Architektury przetwarzania danych big data
W tym module zostały omówione podstawowe koncepcje dotyczące rozproszonych aparatów programistycznych i analitycznych, a także wyzwania związane z przetwarzaniem danych big data na dużą skalę. Przyjrzeliśmy się kilku platformom, m.in. MapReduce, Spark oraz GraphLab, jak również platformom przetwarzania strumieniowego. Aby podsumować naszą dyskusję, przedstawimy teraz niektóre podejmowane obecnie próby zdefiniowania modelu architektury ułatwiającego tworzenie systemów, które będą mogły obsługiwać zarówno dane w czasie rzeczywistym jak i dane historyczne: architektury lambda i kappa.
Na przykład cyfrowe asystenty, takie jak Cortana firmy Microsoft, często używają złożonych algorytmów uczenia maszynowego do rozpoznawania mowy oraz do analizowania zapytań użytkownika. Przychodzące zapytania użytkowników można uznać za strumień, który wymaga odpowiedzi z małym opóźnieniem. Jednak wraz z upływem czasu dane historyczne zapytań użytkowników mogą zostać użyte do ponownego trenowania systemu uczenia maszynowego w celu lepszego rozpoznawania mowy i rozumienia zapytań. Ten drugi proces może korzystać z jakiegoś systemu przetwarzania wsadowego w celu zaktualizowania modeli uczenia maszynowego na potrzeby przyszłych zapytań.
Architektura lambda
Architektura lambda jest architekturą przetwarzania danych przeznaczoną do obsługi dużych ilości danych zarówno przy użyciu metody przetwarzania strumieniowego, jak i przetwarzania wsadowego. W podejściu lambda podjęto próbę zrównoważenia opóźnień, przepływności i odporności na uszkodzenia, wykorzystując przetwarzanie wsadowe w celu zapewnienia złożonych i dokładnych widoków danych wsadowych, jednocześnie stosując przetwarzanie strumieniowe w czasie rzeczywistym, aby zapewnić widoki danych online.
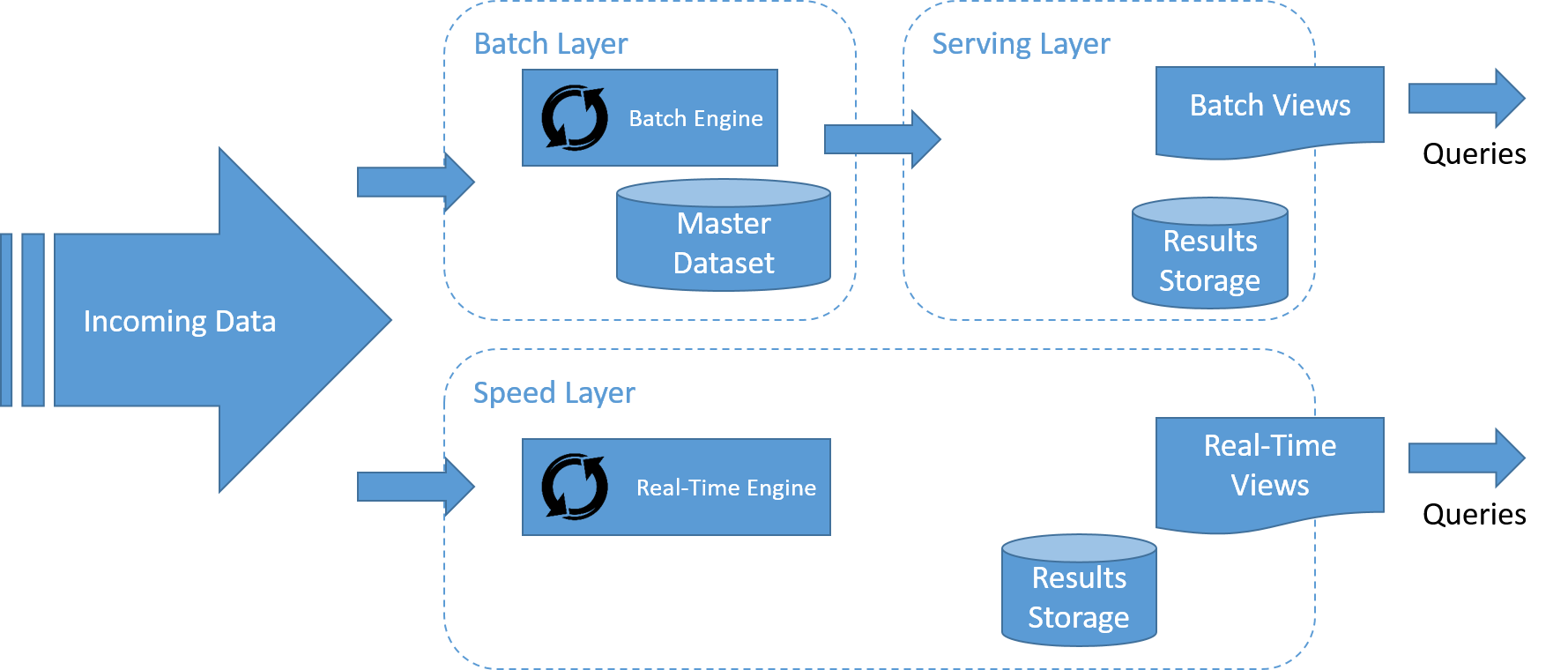
Architektura lambda to system składający się z trzech warstw: warstwy wsadowej, warstwy przetwarzania szybkiego (lub w czasie rzeczywistym) i warstwy obsługującej przeznaczonej do odpowiadania na zapytania.
Rysunek 16. W razie potrzeby system przetwarzania strumieniowego musi przetwarzać dane w strumieniu z oddzielnym potokiem magazynu, który nie leży na "ścieżce krytycznej".
Przepływ danych w architekturze lambda został przedstawiony na rysunku. Kroki tego procesu są następujące:
- Wszystkie dane wprowadzane do systemu są wysyłane do przetworzenia zarówno do warstwy wsadowej, jak i do warstwy szybkiej.
- Warstwa wsadowa zarządza głównym zestawem danych i wstępnie oblicza widoki wsadowe.
- Warstwa obsługująca indeksuje widoki wsadowe w taki sposób, aby można było wykonywać na nich zapytania ad hoc, uzyskując odpowiedzi z małym opóźnieniem.
- Warstwa szybka kompiluje widoki danych przychodzących w czasie rzeczywistym w taki sposób, że jest to znacznie szybsze niż w przypadku warstw wsadowych i obsługującej, ale może nie być równie dokładne.
- Na każde zapytanie przychodzące można udzielić odpowiedzi poprzez scalenie wyników z widoków wsadowych oraz widoków w czasie rzeczywistym.
Warstwa wsadowa
Warstwa wsadowa odgrywa istotną rolę w architekturze lambda:
- Po pierwsze zwykle zarządza głównym zestawem danych. Główny zestaw danych jest źródłem informacji w architekturze lambda i może służyć do odbudowy wszelkich danych obsługiwanych przez system w przypadku awarii w którejkolwiek z warstw systemu. Dane w warstwie wsadowej są zwykle organizowane jako niezmienialny dziennik, do którego można jedynie dołączać nowe dane w miarę ich przychodzenia do systemu.
- Po drugie warstwa wsadowa tworzy widoki wsadowe danych. Warstwa wsadowa ma na celu zapewnić idealną lub prawie idealną dokładność i może przetwarzać wszystkie dostępne dane podczas generowania widoków wsadowych. Oznacza to, że może ona naprawić wszystkie błędy przez ponowne przeprowadzenie obliczeń na podstawie kompletnego zestawu danych, a następnie zaktualizowanie istniejących widoków wsadowych. Dane wyjściowe z warstwy wsadowej są przechowywane w warstwie obsługującej.
Apache Hadoop to de facto standardowy system przetwarzania wsadowego wykorzystywany w większości architektur o wysokiej przepływności i jest typowym rozwiązaniem do wdrażania warstwy wsadowej. Przetwarzanie można wykonywać przy użyciu platformy MapReduce lub dowolnego z systemów przetwarzania wsadowego wyższego poziomu opartych na usłudze Hadoop.
Warstwa obsługująca
Dane wyjściowe z warstw wsadowych (widoki wsadowe) są przechowywane w warstwie obsługującej i udostępniane do wykonywania zapytań przez aplikacje. Są one ściśle powiązane z warstwą wsadową. Warstwa obsługująca jest zwykle rozproszona na wielu maszynach w celu zapewnienia skalowalności. Warstwa obsługująca zazwyczaj zawiera pewien typ bazy danych i najczęściej jest to baza danych NoSQL. Wymagania dotyczące warstwy obsługującej są następujące:
- Zapisywanie wsadowe: widoki wsadowe dla warstwy obsługującej są tworzone od podstaw. Po udostępnieniu nowej wersji widoku musi być możliwość całkowitej wymiany starszej wersji na zaktualizowany widok. W związku z tym systemy warstwy obsługującej nie muszą być optymalizowane na potrzeby szybkiego zapisu losowego, w przeciwieństwie do tradycyjnych systemów baz danych.
- Skalowalne: baza danych warstwy obsługującej musi być w stanie obsługiwać widoki o dowolnym rozmiarze. Podobnie jak w przypadku omówionych wcześniej rozproszonych systemów plików i platformy obliczeń wsadowych, musi być ona rozproszona na wielu maszynach.
- Operacje odczytu losowego: baza danych warstwy obsługującej musi obsługiwać losowe operacje odczytu, a indeksy zapewniają bezpośredni dostęp do małych części widoku. Jeśli opóźnienia na zapytaniach mają być niewielkie, wymóg ten należy koniecznie spełnić.
- Odporność na uszkodzenia: ponieważ baza danych warstwy obsługującej jest dystrybuowana, musi być odporna na awarie maszyn.
Do typowych przykładów magazynów danych używanych w warstwie obsługującej możemy zaliczyć rozwiązania Apache Hive, HBase i Impala.
Warstwa szybka
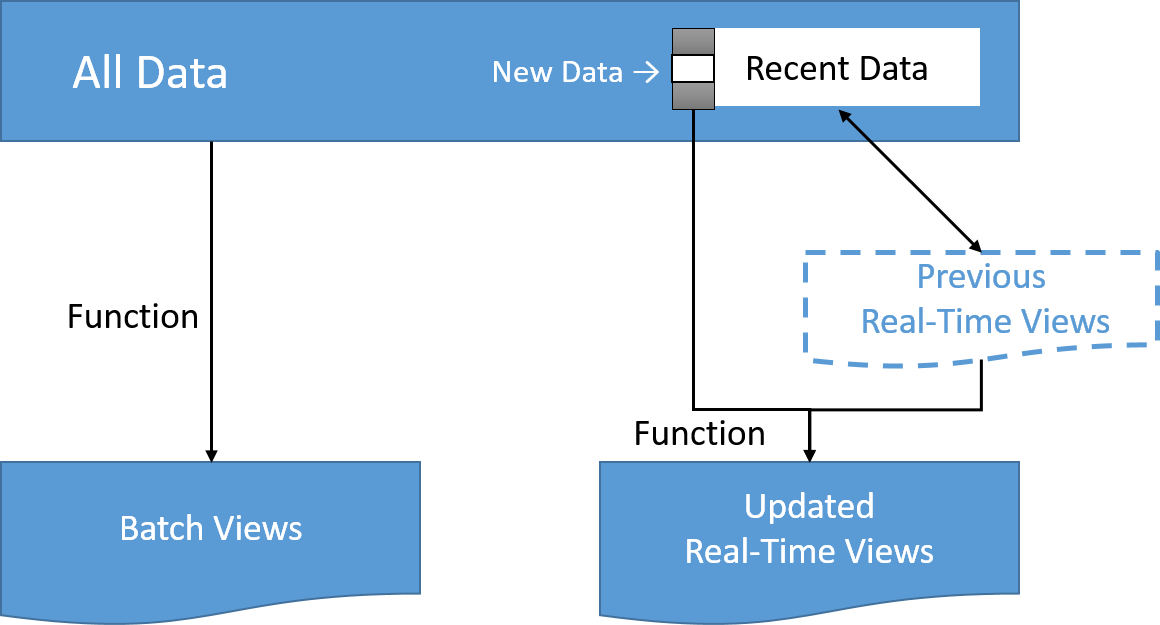
Warstwa szybka przetwarza strumienie danych w czasie rzeczywistym z najniższym możliwym opóźnieniem w celu wygenerowania widoków danych w czasie rzeczywistym. Zasadniczo warstwa szybka jest odpowiedzialna za wypełnienie „luki” spowodowanej zwłoką warstwy wsadowej w dostarczaniu widoków na podstawie najnowszych danych.
Widoki tej warstwy mogą nie być tak dokładne ani tak kompletne jak te ostatecznie utworzone przez warstwę wsadową, ale są one dostępne prawie natychmiast po odebraniu danych i można je zastąpić, gdy zostaną udostępnione widoki warstwy wsadowej dla tych samych danych. W przypadku użycia omawianych wcześniej w tym module rozwiązań przetwarzania przyrostowego i strumieniowego przetwarzanie może odbywać się w bardziej wydajny sposób, jeśli obliczenia można wyrazić jako funkcję poprzedniego widoku w czasie rzeczywistym i najnowszych danych, w celu utworzenia zaktualizowanych widoków danych czasu rzeczywistego.
Rysunek 17. W razie potrzeby system przetwarzania strumieniowego musi przetwarzać dane w strumieniu z oddzielnym potokiem magazynu, który nie leży na "ścieżce krytycznej".
Zwykle używane w tej warstwie technologie przetwarzania strumieniowego obejmują m.in. Apache Samza, Apache Storm, SQLstream i Apache Spark. Dane wyjściowe są zwykle przechowywane w szybkich bazach danych typu NoSQL na potrzeby wykonywania zapytań z małym opóźnieniem.
Architektura kappa
Rysunek 18. W razie potrzeby system przetwarzania strumieniowego musi przetwarzać dane w strumieniu z oddzielnym potokiem magazynu, który nie leży na "ścieżce krytycznej".
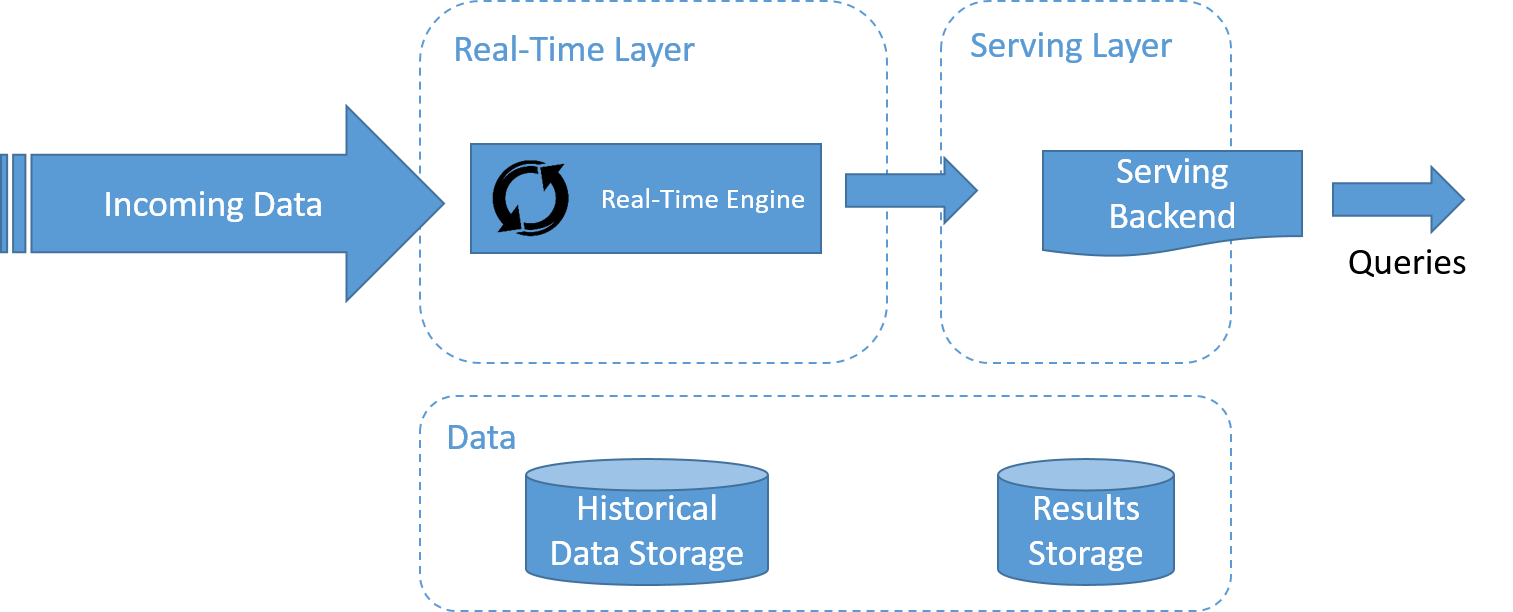
Na rysunku przedstawiono architekturę kappa, spopularyzowaną przez firmę LinkedIn. Jednym z ważnych powodów utworzenia architektury kappa było uniknięcie konieczności utrzymania dwóch oddzielnych baz kodu dla warstwy wsadowej i warstwy szybkiej. Najważniejszą kwestią jest obsługa zarówno przetwarzania danych w czasie rzeczywistym, jak i ciągłego ponownego przetwarzania danych przy użyciu jednego aparatu przetwarzania strumieniowego.
Ponowne przetwarzanie danych jest ważnym warunkiem uwidocznienia w wynikach efektów zmian w kodzie. W związku z tym architektura kappa zawiera tylko dwie warstwy: przetwarzania strumieniowego i obsługującą.
W warstwie przetwarzania strumieniowego uruchamiane są zadania przetwarzania strumieniowego. Zwykle jest uruchamiane jedno zadanie przetwarzania strumieniowego, co ma na celu umożliwienie przetwarzania danych w czasie rzeczywistym. Ponowne przetwarzanie danych jest wykonywane tylko wtedy, gdy trzeba zmodyfikować jakąś część kodu zadania przetwarzania strumieniowego. W tym celu należy uruchomić kolejne, zmodyfikowane zadanie przetwarzania strumieniowego i ponownie odtworzyć wszystkie poprzednie dane. Na koniec, podobnie jak w przypadku architektury lambda, używa się warstwy obsługującej w celu wykonywania zapytań względem wyników.
Lambda vs. Architektura Kappa jest ciągłą debatą w społeczności na potrzeby przetwarzania danych big data. Wybór architektury zależy od pewnych cech aplikacji, która ma zostać wdrożona. Firma Ericsson proponuje następujące proste rozwiązanie:
- Jeśli algorytmy używane na potrzeby danych historycznych i w czasie rzeczywistym są identyczne, zazwyczaj lepiej jest zastosować podejście kappa. Niektóre formy obliczeń wsadowych mogą być niezbędne do uruchamiania widoków w zależności od ilości danych historycznych i szybkości odbierania nowych danych.
- W niektórych typach aplikacji, takich jak aplikacje uczenia maszynowego, dane wyjściowe systemów przetwarzania wsadowego i przetwarzania w czasie rzeczywistym różnią się pod względem dokładności z powodu ilości uwzględnianych danych. Sprawia to, że scalenie wyników przetwarzania wsadowego i przetwarzania w czasie rzeczywistym w spójny widok staje się bardzo trudne, a architektura oparta na rozwiązaniu lambda może być lepsza dla danej aplikacji.
- W niektórych przypadkach można zoptymalizować algorytm wsadowy dzięki temu, że ma on dostęp do pełnego zestawu danych historycznych, a następnie uzyskać dzięki niemu lepsze wyniki (pod względem przepływności przetwarzania) niż w przypadku algorytmu w czasie rzeczywistym. W takiej sytuacji wybór między architekturą lambda i kappa staje się kwestią wyboru między wydajnością wykonywania przetwarzania wsadowego a prostotą bazy kodu.