Zarządzanie Miejsca do magazynowania Direct w programie VMM
Ten artykuł zawiera omówienie Miejsca do magazynowania Direct (S2D) i sposobu wdrażania go w sieci szkieletowej programu System Center Virtual Machine Manager (VMM).
Miejsca do magazynowania Direct (S2D) wprowadzono w systemie Windows Server 2016. Grupuje fizyczne dyski magazynu do pul magazynów wirtualnych w celu zapewnienia zwirtualizowanego magazynu. Dzięki zwirtualizowanej pamięci masowej można wykonywać następujące czynności:
- Zarządzanie wieloma fizycznymi źródłami magazynu jako pojedynczą jednostką wirtualną.
- Uzyskaj niedrogie miejsce do magazynowania z zewnętrznymi urządzeniami magazynowymi i bez tych urządzeń.
- Zbierz różne typy magazynu w jednej puli magazynów wirtualnych.
- Łatwe aprowizuj magazyn i rozszerzaj zwirtualizowany magazyn na żądanie, dodając nowe dyski.
Uwaga
Program VMM 2019 UR3 lub nowszy obsługuje infrastrukturę hiperkonwergentną usługi Azure Stack (HCI, wersja 20H2).
Uwaga
Program VMM 2022 obsługuje infrastrukturę hiperkonwergentną usługi Azure Stack (HCI, wersja 20H2 i 21H2).
Uwaga
Program VMM 2025 obsługuje infrastrukturę hiperkonwergentną usługi Azure Stack (HCI, wersja 23H2 i 22H2).
Jak to działa?
Funkcja Bezpośrednie miejsca do magazynowania tworzy pule magazynu z magazynu dołączonego do określonych węzłów w klastrze systemu Windows Server. Magazyn może być wewnętrzny na węźle lub na urządzeniach dyskowych, które są bezpośrednio dołączone do jednego węzła. Obsługiwane dyski magazynu obejmują NVMe, ssd podłączone za pośrednictwem SATA lub SAS i HDD. Dowiedz się więcej.
- Po włączeniu funkcji Bezpośrednie miejsca do magazynowania w klastrze systemu Windows Server funkcja bezpośrednie miejsca do magazynowania automatycznie odnajduje uprawniony magazyn i dodaje go do puli magazynów dla klastra.
- Funkcja Bezpośrednie miejsca do magazynowania tworzy również wbudowaną pamięć podręczną magazynu po stronie serwera w celu zmaksymalizowania wydajności. Najszybsze dyski są używane do buforowania i pozostałych dysków dla pojemności. Dowiedz się więcej o pamięci podręcznej.
- Woluminy są tworzone na podstawie puli magazynów. Tworzenie woluminu tworzy dysk wirtualny (miejsce do magazynowania), partycje i formatuje go, dodaje go do klastra i konwertuje go na udostępniony wolumin klastra (CSV).
- Skonfigurujesz różne poziomy odporności na uszkodzenia dla woluminu, aby określić, jak dyski wirtualne są rozłożone na dyski fizyczne w puli przy użyciu protokołu SMB 3.0. Wolumin można skonfigurować bez odporności lub odporności dublowania lub parzystości. Dowiedz się więcej.
Wdrożenie zbieżne i niekonwergentne
Klaster z uruchomioną usługą S2D można wdrożyć na kilka sposobów:
- Wdrożenie hiperzbieżne: środowisko obliczeniowe funkcji Hyper-V i magazyn S2D są uruchamiane w tym samym klastrze bez separacji między nimi. Zapewnia to jednoczesne skalowanie zasobów obliczeniowych i magazynowych.
- Wdrożenie rozagregowane: zasoby obliczeniowe są uruchamiane w jednym klastrze funkcji Hyper-V. Magazyn S2D działa w innym klastrze. Klastry można skalować oddzielnie w celu precyzyjnego dostosowania zarządzania.
Wdrożenie hiperkonwergentne
Oto ilustracja dotycząca wdrożenia hiperkonwergentnego
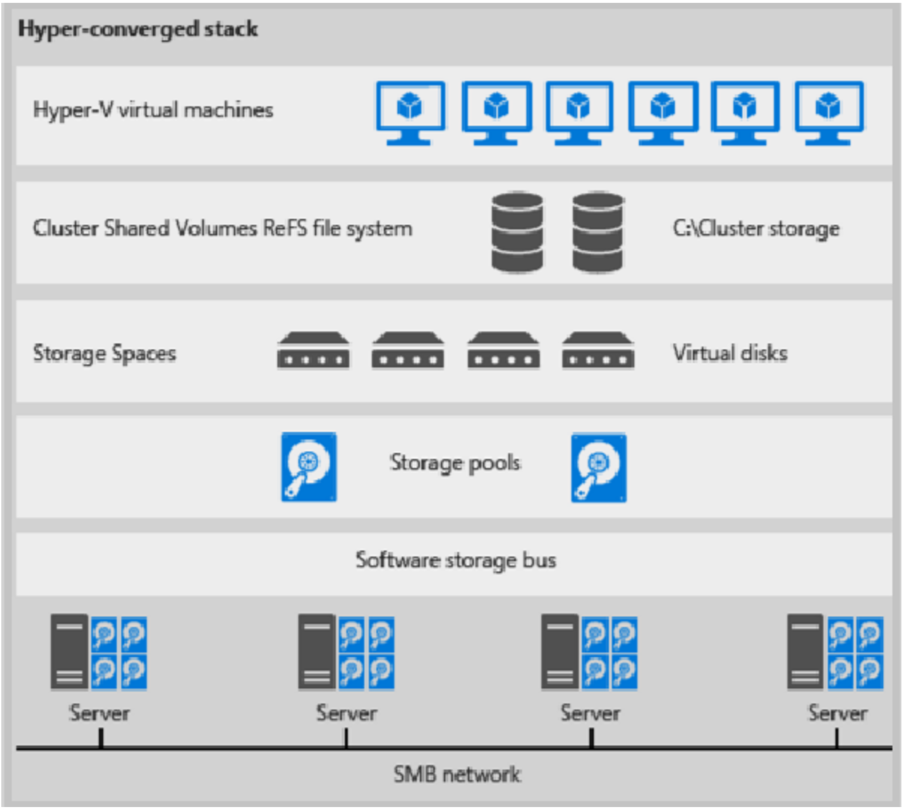
Rysunek 1. Wdrożenie hiperkonwergentne
- Pliki maszyn wirtualnych są przechowywane na lokalnych woluminach CSV.
- Udziały plików i protokół SMB nie są używane.
- Po udostępnieniu woluminów CSV funkcji S2D aprowizuj je tak, jak w przypadku każdego innego wdrożenia funkcji Hyper-V.
- Klaster obliczeniowy funkcji Hyper-V można skalować wraz z magazynem S2D.
Wdrożenie rozagregowane
Oto ilustracja przedstawiająca wdrożenie rozagregowane

Rysunek 2. Wdrożenie rozagregowane
- Udziały plików są tworzone na woluminach CSV S2D.
- Maszyny wirtualne funkcji Hyper-V są skonfigurowane do przechowywania plików na skalowanym w poziomie serwerze plików (SOFS) i uzyskują dostęp przy użyciu protokołu SMB 3.0.
- Klastry funkcji Hyper-V i serwera SOFS można skalować oddzielnie w celu precyzyjnego dostosowania zarządzania. Na przykład węzły obliczeniowe mogą mieć niemal pełną pojemność dla wielu maszyn wirtualnych, ale węzły magazynu mogą mieć nadmiarową pojemność dysku i liczby operacji we/wy na sekundę; dlatego dodajesz tylko dodatkowe węzły obliczeniowe.