MongoDB
MongoDB to baza danych zorientowana na dokument. W bazie MongoDB zrezygnowano z modelu relacyjnego na rzecz modelu „bez schematu”, który ma być bardziej elastyczny i powinien przypominać sposób, w jaki dane są modelowane w nowoczesnych językach programowania zorientowanego obiektowo. Baza MongoDB jest także zaprojektowana pod kątem skalowalności od podstaw. Może ona automatycznie dzielić dane pomiędzy wiele serwerów i równoważyć obciążenie na serwerach w klastrze. Baza MongoDB umożliwia również wykonywanie złożonych zapytań, na przykład obejmujących agregacje w stylu MapReduce i zapytania przestrzenne, dzięki czemu jest popularnym magazynem danych dla aplikacji powiązanych z mapowaniem. Wideo 4.42 obejmuje bazę danych MongoDB
Model bazy MongoDB
Dokument jest podstawową jednostką danych bazy MongoDB, odpowiadającą w przybliżeniu wierszowi w systemie zarządzania relacyjnej bazy danych. Dokument to uporządkowany zestaw kluczy oraz powiązanych z nimi wartości. Poniżej przedstawiono przykładowy dokument:
{
item: "ABC1",
details: {
model: "14Q3",
manufacturer: "XYZ Company"
},
stock: [ { size: "S", qty: 25 }, { size: "M", qty: 50 } ],
category: "clothing"
}
Baza MongoDB przechowuje dokumenty w grupach nazywanych kolekcjami. Baza MongoDB nie nakłada żadnych ograniczeń na dokumenty, które są częścią kolekcji. Mogą one zawierać dowolną liczbę lub typy kluczy i nie muszą być ze sobą powiązane. Jedynym ograniczeniem jest to, że każdy dokument w kolekcji ma klucz o nazwie _id, który powinien mieć unikalną wartość dla każdego dokumentu w kolekcji. Baza MongoDB może automatycznie generować klucz _id dla każdego dokumentu wstawionego do kolekcji.
Kolekcja jest identyfikowana przez ciąg UTF-8 znany jako nazwa kolekcji. Wielu deweloperów decyduje się grupować kolekcje przy użyciu konwencji nazewnictwa, takich jak używanie znaku . do oznaczania dwóch typów kolekcji blogów: blog.posts i blog.authors. Dotyczą one wyłącznie organizacji, a baza MongoDB traktuje te kolekcje jako oddzielne i niepowiązane.
Wreszcie grupa kolekcji tworzy bazę danych MongoDB. Podobnie jak kolekcje baza danych MongoDB jest identyfikowana za pomocą nazwy ciągu UTF-8.
Baza MongoDB obsługuje bogaty zestaw typów danych, w tym 32-/64-bitowe liczby całkowite, 64-bitowe liczby zmiennoprzecinkowe, wartości logiczne, daty, ciągi, wyrażenia regularne, kod JavaScript, tablice i inne typy danych. Dokumenty mogą być również zagnieżdżone, tzn. dokument może zawierać inne dokumenty, dzięki czemu model danych bazy MongoDB jest w pełni zagnieżdżony.
Wewnętrznie dokumenty są przechowywane w bazie MongoDB przy użyciu formatu o nazwie BSON (Binary JSON). Rozmiar pojedynczego dokumentu w bazie MongoDB jest ograniczony do 4 MB.
Operacje w bazie MongoDB
Głównymi operacjami w programie MongoDB do manipulowania danymi są: wstawianie, usuwanie i aktualizacja. Baza MongoDB umożliwia wstawianie partii, co pozwala aplikacji wstawiać wiele dokumentów w pojedynczym żądaniu. Jedynym ograniczeniem w bazie MongoDB jest rozmiar komunikatu, który wynosi 16 MB. Baza MongoDB obsługuje również specjalny rodzaj operacji, znany jako upsert. Ta operacja powoduje zaktualizowanie istniejącego dokumentu lub wstawienie nowego dokumentu, jeśli dokument do zaktualizowania nie istnieje.
Zapytania na danych w bazie MongoDB wykonuje się za pomocą polecenia find. Korzystając z polecenia „find” z zestawem warunków, można zwrócić dokumenty zgodne z zestawem warunków. Delikatne ograniczenie w bazie MongoDB polega na tym, że warunki użyte w poleceniu „find” muszą być stałą wartością określoną w zapytaniu. Oznacza to, że nie można napisać w bazie MongoDB zapytania, które znajduje dokumenty, w których określona wartość jest zgodna z inną wartością z kolekcji.
Oprócz prostych zapytań baza MongoDB udostępnia zestaw narzędzi agregacji, które można stosować do zestawu wyników dokumentów w zapytaniu. Aby móc głębiej analizować dane zwrócone w wyniku zapytania, można użyć agregacji: od prostych liczników do funkcji MapReduce.
Podobnie jak w przypadku większości systemów baz danych baza MongoDB umożliwia tworzenie indeksów określonych kluczy kolekcji. Pozwala to skrócić czas wykonywania niektórych typów zapytań. Najważniejszą funkcją bazy MongoDB jest możliwość tworzenia indeksów kluczy danych geoprzestrzennych, takich jak szerokość i długość geograficzna. Baza MongoDB może efektywnie obsługiwać zapytania dotyczące danych geograficznych.
Baza MongoDB umożliwia także administratorom żądanie od systemu wyjaśnienia zapytań, podobnie jak w przypadku popularnych systemów zarządzania relacyjnymi bazami danych. Dzięki temu administratorzy mogą analizować i optymalizować wykonywanie zapytań w bazie MongoDB.
Architektura bazy MongoDB
Baza MongoDB zarządza kolekcjami i dokumentami jak plikami w lokalnym systemie plików. Jeśli tworzony jest indeks określonego klucza, baza MongoDB używa struktury drzewa B do przechowywania informacji o indeksie. Baza MongoDB zasadniczo działa na tych plikach na dysku na zasadzie mapowania w pamięci, pozostawiając systemowi operacyjnemu i systemowi plików zadanie zarządzania buforem w pamięci dla plików zawierających dane.
W przypadku małych instalacji baza MongoDB jest wdrażana jako system z pojedynczym węzłem. Aby umożliwić skalowanie bazy MongoDB w wielu węzłach, baza ta obsługuje dwa tryby zwiększania skali w poziomie: replikację i fragmentowanie. W replikacji wiele kopii tych samych danych jest przechowywanych na wielu serwerach, co pozwala bazie MongoDB tolerować awarie węzłów w przypadku, gdy węzeł przestanie działać. Zestaw węzłów MongoDB, który zawiera te same dane, jest określany jako zestaw replik. Jeden węzeł w zestawie replik jest określany jako węzeł podstawowy. Pozostałe węzły są znane jako węzły pomocnicze. Domyślnie tylko węzeł podstawowy odpowiada na żądania odczytu i zapisu od klientów. Węzeł podstawowy wysyła komunikaty, aby zaktualizować repliki zawsze wtedy, gdy jest wykonywana operacja zapisu danych. W tym trybie baza MongoDB gwarantuje ścisłą spójność, ponieważ wszystkie żądania danych są przetwarzane tylko przez węzeł podstawowy.
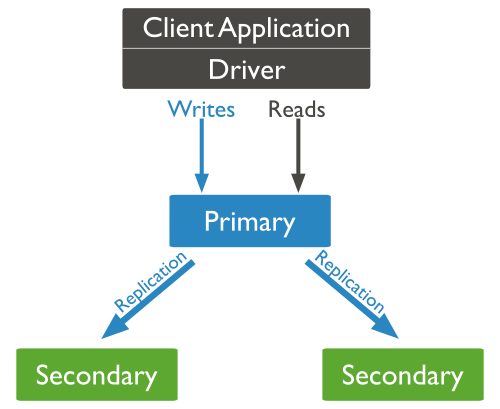
Rysunek 5. Replikacja w bazie danych MongoDB
Zestaw replik bazy MongoDB jest przeznaczony do obsługi automatycznej pracy awaryjnej. Jeśli węzeł nie odpowie przez więcej niż 10 sekund, przyjmuje się, że nie działa, a pozostałe węzły decydują, który z nich powinien być nowym węzłem podstawowym.
Aby można było rozproszyć dane, baza MongoDB umożliwia dzielenie danych na fragmenty między wieloma węzłami. Każdy fragment jest niezależną bazą danych, a poszczególne fragmenty tworzą jedną logiczną bazę danych. Poniżej przedstawiono architekturę podzielonego na fragmenty klastra bazy MongoDB:
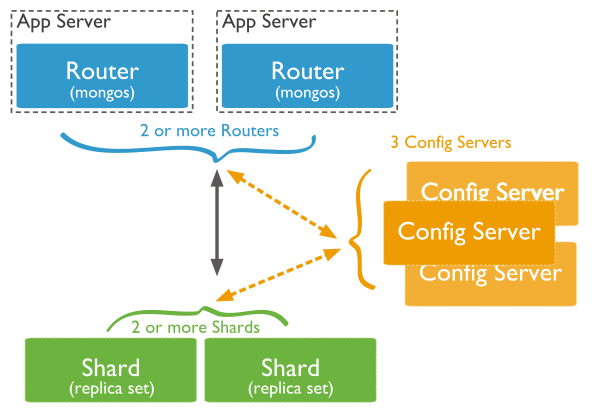
Rysunek 6. Fragmentowanie w bazie danych MongoDB
Fragmenty zawierają dane. Aby zapewnić wysoką dostępność i spójność danych, w środowisku produkcyjnym podzielonym na fragmenty poszczególne fragmenty są zestawami replik.
Routery zapytań komunikują się z aplikacjami klienckimi i operacjami bezpośrednimi na odpowiednich fragmentach. Router zapytań przetwarza operacje i kieruje je do fragmentów, a następnie zwraca wyniki do klientów. Klaster podzielony na fragmenty może zawierać więcej niż jeden router zapytań w celu zapewnienia podziału obciążenia żądaniami klienta. Klient wysyła żądania do jednego routera zapytań. Większość klastrów podzielonych na fragmenty ma wiele routerów zapytań.
Serwery konfiguracji przechowują metadane klastra. Dane te zawierają mapowanie zestawu danych klastra na fragmenty. Router zapytań używa tych metadanych w celu kierowania operacji do określonych fragmentów.
Dane są rozpraszane między wieloma węzłami przy użyciu określonego klucza nazywanego kluczem fragmentowania. Baza MongoDB dzieli wartości klucza fragmentowania na fragmenty i rozdziela je równomiernie na węzły w klastrze. Klucze fragmentowania mogą być oparte na skrótach lub oparte na zakresach. W przypadku fragmentowania opartego na skrótach wartość skrótu klucza fragmentowania służy do przypisywania dokumentu do określonego fragmentu. W przypadku fragmentowania opartego na zakresach każdy fragment jest przypisywany do określonego zakresu wartości klucza fragmentowania, a dokumenty można następnie przypisać do określonego fragmentu.
Baza MongoDB umożliwia administratorom kierowanie zasad równoważenia przy użyciu fragmentowania z tagami. Administratorzy tworzą i kojarzą tagi z zakresami klucza fragmentowania, a następnie przypisują te tagi do fragmentów. Następnie moduł równoważenia migruje otagowane dane do odpowiednich fragmentów i powoduje, że klaster zawsze wymusza dystrybucję danych opisywanych przez tagi.
Przypadki użycia bazy MongoDB
Baz MongoDB można używać w zależności od specyfiki odpowiednich aplikacji:
Duży, szybko rozwijający się zestaw danych: baza MongoDB obsługuje duże ilości danych i ma bardzo elastyczny projekt bez schematu. W przypadku aplikacji, które szybko się zmieniają i wymagają zmian schematu, baza MongoDB może być właściwym wyborem.
Dane oparte na lokalizacji: baza MongoDB jest unikatowa w celu przechowywania i indeksowania danych geoprzestrzennych w wydajny sposób. Z tego powodu baza MongoDB jest szeroko używana przez aplikacje korzystające z danych przestrzennych lub map (takie jak aplikacje do rezerwacji, usługi oparte na lokalizacji itp.).
Aplikacje o dużym obciążeniu zapisu: baza MongoDB ma wbudowaną obsługę operacji wstawiania zbiorczego i obsługuje wysoką szybkość wstawiania, jednocześnie zapewniając swobodne bezpieczeństwo transakcji w porównaniu z systemami RDBMS.
Wysoka dostępność w zawodnym środowisku: architektura bazy danych MongoDB umożliwia niemal natychmiastowe, automatyczne odzyskiwanie po awarii węzła podczas konfigurowania replikacji. Jest to szczególnie przydatne w środowiskach bez gwarancji niezawodności.