Skalowanie zasobów
- 11 min
Jedną z ważnych zalet chmury jest możliwość skalowania zasobów w systemie na żądanie. Skalowanie w górę (aprowizacja większych zasobów) lub zwiększanie skali w poziomie (aprowizacja dodatkowych zasobów) może pomóc w zmniejszeniu obciążenia pojedynczych zasobów przez zmniejszenie wykorzystania w wyniku zwiększenia pojemności lub szerszej dystrybucji obciążenia.
Skalowanie może pomóc w poprawieniu wydajności przez zwiększenie przepływności, ponieważ można teraz obsłużyć większą liczbę żądań. Może również pomóc w zmniejszeniu opóźnienia podczas szczytowych obciążeń, ponieważ podczas szczytowych obciążeń pojedynczego zasobu w kolejce jest umieszczana zmniejszona liczba żądań. Ponadto może to pomóc w zwiększeniu niezawodności systemu przez ograniczenie wykorzystania zasobów, tak aby jak najbardziej odbiegało ono od punktu przerwania zasobu.
Należy pamiętać, że chociaż chmura pozwala na łatwą aprowizację nowszych lub lepszych zasobów, koszt jest zawsze przeciwieństwem czynnika, który należy wziąć pod uwagę. W związku z tym, mimo że skalowanie w górę lub zwiększanie skali w poziomie jest korzystne, ważne jest również, aby rozpoznać, kiedy skalować w dół lub zmniejszać skalę w poziomie, aby zmniejszyć koszty. W aplikacji n-warstwowej trzeba również koniecznie określić, gdzie znajdują się wąskie gardła i które warstwy należy skalować – niezależnie od tego, czy jest to warstwa danych czy warstwa serwera.
W skalowaniu zasobów pomaga równoważenie obciążenia (omawiane wcześniej), które ułatwia maskowanie aspektu skalowania systemu przez ukrycie go za spójnym punktem końcowym.
Strategie skalowania
Skalowanie w poziomie (zwiększanie i zmniejszanie skali)
Skalowanie w poziomie jest strategią, w której dodatkowe zasoby są dodawane do systemu lub nadmiarowe zasoby są z niego usuwane. Ten typ skalowania jest korzystny dla warstwy serwera, gdy obciążenie systemu jest niespójne lub nieprzewidywalne. Charakter wahania obciążenia sprawia, że kluczowym elementem jest wydajna aprowizacja odpowiedniej ilości zasobów do obsługi obciążenia przez cały czas.
Czynniki, które sprawiają, że to zadanie jest wyzwaniem, to czas pracy wystąpienia, model cenowy dostawcy usług w chmurze oraz potencjalna utrata dochodu na skutek obniżenia jakości usług (QoS) z powodu braku zwiększania skali w poziomie na czas. Przyjrzyjmy się na przykład następującemu wzorcowi obciążenia:
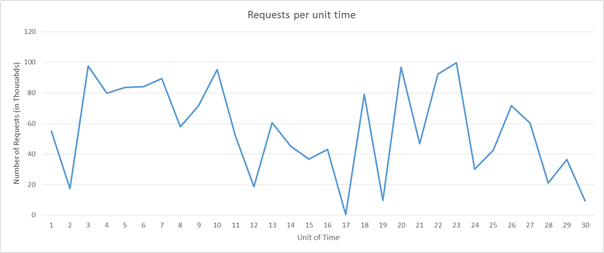
Rysunek 6. Przykładowy wzorzec obciążenia żądania
Wyobraźmy sobie, że używamy platformy Amazon Web Services. Wyobraźmy sobie, że każda jednostka czasu jest równa trzem godzinom rzeczywistego czasu i wymagany jest jeden serwer do obsłużenia 5000 żądań. Jeśli uwzględnimy obciążenie w jednostkach czasu od 16 do 22, w obciążeniu występują ogromne wahania. Możemy wykryć spadek zapotrzebowania w okolicy jednostki czasu 16 i rozpocząć zmniejszanie liczby przydzielonych zasobów. Ponieważ będziemy przechodzić od mniej więcej 50 000 żądań do niemal 0 żądań w ciągu 3 godzin, będziemy mogli zaoszczędzić koszt 10 wystąpień, które byłyby wystawione w jednostce czasu 16.
Teraz z kolei wyobraźmy sobie, że każda jednostka czasu jest równa 20 min. rzeczywistego czasu. W takim przypadku wyłączenie wszystkich zasobów w jednostce czasu 16, aby uruchomić nowe zasoby po 20 min., faktycznie zwiększy koszt, zamiast go zmniejszyć, ponieważ platforma AWS rozlicza każde wystąpienie obliczeniowe co godzinę.
Oprócz powyższych dwóch zagadnień dostawca usług będzie również musiał oszacować straty, które poniesie na skutek zapewnienia obniżonej jakości usług (QoS) w jednostce czasu 20, jeśli ma pojemność tylko na 90 000 żądań, a nie na 100 000.
Skalowanie zależy od charakterystyki ruchu i obciążenia powstałego w usłudze internetowej. Jeśli ruch odbywa się według przewidywalnego wzorca (na przykład na podstawie ludzkiego zachowania, takiego jak oglądanie filmów w streamingu z serwisów internetowych wieczorami), to skalowanie może być predykcyjne, aby utrzymać QoS. Jednak w wielu przypadkach nie można przewidzieć ruchu, a systemy skalowania muszą być reaktywne na podstawie różnych kryteriów, jak pokazano w powyższych przykładach.
Skalowanie w pionie (skalowanie w górę i w dół)
Istnieją pewne rodzaje obciążeń dla dostawców usług, które są bardziej przewidywalne niż inne. Na przykład jeśli na podstawie wzorców historycznych wiesz, że liczba żądań będzie zawsze wynosić 10–15 tys., możesz wygodnie założyć, że jeden serwer, który może obsłużyć 20 tys. żądań, będzie wystarczająco dobry na potrzeby dostawcy usług. Te obciążenia mogą wzrosnąć w przyszłości, ale jeśli będą wzrastać w sposób spójny, usługę można przenieść do większego wystąpienia, które będzie mogło obsłużyć więcej żądań. Jest to odpowiednie rozwiązanie w przypadku małych aplikacji, z którymi jest związany mały ruch.
Skalowanie w pionie wiąże się z wyzwaniem, które polega na tym, że zawsze potrzebny jest czas na przełączenie, który można uznać za przestój. Jest tak, ponieważ podczas przenoszenia wszystkich operacji z mniejszego do większego wystąpienia QoS spada, nawet jeśli czas przełączenia to tylko kilka minut.
Ponadto większość dostawców usług w chmurze oferuje zasoby obliczeniowe zwiększające moc obliczeniową przez podwojenie mocy obliczeniowej zasobu. Dlatego stopień szczegółowości skalowania w górę nie jest tak duży jak w przypadku skalowania w poziomie. Nawet jeśli obciążenie jest przewidywalne i stale rośnie w miarę wzrostu popularności usługi, wielu dostawców usług wybiera skalowanie w poziomie zamiast w pionie.
Zagadnienia dotyczące skalowania
Monitorowanie
Monitorowanie jest jednym z najważniejszych elementów służących do efektywnego skalowania zasobów, ponieważ umożliwia korzystanie z metryk, które mogą służyć do określania części systemu wymagających skalowania i terminu skalowane. Monitorowanie umożliwia analizowanie wzorców ruchu lub wykorzystania zasobów w celu właściwej oceny, kiedy i ile zasobów należy skalować w celu maksymalnego zwiększenia QoS oraz zysków.
Istnieje kilka aspektów zasobów monitorowanych w celu wyzwalania skalowania zasobów. Najbardziej typową metryką jest użycie zasobów. Na przykład usługa monitorowania może śledzić użycie procesora CPU przez każdy węzeł zasobów i skalować zasoby, jeśli użycie jest zbyt duże lub zbyt niskie. Jeśli na przykład użycie dla każdego zasobu jest wyższe niż 95%, warto dodać więcej zasobów, ponieważ system jest mocno obciążony. Dostawcy usług zazwyczaj wyznaczają te punkty wyzwalacza przez analizę punktu przerwania węzłów zasobów, określając, kiedy zaczną kończyć się niepowodzeniem, i mapują zachowanie na różne poziomy obciążenia. Ze względu na koszty ważne jest, aby maksymalnie wykorzystać każdy zasób, jednak zaleca się pozostawienie pewnej ilości miejsca, aby system operacyjny mógł wykonywać działania narzutowe. Podobnie, jeśli wykorzystanie pozostanie na przykład znacznie poniżej 50%, nie wszystkie węzły zasobów mogą być wymagane i można anulować aprowizację niektórych z nich.
W rzeczywistości dostawcy usług zwykle monitorują kombinację kilku różnych metryk węzła zasobu, aby oszacować czas skalowania zasobów. Niektóre z nich obejmują wykorzystanie procesora CPU, użycie pamięci, przepływność i opóźnienie. Na platformie Azure jako dodatkowa usługa jest udostępniane narzędzie Azure Monitor, które może monitorować dowolny zasób platformy Azure i dostarczać takie metryki.
Bezstanowość
Projekt usługi bezstanowej korzysta ze skalowalnej architektury. Usługa bezstanowa oznacza, że żądanie klienta zawiera wszystkie informacje niezbędne do obsługi żądania przez serwer. Serwer nie przechowuje w wystąpieniu żadnych informacji związanych z klientem; w wystąpieniu serwera są przechowywane wszystkie informacje dotyczące sesji.
Usługa bezstanowa pomaga w przełączaniu zasobów w odpowiednim czasie bez żadnej konfiguracji wymaganej do zachowania kontekstu (stanu) połączenia klienta dla kolejnych żądań. Jeśli usługa jest stanowa, skalowanie zasobów wymaga strategii do transferu kontekstu z istniejącej konfiguracji węzłów do nowej konfiguracji węzłów. Istnieją różne techniki wdrażania usług stanowych — na przykład utrzymywanie sieciowej pamięci podręcznej przy użyciu protokołu Memcache, aby można było udostępniać kontekst na różnych serwerach.
Wybieranie elementów do skalowania
W zależności od rodzaju usługi można skalować różne zasoby, w zależności od wymagań. W przypadku warstwy serwera, w miarę wzrostu obciążeń w zależności od typu aplikacji może dojść do zwiększenia rywalizacji o zasoby procesora, pamięci, przepustowości sieci lub wszystkich powyższych. Monitorowanie ruchu pozwala ustalić, który zasób jest ograniczony, i odpowiednio go skalować. Dostawcy usług w chmurze nie muszą koniecznie zapewniać stopnia szczegółowości skalowalności tylko na potrzeby skalowania zasobów obliczeniowych i pamięci, ale udostępniają różne typy wystąpień obliczeniowych, które mogą obsługiwać obciążenia z dużą ilością zasobów obliczeniowych lub pamięci. Na przykład dla aplikacji, której obciążenia intensywnie korzystają z pamięci, lepiej byłoby skalować zasoby w górę do wystąpień zoptymalizowanych pod kątem pamięci. W przypadku aplikacji, które muszą spełniać dużą liczbę żądań niekoniecznie obejmujących dużą ilość zasobów obliczeniowych lub pamięci, zwiększanie skali w poziomie wielu standardowych zasobów obliczeniowych może być lepszą strategią.
Zwiększenie ilości zasobów sprzętowych może nie być najlepszym rozwiązaniem do zwiększenia wydajności usługi. Zwiększenie wydajności algorytmów używanych w usłudze również może pomóc w zmniejszeniu zapotrzebowania na zasoby i poprawić wykorzystanie, eliminując konieczność skalowania zasobów fizycznych.
Skalowanie warstwy danych
W przypadku aplikacji zorientowanych na dane, w których jest wykonywana duża liczba odczytów i zapisów do bazy danych lub systemu magazynowania, obustronny czas dla każdego żądania jest często ograniczony przez czas odczytu i zapisu we/wy na dysku twardym. Większe wystąpienia zapewniają większą wydajność operacji we/wy odczytu i zapisu, co może skrócić czas wyszukiwania na dysku twardym, a to z kolei może spowodować dużą poprawę w zakresie opóźnienia usługi. Posiadanie wielu wystąpień danych w warstwie danych może poprawić niezawodność i dostępność aplikacji przez zapewnienie nadmiarowości trybu failover. Replikowanie danych między wieloma wystąpieniami przynosi dodatkowe korzyści w zakresie zmniejszenia opóźnienia sieci, jeśli klient jest obsługiwany przez centrum danych, które fizycznie znajduje się bliżej tego. Dzielenie na fragmenty lub partycjonowanie danych w wielu zasobach jest kolejną strategią skalowania danych w poziomie, w której zamiast replikacji danych między wieloma wystąpieniami dane są dzielone na kilka partycji i przechowywane na wielu serwerach danych.
Dodatkowym wyzwaniem w przypadku skalowania warstwy danych jest zachowanie spójności (operacja odczytu na wszystkich replikach jest taka sama), dostępność (operacje odczytu i zapisu zawsze kończą się powodzeniem) i tolerancja partycji (gwarantowane właściwości w systemie są zachowywane, gdy awarie uniemożliwiają komunikację między węzłami). Jest to często nazywane twierdzeniem CAP, które określa, że w systemie rozproszonej bazy danych bardzo trudno jest uzyskać w pełni wszystkie trzy właściwości, najczęściej ma dwie z nich. Więcej informacji na temat strategii skalowania bazy danych i twierdzenia CAP znajduje się w dalszych modułach.