Wyodrębnione informacje przechowuj w magazynie wiedzy
Chociaż indeks może być uważany za podstawowe dane wyjściowe z procesu indeksowania, wzbogacone dane, które zawiera, mogą być również przydatne w inny sposób. Przykład:
- Ponieważ indeks jest zasadniczo kolekcją obiektów JSON, każdy reprezentujący rekord indeksowany, może być przydatne wyeksportowanie obiektów jako plików JSON w celu integracji z procesem orkiestracji danych na potrzeby operacji wyodrębniania, przekształcania i ładowania (ETL).
- Możesz chcieć znormalizować rekordy indeksów do schematu relacyjnego tabel na potrzeby analizy i raportowania.
- Po wyodrębnieniu obrazów osadzonych z dokumentów podczas procesu indeksowania możesz zapisać te obrazy jako pliki.
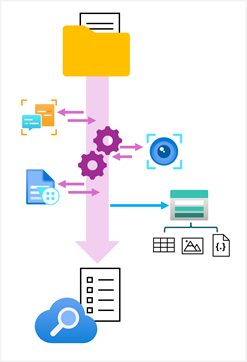
Usługa Azure AI Search obsługuje te scenariusze, umożliwiając definiowanie magazynu wiedzy w zestawie umiejętności, który hermetyzuje potok wzbogacania. Magazyn wiedzy składa się z projekcji wzbogaconych danych, które mogą być obiektami JSON, tabelami lub plikami obrazów. Gdy indeksator uruchamia potok w celu utworzenia lub zaktualizowania indeksu, projekcje są generowane i utrwalane w magazynie wiedzy.
Wskazówka
Aby dowiedzieć się więcej na temat korzystania z magazynu wiedzy, zobacz Magazyn wiedzy w Azure AI Search w dokumentacji Azure AI Search.