Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten artykuł zawiera omówienie korzystania z opcji sztucznej inteligencji(AI), takich jak OpenAI i wektory, w celu tworzenia inteligentnych aplikacji za pomocą SQL Database Engine w SQL Server i Azure SQL Managed Instance.
Aby uzyskać informacje dotyczące Azure SQL Database i SQL Database w usłudze Fabric, znajdziesz je w sekcji Inteligentne aplikacje i AI.
Aby uzyskać próbki i przykłady, odwiedź repozytorium próbek SQL AI.
Przegląd
Duże modele językowe (LLM) umożliwiają deweloperom tworzenie aplikacji opartych na sztucznej inteligencji ze znanym środowiskiem użytkownika.
Korzystanie z funkcji LLMs w aplikacjach zapewnia większą wartość i ulepszone środowisko użytkownika, gdy modele mogą uzyskiwać dostęp do odpowiednich danych w odpowiednim czasie z bazy danych aplikacji. Proces ten jest znany jako generowanie rozszerzone o wyszukiwanie (RAG), a Silnik bazy danych SQL ma wiele funkcji, które obsługują ten nowy wzorzec, dzięki czemu jest to świetna baza danych do tworzenia inteligentnych aplikacji.
Poniższe linki zawierają przykładowy kod różnych opcji tworzenia inteligentnych aplikacji:
| Opcja sztucznej inteligencji | Description |
|---|---|
| SQL MCP Server | Stabilny i zarządzany interfejs dla bazy danych, definiujący zestaw narzędzi i konfiguracji. |
| Azure OpenAI | Generuj osadzanie dla programu RAG i integruj się z dowolnym modelem obsługiwanym przez program Azure OpenAI. |
| Wektory | Dowiedz się, jak przechowywać wektory i używać funkcji wektorów w bazie danych. |
| Azure AI Search | Użyj bazy danych wraz z Azure AI Search, aby wytrenować LLM na podstawie danych. |
| Inteligentne aplikacje | Dowiedz się, jak utworzyć kompleksowe rozwiązanie przy użyciu wspólnego wzorca, który można replikować w dowolnym scenariuszu. |
Program SQL MCP Server w aplikacjach sztucznej inteligencji
Program SQL MCP Server znajduje się bezpośrednio w ścieżce danych dla agentów sztucznej inteligencji.
- W miarę generowania żądań serwer udostępnia stabilny i zarządzany interfejs do twojej bazy danych.
- Zamiast ujawniać nieprzetworzone schematy lub polegać na wygenerowanym języku SQL, kieruje on cały dostęp za pośrednictwem zdefiniowanego zestawu narzędzi wspieranych przez konfigurację.
Takie podejście zapewnia przewidywalne interakcje i zapewnia, że każda operacja jest zgodna z zdefiniowanymi uprawnieniami i strukturą. Aby uzyskać więcej informacji, zobacz aka.ms/sql/mcp.
Oddzielając rozumowanie od wykonywania, modele koncentrują się na intencji, podczas gdy program SQL MCP Server obsługuje sposób, w jaki ta intencja staje się prawidłowymi zapytaniami. Ponieważ obszar powierzchni jest ograniczony i opisany, agenci mogą odnajdywać dostępne możliwości, interpretować dane wejściowe i wyjściowe oraz działać bez odgadnięcia. Ten projekt zmniejsza błędy i eliminuje potrzebę złożonej inżynierii monitów, aby zrekompensować niejednoznaczność schematu.
W przypadku deweloperów takie podejście oznacza, że sztuczna inteligencja może bezpiecznie uczestniczyć w rzeczywistych obciążeniach.
Masz następujące możliwości:
- Definiowanie jednostek raz
- Zastosuj role i ograniczenia
Następnie platforma:
- Zapewnia spójne wdrażanie podmiotów, ról i ograniczeń
- Tworzy niezawodną podstawę dla aplikacji opartych na agentach za pośrednictwem danych SQL.
Ta sama konfiguracja, która obsługuje architekturę REST i GraphQL, również zarządza mcp, więc nie ma duplikacji reguł ani logiki. Aby uzyskać więcej informacji, zobacz aka.ms/dab/docs.
Kluczowe pojęcia dotyczące implementowania programu RAG za pomocą programu Azure OpenAI
Ta sekcja zawiera kluczowe pojęcia, które mają kluczowe znaczenie dla zaimplementowania programu RAG z Azure OpenAI w Database Engine SQL.
Wspomagane generowanie przy użyciu pobierania danych (RAG)
RAG to technika, która zwiększa zdolność LLM do tworzenia odpowiednich i informacyjnych odpowiedzi przez pobieranie dodatkowych danych ze źródeł zewnętrznych. Na przykład usługa RAG może wysyłać zapytania do artykułów lub dokumentów zawierających wiedzę specyficzną dla domeny związane z pytaniem lub monitem użytkownika. Model LLM może następnie użyć tych pobranych danych jako odwołania podczas generowania odpowiedzi. Na przykład prosty wzorzec RAG używający silnika bazy danych SQL może być:
- Wstaw dane do tabeli.
- Połącz wystąpienie z Azure AI Search.
- Utwórz model Azure OpenAI GPT-4 i połącz go z Azure AI Search.
- Porozmawiaj i zadawaj pytania dotyczące swoich danych przy użyciu wytrenowanego modelu Azure OpenAI zarówno z aplikacji, jak i z danych w instancji.
Wzorzec RAG, z inżynierią poleceń, służy do zwiększania jakości odpowiedzi, oferując bardziej kontekstowe informacje dla modelu. Funkcja RAG umożliwia modelowi zastosowanie szerszej bazy wiedzy poprzez włączenie odpowiednich źródeł zewnętrznych do procesu generowania, co skutkuje bardziej kompleksowymi i przemyślanymi odpowiedziami. Aby uzyskać więcej informacji na temat grounding LLMs, zobacz Grounding LLMs — Microsoft Community Hub.
Wskazówki i inżynieria wskazówek
Monit to określony tekst lub informacje, które służą jako instrukcja dla dużego modelu językowego (LLM) lub jako dane kontekstowe, na których może opierać się moduł LLM. Monit może przyjmować różne formy, takie jak pytanie, instrukcja, a nawet fragment kodu.
Przykładowe monity, których można użyć do wygenerowania odpowiedzi z poziomu usługi LLM, obejmują:
- Instrukcje: dostarczanie dyrektyw do modelu LLM
- Zawartość podstawowa: zawiera informacje dla LLM do przetwarzania
- Przykłady: pomoc w przygotowaniu modelu do określonego zadania lub procesu
- Wskazówki: kierować dane wyjściowe LLM we właściwym kierunku
- Zawartość pomocnicza: reprezentuje informacje uzupełniające, których usługa LLM może używać do generowania danych wyjściowych
Proces tworzenia dobrych monitów dotyczących scenariusza jest nazywany inżynierią monitu. Aby uzyskać więcej informacji na temat promptów i najlepszych praktyk w zakresie inżynierii promptów, zobacz techniki inżynierii promptów.
Tokens
Tokeny są małymi fragmentami tekstu generowanymi przez podzielenie tekstu wejściowego na mniejsze segmenty. Te segmenty mogą być wyrazami lub grupami znaków, różniąc się długością od pojedynczego znaku do całego wyrazu. Na przykład słowo hamburger jest podzielone na tokeny, takie jak ham, bur, i ger podczas gdy krótkie i typowe słowo podobne pear jest uznawane za pojedynczy token.
W Azure openAI interfejs API tokenizuje tekst wejściowy. Liczba tokenów przetwarzanych w każdym żądaniu interfejsu API zależy od czynników, takich jak długość parametrów wejściowych, wyjściowych i żądań. Ilość przetwarzanych tokenów wpływa również na czas odpowiedzi i przepływność modeli. Każdy model ma limity liczby tokenów, które można przetworzyć w ramach pojedynczego żądania i odpowiedzi z Azure OpenAI. Aby dowiedzieć się więcej, zobacz Modele Azure OpenAI w ramach limitów i przydziałów Azure AI Foundry.
Vectors
Wektory są uporządkowanymi tablicami liczb (zazwyczaj zmiennoprzecinkowymi), które mogą reprezentować informacje o niektórych danych. Na przykład obraz może być reprezentowany jako wektor wartości pikseli lub ciąg tekstu może być reprezentowany jako wektor wartości ASCII. Proces przekształcania danych w wektor jest nazywany wektoryzacją. Aby uzyskać więcej informacji, zobacz Przykłady wektorów.
Praca z danymi wektorowymi jest łatwiejsza dzięki wprowadzeniu typów danych wektorowych i funkcji wektorów.
Osadzanie
Osadzanie to wektory reprezentujące ważne funkcje danych. Osadzanie często uczy się przy użyciu modelu uczenia głębokiego, a modele uczenia maszynowego i sztucznej inteligencji używają ich jako funkcji. Osadzenia mogą również uchwycić semantyczne podobieństwo między podobnymi pojęciami. Na przykład podczas generowania osadzania dla wyrazów person i humanmożna oczekiwać, że ich osadzanie (reprezentacja wektorowa) będzie podobne w wartości, ponieważ wyrazy są również semantycznie podobne.
Azure OpenAI oferuje modele do tworzenia embeddingów na podstawie danych tekstowych. Usługa dzieli tekst na tokeny i generuje osadzanie przy użyciu modeli wstępnie wytrenowanych przez interfejs OpenAI. Aby dowiedzieć się więcej, zobacz
Wyszukiwanie wektorowe
Wyszukiwanie wektorowe to proces znajdowania wszystkich wektorów w zestawie danych, które są semantycznie podobne do określonego wektora zapytania. W związku z tym wektor zapytania dla wyrazu human wyszukuje cały słownik pod kątem semantycznie podobnych wyrazów i powinien znajdować słowo person jako bliskie dopasowanie. Ta bliskość lub odległość jest mierzona przy użyciu metryki podobieństwa, takiej jak podobieństwo cosinus. Im bliżej znajdują się wektory podobne, tym mniejsza jest odległość między nimi.
Rozważmy scenariusz, w którym uruchamiasz zapytanie dotyczące milionów dokumentów, aby znaleźć najbardziej podobne dokumenty w danych. Można tworzyć osadzenia dla danych oraz generować zapytania do dokumentów za pomocą Azure OpenAI. Następnie możesz wykonać wyszukiwanie wektorów, aby znaleźć najbardziej podobne dokumenty z zestawu danych. Jednak wykonywanie wyszukiwania wektorowego w kilku przykładach jest proste. Wykonanie tego samego wyszukiwania w tysiącach lub milionach punktów danych staje się trudne. Istnieją również kompromisy między wyczerpującymi metodami wyszukiwania i przybliżonymi metodami wyszukiwania najbliższego sąsiada (ANN), w tym opóźnieniami, przepływnością, dokładnością i kosztami. Wszystkie te kompromisy zależą od wymagań aplikacji.
W SQL Database Engine można efektywnie przechowywać wektory i wysyłać do nich zapytania, jak opisano w kolejnych sekcjach. Ta funkcja umożliwia dokładne wyszukiwanie najbliższych sąsiadów z wielką wydajnością. Nie musisz decydować o dokładności i szybkości: możesz mieć obie te wartości. Przechowywanie osadzania wektorów wraz z danymi w zintegrowanym rozwiązaniu minimalizuje potrzebę zarządzania synchronizacją danych i przyspiesza czas opracowywania aplikacji sztucznej inteligencji.
Azure OpenAI
Osadzanie to proces reprezentowania świata rzeczywistego jako danych. Tekst, obrazy lub dźwięki można konwertować na osadzanie. Modele Azure OpenAI mogą przekształcać rzeczywiste informacje w reprezentacje wektorowe. Możesz uzyskać dostęp do modeli jako punktów końcowych REST, dzięki czemu możesz je łatwo używać z silnika bazy danych SQL przy użyciu procedury składowanej systemu sp_invoke_external_rest_endpoint. Ta procedura jest dostępna od wersji SQL Server 2025 (17.x) i Azure SQL Managed Instance skonfigurowanej przy użyciu Always-up-to-date update policy.
DECLARE @retval AS INT,
@response AS NVARCHAR (MAX),
@payload AS NVARCHAR (MAX);
SET @payload = JSON_OBJECT('input':@text);
EXECUTE
@retval = sp_invoke_external_rest_endpoint
@url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version = 2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
DECLARE @e AS VECTOR(1536) = JSON_QUERY(@response, '$.result.data[0].embedding');
Użycie wywołania do usługi REST, aby uzyskać osadzenia, jest tylko jedną z dostępnych opcji integracji podczas pracy z SQL Managed Instance i OpenAI. Możesz zezwolić dowolnym z modeli available uzyskać dostęp do danych przechowywanych w Database Engine SQL w celu utworzenia rozwiązań, w których użytkownicy mogą korzystać z danych, takich jak poniższy przykład:
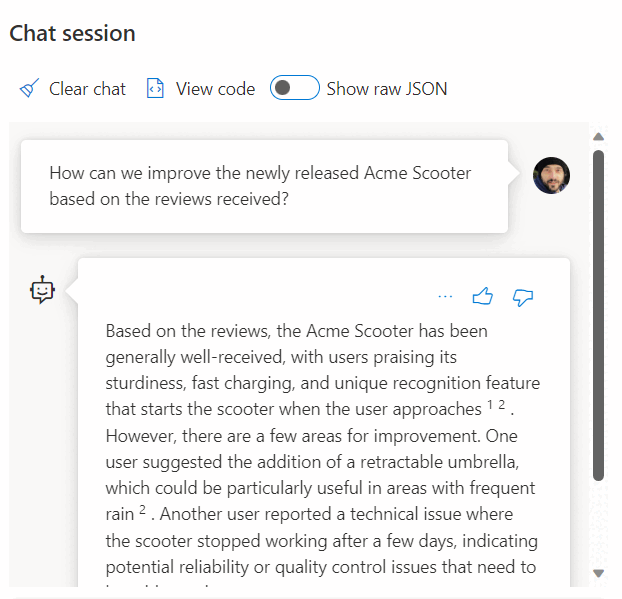
Aby uzyskać dodatkowe przykłady dotyczące używania Azure SQL i interfejsu OpenAI, zobacz następujące artykuły, które dotyczą również SQL Server i Azure SQL Managed Instance:
- Generuj obrazy z Azure OpenAI Service (DALL-E) i Azure SQL
- Korzystanie z punktów końcowych REST OpenAI z Azure SQL
Przykłady wektorów
Dedykowany typ danych wektorowych efektywnie przechowuje dane wektorowe i zawiera zestaw funkcji, które ułatwiają deweloperom implementację wyszukiwania wektorów i podobieństw. Odległość między dwoma wektorami można obliczyć w jednym wierszu kodu przy użyciu nowej VECTOR_DISTANCE funkcji. Aby uzyskać więcej informacji i przykładów, zobacz Przeszukiwanie wektorów i indeksy wektorowe w silniku baz danych SQL.
Przykład:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[embedding] [vector](1536) NOT NULL,
)
GO
SELECT TOP(10)
*
FROM
[dbo].[wikipedia_articles_embeddings_titles_vector]
ORDER BY
VECTOR_DISTANCE('cosine', @my_reference_vector, embedding)
Wyszukiwanie AI platformy Azure
Zaimplementuj wzorce RAG przy użyciu Database Engine SQL i Azure AI Search. Obsługiwane modele czatów można uruchamiać na danych przechowywanych w Database Engine SQL bez konieczności trenowania lub dostosowywania modeli przez zintegrowanie Azure AI Search z Azure OpenAI i Database Engine SQL. Podczas uruchamiania modeli na danych możesz rozmawiać na podstawie danych i analizować je z większą dokładnością i szybkością.
Aby dowiedzieć się więcej na temat integracji Azure AI Search z Azure OpenAI i Database Engine SQL, zobacz następujące artykuły. Te artykuły dotyczą również SQL Server i Azure SQL Managed Instance:
- Azure OpenAI na Twoich danych
- Retrieval Rozszerzone generowanie (RAG) w Azure AI Search
- Wyszukiwanie wektorowe z użyciem Azure SQL i Azure AI Search
Inteligentne aplikacje
Za pomocą Database Engine SQL można tworzyć inteligentne aplikacje, które obejmują funkcje sztucznej inteligencji, takie jak rekomendacje i pobieranie rozszerzonej generacji (RAG), jak pokazano na poniższym diagramie:

Aby zapoznać się z przykładowym projektem typu end-to-end, który pokazuje, jak zbudować aplikację z obsługą sztucznej inteligencji przy użyciu abstrakcyjnych sesji jako przykładowego zestawu danych, zobacz:
- Jak skompilowałem moduł polecający sesję w ciągu 1 godziny przy użyciu interfejsu OpenAI.
- Użyj Retrieval Augmented Generation do zbudowania asystenta sesji konferencyjnej.
Uwaga / Notatka
Integracja aplikacji LangChain i integracja Semantic Kernel polegają na typie danych vector, który jest dostępny od SQL Server 2025 (17.x) i w Azure SQL Managed Instance skonfigurowany za pomocą Always-up-to-date lub SQL Server 2025 update policy, Azure SQL Database i baza danych SQL w Microsoft Fabric.
Integracja aplikacji LangChain
LangChain to dobrze znana platforma do tworzenia aplikacji opartych na modelach językowych. Przykłady pokazujące, jak za pomocą biblioteki LangChain utworzyć czatbota na własnych danych, zobacz:
- langchain-sqlserver Pakiet PyPI.
Kilka przykładów użycia Azure SQL z aplikacją LangChain:
Przykłady od początku do końca:
- Zbuduj czatbota na własnych danych w 1 godzinę z Azure SQL, LangChain i Chainlit: Zbuduj czatbota, używając wzorca RAG na własnych danych, z użyciem biblioteki LangChain do organizacji wywołań LLM i Chainlit do budowy interfejsu użytkownika.
Integracja z Semantic Kernel
Semantic Kernel to zestaw SDK typu open source którego można użyć do łatwego tworzenia agentów wywołujących istniejący kod. Jako wysoce rozszerzalny zestaw SDK można używać Semantic Kernel z modelami z platformy OpenAI, Azure OpenAI, Hugging Face i nie tylko. Łącząc istniejące języki C#, Python i Java z tymi modelami, możesz tworzyć agentów, którzy odpowiadają na pytania i automatyzują procesy.
Przykładem, jak łatwo Semantic Kernel pomaga w tworzeniu rozwiązań wspieranych przez sztuczną inteligencję, jest:
- Najlepszy czatbot?: Twórz czatbota na własnych danych przy użyciu wzorców NL2SQL i RAG dla najlepszych doświadczeń użytkownika.