Omówienie danych
Dane są po prostu kolekcją nieprzetworzonych faktów i cyfr. Aplikacje odpowiadają za generowanie, przechowywanie, analizowanie i zużywanie danych lub pewne kombinacje tych działań.
Charakter i właściwości danych mają zwykle wpływ na projekt i wdrożenie systemów magazynowania. Niektóre właściwości obejmują wolumin, zawartość oraz częstotliwość dostępu do danych. Przykładowo serwis Facebook2 niedawno zbadał wzorce dostępu do obrazów i zawartości wideo opublikowanych przez jego użytkowników. Stwierdzono, że częstotliwość dostępu zmniejsza się wykładniczo w miarę upływu czasu. Serwis Facebook wykorzystał te wnioski w celu zaprojektowania i wdrożenia systemu magazynowania specyficznego dla swoich potrzeb. Poniższy film wideo przedstawia rozmaite właściwości danych, które mają wpływ na projekty systemów magazynowania.
Struktura danych
Dane można klasyfikować przy użyciu ich dynamiki i struktury. Dane można ogólnie podzielić na jedną z czterech ćwiartek przedstawionych na poniższym rysunku. Jedna kategoryzacja reprezentuje strukturę danych, uważanych za ustrukturyzowane lub nieustrukturyzowane.
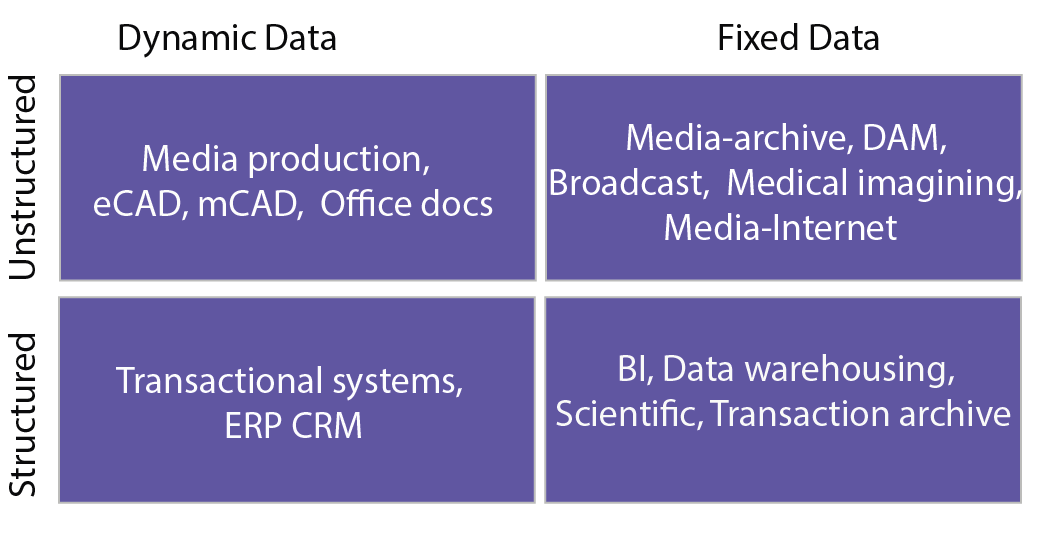
Rysunek 1. Dzielenie danych na różne typy3
Dane ustrukturyzowane mają wstępnie zdefiniowany model danych, który organizuje je w postaci stosunkowo prostej do przetworzenia, przechowywania, pobierania i zarządzania. Dane ustrukturyzowane to zazwyczaj małe dane, które w naturalny sposób pasują do formy tabelarycznej. Mogą więc być łatwo przechowywane w tradycyjnych bazach danych (np. relacyjnych bazach danych). Przykładem danych ustrukturyzowanych są informacje kontaktowe klientów, które są przechowywane w tabelach w bazie danych zarządzania relacjami z klientami (CRM). Dane te wpisują się w dość sztywny model (nazywanego schematem w relacyjnych bazach danych), do którego można szybko uzyskiwać dostęp, a także go przechowywać i nim manipulować.
Dane nieustrukturyzowane natomiast nie muszą mieć wstępnie zdefiniowanego sztywnego modelu organizacyjnego. Dane nieustrukturyzowane mogą być większe i mogą nie pasować naturalnie do formy tabelarycznej, co sprawia, że dane nie nadają się do magazynowania w relacyjnej bazie danych. W związku z tym dane nieustrukturyzowane mogą być stosunkowo trudne do zorganizowania w postaci, która będzie prosta do przetwarzania, przechowywania, pobierania i zarządzania. Przykłady danych nieustrukturyzowanych obejmują płaskie pliki binarne zawierające informacje tekstowe, wideo lub audio. Należy pamiętać, że dane bez nieustrukturyzowane nie są koniecznie pozbawione struktury — dokument albo plik wideo lub audio może mieć strukturę kodowania plików lub metadane, z którymi jest powiązany. W związku z tym dane z pewną strukturą mogą nadal być scharakteryzowane jako nieustrukturyzowane, jeśli ich struktura nie jest pomocna w zadaniu przetwarzania, do którego są potrzebne. Aby to zilustrować, duża pamięć podręczna dokumentów tekstowych (które są nieustrukturyzowane) jest trudna do zindeksowania i wyszukiwania w porównaniu z relacyjną bazą danych zawierającą informacje o klientach (która jest ustrukturyzowana). Na potrzeby tego kursu dane nieustrukturyzowane można zdefiniować jako dane, które nie mieszczą się naturalnie w relacyjnej bazie danych. Ponadto niektóre dane mogą być traktowane jako nieustrukturyzowane (nieprzechowywane w bazie danych), ponieważ będą dostępne przy użyciu nieprzewidywalnych wzorców dostępu. Tradycyjne optymalizacje baz danych są bezcelowe w przypadku takich danych.
Istnieje typ danych pomiędzy danymi ustrukturyzowanymi a nieustrukturyzowanymi, nazywany danymi częściowo ustrukturyzowanymi. Dane częściowo ustrukturyzowane nie są zgodne z formalną strukturą modeli danych skojarzonych z relacyjnymi bazami danych ani innymi formami tabel danych, ale pomimo tego zawierają tagi lub inne znaczniki w celu oddzielenia elementów semantycznych oraz wymuszania hierarchii rekordów i pól w danych. Dane, które są opisane przy użyciu języków znaczników — w tym strony sieci Web, dane strumienia kliknięć oraz obiekty sieci Web — są przykładami danych częściowo ustrukturyzowanych. XML i JSON to klasyczne przykłady reprezentacji danych częściowo ustrukturyzowanych, ponieważ wykorzystują wbudowane tagi opisujące również dane.
Dynamika danych
Kolejną charakterystyką jest dynamika danych, która jest wskaźnikiem, jak często się zmieniają. Dane dynamiczne, takie jak dokumenty pakietu Microsoft Office czy wpisy dotyczące transakcji w finansowej bazie danych, zmieniają się stosunkowo często, natomiast utworzone dane stałe nie mogą być zmieniane. Przykłady danych stałe obejmują dane medyczne z obrazowania MRI lub CT oraz zarchiwizowane w bibliotece wideo wyemitowane materiały wideo.
Segmentacja danych na jedną z tych ćwiartek ułatwia projektowanie i opracowywanie rozwiązań do magazynowania danych. Dane ustrukturyzowane są zwykle przetwarzane przy użyciu relacyjnych baz danych, w których dane są dostępne, zarządzane i manipulowane przy użyciu precyzyjnych poleceń (typowo wydawanych w języku zapytań, np. SQL). Dane nieustrukturyzowane mogą być przechowywane w plikach prostych w systemie plików lub mogą być dalej organizowane z wykorzystaniem bazy danych NoSQL (więcej informacji na temat NoSQL znajduje się w dalszej części modułu).
Struktura i dynamika danych zapewniają wskazówki dotyczące sposobu tworzenia architektury systemu magazynu. Duże ilości danych, które są stosunkowo statyczne, mogą być przechowywane w macierzach dyskowych, jeśli są często odczytywane. Systemy magazynów zaprojektowane z zastosowaniem wielowarstwowej architektury buforowania poprawiają wydajność operacji odczytu na takich danych.
Niektóre typy systemów plików, takie jak wcześniejsze wersje rozproszonego systemu plików Hadoop (HDFS), są przeznaczone dla relatywnie statycznych danych. Umożliwiają zapisanie plików tylko raz. Zapisanego pliku nie można modyfikować. Dane statyczne, takie jak obrazy dysków czy migawki do kopii zapasowych, można archiwizować w stosunkowo niedrogich systemach magazynowania offline, jeśli nie muszą być często dostępne.
Podsumowując, przed wybraniem odpowiedniej architektury magazynu należy rozważyć charakter danych, które będą w nim używane.
Stopień szczegółowości i wolumin danych
Poza typem danych należy wziąć pod uwagę wolumin danych, które muszą być przechowywane i przetwarzane na potrzeby określonej aplikacji. Wolumin danych jest charakteryzowany w dwóch wymiarach — całkowitym rozmiarze danych (wolumin łączny) oraz rozmiarze użytecznego segmentu danych (stopień szczegółowości danych). Przykładowo rozważmy przypadek witryny internetowej do udostępniania zdjęć, która ma miliony użytkowników dodających dziesiątki zdjęć. Łączny rozmiar danych może wynosić dziesiątki lub setki terabajtów, a nawet petabajtów, ale średnio zdjęcie może zajmować tylko kilka megabajtów. Można to zestawić z witryną taką jak YouTube, gdzie łączny rozmiar wszystkich filmów wideo w witrynie to wiele petabajtów, a rozmiar jednego filmu wideo może wynosić od kilkuset megabajtów do nawet gigabajtów.
W związku z tym omówimy często używany termin opisywania dużych ilości danych: dane big data. Istnieje wiele wyjaśnień danych big data, ale jedna najpopularniejszych definicji podsumowuje je jako dane, które są zbyt duże, aby były obsługiwane przy użyciu konwencjonalnych technik.
Szybki rozwój technologii informacji i komunikacji (ICT), która wnika we wszystkie aspekty współczesnego życia, spowodował ogromną eksplozję danych w ciągu ostatnich kilku dekad. Duże postępy w zakresie łączności i cyfryzacji informacji spowodowały, że każdego dnia tworzonych jest coraz więcej danych. Dane te są różne — od obrazów i filmów wideo z telefonów komórkowych przesyłanych do takich witryn jak Facebook czy YouTube, po całodobowe transmisje telewizji cyfrowej, materiały z wideomonitoringu z setek tysięcy kamer zabezpieczających czy duże eksperymenty naukowe, takie jak wielki zderzacz hadronów. Wszystkie te czynności każdego dnia tworzą wiele terabajtów danych. Najnowsze badanie Digital Universe przeprowadzone przez firmę International Data Corporation (IDC) przewiduje 300-krotny wzrost ilości danych tworzonych globalnie, od 130 eksabajtów (1028) w 2012 roku do 30 000 eksabajtowej w 2020 roku.
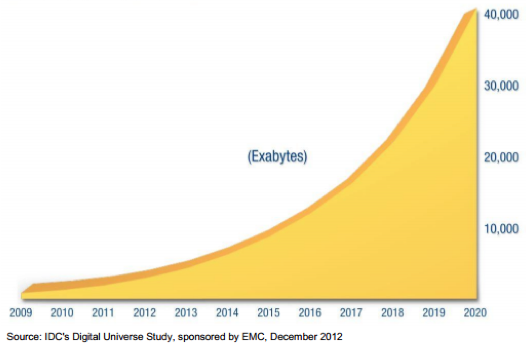
Rysunek 2. Przewidywano wzrost danych z 2009 r. do 20201
Organizacje próbują wykorzystywać lub obsługiwać ogromne ilości danych, które są generowane w coraz większym tempie. Firmy Microsoft, Google, Yahoo i Facebook przeszły z przetwarzania gigabajtów i terabajtów w zakres petabajtów. Wywołuje to ogromny nacisk na ich infrastruktury obliczeniowe, które muszą być dostępne przez całą dobę i muszą być płynnie skalowane w miarę wykładniczego wzrostu ilości tworzonych danych. Są to wyzwania, na które muszą reagować obecne i przyszłe technologie magazynowania.
Odwołania
- John Gantz i David Reinsel (2012 r.). Świat cyfrowy — raport IDC z 2020 roku
- Subramanian Muralidhar, Wyatt Lloyd, Sabyasachi Roy, Cory Hill, Ernest Lin, Weiwen Liu, Satadru Pan, Shiva Shankar, Viswanath Sivakumar, Linpeng Tang i Sanjeev Kumar (2014). f4: Ciepły system magazynowania obiektów blob w serwisie Facebook 11 sympozjum USENIX na temat projektowania i implementacji systemów operacyjnych (OSDI 14) 383-398 USENIX Association
- Thomas Rivera (2012 r.). Samouczek SNIA dotyczący ewolucji systemów plików