Projekt bazy danych: spójność i twierdzenie CAP
Bez replikacji spójność jest nieistotna. Replikacja wiąże się z utrzymywaniem wielu kopii (lub replik) tych samych danych na wielu maszynach, natomiast spójność zapewnia spójny w całym systemie podgląd/stan replik dla wielu klientów/procesów. Jak wskazano wcześniej, elementy danych są replikowane z dwóch podstawowych powodów: wydajności i niezawodności. W odniesieniu do wydajności replikacja ma kluczowe znaczenie, gdy system wymaga skalowania pod względem liczb (ma to głównie miejsce w przypadku magazynów w chmurach prywatnych i publicznych) i obszarów geograficznych (zwykle w przypadku magazynów w chmurach publicznych). Na przykład gdy zwiększona liczba procesów musi uzyskać dostęp do danych, które są zarządzane przez pojedynczy serwer magazynu, wydajność można zwiększyć poprzez replikację danych na wielu serwerach (zamiast korzystania z tylko jednego serwera), a następnie podzielenie pracy na wiele serwerów. Taki podział umożliwia jednoczesne obsługiwanie wielu żądań, a tym samym zwiększa szybkość działania systemu. Natomiast replikację między obszarami geograficznymi (np. stosowana przez platformę Azure) można zagwarantować poprzez replikowanie kopii danych w pobliżu procesów wysyłających żądania w celu zminimalizowania czasu dostępu do danych. W odniesieniu do niezawodności dzięki replikacji można zapewnić lepszą odporność na uszkodzenia i utratę danych, co jest kluczowym wymogiem w systemach w chmurze. W szczególności jeśli replika zostanie utracona lub uszkodzona, można uzyskać dostęp do innej prawidłowej repliki (jeśli jest przechowywana).
Replikacja tworzy wiele replik danych, a spójność zapewnia, że te repliki pozostają jednolite, aby miały do nich dostęp rozmaite procesy (tj. w celu odczytu lub zapisu). Repliki w kolekcji są uważane za spójne, gdy wyglądają na identyczne dla jednocześnie uzyskujących do nich dostęp procesów. Możliwość obsługi operacji współbieżnych na replikach z zachowaniem spójności ma podstawowe znaczenie dla magazynów rozproszonych, w szczególności dla magazynów w chmurze. W tym module spójność jest omawiana w kontekście operacji odczytu i zapisu wykonywanych na udostępnionych replikach w rozproszonym magazynie danych (patrz rysunek 13). Rozproszony magazyn danych może być systemem plików DFS, równoległym systemem plików lub rozproszoną bazą danych. Spójność można uzyskać, wykorzystując model spójności. Model spójności definiujemy jako kontrakt pomiędzy procesami a rozproszonym magazynem danych. Ta definicja implikuje, że jeśli procesy zgadzają się na przestrzeganie pewnych reguł, rozproszony magazyn danych gwarantuje przestrzeganie tych reguł. Poniższy materiał wideo przedstawia rozmaite modele spójności.
W tym module omówimy szczegółowo trzy modele spójności: spójności sekwencyjną, spójność przyczynową oraz spójność ostateczną.
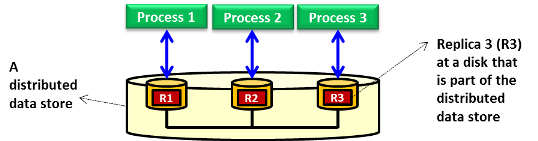
Rysunek 13. Rozproszony magazyn danych, który może być rozproszonym systemem plików, równoległym systemem plików lub rozproszoną bazą danych z replikami przechowywanymi na rozproszonych dyskach magazynu
Spójność sekwencyjna
Zwana jest też spójnością silną lub ścisłą. Wiąże się z natychmiastowym propagowaniem aktualizacji we wszystkich replikach. Zwykle wymaga to zastosowania aktualizacji w powiązanych replikach w pojedynczej niepodzielnej operacji lub transakcji. W praktyce wdrożenie niepodzielności w szeroko rozproszonych replikach znajdujących się w rozproszonym magazynie danych o dużej skali jest naturalnie trudne, szczególnie jeśli aktualizacje mają być wprowadzane szybko. Trudność wynika z nieprzewidzianych opóźnień dostępu narzucanych przez źródłową sieć magazynu oraz brak zegara globalnego, którego można by było użyć do szybkiego i dokładnego uporządkowania operacji. Aby rozwiązać ten problem, można zmniejszyć wymaganie dotyczące wprowadzania aktualizacji jako operacji niepodzielnych. Zmniejszenie wymagań związanych ze spójnością oznacza, że repliki nie muszą zawsze być takie same we wszystkich lokalizacjach. Możliwość zmniejszenia wymagań względem spójności zależy od aplikacji uruchomionej w ramach rozproszonego magazynu danych. Dokładnie mówiąc, zmniejszenie wymagań dotyczące spójności zależy od wzorców dostępu do odczytu i zapisu aplikacji oraz celu użycia replik. Na przykład przeglądarki i serwery proxy sieci Web są często skonfigurowane pod kątem przechowywania stron internetowych w lokalnych pamięciach podręcznych (jest to typ replikacji, ponieważ przechowywanych jest wiele kopii tej samej strony internetowej) w celu skrócenia czasu dostępu w przyszłości. W niektórych sytuacjach dopuszczalne jest, aby użytkownicy otrzymywali dostęp do nieaktualnych stron internetowych tak długo, jak (ostatecznie i wystarczająco szybko) strony będą uaktualniane do najnowszych wersji dostępnych na rzeczywistych serwerach sieci Web. Spójność ostateczna to przykład modelu, który odpowiada takim scenariuszom.
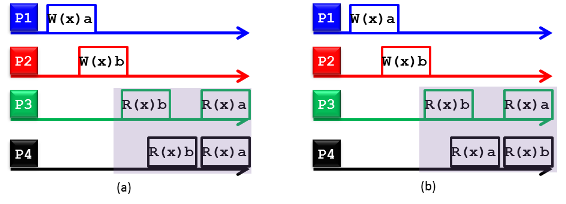
Rysunek 14. (a) Sekwencyjnie spójny rozproszony magazyn danych i (b) niesekwencyjnie spójny rozproszony magazyn danych
Rozproszony magazyn danych jest traktowany jako sekwencyjnie spójny, jeśli wszystkie procesy widzę te same przeploty operacji odczytu i zapisu podczas uzyskiwania jednoczesnego dostępu do replik. Rysunek 14 przedstawia dwa rozproszone magazyny danych: sekwencyjnie spójny magazyn danych [patrz rysunek 14 (a)] i niesekwencyjnie spójny magazyn danych [patrz rysunek 14 (b)]. Symbole W(x)a i R(x)b oznaczają odpowiednio wartość zapisu a w replice x oraz wartość odczytu b repliki x. Na rysunku przedstawiono cztery procesy działające na replikach odpowiadających elementowi danych x. Na rysunku 14(a) proces P1 zapisuje wartość a w x, a później (w czasie bezwzględnym), proces P2 zapisuje wartość b w x. Następnie procesy P3 i P4 najpierw odbierają wartość b i później wartości a po odczycie x. W związku z tym operacja zapisu przeprowadzona przez proces P2 wygląda, jakby miała miejsce przed operacją procesu P1 oraz procesów P3 i P4. Niemniej jednak rysunek 14 (a) nadal przedstawia sekwencyjnie spójny rozproszony magazyn danych, ponieważ procesy P3 i P4 korzystają z tego samego przeplotu operacji (np. najpierw odczytują b a następnie a). W przeciwieństwie do tego procesy P3 i P4 na rysunku 14(b) widzą różne przeploty operacji, co narusza warunek spójności sekwencyjnej.
Spójność przyczynowa
Model spójności przyczynowej jest słabszym wariantem modelu spójności sekwencyjnej. Po pierwsze przyczynowość oznacza, że jeśli operacja b jest spowodowana przez wcześniejszą operację a, każdy proces uzyskujący dostęp do rozproszonego magazynu danych powinien najpierw zobaczyć wartość a, a następnie b. Przyczynowo spójny rozproszony magazyn danych wymusza spójność wyłącznie w przypadku operacji, które są potencjalnie powiązane przyczynowo. Operacje, które nie są potencjalnie powiązane przyczynowo, mogą pojawić się w procesach w dowolnym przeplocie i są oznaczane jako operacje współbieżne. Rysunek 15 przedstawia dwa przyczynowo spójne rozproszone magazyny danych [rysunek15(a) i 15(c)] oraz jeden przyczynowo spójny rozproszony magazyn danych [rysunek 15(b)]. Na rysunku 15(a) operacja w(x)b wykonywana przez proces P2 jest potencjalnie zależna od operacji W(x)a, przenoszonej przez proces P1, ponieważ wartość b może wynikać z obliczeń związanych z odczytem wartości a przez proces P2 [tj. R(x)a] przed zapisem wartości b [tj. W(x)b]. W rezultacie wyniki operacji zapisu W(x)a i W(x)b wykonanych przez odpowiednio procesy P1 i P2 powinny być wyświetlone w tej samej kolejności podczas każdego procesu odczytu. Ponieważ procesy P3 i P4 najpierw odczytują wartość a, a następnie wartość b, są zgodne ze warunkiem przyczynowości, co sprawia, że źródłowy rozproszony magazyn danych jest spójny przyczynowo. W przeciwieństwie do tego proces P3 na rysunku 15(b) nie jest zgodny z warunkiem przyczynowości (tj. najpierw odczytuje wartość b a następnie a). W związku z tym sprawia, że źródłowy rozproszony magazyn danych jest przyczynowo niezgodny. Rysunek 15(c) ilustruje przyczynowo spójny rozproszony magazyn danych, ponieważ W(x)a i W(x)b są operacjami współbieżnymi. W związku z tym ich wyniki [tj. R(x)a i R(x)b] mogą pojawiać się w dowolnej kolejności w procesach odczytu, co ma miejsce w procesach P3 i P4.
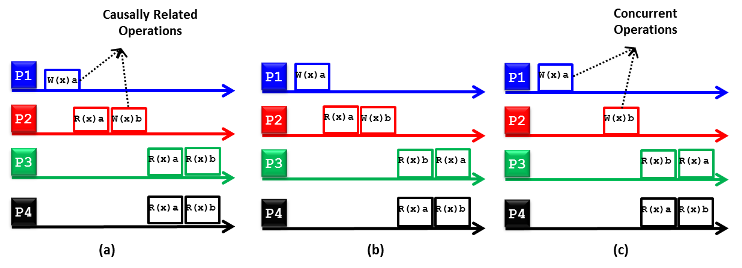
Rysunek 15: (a) przyczynowo spójny rozproszony magazyn danych, (b) przyczynowo niespójny spójny rozproszony magazyn danych oraz (c) przyczynowo spójny rozproszony magazyn danych
Spójność ostateczna
Model spójności ostatecznej jest traktowany jako słabsza forma modeli spójności sekwencyjnej i przyczynowej. Spójność ostateczna oznacza, że zapis w replice nie musi być natychmiast propagowany we wszystkich pozostałych replikach i może być opóźniony (lub czasami nie musi być nigdy propagowany), jeśli będzie zaakceptowany przez aplikacje. W szczególności, jeśli proces P uzyskuje dostęp do określonej repliki, R, $N$ razy na minutę, a R jest aktualizowany $M$ razy na minutę, to jeśli aplikacja wykazuje niski stosunek odczytu do zapisu (tj. $N << M$), wiele aktualizacji repliki nigdy nie będzie uzyskiwać dostępu do repliki, renderowanie wszystkich tych aktualizacji i wymaganej komunikacji sieciowej bez punktu widzenia. W takim przypadku lepszym rozwiązaniem może być zastosowanie słabego modelu spójności, zgodnie z którym wartość R będzie aktualizowana tylko wtedy, P uzyska do niej dostęp. Oznacza to, że wydajniejsze jest propagowanie aktualizacji z opóźnieniem, zgodnie z którym proces odczytu zobaczy aktualizację dopiero po upływie pewnego czasu od momentu jej wprowadzenia (nie natychmiast, tak jak ma to miejsce w przypadku ścisłej spójności). Jeśli konflikty wynikające z dwóch operacji próbujących zapisać te same dane (tj. konfliktów zapisu-zapisu) zdarzają się rzadko lub nie dochodzi do nich nigdy, opóźnienie propagacji aktualizacji jest często akceptowalne. Konflikty występują rzadko w przypadku systemów baz danych, które zwykle wykorzystują spójność ostateczną. Systemy baz danych omówimy szczegółowo w następnej sekcji. Należy zwrócić uwagę, że przedstawiliśmy tylko część informacji dotyczących modeli spójności. W innej części opisany jest sposób wdrażania takich modeli. W niniejszym module zajmujemy się wyłącznie wyjaśnieniem tych modeli oraz możliwością ich zastosowania w systemach magazynów w chmurze. Niemniej jednak wyjaśniamy pokrótce, że spójność sekwencyjna jest trudna do wdrożenia w praktyce oraz charakteryzuje się niewielką skalowalnością. Zwykle spójność sekwencyjna wymaga używania takich mechanizmów synchronizacji, jak transakcje czy blokady. W przeciwieństwie do tego wdrażanie spójności przyczynowej wiąże się ze stworzeniem grafu zależności, który przechwytuje przyczynowo powiązane operacje i wymusza te operacje na procesach. Jednym ze sposobów wdrażania takiego modelu jest użycie wektorowych sygnatur czasowych. Spójność ostateczna może być wdrażana poprzez grupowanie w sesje operacji odczytu i zapisu oraz używanie wektorowych sygnatur czasowych.
Właściwości ACID baz danych
Bazy danych mogą oferować właściwości transakcyjne. Transakcja składa się z jednostki pracy wykonywanej w ramach systemu zarządzania bazami danych (lub podobnego systemu) względem bazy danych. Transakcje są traktowane w spójny i niezawodny sposób, niezależnie od innych transakcji. Transakcje w środowisku bazy danych mają dwa główne cele:
- Zapewnianie prawidłowych jednostek pracy, które umożliwiają poprawne odzyskiwanie danych po wystąpieniu awarii i utrzymywanie spójności bazy danych, nawet w przypadku awarii systemu, gdy wykonywanie zostanie zatrzymane (całkowicie lub częściowo), a wiele operacji w bazie danych pozostanie nieukończonych oraz z nieznanym stanem.
- Zapewnianie izolacji pomiędzy programami uzyskującymi współbieżny dostęp do bazy danych. Jeśli izolacja nie zostanie zapewniona, wyniki działania programu mogą być błędne.
Aby lepiej zrozumieć potrzebę transakcji w bazie danych, rozważ następującą transakcję finansową wykonywaną na dwóch kontach bankowych, A i B. Załóżmy, że użytkownik chce przenieść 100 USD z konta A na konto B. Ten transfer można przedstawić w dwóch krokach:
- Odejmij 100 USD z konta A.
- Kredyt $100 do konta B.
Załóżmy, że błąd bazy danych występuje między operacjami 1 i 2: 100 USD zostałoby odjęte od konta A, ale środki na konto B nie miałyby miejsca. Konta oraz sama baza danych znalazłyby się w stanie niespójnym.
Aby rozwiązać ten problem, można zdefiniować operacje jako transakcje w następujący sposób:
- Rozpocząć transakcję.
- Odejmij 100 USD z konta A.
- Kredyt $100 do konta B.
- Zakończyć transakcję.
Od teraz baza danych odpowiada za zapewnienie niepodzielności tej transakcji — transakcja musi być w całości pomyślna (zatwierdzona) lub niewykonana (wycofana). Baza danych powinna być spójna po zakończeniu transakcji. Oznacza to, że baza danych powinna znajdować się w prawidłowym stanie po zatwierdzeniu transakcji, a wszelkie reguły zdefiniowane dla rekordów w bazie danych nie powinny być naruszone (np. konto oszczędnościowe nie może mieć salda ujemnego). Wszelkie transakcje, które są wykonywane współbieżnie na kontach, nie mogą zakłócać siebie nawzajem — muszą zapewniać izolację. Na koniec transakcja musi być trwała. Oznacza to, że akcje wykonywane w ramach transakcji powinny być utrwalane po zatwierdzeniu transakcji w bazie danych. Właściwości niepodzielności, spójności, izolacji i trwałości są określane zbiorczo jako właściwości ACID transakcji. Większość systemów zarządzania relacyjnymi bazami danych używanych do przetwarzania transakcji powinna przestrzegać tych właściwości. Poniższy film wideo zawiera omówienie właściwości ACID w bazach danych:
- Atomic: Transakcja jest niepodzielna — wszystkie instrukcje w transakcji są stosowane do bazy danych lub żadne.
- Spójne: baza danych pozostaje w spójnym stanie przed i po wykonaniu transakcji.
- Izolowane: mimo że wiele transakcji może być wykonywanych jednocześnie przez jednego lub wielu użytkowników, jedna transakcja nie powinna widzieć efektów innych współbieżnych transakcji.
- Trwałe: gdy transakcja zostanie zapisana w bazie danych (akcja określona w parlance programowania bazy danych jako zatwierdzenie), oczekuje się, że zmiany zostaną utrwalone.
Dlaczego nie możesz mieć tego wszystkiego: twierdzenie CAP
W 1999 roku Brewer1 zaproponował twierdzenie opisujące ograniczenia rozproszonych magazynów danych o nazwie twierdzeniem CAP. Zgodnie z twierdzeniem CAP wszystkie systemy rozproszonych magazynów z udostępnianymi danymi mogą mieć maksymalnie dwie z trzech pożądanych właściwości:
- Spójność: Spójność to stan, w którym każdy węzeł zawsze widzi te same dane w dowolnym momencie (ścisła spójność).
- Dostępność: Gwarancja, że każde żądanie otrzyma odpowiedź na temat tego, czy zakończyło się powodzeniem, czy niepowodzeniem, jest gwarancją dostępności.
- Tolerancja partycji: partycja sieciowa jest warunkiem, w którym węzły systemu rozproszonego nie mogą się ze sobą kontaktować. Tolerancja partycji oznacza, że system kontynuuje normalne działanie pomimo utraty dowolnego komunikatu lub awarii części systemu.
Twierdzenie CAP omówiono w poniższym materiale wideo:
Najprostszym sposobem zrozumienia twierdzenia CAP jest wyobrażenie sobie dwóch węzłów rozproszonego systemu magazynowania po przeciwległych stronach partycji sieciowej (rysunek 16). Zezwolenie co najmniej jednemu węzłowi na aktualizację stanu spowoduje, że węzły staną się niespójne, a tym samym stracą C. Podobnie jeśli priorytetowe będzie zachowanie spójności, jedna strona partycji musi działać tak, jakby była niedostępna, co spowoduje utratę A. Tylko wtedy, gdy węzły komunikują się ze sobą, można zachować zarówno spójność, jak i dostępność, tym samym tracąc P.
Rozważmy na przykład przypadek tradycyjnego systemu zarządzania relacyjnymi bazami danych z jednym węzłem. W tym scenariuszu można zagwarantować spójność i dostępność, chociaż pojęcie tolerancji partycji nie istnieje, ponieważ baza danych znajduje się w jednym węźle.
Gdy firmy takie jak Microsoft opracowywały bazy danych na dużą skalę do obsługi milionów klientów, kluczową sprawą była całodobowa dostępność, ponieważ nawet kilka minut przestoju oznacza stratę przychodów. Podczas skalowania rozproszonych systemów udostępnianych danych na setki lub nawet tysiące komputerów prawdopodobieństwo awarii co najmniej jednego węzła (tworząc w ten sposób partycję sieciową) znacznie się zwiększa. W związku z tym zgodnie z twierdzeniem CAP w celu zapewnienia silnej gwarancji dostępności i tolerancji partycji należy poświęcić ścisłą spójność w rozproszonych bazach danych o wysokiej wydajności i dużej skali.
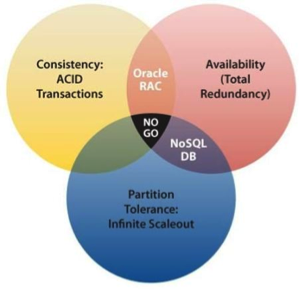
Rysunek 16. Twierdzenie CAP ilustrowane
Odwołania
- Eric Brewer (2000 r.). W kierunku niezawodnych systemów rozproszonych sprawozdanie z rocznego sympozjum ACM na temat zasad przetwarzania rozproszonego