Opisywanie inteligentnego przetwarzania zapytań
W programach SQL Server 2017 i 2019 oraz w usłudze Azure SQL firma Microsoft wprowadziła wiele nowych funkcji na poziomach zgodności 140 i 150. Wiele z tych funkcji poprawia to, co wcześniej uważano za antywzorce, takie jak używanie funkcji skalarnej zdefiniowanej przez użytkownika oraz zmienne tabelaryczne.
Te funkcje dzielą się na kilka rodzin funkcji:
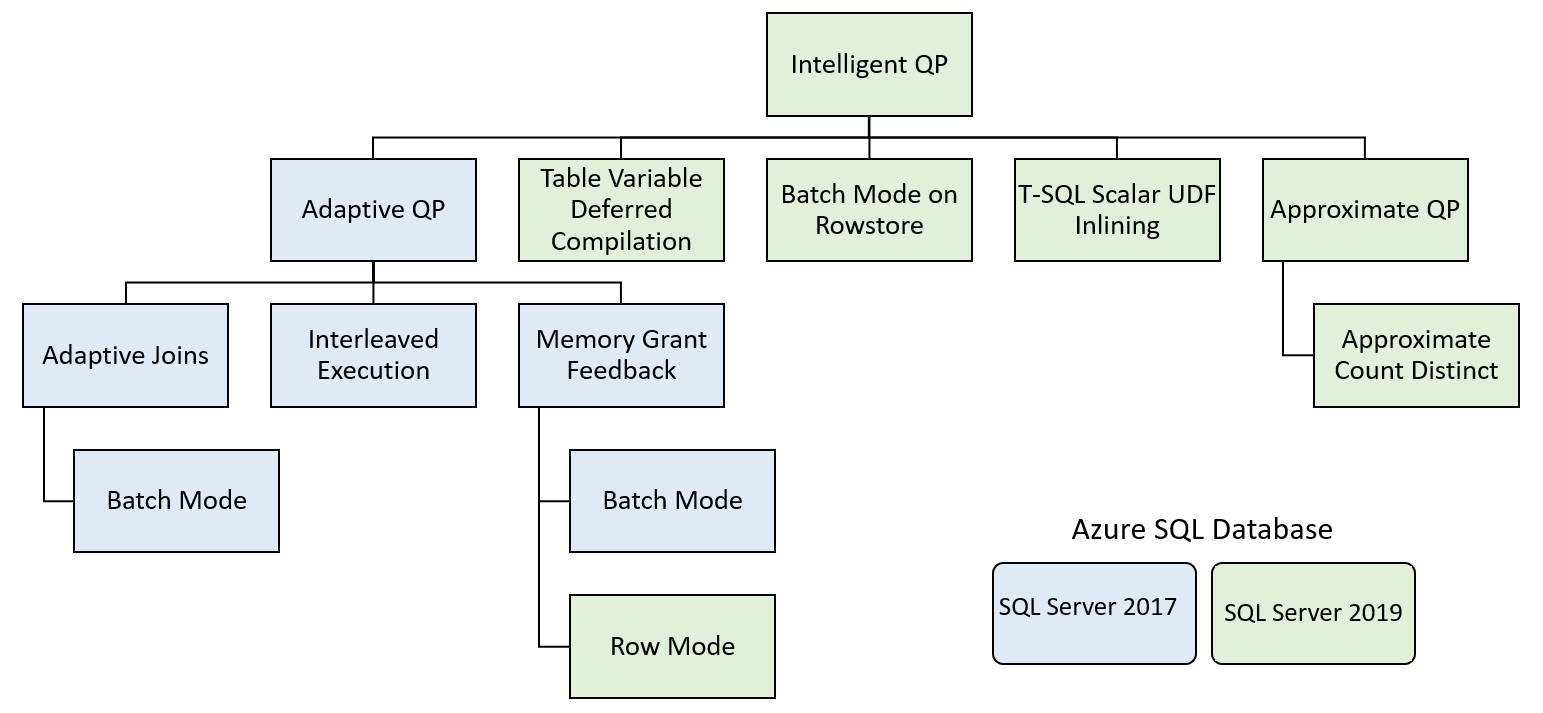
Inteligentne przetwarzanie zapytań obejmuje funkcje, które zwiększają wydajność istniejących obciążeń przy minimalnym wysiłku implementacji.
Aby obciążenia automatycznie kwalifikowały się do inteligentnego przetwarzania zapytań, zmień odpowiedni poziom zgodności bazy danych na 150. Na przykład:
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 150;
Adaptacyjne przetwarzanie zapytań
Funkcja adaptacyjnego przetwarzania zapytań zawiera wiele opcji, które sprawiają, że przetwarzanie zapytań jest bardziej dynamiczne na podstawie kontekstu wykonywania zapytania. Te opcje obejmują kilka funkcji, które zwiększają przetwarzanie zapytań.
Sprzężenia adaptacyjne — aparat bazy danych opóźnia wybór rodzaju sprzężenia między sprzężeniem skrótu a sprzężeniem pętli zagnieżdżonych na podstawie liczby wierszy wchodzących do sprzężenia. Sprzężenia adaptacyjne obecnie pracują tylko w trybie egzekucji wsadowej.
Przeplatane wykonywanie — obecnie ta funkcja obsługuje funkcje z wieloma instrukcjami o wartości tabeli (MSTVF). Przed SQL Server 2017, funkcje MSTVF używały stałego oszacowania wierszy wynoszącego jeden lub 100, w zależności od wersji SQL Server. To oszacowanie może prowadzić do nieoptymalnych planów zapytań, jeśli funkcja zwróciłaby znacznie więcej wierszy. Rzeczywista liczba wierszy jest generowana na podstawie MSTVF, zanim reszta planu zostanie skompilowana z przeplatanym trybem wykonania.
Opinia o udzielaniu pamięci — program SQL Server generuje przydział pamięci w początkowym planie zapytania na podstawie oszacowań liczby wierszy ze statystyk. Poważna niesymetria danych może prowadzić do nadmiernych lub niepełnych przewidywań liczby wierszy, co może spowodować nadmierne przydziały pamięci, które obniżają równoczesność wykonywania zadań, lub niedostateczne przydziały, co może prowadzić do rozlewania danych przez zapytanie do bazy danych tempdb. W przypadku przekazywania opinii o udzielaniu pamięci program SQL Server wykrywa te warunki i zmniejsza lub zwiększa ilość pamięci przyznanej zapytaniu, aby uniknąć rozlania lub nadmiernej alokacji.
Wszystkie te funkcje są automatycznie włączone w trybie zgodności 150 i nie wymagają żadnych innych zmian w celu włączenia.
Kompilacja odroczona zmiennej tabeli
Podobnie jak MSTVFs, zmienne tabeli w planach wykonania programu SQL Server niosą stałą prognozę liczby wierszy ustawioną na jeden wiersz. Podobnie jak MSTVFs, to stałe oszacowanie skutkowało niską wydajnością, gdy zmienna miała większą liczbę wierszy niż oczekiwano. W programie SQL Server 2019 zmienne tabeli są teraz analizowane i mają rzeczywistą liczbę wierszy. Kompilacja odroczona jest podobna do przeplatanego wykonywania MSTVFs, z tą różnicą, że jest wykonywana podczas pierwszej kompilacji zapytania, a nie dynamicznie w ramach planu wykonania.
Tryb wsadowy w przechowywaniu wierszowym
Tryb przetwarzania wsadowego umożliwia przetwarzanie danych w partiach zamiast wiersz po wierszu. Zapytania, które generują znaczne koszty procesora CPU na potrzeby obliczeń i agregacji, widzą największą korzyść z tego modelu przetwarzania. Oddzielając przetwarzanie wsadowe od indeksów magazynu kolumnowego, więcej obciążeń może korzystać z przetwarzania w trybie wsadowym.
Wstawianie funkcji zdefiniowanej przez użytkownika w trybie skalarowym
W starszych wersjach programu SQL Server funkcje skalarne działały słabo z kilku powodów. Funkcje skalarne były wykonywane iteracyjnie, efektywnie przetwarzają jeden wiersz naraz. Nie dokonali odpowiedniego oszacowania kosztów w planie wykonania i nie zezwalali na równoległe przetwarzanie w planie zapytania. W przypadku wbudowywania funkcji zdefiniowanych przez użytkownika te funkcje są przekształcane w podzapytania skalarne w miejscu operatora funkcji zdefiniowanej przez użytkownika w planie wykonywania. Ta transformacja może prowadzić do znacznego wzrostu wydajności zapytań obejmujących wywołania funkcji skalarnych.
Przybliżona ilość unikatowych
Typowym wzorcem zapytań magazynu danych jest wykonanie odrębnej liczby zamówień lub użytkowników. Ten wzorzec zapytania może być kosztowny dla dużej tabeli. Przybliżona liczba unikatowych wartości wprowadza szybsze podejście do określania liczby unikalnych wartości poprzez grupowanie wierszy. Ta funkcja gwarantuje szybkość błędów wynoszącą 2% z interwałem ufności wynoszącym 97%.