Definiowanie problemu
Począwszy od pierwszego kroku, chcesz zdefiniować problem, który powinien rozwiązać model, rozumiejąc:
- Jakie powinny być dane wyjściowe modelu.
- Jakiego typu zadania uczenia maszynowego używasz.
- Jakie kryteria sprawiają, że model zakończył się pomyślnie.
W zależności od posiadanych danych i oczekiwanych danych wyjściowych modelu można zidentyfikować zadanie uczenia maszynowego. Zadanie określa typy algorytmów, których można użyć do trenowania modelu.
Oto niektóre typowe zadania uczenia maszynowego:
- Klasyfikacja: przewidywanie wartości kategorii.
- Regresja: przewidywanie wartości liczbowej.
- Prognozowanie szeregów czasowych: przewidywanie przyszłych wartości liczbowych na podstawie danych szeregów czasowych.
- Przetwarzanie obrazów: klasyfikuj obrazy lub wykrywaj obiekty na obrazach.
- Przetwarzanie języka naturalnego (NLP): wyodrębnianie szczegółowych informacji z tekstu.
Aby wytrenować model, masz zestaw algorytmów, których można użyć, w zależności od zadania, które chcesz wykonać. Aby ocenić model, możesz obliczyć metryki wydajności, takie jak dokładność lub precyzja. Dostępne metryki zależą również od zadania, które musi wykonać model, i pomóc w podjęciu decyzji, czy model zakończył się pomyślnie.
Eksplorowanie przykładu
Rozważ scenariusz, w którym chcesz określić, czy pacjenci mają cukrzycę. Problem, który próbujesz rozwiązać, i typ dostępnych danych określa wybrane zadanie uczenia maszynowego. W takim przypadku dostępne dane są innymi punktami danych zdrowotnych pacjentów. Możemy przedstawić dane wyjściowe, które chcemy przedstawić jako informacje podzielone na kategorie, które pacjent ma cukrzycę lub nie ma cukrzycy. W związku z tym zadanie uczenia maszynowego to klasyfikacja.
Zrozumienie całego procesu przed rozpoczęciem daje możliwość mapowania decyzji, które należy podjąć, aby zaprojektować pomyślne rozwiązanie do uczenia maszynowego. Poniżej przedstawiono diagram przedstawiający jeden ze sposobów podejścia do problemu identyfikowania cukrzycy u pacjenta. Na diagramie dane są wstępnie mapowane, podzielone i wytrenowane przy użyciu określonych algorytmów. Następnie model jest oceniany pod kątem jakości.
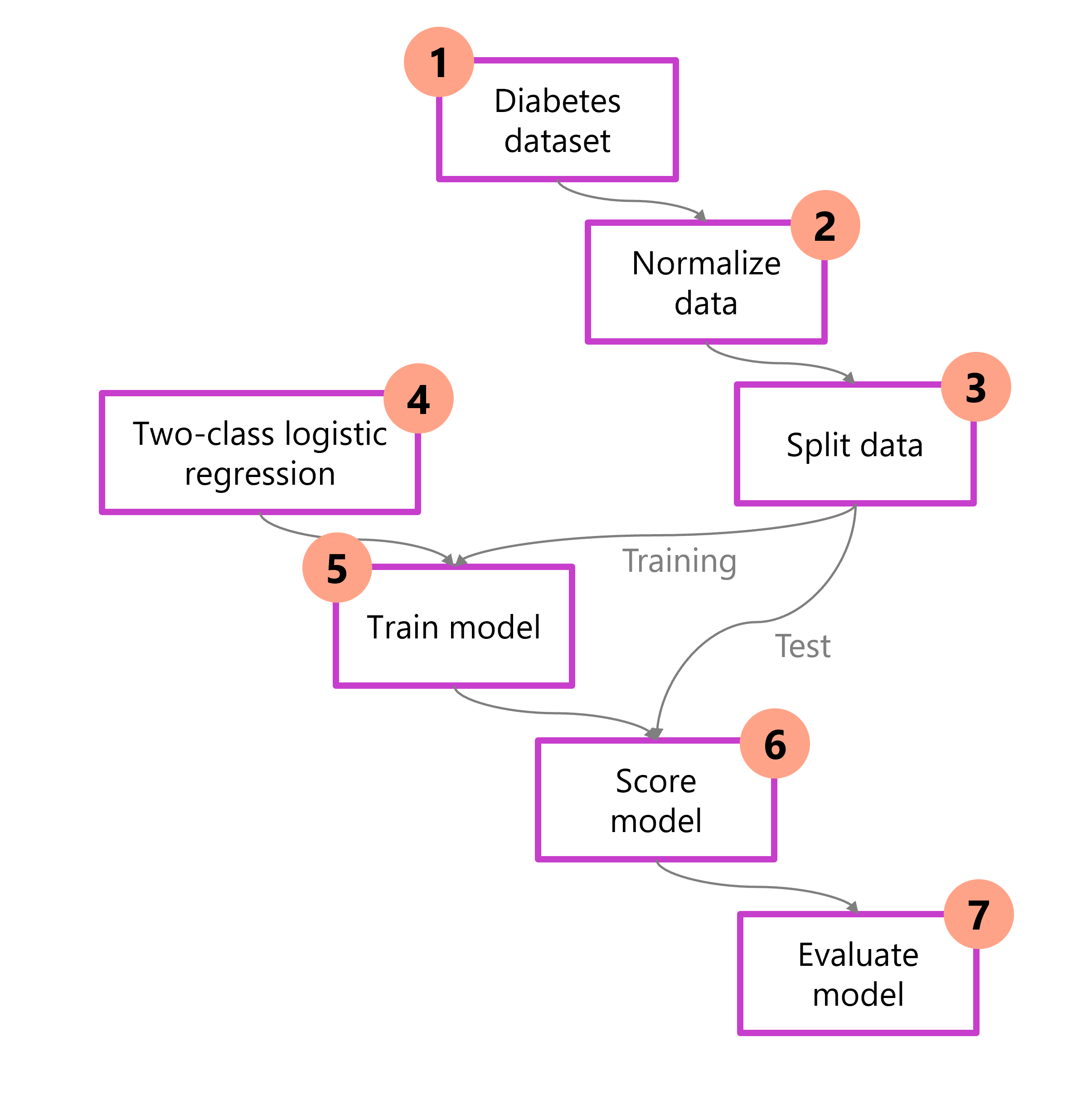
- Ładowanie danych: zaimportuj i sprawdź zestaw danych.
- Przetwarzanie wstępne danych: normalizacja i czyszczenie pod kątem spójności.
- Podziel dane: rozdziel je na zestawy treningowe i testowe.
- Wybierz model: wybierz i skonfiguruj algorytm.
- Trenowanie modelu: poznaj wzorce na podstawie danych treningowych.
- Model oceny: generowanie przewidywań na danych testowych.
- Ocena: oblicz metryki wydajności.
Trenowanie modelu uczenia maszynowego jest często procesem iteracyjnym, w którym wykonuje się poszczególne kroki wielokrotnie w celu znalezienia najlepszego modelu. Następnie przeanalizujmy proces przygotowywania danych na potrzeby tworzenia rozwiązania do uczenia maszynowego.