Abstrakcje magazynu
Na fundamentalnym poziomie dane są przechowywane na niektórych nośnikach (takich jak nośniki magnetyczne lub półprzewodnikowe) w kodowaniu binarnym. Wyzwaniem jest systematyczna organizacja danych w sposoby, które jest dostępne dla użytkowników i aplikacji. Te systemy organizacji zapewniają abstrakcję dla użytkowników i aplikacji w postaci plików w systemie plików lub jednostek w bazie danych.
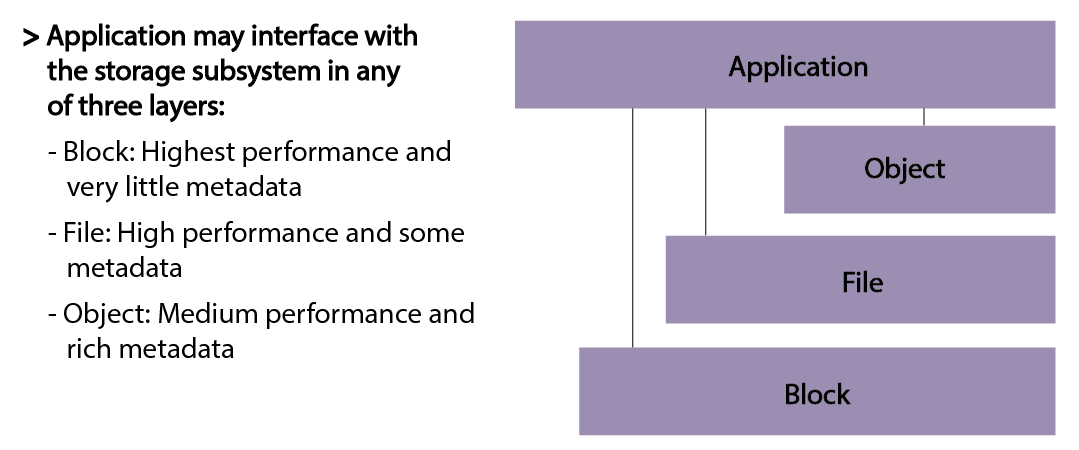
Rysunek 6. Różne warstwy abstrakcji danych
Należy pamiętać, że aplikacje mogą wchodzić w interakcje z dowolną warstwą abstrakcji, w tym z poziomem bloku (rzadko dla programów niesystemowych). Urządzenia blokowe zapewniają najwyższą wydajność, ale mają najmniejszą liczbę metadanych, co bardzo utrudnia pisanie programów przy użyciu tej warstwy. Wiele aplikacji wchodzi w interakcje z systemem plików, a w przypadku aplikacji wymagających większej liczby metadanych systemy baz danych mogą oferować lepszą i bardziej wydajną abstrakcję do zarządzania danymi.
Urządzenia blokowe
Na poprzednich stronach omówiono różne typy danych i urządzeń do magazynowania. Pomimo że dane zawsze będą przechowywane w różnych pamięciach podręcznych w celu zwiększenia wydajności, ostatecznie należy je przechowywać na nośnikach trwałych (czasami nazywanych nieulotnymi), takich jak dyski magnetyczne czy dyski SSD. Ponieważ te urządzenia zazwyczaj mają nietrywialną architekturę i układ, interfejs przedstawiony w systemie operacyjnym jest ogólnym urządzeniem blokowym.
Blok jest po prostu kolekcją bajtów. Rozmiar bloku wskazuje, ile bajtów znajduje się w tym bloku, np. 512 B, 64 kB lub 1 MB. Rozmiary bloków są zwykle reprezentowane jako potęgi cyfry 2. Pojedynczy blok to najmniejsza jednostka, jaką można zaadresować, więc wszystkie bajty w bloku muszą być odczytywane lub zapisywane w tym samym czasie. Jest to podobne do sposobu, w jaki sposób procesor uzyskuje dostęp do pamięci w słowach (32 bitów lub 64 bitów). Jeśli chcesz zmodyfikować pojedynczy bajt danych w rejestrach lub pamięci głównej podczas wykonywania instrukcji procesora, musisz odczytać 8 bajtów (w przypadku procesora 64-bitowego), zmodyfikować 1 bajt, a następnie zapisać nowe słowo (1 nowy bajt + 7 bajtów oryginalnych) z powrotem do pamięci. Ten proces jest wzmacniany blokami. W związku z tym aplikacja, która modyfikuje pojedynczy bajt, wymaga odczytu, powiedzmy, 512 bajtów, modyfikacji 1 bajtu, a następnie zapisania z powrotem 512 bajtów. Jest to rzadki przypadek, ponieważ aplikacje zwykle odczytują wiele ciągłych bloków jednocześnie i mogą być buforowane w hierarchii pamięci.
Urządzenie blokowe zapewnia dostęp systemu operacyjnego do bloków za pośrednictwem interfejsu. W praktyce urządzenia blokowe mogą być fizyczne lub wirtualne oraz lokalne lub zdalne. Poniżej przedstawiono taksonomię urządzeń blokowych, łącznie z przykładami:
| Lokalny | Zdalnie | System magazynowania |
|---|---|---|
| Fizyczne | Wewnętrzne: HDD, SSD, optyczne, stacje taśm. Zewnętrzny: magazyn dołączany bezpośrednio (DAS), dyski wymienne (USB, FireWire, eSATA) | SAN (z mapowaniem jeden do jednego) |
| Wirtualne | Programowe urządzenia blokowe: dyski wirtualne (VHD, VDI, VMDK, CDROM itp.), RAMDisk | SAN (z alokowaniem elastycznym, deduplikacją). DRBD, blokowanie usług urządzeń: Amazon EBS |
Fizyczne urządzenia magazynujące są zgodne z precyzyjnym mapowaniem bloków magazynu fizycznego do bloków widocznych w systemie operacyjnym. Urządzenia wirtualne wydobywają szczegóły fizycznego urządzenia blokowego z systemu operacyjnego i przedstawiają w systemie operacyjnym wirtualne urządzenie blokowe.
Magazyn lokalny odnosi się do urządzeń blokowych podłączonych bezpośrednio do komputera. Mogą to być urządzenia wewnętrzne (połączone za pośrednictwem interfejsów SCSI lub ATA) lub zewnętrzne (połączone przez USB, FireWire, eSATA itp.). Magazyn zdalny to magazyn, który nie jest podłączony bezpośrednio do komputera, ale jest dostępny za pośrednictwem sieci (przy użyciu protokołów takich jak Fibre Channel czy iSCSI).
Lokalne dla komputera fizyczne urządzenia blokowe obejmują typowe przykłady dysków twardych, dysków optycznych oraz stacji taśm, które są bezpośrednio połączone za pomocą interfejsu wewnętrznego lub zewnętrznego. Najlepszym przykładem fizycznego urządzenia blokowego, które jest połączone zewnętrznie z komputerem, jest sieć magazynowania z precyzyjnym mapowaniem między blokami przydzielonymi w sieci SAN a blokami dostępnymi w systemie operacyjnym.
Urządzenia bloku wirtualnego, które są lokalne dla komputera, obejmują wszelkie urządzenia blokowe reprezentowane jako plik. Przykłady obejmują dysk maszyny wirtualnej (VMDK, format dysku wirtualnego VMware), obraz dysku wirtualnego (VDI, format dysku VirtualBox) oraz wirtualny dysk twardy (VHD).
Zdalnie dostępne wirtualne urządzenia blokowe obejmują sieci SAN, które eksportują urządzenia blokowe, które nie mają relacji jeden do jednego z fizycznie przydzielonymi blokami. Na przykład sieci SAN można alokować elastycznie na serwerze urządzenie blokowe o pojemności 1 TB, ale rzeczywista przestrzeń dyskowa używana w sieci SAN jest dokładną ilością miejsca używanego przez serwer w danej chwili. Gdy system operacyjny zapisuje dodatkowe dane na urządzeniu blokowym, wzrastają alokacje bloków w sieci SAN. Sieci SAN mają również takie funkcje jak deduplikacja, które identyfikują identyczne bloki i zapisują tylko ich jedną kopię.
Systemy plików
Jedną z podstawowych abstrakcji magazynu jest koncepcja plików i systemów plików. Plik, w kontekście magazynu, może być uważany za blok informacji, udostępniany programom komputerowym. System plików jest abstrakcją użytkowników i aplikacji, które obejmują skojarzone struktury danych do przechowywania, pobierania i aktualizowania zestawu plików. System plików zazwyczaj zarządza dostępem do jego danych i metadanych (metadane są informacjami dodatkowymi i parametrami opisującymi pliki). Systemy plików mają liczne obowiązki, od zarządzania wolną przestrzenią, nazewnictwa, zarządzania metadanymi i kontroli dostępu po zachowywanie niezawodności i integralności plików przechowywanych w systemie plików.
Systemy plików można podzielić na wiele typów. Rysunek 7 przedstawia hierarchiczną taksonomię systemów plików zgodnie z definicją stowarzyszenia Storage Networking Industry Association (SNIA).
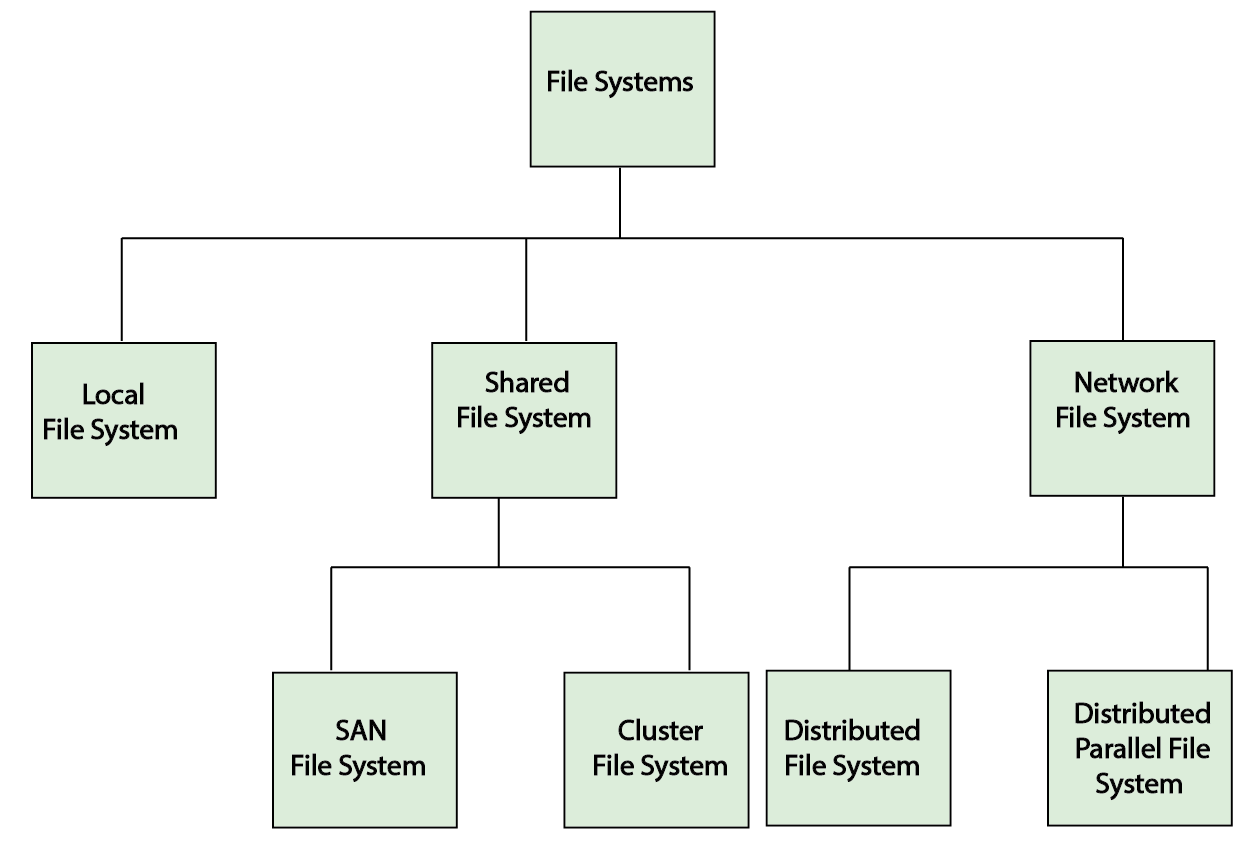
Rysunek 7. Taksonomiasystemu plików 1
W oparciu o architekturę SNIA i wdrożenie systemy plików można ogólnie podzielić na trzy kategorie:
- Lokalne systemy plików: są to systemy plików, które mają być obsługiwane na co najmniej jednym dysku, udzielając dostępu do jednego wystąpienia systemu operacyjnego na urządzeniach magazynujących. Przykłady obejmują systemy FAT, EXT, HFS i ReiserFS.
- Udostępnione systemy plików: są to systemy plików specjalnego przeznaczenia, które umożliwiają łączenie wielu dysków w grupę dostępnych urządzeń blokowych, które mają być współużytkowane przez wiele maszyn w sieci. Przykłady obejmują GPFS i SanFS firmy IBM.
- Sieciowe systemy plików: Systemy plików sieciowych to usługi magazynowania wyższego poziomu oferowane aplikacjom (w przeciwieństwie do zwykłych urządzeń blokowych w lokalnych i udostępnionych systemach plików). Przykłady obejmują systemy plików CIFS i NFS. W tym module omówimy szczegółowo specjalną klasę systemów plików sieciowych nazywanych rozproszonymi systemami plików.
Bazy danych
Kolejną warstwą abstrakcji w systemach magazynowania są bazy danych. Bazy danych są zwykle uruchamiane na systemach plików. Istnieją wystąpienia, w których bazy danych są uruchamiane bezpośrednio na urządzeniach blokowych w celu zwiększenia wydajności, ale zdarzają się rzadko. W niniejszym module dowiemy się, że bazy danych są przeznaczone do przechowywania i pobierania informacji dla aplikacji. Bazy danych mają lepszy wgląd w dane, co czasami pozwala na przeprowadzanie skomplikowanych zapytań i operacji na danych.
Odwołania
- Thomas Rivera (2012 r.). Samouczek SNIA dotyczący ewolucji systemów plików