Wdrażanie aplikacji w chmurze
Po zaprojektowaniu i utworzeniu aplikację w chmurze można przekazać do wdrożenia i wydania jej klientom. Wdrożenie może być procesem wieloetapowym, w którym każdy etap obejmuje serię kontroli, których zadaniem jest zagwarantowanie osiągnięcia celów aplikacji.
Przed wdrożeniem aplikacji w chmurze w środowisku produkcyjnym warto przygotować listę kontrolną ułatwiającą ocenę aplikacji pod kątem niezbędnych i zalecanych najlepszych rozwiązań. W przykładach wykorzystano listę kontrolną wdrożenia platform AWS i Azure. Wielu dostawców usług w chmurze oferuje obszerny zestaw narzędzi i usług, które ułatwiają wdrażanie, np. ten dokument dotyczący platformy Azure.
Proces wdrażania
Wdrożenie aplikacji w chmurze to proces iteracyjny, który zaczyna się po zakończeniu tworzenia i trwa do wydania aplikacji w zasobach produkcyjnych:
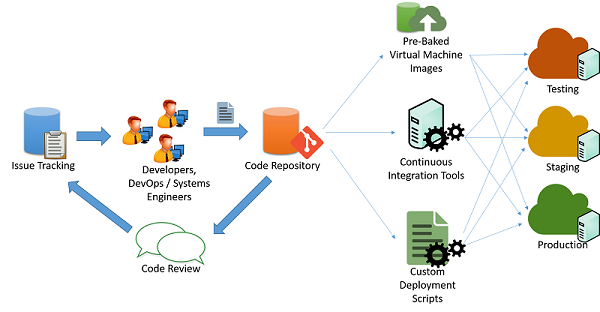
Rysunek 1. Proces wdrażania kodu
Zwykle deweloperzy usług w chmurze utrzymują wiele współbieżnie uruchomionych wersji swoich aplikacji na potrzeby wdrażania w potokach na różnych etapach:
- Testowanie
- Przygotowanie
- Produkcyjne
Najlepiej będzie, jeśli każdy z trzech etapów będzie miał identyczne zasoby i konfigurację. Umożliwi to deweloperom testowanie i wdrażanie aplikacji oraz zminimalizowanie ryzyka niespójności wynikających ze zmian w środowisku i konfiguracji.
Tworzenie potoku zmian w aplikacji
W typowym scenariuszu zwinnego programowania aplikacji (jak to pokazano na poprzednim rysunku) aplikacje są utrzymywane przez zespół inżynierów i deweloperów, którzy pracują nad problemami i usterkami, stosując pewien mechanizm śledzenia problemów. Zmiany w kodzie są zapisywane w systemie repozytorium kodu (np. svn, mercurial lub git), w którym są utrzymywane oddzielne gałęzie do wydania kodu. Po wprowadzeniu zmian w kodzie, jego przeglądach i zatwierdzeniach można utworzyć potok kodu obejmujący testowanie, tworzenie etapów i fazę produkcyjną. Można to zrobić na wiele sposobów:
Skrypty niestandardowe: Deweloperzy mogą używać skryptów niestandardowych do ściągania najnowszej wersji kodu i uruchamiania określonych poleceń w celu skompilowania aplikacji i przełączenia jej do stanu produkcyjnego.
Wstępnie upieczone obrazy maszyn wirtualnych: deweloperzy mogą również aprowizować i konfigurować maszynę wirtualną ze wszystkimi wymaganymi środowiskami i oprogramowaniem w celu wdrożenia aplikacji. Po skonfigurowaniu można wykonać migawki maszyny wirtualnej i wyeksportować ją do obrazu maszyny wirtualnej. Obraz ten można przekazać do różnych systemów orkiestracji w chmurze do automatycznego wdrożenia i konfiguracji na potrzeby wdrożenia produkcyjnego.
Systemy ciągłej integracji: aby uprościć różne zadania związane z wdrażaniem, narzędzia ciągłej integracji (CI) mogą służyć do automatyzowania zadań (takich jak pobieranie najnowszej wersji z repozytorium, tworzenie plików binarnych aplikacji i uruchamianie przypadków testowych), które należy wykonać na różnych maszynach tworzących infrastrukturę produkcyjną. Przykładami popularnych narzędzi CI są Jenkins, Bamboo i Travis. Azure Pipelines to narzędzie CI specyficzne dla platformy Azure zaprojektowane do pracy z wdrożeniami platformy Azure.
Zarządzanie przestojami
Wprowadzenie niektórych zmian w aplikacji może wymagać częściowego lub całkowitego przerwania usług aplikacji, aby umożliwić uwzględnienie zmiany w zapleczu aplikacji. Deweloperzy muszą je zwykle zaplanować na określony czas w ciągu dnia, aby zminimalizować przerwy w działaniu aplikacji. W przypadku aplikacji zaprojektowanych do ciągłej integracji może istnieć możliwość wprowadzenia tych zmian na żywo w systemach produkcyjnych z minimalnymi przerwami w działaniu klientów aplikacji lub bez nich.
Nadmiarowość i odporność na uszkodzenia
Najlepsze rozwiązania w zakresie wdrażania aplikacji zwykle zakładają, że infrastruktura chmury jest efemeryczna i w każdej chwili może stać się niedostępna lub mogą pojawić się w niej zmiany. Na przykład przerwa w pracy maszyn wirtualnych wdrożonych w usłudze IaaS może zostać zaplanowana według uznania dostawcy usług w chmurze, w zależności od typu umowy SLA.
Aplikacje muszą zrezygnować z trwałego kodowania lub uwzględniania statycznych punktów końcowych dla różnych składników, np. baz danych i punktów końcowych magazynu. Dobrze zaprojektowane aplikacje powinny używać interfejsów API usługi do wykonywania zapytań i odnajdywania zasobów oraz łączenia się z nimi w sposób dynamiczny.
Katastrofalne w skutkach awarie związane z zasobami lub łącznością mogą wystąpić nagle. Krytyczne aplikacje należy projektować, przewidując takie awarie oraz uwzględniając nadmiarowość trybu failover.
Wielu dostawców usług w chmurze projektuje swoje centra danych z podziałem na regiony i strefy. Region jest określoną lokalizacją geograficzną, w której znajduje się pełne centrum danych, a strefy są pojedynczymi sekcjami w centrum danych wyizolowanymi w celu zapewnienia odporności na uszkodzenia. Na przykład co najmniej dwie strefy w centrum danych mogą mieć oddzielną infrastrukturę elektryczną, chłodzenia i łączności, aby awaria w jednej strefie nie miała wpływu na infrastrukturę w innej. Informacje o regionie i strefie są zwykle udostępniane przez dostawców usług w chmurze klientom i deweloperom, aby umożliwić projektowanie i programowanie aplikacji, które będą mogły z tej właściwości izolacji korzystać.
Dzięki temu deweloperzy mogą skonfigurować aplikację do używania zasobów w wielu regionach lub strefach w celu zwiększenia jej dostępności i zapewnienia odporności na uszkodzenia, do których może dojść w strefie lub regionie. Ich zadaniem będzie skonfigurowanie systemów, które będą mogły kierować ruchem i równoważyć go w regionach i strefach. Również serwery DNS można skonfigurować tak, aby odpowiadały na żądania wyszukiwania domeny do określonych adresów IP w każdej strefie, w zależności od tego, skąd pochodzi żądanie. Jest to metoda równoważenia obciążenia w oparciu o geograficzne sąsiedztwo klientów.
Bezpieczeństwo i ograniczanie funkcjonalności w środowisku produkcyjnym
Uruchamianie aplikacji internetowych w chmurze publicznej musi odbywać się z zachowaniem zasad ostrożności. Ponieważ zakresy adresów IP w chmurze to dobrze znane lokalizacje dla elementów docelowych o dużej wartości, ważne jest, aby zagwarantować, że wszystkie aplikacje wdrożone w chmurze będą stosować najlepsze rozwiązania w zakresie zabezpieczania i ograniczania funkcjonalności punktów końcowych i interfejsów. Należy przestrzegać pewnych podstawowych zasad:
- Wszystkie programy należy przełączyć w tryb produkcyjny. Większość programów obsługuje „tryb debugowania” na potrzeby testowania lokalnego i „tryb produkcyjny” na potrzeby rzeczywistych wdrożeń. W aplikacjach w trybie debugowania zwykle dochodzi do przecieku dużych ilości informacji na rzecz atakujących, którzy wysyłają źle sformułowane dane wejściowe, a tym samym udostępniają łatwe źródło rozpoznania hakerom. Niezależnie od tego, czy używasz struktury sieci Web, np. Django lub Rails, czy bazy danych, np. Oracle, ważne jest przestrzeganie odpowiednich wytycznych dotyczących wdrażania aplikacji produkcyjnych.
- Dostęp do usług niepublicznych powinien być ograniczony do określonych wewnętrznych adresów IP na potrzeby dostępu administratora. Upewnij się, że administratorzy nie mogą bezpośrednio zalogować się do krytycznego zasobu z Internetu bez korzystania z wewnętrznego programu Launchpad. Skonfiguruj zapory z użyciem adresu IP i reguł opartych na portach, aby zezwolić na minimalny zestaw wymaganych dostępów, szczególnie za pośrednictwem protokołu SSH i innych narzędzi łączności zdalnej.
- Przestrzegaj reguły najmniejszych uprawnień. Uruchom wszystkie usługi jako użytkownik posiadający jak najmniej uprawnień niezbędnych do wykonania wymaganej roli. Ogranicz użycie informacji logowania administratora do określonych ręcznych logowań przez administratorów systemu, którzy muszą debugować lub konfigurować krytyczne problemy w systemie. Dotyczy to również dostępu do baz danych i paneli administracyjnych. Dostępy powinny być chronione przy użyciu długiej, losowej pary kluczy publiczny-prywatny, a ta para kluczy powinna być bezpiecznie przechowywana w ograniczonej i zaszyfrowanej lokalizacji. Wszystkie hasła powinny podlegać rygorystycznym wymaganiom dotyczącym siły.
- Korzystaj z dobrze znanych technik i narzędzi, np. systemów wykrywania włamań i zapobiegania im (systemy wykrywania nieautoryzowanego dostępu/adresy IP), zarządzania informacjami i zdarzeniami zabezpieczeń (SIEM), zapór warstwy aplikacji oraz systemów chroniących przed złośliwym oprogramowaniem.
- Skonfiguruj harmonogram stosowania poprawek zgodny z wersjami poprawek dostawcy używanych systemów. Często dostawcy, np. firma Microsoft, mają dla poprawek stały cykl wydawniczy.