Przetwarzanie bezserwerowe
- 6 min
Na wczesnym etapie przetwarzania w chmurze dostawcy usług w chmurze, tacy jak Amazon i Microsoft, koncentrują się na oferowaniu klientom bogatego asortymentu usług IaaS. To przyspieszyło rozwój chmur publicznych przez umożliwienie klientom łatwego przesunięcia obciążeń uruchomionych lokalnie na serwerach fizycznych lub maszynach wirtualnych do maszyn wirtualnych w chmurze. Z usługami IaaS wiąże się odpowiedzialność. Organizacja, która uruchamia maszynę wirtualną w chmurze, zakłada również, że jest odpowiedzialna za utrzymywanie zawartości maszyny wirtualnej — systemu operacyjnego, wymaganych środowisk uruchomieniowych, aplikacji korzystających z tych środowisk uruchomieniowych itp.
Usługa PaaS przenosi część tej odpowiedzialności na dostawcę usług w chmurze i dodatkowo przyspiesza inwestycje w chmurę. Dzięki takim usługom jak AWS Elastic Beanstalk i Azure App Service klienci mogą aprowizować wirtualne serwery internetowe, które są wyposażone w popularne środowiska uruchomieniowe, takie jak Java, Node.js i Microsoft .NET, oraz uruchamiać na nich oprogramowanie w ciągu kilku minut. Maszyny wirtualne wykonują rzeczywiste zadania w tle, jednak obecność tych maszyn wirtualnych jest w dużym stopniu wyabstrahowana. Usługa PaaS umożliwia klientom skoncentrowanie się na aplikacjach, które piszą, aby rozwiązywać problemy biznesowe, a nie poświęcać cykle na zarządzanie maszynami wirtualnymi oraz stosowanie poprawek i aktualizacji platform.
Przetwarzanie bezserwerowe to stosunkowo nowa innowacja w zakresie przetwarzania w chmurze, która posuwa takie abstrakcje jeszcze dalej. Załóżmy, że organizacja pisze i utrzymuje kod, który wykonuje nocne kopie zapasowe danych o kluczowym znaczeniu, wykonuje cotygodniowe przebiegi rozliczeń lub przesyła elektroniczną płatność za każdym razem, gdy faktura zostanie przekazana do magazynu w chmurze. W takim przypadku nadrzędny cel polega na wykonaniu tego kodu i wykonaniu go w odpowiednim czasie. Wszystko inne ma drugorzędne znaczenie, w tym miejsce przechowywania kodu oraz sposób i miejsce wykonywania.
Możesz użyć podejścia IaaS, tworząc co najmniej jedną maszynę wirtualną, aby uruchomić kod i zainstalować wymagane platformy i biblioteki. Możesz aprowizować wystąpienie usługi Elastic Beanstalk lub App Service i hostować w nim kod. Możesz też użyć środowiska uruchomieniowego funkcji, takiego jak AWS Lambda lub Azure Functions, aby wykonać kod w dowolnym momencie bez względu na miejsce lub sposób hostowania go. AwS Lambda i Azure Functions to przykłady przetwarzania bezserwerowego (w szczególności funkcji bezserwerowych), podobnie jak usługa Google Cloud Functions. Wszystkie trzy rozwiązania reprezentują następny krok w naturalnej ewolucji przetwarzania w chmurze od usługi IaaS, w której ponosisz odpowiedzialność za wszystko, do przetwarzania bezserwerowego, w przypadku którego koncentrujesz się na działaniach do wykonania (kodzie do wykonania) w chmurze i dostawca usług w chmurze zarządza pozostałymi elementami.
Funkcje bezserwerowe wykonywane przez środowiska uruchomieniowe funkcji w chmurze są najbardziej typową, ale nie jedyną, formą przetwarzania bezserwerowego. Firmy Amazon, Microsoft i Google oferują bezserwerowe wersje niektórych z innych usług PaaS, w tym bezserwerowych baz danych. Niektórzy dostawcy oferują obsługę przepływów pracy bezserwerowych, które umożliwiają definiowanie przepływów pracy biznesowych w chmurze i wykonywanie ich w odpowiedzi na zdarzenia zewnętrzne, takie jak faktury przekazywane do magazynu w chmurze, czasomierze uruchamiane w określonych odstępach czasu lub wiadomości e-mail uderzające w skrzynkę odbiorczą — często bez konieczności pisania pojedynczego wiersza kodu. Na koniec wiele usług kontenerów oferowanych przez dostawców usług w chmurze, w tym Azure Container Instances i AWS Elastic Container Service, kwalifikują się jako przykłady przetwarzania bezserwerowego, ponieważ umożliwiają uruchamianie kontenerów w chmurze przy wyabstrahowaniu źródłowej infrastruktury.
Zalety przetwarzania bezserwerowego
Przetwarzanie bezserwerowe oferuje trzy podstawowe korzyści dla organizacji korzystających z przetwarzania w chmurze:
Niższe koszty przetwarzania: Klienci zazwyczaj płacą miesięczne opłaty za maszyny wirtualne IaaS i usługi PaaS, takie jak Elastic Beanstalk i Azure App Service. Rozliczanie jest kontynuowane, nawet jeśli usługi są w stanie bezczynności. Większość usług przetwarzania bezserwerowego obsługuje jednak ceny użycia, w których opłaty są naliczane tylko za czas wykonywania kodu. Załóżmy, że używasz maszyny wirtualnej o wartości 100 dolarów na miesiąc do uruchamiania kodu, który wykonuje nocną kopię zapasową danych o kluczowym znaczeniu, oraz że kod jest uruchamiany przez 30 minut każdej nocy. Płacisz 100 dolarów miesięcznie, aby wykonywać kod przez 1/48 miesiąca lub mniej niż jeden dzień. Wdrożenie tego samego kodu jako funkcji bezserwerowej może kosztować zaledwie kilka dolarów miesięcznie. W przypadku cennika za użycie nie płacisz za czas bezczynności.
Automatyczna skalowalność: dostawcy usług w chmurze oferują mechanizmy skalowania usług IaaS w produktach, takich jak skalowanie automatyczne aws i zestawy skalowania maszyn wirtualnych na platformie Azure. Udostępniają oni również opcje ręcznego i automatycznego skalowania dla usług PaaS. Jednak nawet jeśli skalowanie jest wykonywane automatycznie, administrator chmury musi włączyć automatyczne skalowanie i skonfigurować je tak, aby dostawca chmury wiedział, jak i kiedy skalowanie ma się odbywać. Jedną z podstawowych kwestii, które administratorzy muszą wziąć pod uwagę, jest to, że ponieważ płacisz za poszczególne wystąpienia usług IaaS i PaaS, chcesz skonfigurować usługę do skalowania wystarczająco, nie skalując zbyt mocno. Przetwarzanie bezserwerowe umożliwia przezroczyste i automatyczne skalowanie na zewnątrz w celu spełnienia zwiększonego zapotrzebowania oraz skalowanie do wewnątrz w przypadku zmniejszenia zapotrzebowania. Administrator chmury zwykle nie wykonuje żadnych czynności konfiguracyjnych poza włączeniem tej opcji w usłudze. Jeśli w celu wykonania funkcji bezserwerowej otrzymasz 100 żądań, dostawca usług w chmurze sprawdzi, czy żądania mogą być wykonywane równolegle (lub w większości równolegle). Nie ma to wpływu na koszty, ponieważ w przypadku ceny za użycie koszt wykonania funkcji 100 razy jest taki sam bez względu na to, czy wykonywanie jest szeregowe czy równoległe.
Obniżone koszty administracyjne: Bezserwerowa pozwala skupić się na wykonywaniu kodu i przepływów pracy, jednocześnie przenosząc odpowiedzialność za wszystkie inne elementy, w tym utrzymywanie podstawowej platformy, do dostawcy usług w chmurze.
Przetwarzanie bezserwerowe ma także wady. Poniżej wymieniono część ograniczeń, które należy wziąć pod uwagę:
Niektóre środowiska uruchomieniowe funkcji nakładają limit czasu, przez który funkcja może zostać wykonana.
Niektóre środowiska uruchomieniowe funkcji nie gwarantują, że funkcja zostanie wykonana natychmiast, chyba że chcesz zapłacić więcej. W przypadku usługi Azure Functions skonfigurowanej pod kątem cen opartych na użyciu na przykład funkcja może nie zostać wykonana przez maksymalnie 10 minut od momentu jej wyzwolenia. To może nie stanowić problemu w przypadku nocnej kopii zapasowej; prawdopodobnie nie obchodzi cię, czy kopia zapasowa jest uruchamiana o godzinie 1:00, czy o godzinie 1:10. Jednak może to być przeszkodą dla funkcji, które są czasowo krytyczne — funkcji, które muszą być wykonywane w czasie rzeczywistym (lub niemal w czasie rzeczywistym).
Funkcje bezserwerowe zwykle nie są bezstanowe — oznacza to, że nie mogą wewnętrznie przechowywać danych i oczekiwać, że będą one utrwalane między wywołaniami funkcji. Mogą używać zewnętrznych usług magazynu w chmurze, takich jak Amazon S3 i Azure Storage, do utrwalania danych między wywołaniami, ale sprawia to, że kod funkcji jest bardziej złożony.
Niektórzy dostawcy usług w chmurze oferują pomoc techniczną dla funkcji stanowych (na platformie Azure są one nazywane „funkcjami trwałymi”), ale funkcje, które zachowują stan, są stosunkowo nowym dodatkiem do przetwarzania bezserwerowego i nie są obsługiwane uniwersalnie.
Funkcje bezserwerowe
Najbardziej typowym przykładem przetwarzania bezserwerowego są funkcje bezserwerowe. Przekaż kod do chmury i określ, kiedy należy go wykonać. Kod można napisać w różnych językach, w tym Java i C#.
Rysunek 11 przedstawia listę języków programowania obsługiwanych przez funkcje bezserwerowe na platformie Azure oraz w usługach AWS i GCP w momencie tworzenia tego wpisu:
| Język | Azure Functions | AWS Lambda | Google Cloud Functions |
|---|---|---|---|
| C# | x | x | |
| F# | x | ||
| Go | x | x | |
| Java | x | x | |
| JavaScript (Node.js) | x | x | x |
| PowerShell | x | x | |
| Python | x | x | x |
| Ruby | x | ||
| TypeScript | x |
Rysunek 11. Języki programowania obsługiwane przez popularne środowiska uruchomieniowe funkcji bezserwerowych.
Podczas tworzenia funkcji i dostarczenia kodu, który zostanie wykonany, wskazuje się też zewnętrzne zdarzenie, które powoduje uruchomienie funkcji. Popularne platformy w chmurze obsługują wyzwalacze różnych typów, w tym czasomierze, zdarzenia wykonywane w innych usługach w chmurze (takich jak dokument przekazywany do magazynu w chmurze) i wywołania HTTP. Łatwiej jest przekazać kod rozliczeń do środowiska uruchomieniowego funkcji i skonfigurować go do uruchamiania raz dziennie, raz w tygodniu lub raz w miesiącu. Równie prosta jest aktywacja funkcji za każdym razem, gdy faktura jest przekazywana do magazynu w chmurze (na przykład do usługi Amazon S3 lub Azure Storage) albo za każdym razem, gdy wywołanie jest umieszczane w punkcie końcowym REST skojarzonym z funkcją.
Funkcje bezserwerowe są często używane do wykonywania zadań autonomicznych, takich jak nocne kopie zapasowe i rozliczanie. Są one również używane do łączenia innych usług w chmurze i tworzenia zaawansowanych rozwiązań za pomocą usług w chmurze jako bloków konstrukcyjnych. Rysunek 12 przedstawia jedno z takich rozwiązań, które służy do łączenia kilku usług platformy Azure w celu monitorowania aktywności niedźwiedzi polarnych na Arktyce. Funkcja platformy Azure odgrywa kluczową rolę w architekturze przez pobieranie danych wyjściowych z usługi Azure Stream Analytics (wyzwalane przez wywołanie HTTP), pobranie zdjęcia z usługi Azure Blob Storage i przesłanie zdjęcia do modelu wytrenowanego za pomocą usługi Azure Custom Vision Service, która używa sztucznej inteligencji do określenia, czy na zdjęciu jest niedźwiedź polarny. Funkcja jest łącznikiem między usługami Stream Analytics, Blob Storage i Custom Vision Service.
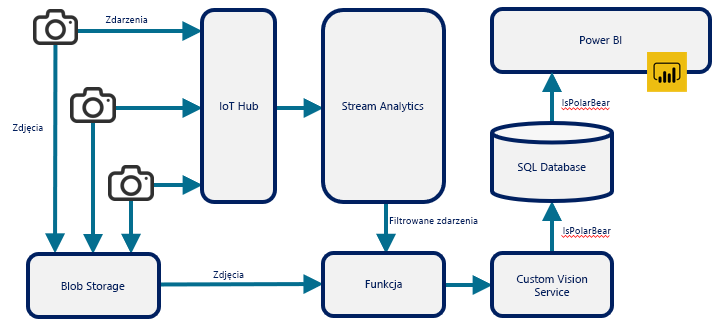
Rysunek 12. Łączenie innych usług platformy Azure przy użyciu funkcji platformy Azure.
Bezserwerowe przepływy pracy
Niektóre usługi przetwarzania bezserwerowego umożliwiają klientom automatyzację biznesowych przepływów pracy bez konieczności pisania kodu. Na przykład usługa Azure Logic Apps udostępnia ponad 100 wbudowanych łączników do komunikacji ze źródłami danych, od baz danych Oracle po usługi mediów społecznościowych, takie jak X. Zapewniają one wyzwalacze do definiowania, kiedy przepływy pracy powinny być wykonywane — na przykład gdy plik zostanie przekazany do Box.com lub coś jest tweetowane z określonym hasztagiem. Udostępniają one również setki wstępnie zdefiniowanych akcji , które definiują, co się stanie, gdy wyzwalacz zostanie wyzwolony i które mogą być połączone w celu utworzenia złożonych przepływów pracy oraz warunków , które umożliwiają warunkowe wykonywanie akcji. Ponadto można je nieskończenie rozszerzać, ponieważ jedną z akcji obsługiwanych przez usługę Azure Logic Apps jest taka, która wywołuje funkcję platformy Azure. Jeśli przepływ pracy obejmuje logikę niestandardową, która nie jest hermetyzowana w akcji, można dostarczyć kod zawierający implementację tej logiki i uwzględniający ją w przepływie pracy tak, jakby był wstępnie zdefiniowaną akcją.
Rysunek 13 przedstawia jeden z takich przepływów pracy w projektancie usługi Azure Logic Apps1. Po nadejściu wiadomości e-mail aplikacja logiki rozpoczyna działanie i sprawdza obecność frazy kluczowej w wierszu tematu wiadomości e-mail i obecność załącznika. W przypadku spełnienia obu warunków aplikacja logiki wywołuje funkcję platformy Azure w celu rozdzielenia kodu HTML od treści wiadomości e-mail. Następnie aplikacja umieszcza oczyszczoną wiadomość e-mail i wszystkie jej załączniki w usłudze Azure Blob Storage oraz wysyła wiadomość e-mail z linkami do odpowiednich dokumentów w usłudze Blob Storage w celu powiadomienia zainteresowanych stron, że informacje są dostępne i oczekują na przegląd. Ten przykład łączy dwa paradygmaty bezserwerowe — aplikację logiki, która wykonuje akcje bez żadnego kodu (przynajmniej nie kodu napisanego przez Ciebie lub każdą osobę w organizacji) oraz funkcję platformy Azure zawierającą kod udostępniony w celu dostosowania przepływu pracy — i jest reprezentatywna dla zmiany wykonywanej w przetwarzaniu w chmurze z maszyn wirtualnych do samodzielnie do abstrakcji wyższego poziomu, które umożliwiają organizacjom skupienie się na rozwiązywaniu problemów biznesowych, a nie zarządzaniu wirtualnymi problemami maszyny i instalowanie i konserwowanie środowisk uruchomieniowych.
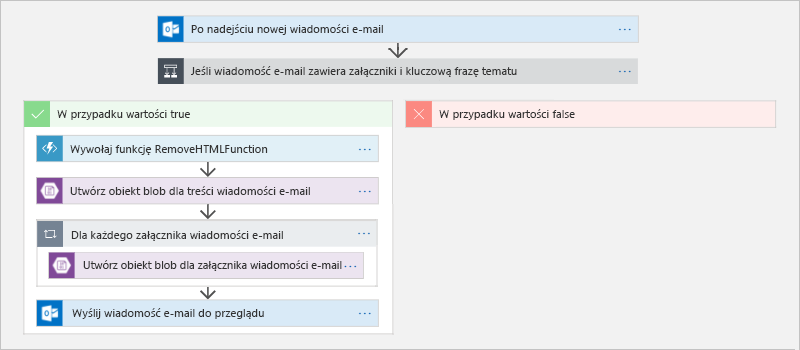
Rysunek 13. Definiowanie przepływu pracy w usłudze Azure Logic Apps.
Firma Amazon oferuje podobną usługę w postaci usługi AWS Step Functions. Usługa Step Functions umożliwia redagowanie wizualnych przepływów pracy, które łączą w sobie inne usługi, takie jak AWS Lambda i AWS ECS. Przepływy pracy obejmują serię kroków, gdzie dane wyjściowe jednego kroku są danymi wejściowymi w następnym kroku. Podobnie jak usługa Azure Logic Apps, usługa AWS Step Functions udostępnia elementy pierwotne na potrzeby rozgałęziania i wykonywania równoległego. W rezultacie biznesowy przepływ pracy staje się diagramem automatu stanów, który jest łatwy w zrozumieniu, wyjaśnieniu innym osobom i modyfikowaniu.
Bezserwerowe bazy danych
Na wczesnym etapie przetwarzania w chmurze hostowanie bazy danych w chmurze oznaczało aprowizację maszyny wirtualnej i zainstalowanie produktu bazy danych, takiego jak MySQL, PostgreSQL lub SQL Server. Usługi PaaS zmieniły to przez oferowanie baz danych jako usługi. Na przykład w przypadku usługi Azure SQL Database lub usługi Amazon Relational Database Service (RDS) wystarczy aprowizować wystąpienie i w ciągu kilku minut uzyskać bazę danych hostowaną w chmurze, która jest gotowa do obsługi klientów. Dodatkowo dostawca usług w chmurze utrzymuje aktualną platformę bazy danych przez stosowanie aktualizacji oprogramowania i poprawek.
Nowszą innowacją w zakresie przetwarzania w chmurze są bezserwerowe bazy danych, które oferują zoptymalizowany model stosunku ceny do wydajności, idealny w przypadku pojedynczych baz danych z nieregularnymi wzorcami użycia. Na przykład platforma Azure oferuje bezserwerową wersję usługi Azure SQL Database. W przypadku głównej wersji usługi Azure SQL Database możesz wybrać warstwę ceny i wydajności na podstawie maksymalnego obciążenia, które ma zostać obsłużone przez bazę danych. Jeśli obciążenia są skokowe lub sporadyczne, często płacisz za bazę danych tak, jakby miała duże obciążenie przez cały czas.
Bezserwerowa wersja usługi Azure SQL Database zmniejsza to ryzyko przez skalowanie bazy danych w razie potrzeby obsługi obciążeń z kosztami opartymi na sumie kosztów obliczeń i kosztów magazynowania. Podobnie jak w przypadku funkcji bezserwerowych używających modelu użycia, płacisz tylko za to, czego używasz. Firma Amazon oferuje podobną usługę w postaci usługi AWS Aurora Serverless, która jest bezserwerową wersją usługi bazy danych Aurora firmy Amazon, a firma Google oferuje klientom bezserwerową usługę bazy danych NoSQL znaną jako Google Cloud Firestore.
Informacje
- Microsoft (2019). Automatyzowanie obsługi wiadomości e-mail i załączników za pomocą usługi Azure Logic Apps. https://learn.microsoft.com/azure/logic-apps/tutorial-process-email-attachments-workflow.