Wprowadzenie
W tym module omówimy kilka popularnych magazynów danych NoSQL: Apache HBase, MongoDB i Apache Cassandra.
Jak pamiętamy z wcześniejszego opisu, przejście na bazy danych NoSQL wiązało się głównie z wyzwaniami dotyczącymi dużej ilości danych i skalowalności. Na przykład system BigTable firmy Google został utworzony w celu obsługi rosnących ilości informacji wymagających przetworzenia przez firmę. Wielkość indeksu sieci Web firmy Google wzrosła z 26 000 000 stron w 1998 roku do ponad 1 000 000 000 000 unikatowych adresów URL w 2008 roku. Przetwarzanie tak dużych ilości danych przy użyciu modelu relacyjnego jest uciążliwe, a często niemożliwe. Ponadto w przypadku problemów z dużą ilością danych, jak w przypadku funkcji Web Analytics, nie są wymagane określone ograniczenia i gwarancje dotyczące standardu ACID zapewniane przez systemy zarządzania relacyjnymi bazami danych, ale zamiast tego można korzystać z elastycznego modelu danych, który ogranicza zgodność na rzecz wydajności i skalowalności.
Powiedzenie „Użyj odpowiedniego narzędzia do zadania” jest adekwatne, ponieważ bazy danych NoSQL nie zawsze pasują do konkretnego rodzaju problemu. Bazy danych NoSQL zazwyczaj wyróżniają się zdolnością do zarządzania dużymi ilościami danych, które mogą nie być w pełni uporządkowane (według określonego schematu). Niektóre typy danych mogą być lepiej reprezentowane w jednej z form bazy danych NoSQL, takich jak klucz-wartość, dokument lub grafowa baza danych, a nie w modelu relacyjnej bazy danych. Niektóre bazy danych NoSQL, takie jak Apache Cassandra, obsługują nawet w pełni zagnieżdżony model danych, który pozwala na obecność złożonych struktur danych jako wartości w bazie danych.
Bazy danych NoSQL nie są dobrym wyborem w sytuacjach, w których dane są dość dobrze uporządkowane i zdefiniowane, a ich rozmiar nie przekracza kilku gigabajtów lub terabajtów. Większość baz danych NoSQL działa na dużej liczbie komputerów uporządkowanych w formie klastra w celu równoległego przetwarzania danych. Na przykład jeśli baza HBase lub Cassandra jest uruchamiana w jednym węźle, wydajność może nie dorównywać produktowi MySQL czy innemu systemowi zarządzania relacyjnymi bazami danych.
Dobrym przykładem nierelacyjnej bazy danych, która jest odpowiednia dla baz danych NoSQL, jest tabela WebTable, jak pokazano na poniższej ilustracji. Tabela WebTable jest strukturą danych, która przechowuje wyniki przeszukiwania sieci Web. Przeszukiwanie sieci Web polega na przeszukiwaniu listy stron sieci Web i przechodzenia do ich łączy w celu skatalogowania i poindeksowania informacji zawartych w witrynie sieci Web.
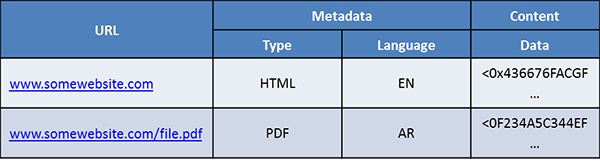
Rysunek 1. Tabela internetowa NoSQL
Każdy unikatowy adres URL w przeszukiwaniu internetowym może być przechowywany jako wiersz w tabeli webtable, a adres URL jest unikatową cechą identyfikującą tego wiersza, co sprawia, że adres URL jest kluczem. Kolumny w tabeli WebTable mogą przechowywać zawartość binarną i metadane adresu URL. W miarę analizowania tabeli WebTable można dodawać nowe kolumny z informacjami semantycznymi pochodzącymi z zawartości HTML, takimi jak łącza do innych stron w obiekcie URL, oraz innymi informacjami. Tabela WebTable może również pełnić rolę zaplecza bazy danych dla usługi archiwum sieci Web, takiej jak archiwum internetowe, dzięki czemu klienci mogą bezpośrednio pobierać obiekty przy użyciu adresu URL jako klucza.
Utworzenie tabeli webtable dla kilku adresów URL może być prostym zadaniem, które może być obsługiwane przez tradycyjne maszyny RDBMS, ale gdy należy przeszukać miliardy witryn internetowych, a ich informacje muszą być przechowywane w tabeli, która może być dostępna przez setki tysięcy klientów jednocześnie, magazyn danych najlepiej jest utrzymywać w dużym klastrze przy użyciu rozwiązania NoSQL.
Magazyn obiektów w chmurze
Magazyn obiektów w chmurze jest ważnym aspektem magazynu w chmurze i jest jedną z najwcześniejszych usług obliczeniowych w chmurze publicznej.
Magazyn obiektów jest szczególnie istotny w usługach sieci Web, ponieważ zawartość statycznej sieci Web (obrazów, wideo i innych plików) można przechowywać w miejscu, które jest łatwo dostępne dla klientów sieci Web. Zapewnia to możliwości zarządzania i złożonego skalowania, nadmiarowość i dostępność systemów magazynowania wyabstrahowanych od dewelopera aplikacji sieci Web, korzystających z prostego interfejsu API w celu przechowywania takich danych i uzyskiwania do nich dostępu. Innym przykładem aplikacji korzystających z usług magazynu obiektów są witryny sieci Web, które udostępniają dużo zawartości wygenerowanej przez użytkownika (na przykład sieci społecznościowe).
Cele szkolenia
Zawartość tego modułu:
- Objaśnienie modeli danych baz danych NoSQL Apache HBase, Apache Cassandra i MongoDB.
- Przedstawienie typowych operacji w bazach danych HBase, Cassandra i MongoDB.
- Podsumowanie architektur baz danych HBase, Cassandra i MongoDB.
- Przedstawienie przypadków użycia baz danych HBase, Cassandra i MongoDB.
- Omówienie modeli danych magazynu obiektów usługi OpenStack Swift w chmurze.
- Omówienie gwarancji spójności dostarczanych w usłudze Swift.
Wymagania wstępne
- Zrozumienie idei przetwarzania w chmurze, w tym modeli usług w chmurze, i zapoznanie się z najpopularniejszymi dostawcami usług w chmurze.
- Znajomość technologii umożliwiających przetwarzanie w chmurze.
- Zrozumienie, jak dostawcy usług w chmurze płacą za korzystanie z chmury oraz pobierają za to opłaty.
- Wiedza o tym, czym są centra danych oraz dlaczego istnieją.
- Wiedza na temat sposobu konfiguracji, zasilania i aprowizacji centrów danych.
- Wiedza na temat sposobu aprowizacji i mierzenia zasobów chmury.
- Znajomość koncepcji wirtualizacji.
- Znajomość różnych typów wirtualizacji.
- Zrozumienie wirtualizacji procesora.
- Zrozumienie wirtualizacji pamięci.
- Zrozumienie wirtualizacji we/wy.
- Znajomość różnych typów danych i sposobów ich przechowywania.
- Znajomość działania rozproszonych systemów plików.