Lokalne systemy plików
Lokalne systemy plików są łączone z serwerem, na którym działa aplikacja. Ze względu na charakter systemu plików systemy lokalne mają ograniczoną skalowalność i nie zezwalają na udostępnianie danych między różnymi klientami za pośrednictwem sieci:
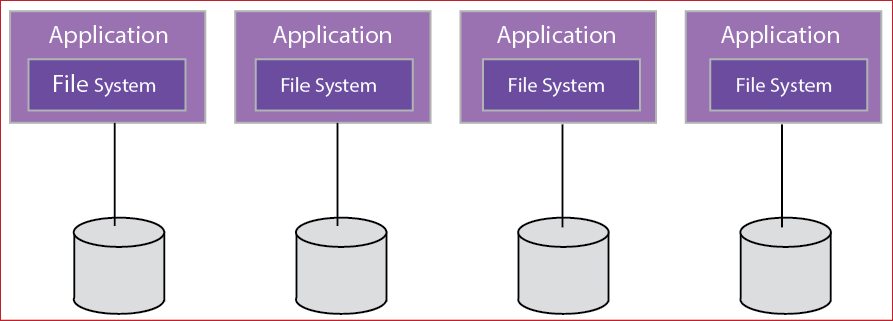
Rysunek 8. Lokalne systemyplików 1
Dane przechowywane na dysku są zwykle reprezentowane jako bloki lub w ciągłej nieustrukturyzowanej kolekcji bajtów. Lokalne systemy plików zapewniają abstrakcję plików, które są po prostu kolekcją bloków reprezentujących plik.
Aplikacje korzystające z lokalnych systemów plików nie zajmują się sposobem, w jaki pliki są fizycznie reprezentowane na nośnikach magazynowania, ilościami danych przesyłanych do lub z aplikacji na żądanie pliku (nazywanymi rozmiarem rekordu) ani jednostką, za pomocą której dane są przesyłane do lub z nośników magazynowania (nazywaną rozmiarem bloku) itd. Wszystkie takie szczegóły niskiego poziomu są zarządzane przez lokalne systemy plików i są skutecznie odseparowywane z aplikacji użytkownika. Z zasady lokalne systemy plików są podstawowym podłożem tworzącym każdy typ systemu plików w chmurze. Na przykład rozproszone systemy plików (np. rozproszony system plików Hadoop, które naśladuje system plików Google)2 i równoległe systemy plików (np. PVFS) są tworzone i wykonywane w wielu wspólnych lokalnych systemach plików. Ponadto skuteczność radzenia sobie maszyny wirtualnej lub fizycznej z awariami oprogramowania i sprzętu w chmurze lub innych systemach zależy od tego, jak dobrze zaprojektowano lokalne systemy plików pod kątem obsługi takich awarii. Krótko mówiąc, praktycznie każdy system plików, niezależnie od tego, czy jest udostępniany czy w sieci, polega na lokalnych systemach plików.

Rysunek 9. Układ systemu plików
System plików UNIX jest klasycznym lokalnym systemem plików, który zaprojektowano w latach 70. XX wieku i był powszechnie używany w wielu formach (FFS, EXT-2 itd.). Pomimo że dane w pliku są dystrybuowane jako szereg bloków na urządzeniu magazynującym, system plików zachowuje abstrakcję pliku wraz ze skojarzonymi z nim danymi. Jak pokazano na powyższym rysunku, podstawowy lokalny system plików zawiera blok rozruchowy, blok nadrzędny, I-listę oraz obszar danych. Blok rozruchowy zawiera program rozruchowy, który odczytuje obraz binarny systemu operacyjnego (OS) do pamięci podczas jego uruchamiania. Blok rozruchowy nie ma więc nic wspólnego żadnymi procesami i funkcjami zarządzania systemem plików. Blok nadrzędny opisuje układ i charakterystykę lokalnego systemu plików, w tym jego rozmiar, rozmiar bloku, liczbę bloków, rozmiar I-listy, lokalizację itp.
Na I-liście hermetyzowany jest stan każdego pliku w formie i-węzła systemu UNIX (węzła indeksu, jak pokazano na poniższym rysunku). I-węzeł działa jako główna struktura danych pliku i przechowuje metadane dotyczące tego pliku, w tym wskaźniki do poszczególnych bloków plików w magazynie, własności i listy kontroli dostępu, sygnaturę czasową ostatniego dostępu do pliku itp.
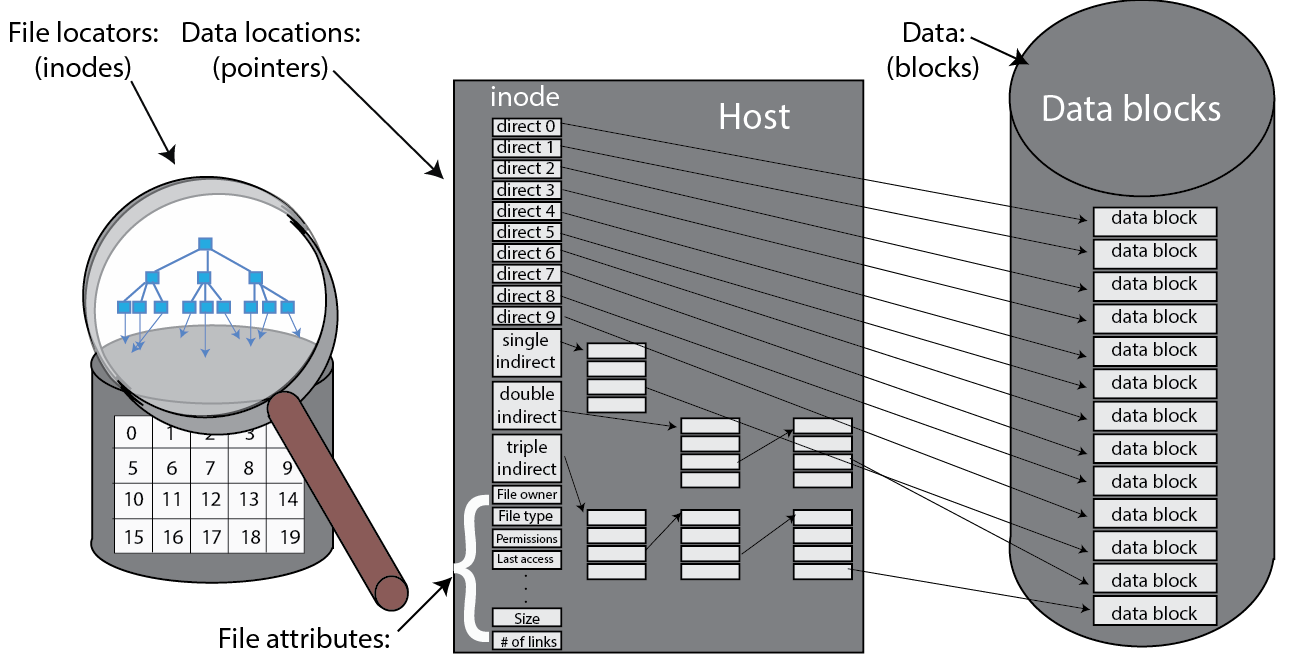
Rysunek 10. Pliki, węzły i bloki1
Przykłady lokalnych systemów plików to NTFS, FAT i EXT. Ograniczenia skalowalności, wydajności i udostępniania lokalnych systemów plików można przezwyciężyć, korzystając z udostępnionych/sieciowych systemów plików.
Standardy we/wy POSIX
Przenośny interfejs systemu operacyjnego (POSIX) to rodzina standardów definiujących interfejsy systemów operacyjnych (OS) w wielu systemach operacyjnych UNIX i podobnych do UNIX. Standardy systemu plików POSIX są często używane do opisywania możliwości oczekiwanych od systemu plików, którego można używać w systemach operacyjnych UNIX i podobnych do UNIX.
POSIX definiuje następujące operacje standardowe na plikach: open, read, write i close. Ponadto standardy POSIX pozwalają na bezpośrednie instalowanie takich systemów plików, w systemach operacyjnych UNIX lub podobnych do UNIX bez konieczności stosowania specjalnego sterownika/procesu klienta w celu zarządzania systemem plików.
System plików na poziomie jądra a na poziomie użytkownika
Systemy plików na poziomie jądra to systemy plików zawierające interfejs API na poziomie jądra. Oznacza to, że kod, który wchodzi w interakcje z systemem plików, znajduje się w jądrze. W systemach operacyjnych UNIX i podobnych do UNIX te interfejsy API są ładowane w postaci modułów. Systemy plików na poziomie jądra w systemach operacyjnych podobnych do UNIX są zwykle zgodne ze standardem POSIX i są zazwyczaj ograniczone do lokalnych systemów plików.
Systemy plików na poziomie użytkownika działają w przestrzeni użytkownika, w przeciwieństwie do przestrzeni jądra. Takie interfejsy systemu plików zapewniają mobilność interfejsu API systemu plików i zezwalają na instalację w o wiele szerszych zestawach klientów. Wiele rozproszonych i sieciowych systemów plików jest przeznaczonych do pracy na poziomie użytkownika z wyjątkiem AFS, które korzystają ze sterownika na poziomie jądra w systemie Linux.
Kwestie do rozważenia podczas projektowania dotyczące lokalnych systemów plików
Aby zrozumieć, jak projektowane są lokalne systemy plików, ważne jest poznanie źródłowego nośnika magazynowania. W tej dyskusji zakładamy, że obracający się dysk jest nośnikiem magazynowania.
Lokalne systemy plików są projektowane tak, aby minimalizować czas wyszukiwania i rotacji po alokacji pojemności dysku na plik w celu zwiększenia wydajności systemu. Lokalne systemy plików mogą również zmaksymalizować transfer przydatnych danych po naliczeniu czasu na wyszukiwanie i rotację. Wydajność jest głównym kryterium projektowania skutecznego lokalnego systemu plików. Nośniki magazynowania, np. dyski czy taśmy magnetyczne, nie zapewniają jednolitych czasów dostępu jako magazyny podstawowe (np. pamięci lub pamięci podręczne). W związku z tym lokalny system plików powinien korzystać w pełni ze źródłowego nośnika magazynowego, aby osiągnąć akceptowalną wydajność systemu i uniknąć niepotrzebnego marnowania przestrzeni. Unikanie niepotrzebnego marnowania przestrzeni jest kluczowe, szczególnie w chmurze, gdzie wykorzystanie zasobów systemowych ma duże znaczenie.
Wydajność
Lokalne systemy plików mogą wykorzystywać różne strategie, aby zwiększyć swoją wydajność. Po pierwsze lokalne systemy plików mogą przechowywać wiele adresów bloku w i-węźle pliku (konkretnie w diskmap). Lokalne systemy plików mogą buforować i-węzły w pamięci, aby zmniejszyć liczbę dostępów do dysku potrzebnych do odczytu/zapisu lokalizacji bloków. Po drugie lokalne systemy plików mogą stosować większe rozmiary bloków w celu zmaksymalizowania transferu przydatnych danych. Po trzecie aby zminimalizować czas wyszukiwania, można wykorzystać lokalność. W szczególności bloki, do których prawdopodobnie będzie uzyskiwany dostęp w najbliższej przyszłości, mogą być przechowywane blisko siebie na dysku. Oznacza to, że bloki każdego pliku muszą być przechowywane tak blisko siebie, jak to możliwe. Ponadto, ponieważ i-węzły są dostępne w połączeniu z ich blokami danych, muszą być przechowywane blisko siebie. Węzły katalogu są często badane jednocześnie (np. ls –la), więc i-węzły i pliki w jednym katalogu powinny być również blisko siebie. Po czwarte, aby zmniejszyć opóźnienie rotacyjne, bloki pliku w cylindrze (jeśli istnieją) powinny być ułożone w taki sposób, że po upływie czasu wyszukiwania mogłyby zostać odczytane bez dalszych opóźnień rotacyjnych. To rozwiązanie zwiększa wydajność, zwłaszcza jeśli bloki są żądane sekwencyjnie. Jeśli jednak bloki są żądane losowo, użycie takiego układu blokowego w cylindrze staje się trudne w celu zminimalizowania opóźnienia rotacyjnego. Na koniec gdy lokalny system plików pobiera żądany blok, może jednocześnie wstępnie pobierać bloki, do których prawdopodobnie będzie uzyskiwany dostęp w najbliższej przyszłości. W rzeczywistości wiele lokalnych systemów plików (np. Ext2 i nowsze wersje) korzysta z strategii opartej na wielu blokach jednocześnie, znanej jako klastrowanie bloków, zgodnie z którym jednocześnie alokowanych jest osiem ciągłych bloków. Bloki mogą być również buforowane lub zapisywane w pamięci podręcznej na potrzeby przyszłych odwołań przez system operacyjny.
Systemy plików były tradycyjnie tworzone w celu optymalizacji wydajności na magnetycznych dyskach twardych. Pomimo tego wiele bieżących systemów plików ma tryby operacyjne przeznaczone dla dysków SSD, które rezygnują z pewnych optymalizacji dostosowanych do dysków, ale wprowadzają nowe funkcje w celu zwiększenia wydajności i zarządzania zużyciem przestrzeni na dyskach SSD.
Niezawodność
Kolejnym ważnym kryterium projektowania skutecznych lokalnych systemów plików jest niezawodność. Jest ona też ważną kwestią do rozważenia w przypadku magazynów w chmurze. Lokalne systemy plików powinny być niezawodne. Oznacza to, że przechowywane dane muszą być dostępne zawsze wtedy, gdy jest to konieczne. W związku z tym dane powinny skutecznie tolerować awarie oprogramowania i sprzętu. Ponadto lokalne systemy plików muszą zapewnić ciągłą spójność przechowywanych danych. Zapisywanie, tworzenie, usuwanie i zmiana nazwy pliku może wymagać wielu operacji dyskowych, które mają wpływ na dane i metadane. Aby upewnić się, że źródłowy lokalny system plików jest odporny na awarie, należy się upewnić, że każda z tych operacji przeprowadzi system z jednego spójnego stanu na inny. Na przykład przeniesienie pliku z jednego katalogu do innego, który obejmuje operacje tworzenia i usuwania, może spowodować niespójny stan systemu plików. Do awarii może dojść podczas przenoszenia pliku, co doprowadzi do zniknięcia pliku w dwóch katalogach — oryginalnym i prognozowanym. Aby uniknąć tego ryzyka, lokalny system plików może najpierw utworzyć plik w prognozowanym katalogu, a następnie go usunąć ze starego katalogu (po zatwierdzeniu pliku w nowym katalogu).
Wieloetapowe operacje systemu plików
Niektóre operacje na plikach mogą wymagać wielu czynności odczytu lub zapisu, znanych jako wieloetapowe operacje systemu plików. Na przykład zapisanie w pliku dużej ilości danych może spowodować wiele oddzielnych operacji dyskowych (które są wspólne w chmurach). Jeśli awaria wystąpi przed zapisaniem wszystkich wymaganych danych, lokalny system plików uzyska stan, w którym zakończona będzie tylko część operacji zapisu. Popularnym podejściem do obsługi wieloetapowych operacji jest użycie transakcji niepodzielnych. Dzięki transakcjom niepodzielnym, jeśli system ulegnie awarii w dowolnym kroku danej operacji wieloetapowej, efekt (prawdopodobnie po niektórych operacjach odzyskiwania) jest taki, jakby operacja została wykonana w całości lub wcale nie miała miejsca. Transakcje są standardowymi akcjami w systemach baz danych i zostały szczegółowo omówione w sekcji baz danych.
Jeden podstawowy schemat wdrażania transakcji niepodzielnych w lokalnych systemach plików jest nazywany tworzeniem dzienników. W tworzeniu dzienników kroki transakcji są najpierw zapisywane na dysku w specjalnym pliku dziennika. Gdy kroki zostaną bezpiecznie zarejestrowane, a operacja zostanie zatwierdzona (tj. całkowicie ukończona), można je zastosować w rzeczywistym systemie plików. Jeśli podczas wykonywania kroków na systemie plików wystąpi awaria, kroki te można łatwo odzyskać z pliku dziennika (przy założeniu, że jest stale chroniony przed awariami). Ta technika jest znana jako ponowne wykonanie lub tworzenie dzienników nowych wartości. Nawet jeśli system ulegnie awarii podczas wykonywania kroków na pliku dziennika, już zarejestrowane kroki w pliku dziennika mogą zostać odrzucone, a sam system plików pozostanie nienaruszony. Tworzenie dzienników gwarantuje, że operacja zostanie wykonana całkowicie lub nie zostanie wykonana wcale.
Rozszerzanie jednego systemu plików na wiele dysków
Aby zwiększyć niezawodność i/lub wydajność, lokalny system plików może być używany na wielu dyskach. W tym filmie wideo omówiono różne techniki używane do rozszerzania systemu plików na wielu dyskach:
Trzy główne powody zwiększania liczby dysków są następujące:
- Uzyskanie większej przestrzeni dyskowej.
- Nadmiarowe przechowywanie danych.
- Rozłożenie bloków na wiele dysków, aby można było uzyskać do nich dostęp równolegle, zwiększając wydajność.
Wiele dysków można w przejrzysty sposób uwidocznić dla lokalnego systemu plików jako pojedynczy dysk, korzystając z tak zwanego menedżera woluminów logicznych (LVM). Jeśli założymy, że mamy dwa dyski, LVM może zapewnić lokalnemu systemowi plików dużą przestrzeń adresową i wewnętrznie zmapować połowę adresów na jeden dysk, a drugą połowę na drugi dysk. Aby zapewnić nadmiarowość, LVM może przechowywać identyczne kopie każdego bloku na każdym z tych dwóch dysków. Wymaga to przeprowadzania operacji odczytu i zapisu przez LVM. Dla każdego zapisu LVM aktualizuje dwie żądane identyczne kopie na dwóch dyskach. Dla każdego odczytu LVM przekazuje żądanie do dysku, który jest mniej zajęty. Ponadto dostęp równoległy z wieloma dyskami można przeprowadzić przy użyciu techniki zwanej rozkładaniem plików. Dzięki rozkładaniu plików, plik jest zielony na wiele jednostek, które są następnie rozkładane na różne dyski, aby umożliwić równoległy dostęp do pliku.
Dane można rozkładać na różne sposoby w zależności od jednostki rozłożenia (poziomu, na którym dane są rozkładane na wielu dyskach). W rozkładaniu na poziomie bloku jednostka rozłożenia jest blokiem danych. Rozmiar bloku danych, nazywanego szerokością rozłożenia, zależy od implementacji, ale jest zawsze co najmniej tak duży, co rozmiar sektora dysku. Gdy pojawi się potrzeba odczytania tych danych sekwencyjnych, wszystkie dyski można odczytać jednocześnie. W przypadku wielozadaniowego systemu operacyjnego istnieje duże prawdopodobieństwo, że nawet niesekwencyjny dostęp do dysku wywoła równoległą pracę wszystkich dysków. W rozkładaniu na poziomie bajtu jednostka rozłożenia wynosi dokładnie jeden bajt. W rozkładaniu na poziomie bitu jednostka rozłożenia wynosi dokładnie jeden bit.
RAID
Zgodnie z opisem w module dotyczącym centrum danych wiele dysków można łączyć w jeden dysk logiczny przy użyciu organizacji RAID. RAID 0 rozkłada dane na poziomie bloku na wielu dyskach bez nadmiarowości. RAID 1 odzwierciedla z dane jednego dysku na innym i zazwyczaj zmniejsza dyspozycyjność macierzy o połowę. RAID 2 zapewnia rozkładanie na poziomie bitu przy użyciu kodów Hamminga przechowywanych na dyskach parzystości. RAID 3 zapewnia rozkładanie na poziomie bajtów z informacjami o parzystości przechowywanych na dedykowanych dyskach parzystości. RAID 4 zapewnia rozkładanie na poziomie bloku z dedykowanymi dyskami parzystości. RAID 5 zapewnia to samo rozkładanie na poziomie bloku co RAID 4 i 1, ale informacje o parzystości są dystrybuowane między wszystkimi dyskami w zestawie. Organizacja RAID 6 jest taka sama co RAID 5, ale z blokami parzystości zapisanymi dwukrotnie, więc RAID 6 może tolerować do dwóch awarii dysku w zestawie. Kombinacje konfiguracji RAID, np. RAID 1 + 0 i RAID 0 + 1, są możliwe do zastosowania, aby uzyskać róże kombinacje wydajności i niezawodności.
Sieci magazynowania
W środowisku IT przedsiębiorstwa magazyn jest zwykle konsolidowany, aby można było z niego korzysta i udostępnić go na wielu serwerach. Urządzenia magazynujące mogą być współużytkowane przez wiele serwerów przy użyciu sieci SAN. SAN to dedykowana sieć, która zapewnia dostęp do skonsolidowanego magazynu danych na poziomie bloku (patrz poniższy rysunek). Skonsolidowany magazyn na poziomie bloku ma zwykle postać macierzy dyskowej. Macierz dyskową można skonfigurować przy użyciu jednej z organizacji RAID, w zależności od wymaganej wydajności i niezawodności. Serwery zwykle uzyskują dostęp do sieci SAN przy użyciu protokołu, takiego jak iSCSI lub Fibre Channel. Serwery, które używają sieci SAN, widzą logiczne urządzenie blokowe, które można sformatować w systemie plików i zainstalować na serwerze. Serwer aplikacji może następnie używać zewnętrznie przechowywanych bloków logicznych w taki sam sposób, jak w przypadku bloków przechowywanych lokalnie. W rezultacie logiczne rozmieszczenie danych różni się rozmieszczenia fizycznego.
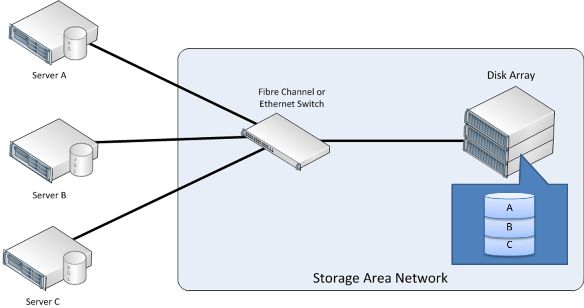
Rysunek 11. Sieci magazynowania
Pomimo że serwery współdzielą macierz dyskową, nie mogą fizycznie udostępniać danych znajdujących się na dyskach. Zamiast tego wyznaczane są fragmenty sieci SAN (zidentyfikowane jako numery jednostek logicznych lub LUN) i udostępniane do wyłącznego użytku przez każdy serwer.
Odwołania
- Thomas Rivera (2012 r.). Samouczek SNIA dotyczący ewolucji systemów plików
- Sanjay Ghemawat, Howard Gobioff i Shun-Tak Leung (2003). 19. sympozjum ACM Google File Systems dotyczące zasad systemów operacyjnych