Struktura danych i przepływ grafu
Narzędzie GraphLab zostało opracowane przez uniwersytet Carnegie Mellon University i zawiera przykładowe rozproszone aparaty do analizy grafów równoległych w chmurze. Tak jak wszystkie aparaty do analizy grafów równoległych, narzędzie GraphLab obsługuje problemy wejściowe modelowane jako grafy, w których wierzchołki reprezentują obliczenia, a krawędzie kodują zależności między danymi lub komunikację.
Ewolucja i wersje narzędzia GraphLab
Narzędzie GraphLab zostało pierwotnie opracowane jako struktura do przetwarzania grafów przeznaczone dla systemów o pamięci współdzielonej (maszyn wielordzeniowych)1. Narzędzie GraphLab obejmowało następnie aparat wykonywania rozproszonego, aby umożliwić obliczanie bardzo dużych grafów w klastrze maszyn.2PowerGraph3 (znany również jako GraphLab 2.0) pojawiły się przy użyciu technik, które pozwoliły na szybsze rozproszone przetwarzanie grafów, które podążały za dystrybucją prawa zasilania (np. grafami społecznościowymi). Narzędzie GraphLab posłużyło do utworzenia nowego przedsiębiorstwa o nazwie Dato Inc., które oferuje pakiet oprogramowania GraphLab Create. Nasze omówienie narzędzia GraphLab w tym module będzie dotyczyć najnowszej wersji typu open source, PowerGraph (GraphLab 2.0).
W narzędziu GraphLab grafy są początkowo przechowywane jako pliki w podstawowej warstwie magazynów rozproszonych, takiej jak system plików HDFS, jak pokazano na rysunku 5. Narzędzie GraphLab obejmuje dwie fazy: inicjowania i wykonywania. Podczas inicjowania aparat GraphLab odczytuje wejściowe pliki grafów z podstawowego magazynu i dzieli je na wiele partycji, które mogą być rozproszone na wielu maszynach w klastrze. W fazie wykonywania na poszczególnych maszynach uruchamiane są obliczenia na wierzchołkach grafu zdefiniowane przez użytkownika, przesyłane są aktualizacje i wykonywane są iteracje, aż do momentu spełnienia pewnego warunku zbieżności.
Faza inicjowania
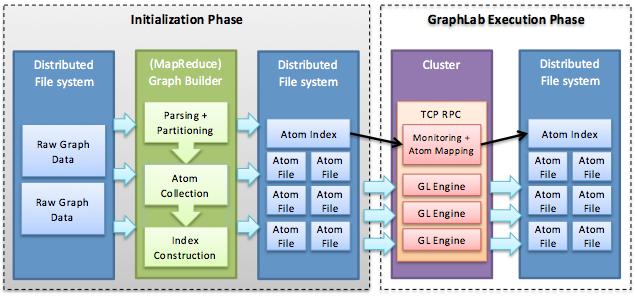
Rysunek 5. System GraphLab. W fazie inicjowania atomy są konstruowane przy użyciu struktury MapReduce (na przykład). W fazie wykonania narzędzia GraphLab atomy są przypisywane do maszyn w klastrze i ładowane przez maszyny z rozproszonego systemu plików (np. HDFS).
W pierwszej fazie graf wejściowy jest dzielony na k partycji, nazywanychatomami, gdzie wartość k jest znacznie większa niż liczba maszyn w klastrze. Jak pokazano na rysunku 5, atomy mogą być tworzone sekwencyjnie lub przy użyciu technik obciążenia równoległego, w tym struktury MapReduce. Narzędzie GraphLab nie przechowuje rzeczywistych wierzchołków i krawędzi w atomach, ale zamiast tego przechowuje polecenia służące do ich generowania w postaci dziennika. Dzięki temu narzędzie GraphLab może odtworzyć fragmenty grafu w przypadku awarii węzłów. Ponadto narzędzie GraphLab przechowuje w poszczególnych atomach informacje o sąsiadujących wierzchołkach i krawędziach. Te informacje, określane w narzędziu GraphLab jako duplikaty wierzchołków, zapewniają możliwość buforowania w celu umożliwienia efektywnego uzyskiwania dostępu do danych dotyczących sąsiedztwa.
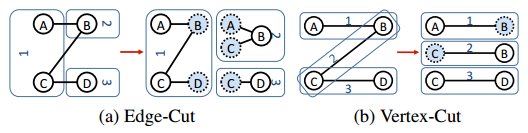
Rysunek 6. Strategie partycjonowania grafu. (a) Ilustruje technikę partycjonowania według krawędzi, a (b) ilustruje technikę dzielenia według wierzchołków.
Graf może zostać podzielony na partycje między maszyny w klastrze na wiele sposobów (rysunek 6). Prostą techniką jest dzielenie według krawędzi, które polega na partycjonowaniu grafu wzdłuż każdego wierzchołka (rysunek 6(a)). Każdy wierzchołek jest losowo przypisywany do maszyny wraz ze wszystkimi skojarzonymi z nim krawędziami. W efekcie generowane są duplikaty wierzchołków, aby krawędzie mogły być skojarzone z wierzchołkiem, który nie znajduje się na określonej maszynie. Jednak w przypadku grafów z rozkładem wykładniczym krawędzi, oznacza to, że partycjonowanie według krawędzi będzie niezrównoważone i niektóre maszyny będą bardziej obciążone niż inne (ze względu na niewielką liczbę wierzchołków o wzorcu gwiazdy). Aby obsługiwać takie wykresy, narzędzie GraphLab używa nowej techniki (znanej jako zachłanne dzielenie według wierzchołków) do partycjonowania wierzchołków o dużej liczbie krawędzi i rozpraszania ich między maszyny w celu bardziej wydajnego rozkładu obliczeń. Wierzchołki o dużej liczbie krawędzi są replikowane między maszynami, a każda maszyna otrzymuje podzestaw krawędzi dla tego wierzchołka (rysunek 6(b)). Maszyna, która przechowuje daną krawędź wierzchołka jest określana przy użyciu następującego algorytmu:
Algorytm 1
Zachłanne dzielenie według krawędzi dla rozkładu krawędzi $e = \lbrace v_{i}, v_{j} \rbrace$ wierzchołka $v_{i}$:
if istnieje maszyna, do której przypisano zarówno wierzchołek $v_{i}$, jak i $v_{j}$, then
- Przypisz wierzchołek $v_{j}$ do tej maszyny
else if wierzchołki $v_{i}$ i $v_{j}$ są przypisane do innych maszyn, then
- Przypisz wierzchołek $e$ do maszyny, do której jest przypisana najmniejsza liczba krawędzi
else
- Przypisz $e$ do najmniej obciążonej maszyny
Oznacz krawędź $e$ jako przypisaną
Ładowanie tych partycji może odbywać się w sposób rozproszony i skoordynowany, co gwarantuje, że przydział wierzchołków i krawędzi w klastrze jest optymalny, ale czas potrzebny do załadowania jest znacznie dłuższy niż w przypadku losowego umieszczania. Z kolei losowe umieszczanie będzie prowadzić do niezrównoważonego obciążenia i utraty lokalizacji. Kompromis między tymi dwoma podejściami, gdzie w każdej maszynie szacowane są przypisania krawędzi i wierzchołków w klastrze, jest kompromis sugerowany w artykule "PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs" (Rozproszona grafu równoległa obliczenia na grafach naturalnych).3
Jednak użytkownicy nie muszą przechowywać grafów w formatach, które mogą używane i analizowane przez narzędzie GraphLab w fazie inicjowania. Jest to zależne od podstawowej warstwy magazynu i aparatu analizy, z którego korzysta narzędzie GraphLab. Jeśli na przykład struktura MapReduce jest używana do odczytywania i analizowania plików grafów wejściowych z systemu plików HDFS, pliki grafów wejściowych muszą być sformatowane przy użyciu struktury danych klucz-wartość MapReduce.
Generowanie atomów dla danego grafu wejściowego kończy pierwszą fazę strategii partycjonowania GraphLab. Następnie aparat zapisuje strukturę połączeń i lokalizacje atomów w pliku indeksu, znanego również jako metagraf (rysunek 5). Plik indeksu atomów obejmuje k wierzchołków, z których każdy odpowiada atomowi, oraz krawędzie kodujące połączenia między nimi. W drugiej fazie plik indeksu atomów jest dzielony równomiernie między maszyny w klastrze. Następnie atomy są ładowane przez maszyny w klastrze, a każda maszyna tworzy swoje partycje danego grafu, wykonując dziennik w każdym z przypisanych do niego atomów. Generując partycje z dzienników atomów (a nie bezpośrednio mapując partycje do maszyn w klastrze), narzędzie GraphLab umożliwia wprowadzanie przyszłych zmian w grafie przez dołączanie poleceń dziennika, bez konieczności ponownego dzielenia na partycje całych grafów. Ponadto te same atomy grafu mogą być ponownie wykorzystane dla różnych rozmiarów klastra przez ponowny podział odpowiedniego pliku indeksu atomów i ponowne wykonanie dzienników atomów, dzięki czemu powtarzana jest tylko druga faza partycjonowania.
Tworzenie partycji grafu na maszynach w klastrze kończy fazę inicjowania narzędzia GraphLab i rozpoczyna fazę wykonywania.
Faza wykonywania
Jak pokazano na rysunku 5, na każdej maszynie w klastrze jest uruchomione wystąpienie aparatu GraphLab, które składa się z dwóch głównych części: grafu danych oraz zdefiniowanych przez użytkownika funkcji wykonujących operacje na grafie danych. Graf danych reprezentuje stan programu użytkownika w maszynie w klastrze i zawiera graf kierunkowy $G = (V, E, D)$, gdzie wartość $V$ jest zestawem wierzchołków, wartość $E$ jest zestawem krawędzi, a wartość $D$ to dane zdefiniowane przez użytkownika (np. parametry, dane wejściowe użytkownika, a nawet dane statystyczne). W narzędziu GraphLab dane są skojarzone z wierzchołkami i krawędziami.
Obliczenie jest następnie reprezentowane jako program bezstanowy wykonywany równolegle na każdym wierzchołku grafu. Ten program składa się z trzech odrębnych faz: Zbieraj, Zastosuj i Punktowy (GAS).
Faza zbierania: W fazie zbierania każdy wierzchołek (określany jako centralny wierzchołek) zbiera informacje z sąsiednich wierzchołków i krawędzi. Następnie narzędzie GraphLab może zastosować operację agregacji lub sumowania zdefiniowaną przez użytkownika:
$$\Sigma \leftarrow \bigoplus_{\substack{v \in Nbr[u]}} g(D_{u}, D_{u, v}, D_{v})$$
W powyższym równaniu wartości $D_{u}$, $D_{v}$ i $D_{u, v}$ oznaczają odpowiednio wartości i metadane dla wierzchołków $u$, $v$ i krawędzi $(u, v)$. Operacja sumowania zdefiniowana przez użytkownika ($\bigoplus$) musi być komutatywna i asocjacyjna, a jej zakres może obejmować od sumy liczb po sumę zbiorów danych wszystkich sąsiednich wierzchołków i krawędzi.
Faza stosowania: W fazie stosowania wynikowa wartość $\Sigma$ służy do aktualizowania wartości centralnego wierzchołka:
$$D_u^{new} \leftarrow a(D_{u}, \Sigma)$$
Faza punktowa: Na koniec w fazie punktowej nowa wartość centralnego wierzchołka jest wysyłana do wszystkich sąsiednich wierzchołków:
$$\forall v \in Nbr[u]:(D_{(u, v)}) \leftarrow s(D_u^{new}, D_{u, v}, D_{v})$$
Po zakończeniu operacji rozpraszania jedna iteracja obliczenia wierzchołka zostanie ukończona.
Funkcje GAS są wykonywane na zestawie aktywnych wierzchołków w każdej iteracji. Podczas początkowej iteracji wszystkie wierzchołki są umieszczane w zestawie aktywnych wierzchołków. Na podstawie logiki funkcji GAS wierzchołek może oznaczyć jeden z sąsiadujących elementów jako aktywny, aby mógł zostać obliczony podczas kolejnej iteracji.
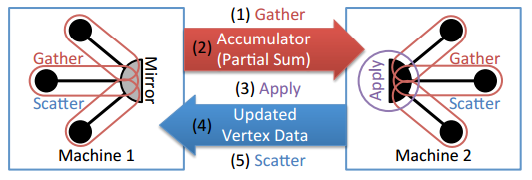
Rysunek 7. Wykonywanie funkcji Zbieraj, Zastosuj, Punktowe na dwóch maszynach, które są podzbiorem krawędzi tego samego wierzchołka.
Rysunek przedstawia wynikowy wzorzec stosowania funkcji GAS na grafie partycjonowanym przy użyciu zachłannego algorytmu cięcia krawędziowego. Funkcje zbierania są uruchamiane lokalnie na każdej maszynie, która zawiera duplikat wierzchołka. Podczas gromadzenia te zebrane wartości są wysyłane do maszyny, na której znajduje się główna kopia wierzchołka, gdzie może zostać obliczona funkcja zdefiniowana na etapie stosowania. Na koniec zaktualizowane dane wierzchołków są kopiowane do wszystkich maszyn, na których znajdują się duplikaty wierzchołka, i wykonywana jest funkcja rozpraszania w celu propagowania wartości do sąsiednich wierzchołków.
Buforowanie różnicowe: istnieją sytuacje, w których program wierzchołka zostanie wyzwolony (aktywny) ze względu na zmianę tylko kilku jego sąsiadów. Wyzwolenie wierzchołka spowoduje wykonanie operacji zbierania ze wszystkich elementów sąsiadujących, z których wiele nie zostało wykonanych, dlatego zwrócą wartości niezmienione względem ostatniego uruchomienia tego wierzchołka. W narzędziu GraphLab wprowadzono subtelną optymalizację nazywaną buforowaniem różnicowym, która polega na tym, że wyniki operacji zbierania ze wszystkich sąsiednich wierzchołków są buforowane w tym wierzchołku. Podczas operacji punktowej uruchamianej na sąsiednich wierzchołkach może zostać wysłany opcjonalny parametr $\Delta a$, podsumowujący zmiany w wartości zmiennej $a$ między iteracjami. Ta wartość może zostać użyta do pominięcia fazy zbierania i dodana do zbuforowanej wartości $a$ w celu przyspieszenia wykonywania.
Odwołania
- Y. Low, J. Gonzalez, A. Kyrola, D. Bickson, C. Guestrin i J. M. Hellerstein (2010). GraphLab: nowa struktura równoległa dla konferencji machine Edukacja na temat niepewności w sztucznej inteligencji (UAI)
- Y. Low, J. Gonzalez, A. Kyrola, D. Bickson, C. Guestrin i J. M. Hellerstein (2012). Distributed GraphLab: struktura dla Edukacja maszynowych i wyszukiwania danych w chmurze PVLDB
- J. Gonzalez, Y. Low, H. Gu, D. Bickson i C. Guestrin (październik 2012 r.). PowerGraph: rozproszone obliczenia równoległe grafu na grafach naturalnych w ramach 10 konferencji USENIX na temat projektowania i implementacji systemów operacyjnych