Wprowadzenie
Obecnie skala problemów związanych z uczeniem maszynowym i wyszukiwaniem danych (MLDM) rośnie wykładniczo. Podobnie rośnie zainteresowanie aparatami analitycznymi, które mogą efektywnie wykonywać algorytmy MLDM w systemach rozproszonych, takimi jak chmury. Projektowanie, wdrażanie i testowanie rozproszonych aplikacji MLDM może być trudne, ponieważ zazwyczaj wymaga to od ekspertów wiedzy, jak rozwiązywać problemy z synchronizacją, zakleszczeniami, komunikacją, planowaniem, zarządzaniem stanem rozproszonym i odpornością na uszkodzenia. Wiele najnowszych osiągnięć w zakresie projektowania algorytmów MLDM skupia się na modelowaniu takich algorytmów jako grafy.
Wyrażanie danych i obliczeń za pomocą abstrakcji grafu
Przyjrzyjmy się kilku przykładom danych modelowanych jako grafy oraz sposobom wyrażania obliczeń w tym modelu. Graf jest modelowany matematycznie jako zestaw: $G = \lbrace V, E \rbrace$, gdzie $V$ jest zestawem wierzchołków $v_{i}$, a $E$ jest zestawem krawędzi $e_{i}$. Ponadto każda krawędź $e_{i}$ in $G$ reprezentuje krawędź między dokładnie dwoma wierzchołkami : $\lbrace v_{i}, v_{j} \rbrace \in V$. Istnieje wiele typów grafów, które mogą nie mieć określonego kierunku, co oznacza, że $e = \lbrace v_{i}, v_{j} \rbrace = \lbrace v_{j}, v_{i} \rbrace \forall e \in E$ (tj. wszystkie krawędzie są równoważne i dwukierunkowe), lub mieć określony kierunek, gdzie krawędzie są unikatowe i nie są równe. Grafy mogą być również ważone, jeśli dodatkowy parametr, znany jako waga ($w_{i}$), istnieje $\forall e \in E$. Ponadto wierzchołki również mogą być ważone. Jak zobaczymy, jest to przydatne w różnych aplikacjach. Typowe obliczenia grafu obejmują obliczenie najkrótszej ścieżki między dwoma punktami, grafu na podgrafy na podstawie pewnej metryki optymalizacji (minimalna liczba ciętych krawędzi lub maksymalny przepływ między grafami), obliczenia maksymalnego stopnia (wierzchołka z największą liczbą krawędzi) itd.
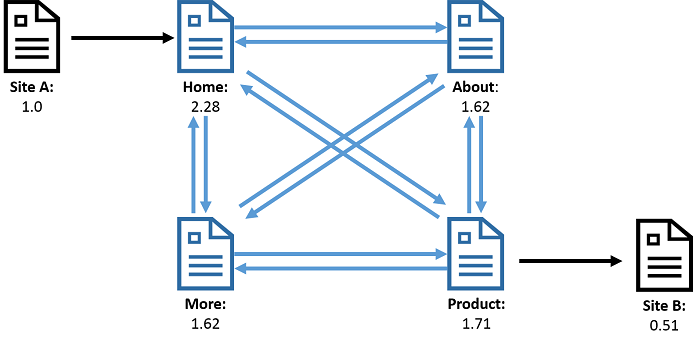
Rysunek 1. Wykres internetowy, w którym wierzchołki reprezentują strony internetowe i krawędzie reprezentują łącza między stronami. W wyniku uruchomienia algorytmu PageRank dla tego grafu każdy wierzchołek ma skojarzoną wartość, znaną jako ranga, która jest reprezentacją ważności strony. Ranga jest obliczana na podstawie liczby łączy przychodzących i wychodzących danej strony.
Rysunek przedstawia przykład grafu internetowego. Wierzchołki oznaczają strony sieci Web, a krawędzie reprezentują łącza między stronami sieci Web. Klasycznym przykładem obliczenia wykonanego na grafie internetowym jest algorytm PageRank, który oblicza ważność strony sieci Web na podstawie stron, które zawierają łącza niej. Podobnie graf sieci społecznościowej na rysunku 2 przedstawia osoby jako wierzchołki oraz krawędzie reprezentujące relację, taką jak „jest znajomym” lub „obserwuje”. W tym przypadku interesujące są obliczenia, takie jak obliczanie najpopularniejszych osób (obliczanie wierzchołków o największej liczbie krawędzi) lub znajdowanie silnie zintegrowanych społeczności osób, które znają się nawzajem (zliczanie trójkątów).
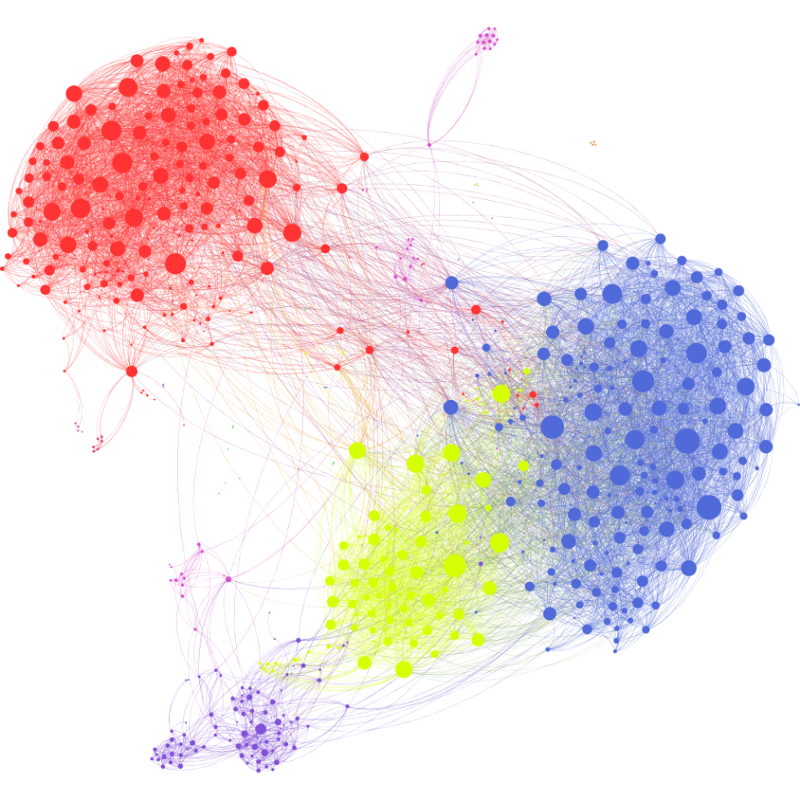
Rysunek 2. Wizualizacja grafu społecznościowego serwisu Facebook dla ograniczonej liczby użytkowników. (Źródło)
Jak można sobie wyobrazić, niektóre z problemów wymienionych powyżej zwiększają się wraz ze skalą i złożonością. Jeden z największych grafów internetowych dostępnych publicznie składa się z 1,7 miliarda stron sieci Web i 64 miliardów łączy. Jest ogólnie uznawany za znacznie mniejszy niż dane obsługiwane przez systemy produkcyjne firm świadczących usługi sieci Web, takich jak Google i Microsoft. Nie można zhermetyzować wszystkich tych danych do pamięci pojedynczego komputera, mimo to potrzebujemy wydajnych systemów, które mogą obsługiwać przetwarzanie takich danych o dużej skali.
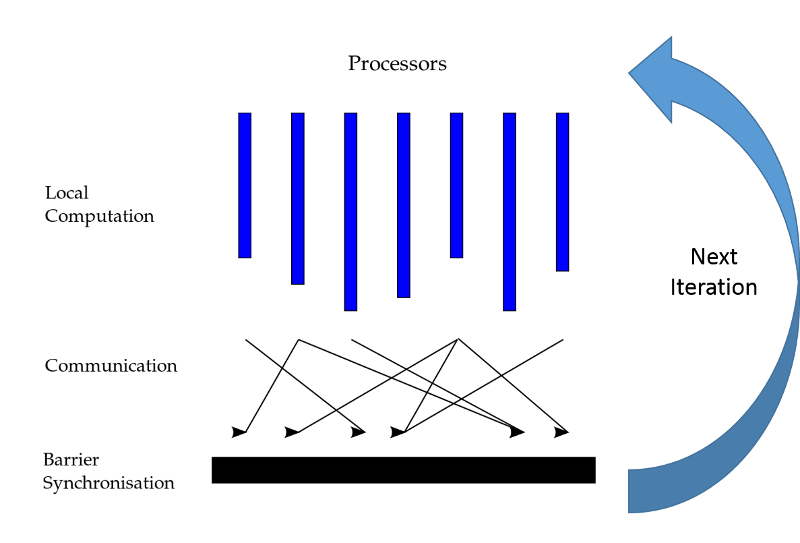
Rysunek 3. Równoległy model zbiorczo-synchroniczny (BSP)
Przykładem systemu zaprojektowanego do przetwarzania dużych grafów w sposób rozproszony jest Pregel firmy Google. Pregel wykonuje obliczenia na grafach w sposób iteracyjny i synchronizowany (znany również jako model równoległy, zbiorczy i synchroniczny lub BSP). Program systemu Pregel jest uruchamiany jako seria globalnie zsynchronizowanych iteracji, co może powodować wykonywanie niektórych obliczeń w kontekście każdego wierzchołka w grafie (rysunek 3). Wierzchołki mogą następnie wymieniać komunikaty ze swoimi sąsiadami. Zwykle odbywa się to w celu zaktualizowania stanu lub innych zmiennych. System Pregel uruchamia następną iterację po zakończeniu przetwarzania bieżącego wykonania przez wszystkie wierzchołki. Komunikaty wymieniane między maszynami w iteracji $i $ są dostarczane w iteracji $i + $1. Program będzie uruchamiać kolejne iteracje, aż zostanie spełniony warunek zbieżności lub liczba ukończonych iteracji wyniesie $N $, gdzie $N $ to zdefiniowana przez użytkownika maksymalna liczba iteracji do wykonania.
Mimo że pregel oferuje obiecującą opcję jako rozproszony, równoległy aparat analizy grafów, cierpi z powodu poważnego niedoboru: Pregel uruchamia obliczenia synchronicznie, co może mieć wpływ na wydajność, ponieważ środowisko uruchomieniowe każdej iteracji jest zawsze dyktowane przez ostatni wątek do ukończenia wykonywania. Można również wyobrazić sobie skutki niezrównoważenia grafu pod względem stopnia wierzchołków. Ma to miejsce w przypadku dużej liczby grafów potrzebnych do analizy danych big data. Na przykład grafy społecznościowe wykazują rozkład wykładniczy, gdzie niewielka liczba wierzchołków ma dużą liczbę krawędzi. Przykładem tego zjawiska jest graf obserwujących w serwisie Twitter (rysunek 4), gdzie celebryci i osoby wpływowe mają miliony obserwujących, a większość innych użytkowników ma znacznie mniejszą liczbę obserwujących.
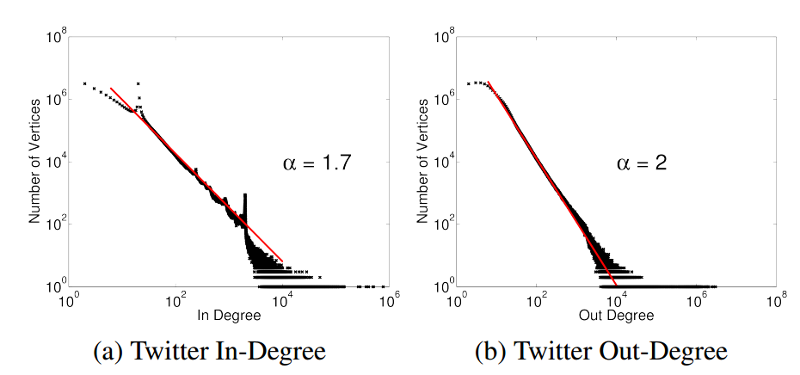
Rysunek 4. Dystrybucja power-law na wykresie obserwowania w serwisie Twitter. Zwróć uwagę, że niewielka liczba wierzchołków (<100) ma bardzo wysoką liczbę stopni i wychodzących (>10 000)1
W tym module prezentujemy oprogramowanie GraphLab, alternatywny rozproszony aparat do równoległej analizy, który umożliwia wydajne i prawidłowe wykonywanie synchronicznych i asynchronicznych problemów MLDM i innych. Narzędzie GraphLab jest również odpowiednie do obsługi grafów, które wykazują rozkład wykładniczy.
Zawartość tego modułu:
- Omówienie struktury danych, która powinna być używana do przechowywania grafów wejściowych do użycia i przetwarzania za pomocą oprogramowania GraphLab
- Prezentacja przepływu grafów wejściowych przez aparat GraphLab od ich użycia po wygenerowanie wyników
- Omówienie modelu architektonicznego oprogramowania GraphLab
- Prezentacja modelu programowania stosowanego w oprogramowaniu GraphLab oraz obsługiwanych mechanizmów zapewniania spójności do ochrony udostępnianych danych przez konfliktami typu odczyt-zapis lub zapis-zapis.
- Omówienie asynchronicznego modelu obliczeniowego, na którym oparty jest aparat GraphLab
- Analiza technik odporności na błędy w oprogramowaniu GraphLab
Cele szkolenia
Zawartość tego modułu:
- Opis unikatowych funkcji w narzędziu GraphLab i typów aplikacji, dla których jest przeznaczone
- Przedstawienie funkcji struktury programowania równoległego i rozproszonego opartego na grafach
- Przedstawienie trzech głównych elementów aparatu GraphLab
- Opis czynności związanych z aparatem wykonywania GraphLab
- Opis modelu architektonicznego oprogramowania GraphLab
- Przedstawienie strategii planowania w narzędziu GraphLab
- Opis modelu programowania narzędzia GraphLab
- Lista poziomów spójności w oprogramowaniu GraphLab i ich wyjaśnienie
- Opis strategii umieszczania danych w pamięci w narzędziu GraphLab i jej wpływ na wydajność niektórych typów grafów
- Omówienie modelu obliczeniowego oprogramowania GraphLab
- Omówienie mechanizmów odporności na awarie oprogramowania GraphLab
- Opis czynności związanych z wykonywaniem programu GraphLab
- Porównanie oprogramowania MapReduce, Spark i GraphLab pod względem modeli programowania, obliczeń, przetwarzania równoległego, architektury i planowania
- Identyfikowanie odpowiedniego aparatu analitycznego zależnie od cech aplikacji
Wymagania wstępne
- Zrozumienie idei przetwarzania w chmurze, w tym modeli usług w chmurze, i zapoznanie się z najpopularniejszymi dostawcami usług w chmurze
- Znajomość technologii umożliwiających przetwarzanie w chmurze
- Zrozumienie, jak dostawcy usług w chmurze płacą za korzystanie z chmury oraz pobierają za to opłaty
- Wiedza o tym, czym są centra danych oraz dlaczego istnieją
- Wiedza na temat sposobu konfiguracji, zasilania i aprowizacji centrów danych
- Wiedza na temat sposobu aprowizacji i mierzenia zasobów chmury
- Znajomość koncepcji wirtualizacji
- Znajomość różnych typów wirtualizacji
- Zrozumienie wirtualizacji procesora
- Zrozumienie wirtualizacji pamięci
- Zrozumienie wirtualizacji we/wy
- Znajomość różnych typów danych i sposobów ich przechowywania
- Znajomość działania rozproszonych systemów plików
- Znajomość działania baz danych NoSQL i magazynu obiektów
- Znajomość programowania rozproszonego oraz wiedza o tym, dlaczego jest ono przydatne w chmurze
- Zrozumienie usługi MapReduce i sposobu, w jaki umożliwia ona przetwarzanie danych big data
- Omówienie platformy Spark i różnic między platformą MapReduce
Odwołania
- J. Gonzalez, Y. Low, H. Gu, D. Bickson i C. Guestrin (październik 2012 r.). PowerGraph: rozproszone obliczenia równoległe grafu na grafach naturalnych w ramach 10 konferencji USENIX na temat projektowania i implementacji systemów operacyjnych