Korzystanie z interfejsu API zamiany mowy na tekst w usłudze Azure AI
Usługa Azure AI Speech obsługuje rozpoznawanie mowy za pomocą dwóch interfejsów API REST:
- Interfejs API zamiany mowy na tekst , który jest podstawowym sposobem rozpoznawania mowy.
- Interfejs API krótkiego dźwięku zamiany mowy na tekst, zoptymalizowany pod kątem krótkich strumieni audio (do 60 sekund).
Możesz użyć dowolnego interfejsu API do interaktywnego rozpoznawania mowy, w zależności od oczekiwanej długości wypowiedzi wejściowych. Możesz również użyć interfejsu API zamiany mowy na tekst na potrzeby transkrypcji wsadowej, transkrypcji wielu plików audio do tekstu jako operacji wsadowej.
Więcej informacji na temat interfejsów API REST można uzyskać w dokumentacji interfejsu API REST zamiany mowy na tekst. W praktyce większość interakcyjnych aplikacji obsługujących mowę używa usługi Mowa za pomocą zestawu SDK specyficznego dla języka (programowania).
Korzystanie z zestawu Azure AI Speech SDK
Szczegóły różnią się w zależności od używanego zestawu SDK (Python, C#itd.); Istnieje spójny wzorzec używania interfejsu API zamiany mowy na tekst :
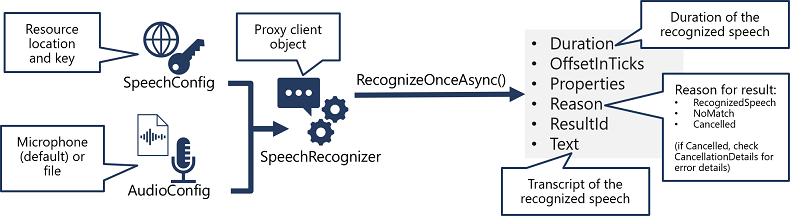
- Użyj obiektu SpeechConfig, aby hermetyzować informacje wymagane do nawiązania połączenia z zasobem usługi Mowa usługi Azure AI. W szczególności jego lokalizacja i klucz.
- Opcjonalnie użyj pliku AudioConfig , aby zdefiniować źródło wejściowe dla dźwięku do transkrypcji. Domyślnie jest to domyślny mikrofon systemowy, ale można również określić plik dźwiękowy.
- Użyj obiektów SpeechConfig i AudioConfig, aby utworzyć obiekt SpeechRecognizer. Ten obiekt jest klientem proxy interfejsu API zamiany mowy na tekst .
- Użyj metod obiektu SpeechRecognizer , aby wywołać podstawowe funkcje interfejsu API. Na przykład metoda RecognizeOnceAsync() używa usługi Azure AI Speech do asynchronicznego transkrypcji pojedynczej wypowiedzi mówionej.
- Przetwórz odpowiedź z usługi Azure AI Speech. W przypadku metody RecognizeOnceAsync() wynik jest obiektem SpeechRecognitionResult zawierającym następujące właściwości:
- Czas trwania
- OffsetInTicks
- Właściwości
- Przyczyna
- ResultId
- Text
Jeśli operacja zakończyła się pomyślnie, właściwość Reason ma wyliczoną wartość RecognizedSpeech, a właściwość Text zawiera transkrypcję. Inne możliwe wartości dla pola Result to NoMatch (wskazująca, że dźwięk został pomyślnie przeanalizowany, ale nie rozpoznano mowy) lub Anulowano, wskazując, że wystąpił błąd (w takim przypadku można sprawdzić kolekcję Właściwości dla właściwości CancellationReason , aby określić, co poszło nie tak).