśli predykat zapytania używa kolumny w porównaniu, które nie jest równoważne wyrażeniu indeksu filtrowanego. Na przykład FIBillOfMaterialsWithEndDate jest prawidłowe dla następującego zapytania, ponieważ wybiera podzbiór wierszy z filtrowanego indeksu. Nie obejmuje to jednak następującego zapytania, ponieważ EndDate jest używane w porównaniu EndDate > '20040101', które nie jest równoważne filtrowanemu wyrażeniu indeksu. Procesor zapytań nie może wykonać tego zapytania bez badania wartości EndDate.
EndDate powinna stać się kluczem lub dołączoną kolumną w definicji filtrowanego indeksu.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
Kolumna w filtrowanym wyrażeniu indeksu powinna być kluczem lub dołączona kolumna w definicji filtrowanego indeksu, jeśli kolumna znajduje się w zestawie wyników zapytania. Na przykład FIBillOfMaterialsWithEndDate nie obejmuje następującego zapytania, ponieważ w wynikach zapytania zwraca kolumnę EndDate.
EndDate powinna stać się kluczem lub dołączoną kolumną w definicji filtrowanego indeksu.
SELECT ComponentID,
StartDate,
EndDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Klucz w indeksie klastrowanym tabeli nie musi być kluczem ani kolumną dołączoną do definicji indeksu filtrowanego. Klucz indeksu klastrowanego jest automatycznie uwzględniany we wszystkich indeksach nieklastrowanych, w tym indeksach filtrowanych.
Operatory konwersji danych w predykacie filtru
Jeśli operator porównania określony w filtrowanym wyrażeniu indeksu filtrowanego powoduje niejawną lub jawną konwersję danych, występuje błąd, jeśli konwersja występuje po lewej stronie operatora porównania. Rozwiązaniem jest zapisanie filtrowanego wyrażenia indeksu za pomocą operatora konwersji danych (CAST lub CONVERT) po prawej stronie operatora porównania.
Poniższy przykład tworzy tabelę z kolumnami różnych typów danych.
CREATE TABLE dbo.TestTable
(
a INT,
b VARBINARY(4)
);
W poniższej przefiltrowanej definicji indeksu kolumna b jest niejawnie konwertowana na typ danych całkowitych w celu porównania jej z stałą 1. Spowoduje to wygenerowanie komunikatu o błędzie 10611, ponieważ konwersja występuje po lewej stronie operatora w przefiltrowanej predykacie.
CREATE NONCLUSTERED INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = 1;
Rozwiązaniem jest przekonwertowanie stałej po prawej stronie na taki sam typ jak kolumna b, jak pokazano w poniższym przykładzie:
CREATE INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = CONVERT (VARBINARY(4), 1);
Przeniesienie konwersji danych z lewej strony do prawej strony operatora porównania może zmienić znaczenie konwersji. W poprzednim przykładzie, gdy CONVERT operator został dodany do prawej strony, porównanie zmieniło się z porównania typu int na porównanie typu varbinary.
Architektura kolumnowego indeksu magazynu
Indeks magazynu kolumn to technologia do przechowywania, pobierania i zarządzania danymi przy użyciu formatu danych kolumnowych nazywanego magazynem kolumn. Aby uzyskać więcej informacji, zobacz Indeksy Columnstore: omówienie.
Aby uzyskać informacje o wersji i dowiedzieć się, co nowego się pojawiło, odwiedź stronę Co nowego w indeksach kolumnowych.
Znajomość tych podstaw ułatwia zrozumienie innych artykułów dotyczących magazynowania kolumnowego, które wyjaśniają, jak efektywnie korzystać z tej technologii.
Przechowywanie danych wykorzystuje kolumnowy i wierszowy magazyn danych
Podczas omawiania indeksów magazynu kolumn używamy terminów rowstore i columnstore , aby podkreślić format magazynu danych. Indeksy Columnstore używają obu typów przechowywania.
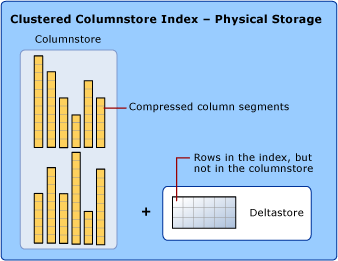
Magazyn kolumn to dane uporządkowane logicznie jako tabela z wierszami i kolumnami oraz fizycznie przechowywane w formacie danych z kolumnami.
Indeks kolumnowy przechowuje fizycznie większość danych w formacie kolumnowym. W formacie magazynu kolumn dane są kompresowane i dekompresowane w postaci kolumn. Nie ma potrzeby dekompresowania innych wartości w każdym wierszu, które nie są żądane przez zapytanie. Dzięki temu można szybko skanować całą kolumnę dużej tabeli.
Rowstore to dane uporządkowane logicznie jako tabela z wierszami i kolumnami, a następnie fizycznie przechowywane w formacie wierszowym. Jest to tradycyjny sposób przechowywania danych tabeli relacyjnej, takich jak klastrowany indeks drzewa B+ lub sterta.
Indeks kolumnowy przechowuje również niektóre wiersze w formacie magazynu wierszy nazywanym deltamagazynem. Magazyn delta, nazywany również grupami wierszy delta, jest miejscem przechowywania wierszy, które są zbyt nieliczne, aby mogły zostać skompresowane do magazynu kolumn. Każda grupa wierszy różnicowych jest implementowana jako klasterowy indeks drzewa B+, który jest strukturą przechowującą wiersze.
Operacje są wykonywane w grupach wierszy i segmentach kolumn
Indeks magazynu kolumn grupuje wiersze w jednostki możliwe do zarządzania. Każda z tych jednostek jest nazywana grupą wierszy. Aby uzyskać najlepszą wydajność, liczba wierszy w grupie wierszy jest wystarczająco duża, aby poprawić współczynnik kompresji, i wystarczająco mała, aby korzystać z operacji w pamięci.
Na przykład indeks magazynu kolumn wykonuje następujące operacje w grupach wierszy:
Kompresuje grupy wierszy do kolumnowego magazynu danych. Kompresja jest wykonywana w poszczególnych segmentach kolumn w grupie wierszy.
Łączy grupy wierszy podczas
ALTER INDEX ... REORGANIZEoperacji, w tym usuwanie danych oznaczonych do usunięcia.Podczas operacji
ALTER INDEX ... REBUILDponownie tworzone są wszystkie grupy wierszy.Raporty dotyczące kondycji i fragmentacji grup rzędów w dynamicznych widokach zarządzania (DMV).
Magazyn różnicowy składa się z co najmniej jednej grupy wierszy nazywanej grupami wierszy różnicowych. Każda grupa wierszy różnicowych jest klastrowanym indeksem drzewa B+, który przechowuje małe obciążenia zbiorcze i wstawienia do momentu, gdy grupa wierszy zawiera 1 048 576 wierszy, w momencie gdy proces nazywany tuple-mover automatycznie kompresuje zamkniętą grupę wierszy do magazynu kolumnowego.
Aby uzyskać więcej informacji na temat statusów grup kolumn, zobacz sys.dm_db_column_store_row_group_physical_stats.
Tip
Zbyt wiele małych grup wierszy zmniejsza jakość indeksu kolumnowego. Operacja reorganizacji scala mniejsze grupy wierszy, postępując zgodnie z wewnętrznymi zasadami progowymi określającymi sposób usuwania usuniętych wierszy i łączenia skompresowanych grup wierszy. Po scaleniu jakość indeksu zostanie ulepszona.
W programie SQL Server 2019 (15.x) i nowszych wersjach mechanizm przemieszczenia krotek wspiera proces scalania działający w tle, który automatycznie kompresuje mniejsze otwarte grupy wierszy delta, które istniały przez jakiś czas, określony przez próg wewnętrzny, lub scala skompresowane grupy wierszy, z których usunięto wiele wierszy.
Każda kolumna ma niektóre swoje wartości w grupach wierszy. Te wartości są nazywane segmentami kolumn. Każda grupa wierszy zawiera jeden segment kolumn dla każdej kolumny w tabeli. Każda kolumna ma jeden segment kolumny w każdej grupie wierszy.
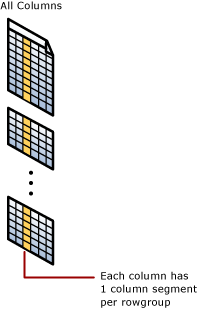
Gdy indeks magazynu kolumn kompresuje grupę wierszy, kompresuje oddzielnie każdy segment kolumny. Aby usunąć cała kolumnę, indeks magazynu kolumn musi usunąć tylko jeden segment kolumny z każdej grupy wierszy.
Małe obciążenia i wkładki przechodzą do deltastore
Indeks kolumnowy poprawia kompresję i wydajność kolumn poprzez jednoczesne kompresowanie co najmniej 102 400 wierszy do indeksu kolumnowego. Aby skompresować wiersze zbiorczo, indeks magazynu kolumn gromadzi małe obciążenia i wstawia do magazynu różnicowego. Operacje deltastore są obsługiwane w tle. Aby zwrócić wyniki zapytania, indeks klastrowanego magazynu kolumn łączy wyniki zapytania zarówno z magazynu kolumn, jak i magazynu różnicowego.
Wiersze trafiają do deltastore, gdy są:
Wstawiono instrukcję
INSERT INTO ... VALUES.Na końcu obciążenia zbiorczego, jeśli ich liczba jest mniejsza niż 102 400.
Updated. Każda aktualizacja jest implementowana jako usuwanie i wstawianie.
Magazyn różnicowy przechowuje również listę identyfikatorów wierszy oznaczonych jako usunięte, które nie zostały jeszcze fizycznie usunięte z magazynu kolumn.
Gdy grupy wierszy różnicowych są pełne, są kompresowane do magazynu kolumn
Klastrowane indeksy magazynu kolumn zbierają do 1048 576 wierszy w każdej grupie wierszy różnicowych przed skompresowaniem grupy wierszy do magazynu kolumn. To poprawia lepszą kompresję indeksu columnstore. Gdy delta rowgroup osiągnie maksymalną liczbę wierszy, przechodzi ze stanu OPEN do stanu CLOSED. Proces w tle o nazwie "tuple-mover" sprawdza zamknięte grupy wierszy. Jeśli proces znajdzie zamkniętą grupę wierszy, kompresuje grupę wierszy i zapisuje ją w magazynie kolumn.
Po skompresowaniu grupy wierszy różnicowych, istniejąca grupa przechodzi w TOMBSTONE stan, który ma zostać usunięty później przez mechanizm przenoszenia krotek, gdy nie będzie do niego żadnych odwołań, a nowa skompresowana grupa wierszy jest oznaczona jako COMPRESSED.
Aby uzyskać więcej informacji na temat statusów grup kolumn, zobacz sys.dm_db_column_store_row_group_physical_stats.
Można wymusić przeniesienie grup wierszy delta do magazynu kolumnowego za pomocą ALTER INDEX, aby przebudować lub zreorganizować indeks. Jeśli podczas kompresji występuje wykorzystanie pamięci, indeks magazynu kolumn może zmniejszyć liczbę wierszy w skompresowanej grupie wierszy.
Każda partycja tabeli ma własne grupy wierszy i grupy wierszy różnicowych
Koncepcja partycjonowania jest taka sama w indeksie klastrowanym, stercie i indeksie magazynującym kolumny. Partycjonowanie tabeli dzieli tabelę na mniejsze grupy wierszy zgodnie z zakresem wartości kolumn. Jest ona często używana do zarządzania danymi. Można na przykład utworzyć partycję dla każdego roku danych, a następnie użyć przełączania partycji w celu zarchiwizowania starych danych do tańszego magazynu.
Grupy wierszy są zawsze definiowane w ramach partycji tabeli. Gdy indeks magazynu kolumn jest partycjonowany, każda partycja ma własne skompresowane pakiety wierszy i pakiety wierszy różnicowych. Tabela niepartyjna zawiera jedną partycję.
Tip
Rozważ użycie partycjonowania tabel, jeśli istnieje potrzeba usunięcia danych z magazynu kolumn. Wyłączanie i obcinanie partycji, które nie są już potrzebne, to efektywna strategia usuwania danych bez wprowadzania fragmentacji w magazynie kolumn.
Każda partycja może mieć wiele grup wierszy różnicowych
Każda partycja może mieć więcej niż jedną grupę wierszy różnicowych. Gdy indeks columnstore musi dodać dane do grupy wierszy różnicowych, a ta grupa jest zablokowana przez inną transakcję, indeks columnstore próbuje uzyskać blokadę na innej grupie wierszy różnicowych. Jeśli nie ma dostępnych grup wierszy różnicowych, indeks magazynowania kolumnowego tworzy nową grupę wierszy różnicowych. Na przykład tabela z 10 partycjami może mieć 20 lub więcej grup wierszy delta.
Łączenie indeksów kolumnowych i wierszowych w tej samej tabeli
Indeks nieklastrowany zawiera kopię części lub wszystkich wierszy i kolumn w tabeli bazowej. Indeks jest definiowany jako co najmniej jedna kolumna tabeli i ma opcjonalny warunek, który filtruje wiersze.
Można utworzyć aktualizowalny indeks kolumnowy nieklastrowany na tabeli przechowującej wiersze. Indeks magazynowy kolumn przechowuje kopię danych, więc potrzebujesz dodatkowej przestrzeni pamięci. Jednak dane w indeksie kolumnowym są kompresowane do znacznie mniejszego rozmiaru niż wymaga tabela wierszowa. Dzięki temu można jednocześnie uruchamiać analizę na indeksie kolumnowym oraz obciążenia OLTP na indeksie wierszowym. Magazyn kolumn jest aktualizowany, gdy dane zmieniają się w tabeli typu rowstore, dlatego oba indeksy operują na tych samych danych.
Tabela rowstore może zawierać jeden nieklastrowany indeks kolumnowy. Aby uzyskać więcej informacji, zobacz Indeksy magazynu kolumn — wskazówki dotyczące projektowania.
W tabeli klastrowanego magazynu kolumn może znajdować się co najmniej jeden nieklastrowany indeks magazynu wierszy. Dzięki temu można wykonać wydajne wyszukiwanie tabel w bazowym magazynie kolumn. Inne opcje również staną się dostępne. Na przykład można wymusić unikatowość przy użyciu UNIQUE ograniczenia w tabeli rowstore. Jeśli nie można wstawić wartości nieunikalnej do tabeli wierszowej, silnik bazy danych nie wstawia wartości do magazynu kolumn.
Zagadnienia dotyczące wydajności nieklastrowanego magazynu kolumn
Definicja indeksu magazynu kolumn nieklastrowanego obsługuje używanie filtrowanego warunku. Aby zminimalizować efekt wydajności dodawania indeksu magazynu kolumn, użyj wyrażenia filtru, aby utworzyć nieklastrowany indeks magazynu kolumn tylko dla podzbioru danych wymaganych do analizy.
Tabela zoptymalizowana pod kątem pamięci może mieć jeden indeks magazynu kolumn. Możesz utworzyć ją po utworzeniu tabeli lub dodaniu jej później za pomocą polecenia ALTER TABLE.
Aby uzyskać więcej informacji, zobacz Indeksy kolumnowe — wydajność zapytań.
Wytyczne dotyczące projektowania indeksu skrótów zoptymalizowane pod kątem pamięci
W przypadku korzystania z In-Memory OLTP wszystkie tabele zoptymalizowane pod kątem pamięci muszą mieć co najmniej jeden indeks. W przypadku tabeli zoptymalizowanej pod kątem pamięci każdy indeks jest również zoptymalizowany pod kątem pamięci. Indeksy haszowe są jednym z możliwych typów indeksów w tabeli zoptymalizowanej dla pamięci. Aby uzyskać więcej informacji, zobacz Indeksy dotyczące tabel Memory-Optimized.
Architektura indeksu skrótu zoptymalizowanego pod kątem pamięci
Indeks skrótu składa się z tablicy wskaźników, a każdy element tablicy jest nazywany zasobnikiem skrótu.
- Każdy zasobnik to 8 bajtów, które są używane do przechowywania adresu pamięci listy łączy elementów kluczowych.
- Każdy wpis jest wartością klucza indeksu oraz adresem odpowiadającego mu wiersza w podstawowej tabeli zoptymalizowanej pod kątem pamięci.
- Każdy wpis wskazuje na kolejny wpis w łańcuchowej liście wpisów, wszystkie połączone z bieżącym kubełkiem.
Liczbę zasobników należy określić w czasie tworzenia indeksu:
- Im niższy stosunek zasobników do wierszy tabeli lub do odrębnych wartości, tym dłuższa jest średnia lista połączeń dla zasobników.
- Krótkie listy linków działają szybciej niż długie listy linków.
- Maksymalna liczba zasobników w indeksach skrótów wynosi 1073 741 824.
Tip
Aby określić właściwy BUCKET_COUNT dla Twoich danych, zobacz Konfiguracja liczby zasobników indeksu skrótu.
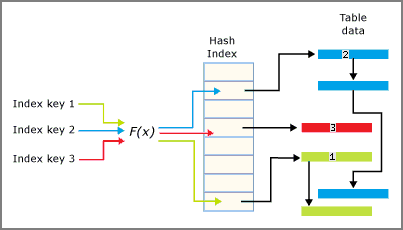
Funkcja skrótu jest stosowana do kolumn klucza indeksu, a wynik funkcji określa, w jakim zasobniku znajduje się ten klucz. Każdy kubek ma wskaźnik do wierszy, których zahaszowane wartości klucza są przypisane do tego kubka.
Funkcja skrótu używana dla indeksów haszujących ma następujące cechy:
- Silnik bazy danych ma jedną funkcję skrótu używaną we wszystkich indeksach skrótów.
- Funkcja skrótu jest deterministyczna. Ta sama wartość klucza wejściowego jest zawsze mapowana na ten sam zasobnik w indeksie skrótu.
- Wiele kluczy indeksu może zostać zamapowanych na ten sam zasobnik skrótu.
- Funkcja skrótu jest zrównoważona, co oznacza, że rozkład wartości kluczy indeksu na zasobnikach skrótów zwykle następuje według rozkładu Poissona lub krzywej dzwonowej, a nie płaski liniowy rozkład.
- Rozkład Poissona nie jest równomiernym rozkładem. Wartości klucza indeksu nie są równomiernie dystrybuowane w zasobnikach skrótów.
- Jeśli dwa klucze indeksu są mapowane na ten sam zasobnik skrótu, występuje kolizja skrótu. Duża liczba kolizji skrótów może mieć wpływ na wydajność operacji odczytu. Realistycznym celem jest, aby 30 procent wiader zawierało dwie różne wartości klucza.
Interakcja indeksu skrótu i zasobników jest podsumowana na poniższym obrazie.
Skonfiguruj liczbę zasobników indeksu skrótu
Liczba zasobników indeksu skrótu jest określana przy tworzeniu indeksu i może zostać zmieniona przy użyciu składni ALTER TABLE...ALTER INDEX REBUILD.
W większości przypadków liczba zasobników powinna być pomiędzy jedną a dwoma krotnościami liczby unikatowych wartości w kluczu indeksu.
Nie zawsze można przewidzieć, ile wartości ma określony klucz indeksu. Wydajność jest zwykle dobra, jeśli BUCKET_COUNT wartość znajduje się w granicach 10-krotności względem rzeczywistej liczby wartości klucza, a przeszacowanie jest ogólnie lepsze niż niedoszacowanie.
Zbyt mało zasobników może mieć następujące wady:
- Więcej kolizji skrótów odrębnych wartości klucza.
- Każda odrębna wartość jest wymuszana do współużytkowania tego samego zasobnika o innej odrębnej wartości.
- Średnia długość łańcucha na wiadro rośnie.
- Tym dłużej łańcuch zasobników, tym wolniejsza szybkość wyszukiwania równości w indeksie.
Zbyt wiele zasobników może mieć następujące wady:
- Zbyt wysoka liczba zasobników może spowodować więcej pustych zasobników.
- Puste zasobniki wpływają na wydajność pełnego skanowania indeksu. Jeśli skanowanie jest wykonywane regularnie, rozważ wybranie liczby zasobników zbliżonych do liczby unikatowych wartości klucza indeksu.
- Puste zasobniki używają pamięci, ale każdy zasobnik używa tylko 8 bajtów.
Note
Dodanie większej liczby zasobników nie zmniejsza łączenia wpisów, które mają zduplikowaną wartość. Szybkość duplikowania wartości służy do decydowania, czy indeks skrótu, czy indeks nieklastrowany jest odpowiednim typem indeksu, a nie do obliczania liczby zasobników.
Zagadnienia dotyczące wydajności indeksów skrótów
Wydajność indeksu skrótu to:
- Doskonały, gdy predykat w
WHEREklauzuli określa dokładną wartość dla każdej kolumny w kluczu indeksu skrótu. Indeks skrótu zmienia się na skanowanie przy użyciu predykatu nierówności. - Słabe, gdy predykat w klauzuli
WHEREszuka zakresu wartości w kluczu indeksu. - Źle, gdy predykat w
WHEREklauzuli określa jedną konkretną wartość dla pierwszej kolumny dwukolumnowego klucza indeksu skrótu, ale nie określa wartości dla innych kolumn klucza.
Tip
Predykat musi zawierać wszystkie kolumny w kluczu indeksu skrótu. Indeks skrótu wymaga całego klucza do wyszukiwania w indeksie.
Jeśli jest używany indeks skrótu, a liczba unikatowych kluczy indeksu jest ponad 100 razy mniejsza niż liczba wierszy, rozważ zwiększenie liczby zasobników, aby uniknąć dużych łańcuchów wierszy, lub zamiast tego, użyj indeksu nieklastrowanego.
Tworzenie indeksu skrótu
Podczas tworzenia indeksu skrótu należy wziąć pod uwagę następujące kwestie:
- Indeks skrótu może być używany tylko w tabeli zoptymalizowanej dla pamięci. Nie może istnieć w tabeli opartej na dysku.
- Indeks skrótu jest domyślnie nieokreślony, ale można go zadeklarować jako unikatowy.
Poniższy przykład tworzy unikatowy indeks skrótu:
ALTER TABLE MyTable_memop ADD INDEX ix_hash_Column2
UNIQUE HASH (Column2) WITH (BUCKET_COUNT = 64);
Wersje wierszy i odzyskiwanie pamięci w tabelach zoptymalizowanych pod kątem pamięci
W tabeli zoptymalizowanej pod kątem pamięci, gdy wiersz ma wpływ na instrukcję UPDATE , tabela tworzy zaktualizowaną wersję wiersza. Podczas transakcji aktualizacji inne sesje mogą być w stanie odczytać starszą wersję wiersza i uniknąć spowolnienia wydajności skojarzonego z blokadą wiersza.
Indeks skrótu może również mieć różne wersje swoich wpisów, aby uwzględnić aktualizację.
Później, gdy starsze wersje nie są już potrzebne, wątek odzyskiwania pamięci (GC) przechodzi przez zasobniki i ich listy linków, aby wyczyścić stare wpisy. Wątek GC działa lepiej, jeśli długość łańcucha listy łączy jest krótka. Aby uzyskać więcej informacji, zobacz In-Memory zarządzanie pamięcią OLTP.
Wytyczne dotyczące projektowania indeksu nieklastrowanego zoptymalizowane pod kątem pamięci
Oprócz indeksów skrótów indeksy nieklastrowane są innymi możliwymi typami indeksów w tabeli zoptymalizowanej pod kątem pamięci. Aby uzyskać więcej informacji, zobacz Indeksy dotyczące tabel Memory-Optimized.
Architektura indeksu nieklastrowanego zoptymalizowana pod kątem pamięci
Indeksy nieklastrowane w tabelach zoptymalizowanych pod kątem pamięci są implementowane przy użyciu struktury danych o nazwie Bw-tree, pierwotnie przewidywanej i opisanej przez firmę Microsoft Research w 2011 roku. Drzewo Bw to wariacja drzewa B wolna od blokad oraz zatrzaśnięć. Aby uzyskać więcej informacji, zobacz Bw-tree: A B-tree for New Hardware Platforms (Drzewo B: drzewo B dla nowych platform sprzętowych).
Na wysokim poziomie drzewo Bw można rozumieć jako mapę stron zorganizowanych według identyfikatora strony (PidMap), mechanizm do przydzielania i ponownego używania identyfikatorów stron (PidAlloc) oraz zbiór stron połączonych na mapie stron oraz siebie nawzajem. Te trzy podskładniki wysokiego poziomu składają się na podstawową strukturę wewnętrzną drzewa Bw.
Struktura jest podobna do normalnego drzewa B w tym sensie, że każda strona ma zestaw uporządkowanych kluczowych wartości, a w indeksie znajdują się poziomy wskazujące niższy poziom, a poziomy liści wskazują wiersz danych. Istnieje jednak kilka różnic.
Podobnie jak w przypadku indeksów skrótów wiele wierszy danych może być połączonych ze sobą w celu obsługi przechowywania wersji. Wskaźniki stron między poziomami to identyfikatory stron logicznych, które są przesunięte na tabelę mapowania stron, która z kolei ma adres fizyczny dla każdej strony.
Aktualizacje stron indeksu nie są wykonywane bezpośrednio. W tym celu wprowadzono nowe strony delta.
- W przypadku aktualizacji strony nie jest wymagane zatrzaśanie ani blokowanie.
- Strony indeksu nie są stałym rozmiarem.
Wartość klucza na każdej stronie poziomu niebędącym liściem jest najwyższą wartością elementu podrzędnego, na który wskazuje. Każdy wiersz zawiera również logiczny identyfikator strony. Na stronach poziomu liściowego, oprócz wartości klucza, znajduje się fizyczny adres wiersza danych.
Wyszukiwania punktowe są podobne do drzew B, z tą różnicą, że strony są połączone tylko w jednym kierunku, w ten sposób silnik bazy danych podąża za prawymi wskaźnikami stron, gdzie każda strona niebędąca liściem zawiera najwyższą wartość swojego elementu podrzędnego, a nie najniższą, jak w drzewie B.
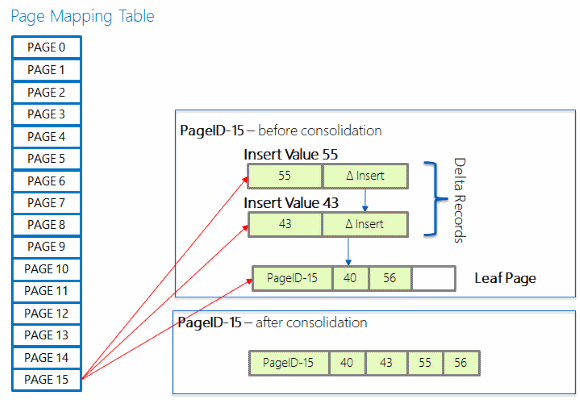
Jeśli strona na poziomie liścia musi ulec zmianie, aparat bazy danych nie modyfikuje samej strony. Silnik bazy danych tworzy rekord różnicowy opisujący zmianę i dodaje go do poprzedniej strony. Następnie aktualizuje adres w tabeli mapowania stron dla poprzedniej strony na adres rekordu delta, który teraz staje się fizycznym adresem dla tej strony.
Istnieją trzy różne operacje, które mogą być wymagane do zarządzania strukturą drzewa Bw: konsolidacja, podział i scalanie.
Konsolidacja różnic
Długi łańcuch rekordów różnicowych może ostatecznie obniżyć wydajność wyszukiwania, ze względu na możliwość wymagać przechodzenia przez długi łańcuch podczas przeszukiwania indeksu. Jeśli nowy rekord różnicowy zostanie dodany do łańcucha, który ma już 16 elementów, zmiany w rekordach różnicowych są konsolidowane na stronie indeksu, do której się odwołuje, a strona jest następnie zrekonstruowana, w tym zmiany wskazywane przez nowy rekord różnicowy wywołujący konsolidację. Nowo utworzona strona ma ten sam identyfikator strony, ale nowy adres pamięci.
Podziel stronę
Strona indeksu w drzewie Bw rośnie zgodnie z potrzebami, począwszy od przechowywania pojedynczego wiersza do przechowywania maksymalnie 8 KB. Gdy strona indeksu wzrośnie do 8 KB, nowe wstawienie pojedynczego wiersza spowoduje podzielenie strony indeksu. W przypadku strony wewnętrznej oznacza to, że nie ma więcej miejsca na dodanie kolejnej wartości klucza i wskaźnika, a dla strony liściowej oznacza to, że wiersz będzie zbyt duży, aby zmieścić się na stronie po włączeniu wszystkich rekordów różnicowych. Informacje statystyczne w nagłówku strony liścia rejestrują wymaganą ilość miejsca na skonsolidowanie rekordów różnicowych. Te informacje są aktualizowane w miarę dodawania każdego nowego rekordu różnicowego.
Operacja podziału jest wykonywana w dwóch atomowych krokach. Na poniższym diagramie przyjęto założenie, że strona liściowa wymusza podział, ponieważ jest wstawiany klucz o wartości 5, a strona nie-liściowa wskazuje na koniec bieżącej strony na poziomie liściowym (wartość klucza 4).

Krok 1: Przydziel dwie nowe strony P1 i P2, i podziel wiersze ze starej P1 strony na te nowe strony, w tym nowo wstawiony wiersz. Nowe miejsce w tabeli mapowania stron służy do przechowywania fizycznego adresu strony P2. Strony P1 i P2 nie są jeszcze dostępne dla żadnych operacji współbieżnych. Ponadto ustawiono wskaźnik logiczny od P1 do P2 . Następnie, w jednym kroku atomowym, zaktualizuj tabelę mapowania stron, aby zmienić wskaźnik ze starego P1 na nowy P1.
Krok 2. Strona nieliściowa wskazuje do P1 ale nie ma bezpośredniego wskaźnika ze strony nieliściowej do P2.
P2 jest osiągalny tylko za pośrednictwem P1. Aby utworzyć wskaźnik ze strony niebędącej liściem do P2, przydziel nową stronę niebędącą liściem (wewnętrzną stronę indeksu), skopiuj wszystkie wiersze ze starej strony niebędącej liściem i dodaj nowy wiersz, aby wskazać na P2. Po wykonaniu tej czynności, zaktualizuj tabelę mapowania stron jednym atomowym krokiem, aby zmienić wskaźnik ze starej nie-liściowej strony na nową nie-liściową stronę.
Strona łączenia
DELETE Gdy operacja powoduje, że strona ma mniej niż 10 procent maksymalnego rozmiaru strony (8 KB) lub z pojedynczym wierszem na niej, ta strona jest scalona ze stroną ciągłą.
Po usunięciu wiersza ze strony dodawany jest rekord różnicowy usuwania. Ponadto jest wykonywane sprawdzanie w celu określenia, czy strona indeksu (strona niestronicowa) kwalifikuje się do scalania. To sprawdzenie sprawdza, czy pozostałe miejsce po usunięciu wiersza jest mniejsze niż 10 procent maksymalnego rozmiaru strony. Jeśli spełnia wymagania, scalanie jest wykonywane w trzech krokach atomowych.
Na poniższej ilustracji założono, że DELETE operacja usuwa wartość klucza 10.

pl-PL: Krok 1: Zostanie utworzona strona delta reprezentująca wartość 10 klucza (niebieski trójkąt), a jej wskaźnik na stronie Pp1 nie-liściowej jest ustawiony na nową stronę delta. Ponadto jest tworzona specjalna strona różnicowa scalania (zielony trójkąt) i jest połączona w taki sposób, aby wskazywała stronę różnicową. Na tym etapie zarówno strona różnicowa, jak i strona scalania różnic nie są widoczne dla żadnej równoczesnej transakcji. W jednym atomowym kroku wskaźnik do strony P1 na poziomie liścia w tabeli mapowania stron jest aktualizowany, aby wskazać scalanej delta-strony. Po wykonaniu tego kroku wpis dla wartości klucza 10 w Pp1 wskazuje teraz na stronę delta-scalania.
Krok 2: Wiersz reprezentujący wartość klucza 7 na stronie nieliściastej musi zostać usunięty, a wpis dla wartości klucza Pp1 musi zostać zaktualizowany tak, aby wskazywał 10. W tym celu zostanie przydzielona nowa nielistna strona Pp2 i wszystkie wiersze z Pp1 zostaną skopiowane, z wyjątkiem wiersza reprezentującego wartość klucza 7; następnie wiersz dla wartości klucza 10 zostanie zaktualizowany, aby wskazywać na stronę P1. Po wykonaniu tej czynności, w jednym niepodzielnym kroku, wpis tabeli mapowania strony wskazujący na Pp1 zostanie zaktualizowany, aby wskazywać na Pp2.
Pp1 nie jest już osiągalny.
Krok 3: Strony P2 na poziomie liścia i P1 są scalane, a strony różnicowe są usuwane. W tym celu przydzielana jest nowa strona P3, a wiersze z P2 i P1 są scalane, a zmiany strony różnicowej są uwzględniane w nowym P3. Następnie, w jednym atomowym kroku, wpis w tabeli mapowania strony wskazujący na stronę P1 jest aktualizowany, aby wskazywał na stronę P3.
Zagadnienia dotyczące wydajności dla indeksów nieklastrowanych zoptymalizowanych pod kątem pamięci
Wydajność indeksu nieklastrowanego jest lepsza niż w przypadku indeksów skrótów podczas wykonywania zapytań względem tabeli zoptymalizowanej pod kątem pamięci z predykatami nierówności.
Kolumna w tabeli zoptymalizowanej pod kątem pamięci może być częścią zarówno indeksu skrótu, jak i indeksu nieklastrowanego.
Gdy kluczowa kolumna w indeksie nieklastrowanym ma wiele zduplikowanych wartości, może to pogorszyć wydajność podczas aktualizacji, wstawiania i usuwania. Jednym ze sposobów poprawy wydajności w tej sytuacji jest dodanie kolumny, która ma lepszą selektywność w kluczu indeksu.
Metadane indeksu
Aby zbadać metadane indeksu, takie jak definicje indeksu, właściwości i statystyki danych, użyj następujących widoków systemowych:
- sys.objects
- sys.indexes
- sys.index_columns
- sys.columns
- sys.types
- sys.partitions
- sys.internal_partitions
- sys.dm_db_index_usage_stats
- sys.dm_db_partition_stats
- sys.dm_db_index_operational_stats
Poprzednie widoki dotyczą wszystkich typów indeksów. W przypadku indeksów magazynujących kolumny dodatkowo użyj następujących widoków:
- sys.column_store_row_groups
- sys.column_store_segments
- sys.column_store_dictionaries
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
W przypadku indeksów kolumnowych wszystkie kolumny są przechowywane w metadanych jako kolumny dołączone. Indeks columnstore nie zawiera kolumn kluczowych.
W przypadku indeksów w tabelach zoptymalizowanych pod kątem pamięci należy dodatkowo użyć następujących widoków:
- sys.hash_indexes
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.memory_optimized_tables_internal_attributes
Treści powiązane
- CREATE INDEX (Transact-SQL)
- Optymalizowanie konserwacji indeksu w celu zwiększenia wydajności zapytań i zmniejszenia zużycia zasobów
- partycjonowane tabele i indeksy
- Indeksy w tabelach Memory-Optimized
- Indeksy kolumnowe: omówienie
- Indeksy w kolumnach obliczanych
- Dostrajanie indeksów nieklastrowanych za pomocą sugestii brakujących indeksów