Wdrażanie modelu w punkcie końcowym
Podczas tworzenia aplikacji generującej sztuczną inteligencję należy zintegrować modele językowe z aplikacją. Aby móc korzystać z modelu językowego, należy wdrożyć model. Przyjrzyjmy się, jak wdrożyć modele językowe w rozwiązaniu Microsoft Foundry, po zapoznaniu się z pierwszym zrozumieniem, dlaczego wdrożyć model.
Dlaczego warto wdrożyć model?
Wytrenujesz model, aby wygenerować dane wyjściowe na podstawie niektórych danych wejściowych. Aby uzyskać wartość z modelu, potrzebujesz rozwiązania, które pozwala wysyłać dane wejściowe do modelu; model je przetwarza, a następnie dane wyjściowe są dla Ciebie wizualizowane.
W przypadku generowania aplikacji sztucznej inteligencji najczęstszym typem rozwiązania jest aplikacja do czatu, która oczekuje pytania użytkownika, które przetwarza model, w celu wygenerowania odpowiedniej odpowiedzi. Odpowiedź jest następnie wizualizowana jako odpowiedź na jego pytanie dla użytkownika.
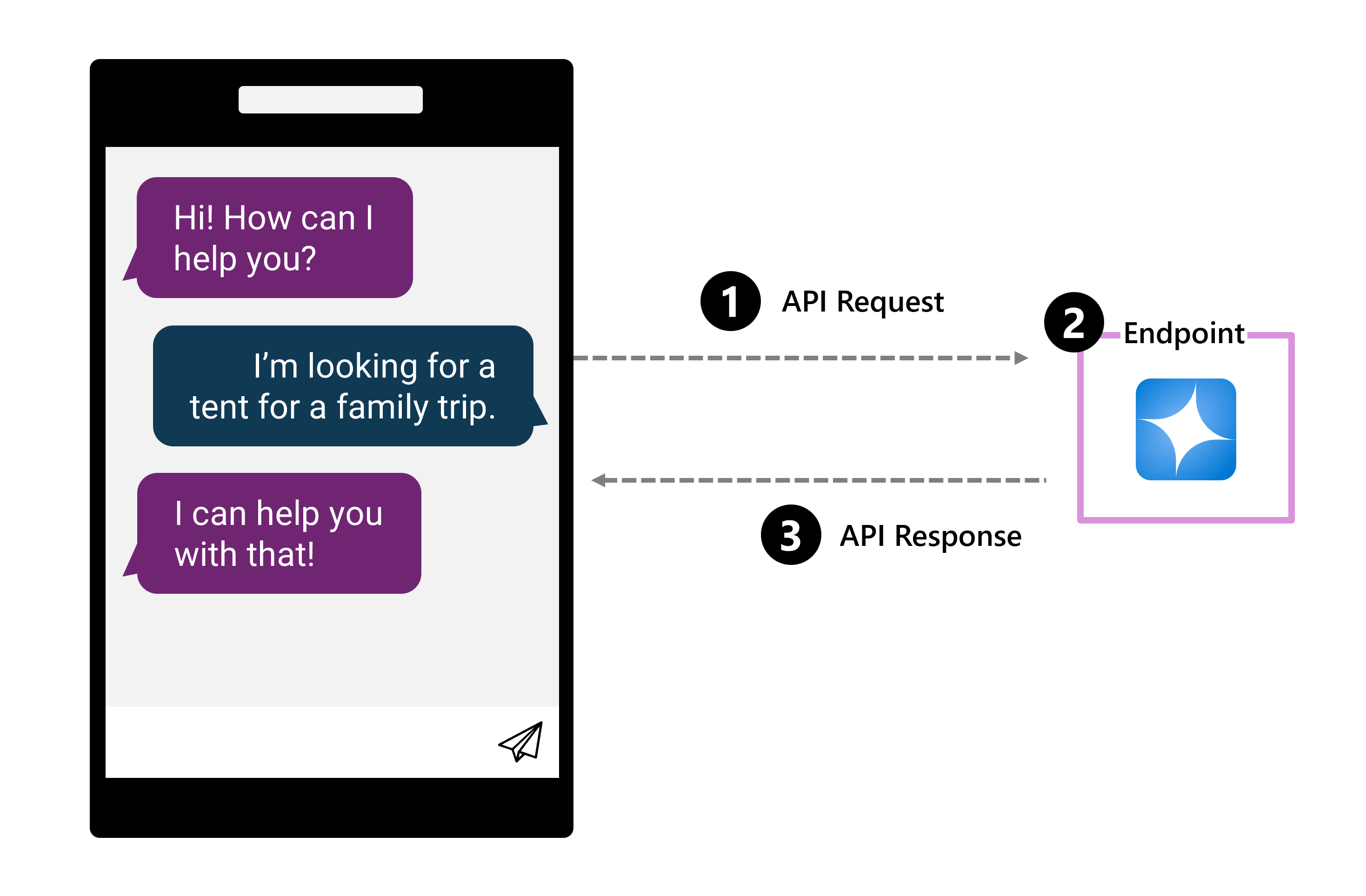
Model językowy można zintegrować z aplikacją czatu, wdrażając model w punkcie końcowym. Punkt końcowy to określony adres URL, pod którym można uzyskać dostęp do wdrożonego modelu lub usługi. Każde wdrożenie modelu zwykle ma własny unikatowy punkt końcowy, który umożliwia różnym aplikacjom komunikowanie się z modelem za pośrednictwem interfejsu API (Interfejs programowania aplikacji).
Gdy użytkownik zadaje pytanie:
- Żądanie interfejsu API jest wysyłane do punktu końcowego.
- Punkt końcowy określa model, który przetwarza żądanie.
- Wynik jest wysyłany z powrotem do aplikacji za pośrednictwem odpowiedzi interfejsu API.
Teraz, gdy już wiesz, dlaczego chcesz wdrożyć model, zapoznajmy się z opcjami wdrażania za pomocą rozwiązania Microsoft Foundry.
Wdrażanie modelu językowego za pomocą rozwiązania Microsoft Foundry
Podczas wdrażania modelu językowego za pomocą rozwiązania Microsoft Foundry dostępnych jest kilka typów, które zależą od modelu, który chcesz wdrożyć.
Opcje wdrażania obejmują:
- Wdrożenie standardowe: modele są hostowane w zasobie projektu Microsoft Foundry.
- Przetwarzanie bezserwerowe: modele są hostowane w dedykowanych punktach końcowych bezserwerowych zarządzanych przez firmę Microsoft w projekcie centrum Microsoft Foundry.
- Zarządzane zasoby obliczeniowe: modele są hostowane w zarządzanych obrazach maszyn wirtualnych w projekcie centrum Microsoft Foundry.
Skojarzony koszt zależy od typu wdrażanego modelu, wybranej opcji wdrożenia i tego, co robisz z modelem:
| Wdrażanie standardowe | Bezserwerowe obliczenia | Zarządzane obliczenia | |
|---|---|---|---|
| Obsługiwane modele | Modele rozwiązania Microsoft Foundry (w tym modele azure OpenAI i modele jako usługa) | Modele Foundry z rozliczeniami w modelu płatności za użycie | Otwarte i modele niestandardowe |
| Usługa hostingu | Zasób Microsoft Foundry | Zasób projektu sztucznej inteligencji w centrum | Zasób projektu sztucznej inteligencji w centrum |
| Podstawa rozliczeń | Rozliczenia oparte na tokenach | Rozliczenia oparte na tokenach | Rozliczenia oparte na obliczeniach |
Uwaga / Notatka
Wdrożenie standardowe jest zalecane w przypadku większości scenariuszy.