Indeksy projektu
Program SQL Server oferuje kilka typów indeksów do obsługi różnych obciążeń. Na wysokim poziomie indeks można traktować jako strukturę dysku skojarzona z tabelą lub widokiem, umożliwiając programowi SQL Server łatwiejsze znajdowanie wierszy lub wierszy skojarzonych z kluczem indeksu (który składa się z co najmniej jednej kolumny w tabeli lub widoku) w porównaniu ze skanowaniem całej tabeli.
Indeksy klastrowane
Typowym pytaniem na wywiad z zadaniem administratora bazy danych jest zadawanie kandydatowi różnicy między indeksem klastrowanym i nieklastrowanym, ponieważ indeksy są podstawowymi technologiami przechowywania danych w programie SQL Server. Indeks klastrowany to tabela bazowa przechowywana w kolejności posortowanej na podstawie wartości klucza. W danej tabeli może istnieć tylko jeden indeks klastrowany, ponieważ wiersze mogą być przechowywane tylko w jednej kolejności. Tabela bez indeksu klastrowanego jest nazywana stertą, a sterta jest zwykle używana tylko jako tabela przejściowa. Ważną zasadą projektowania wydajności jest utrzymanie klucza indeksu klastrowanego tak wąskiego, jak to możliwe. Podczas rozważania co najmniej jednej kolumny klucza dla indeksu klastrowanego należy wybrać kolumny, które są unikatowe lub zawierają wiele odrębnych wartości. Kolejną cechą dobrego klastrowanego klucza indeksu jest jego zdolność do obsługi rekordów uzyskiwanych sekwencyjnie oraz częste użycie do sortowania danych pobranych z tabeli. Posiadanie indeksu klastrowanego w kolumnie używanej do sortowania może zapobiec kosztowi sortowania za każdym razem, gdy zapytanie jest wykonywane, ponieważ dane będą już przechowywane w żądanej kolejności.
Uwaga
Gdy mówimy, że tabela jest "przechowywana" w określonej kolejności, odnosimy się do kolejności logicznej, a nie fizycznej, na dysku. Indeksy mają wskaźniki między stronami, a wskaźniki pomagają utworzyć kolejność logiczną. Podczas skanowania indeksu w kolejności program SQL Server podąża za wskaźnikami z jednej strony do drugiej. Natychmiast po utworzeniu indeksu najprawdopodobniej jest on również przechowywany w fizycznej kolejności na dysku. Jednak po rozpoczęciu wprowadzania modyfikacji danych i dodawania nowych stron do indeksu, wskaźniki nadal zapewnią nam prawidłową kolejność logiczną, ale nowe strony najprawdopodobniej nie będą w fizycznej kolejności na dysku.
Indeksy nieklastrowane
Indeksy nieklastrowane są oddzielnymi strukturami od wierszy danych. Indeks nieklastrowany zawiera wartości klucza zdefiniowane dla indeksu i wskaźnik do wiersza danych zawierającego wartość klucza. Możesz dodać dodatkowe kolumny niebędące kluczami do poziomu liści indeksu nieklastrowanego z użyciem funkcji dołączania kolumn w programie SQL Server, pozwalając na objęcie większej liczby kolumn. W tabeli można utworzyć wiele indeksów nieklastrowanych.
W poniższym przykładzie pokazano, kiedy trzeba dodać indeks lub dodać kolumny do istniejącego indeksu nieklastrowanego.

Plan zapytania wskazuje, że dla każdego wiersza pobranego przy użyciu wyszukiwania indeksu należy pobrać więcej danych z klastrowanego indeksu (samej tabeli). Istnieje indeks nieklastrowany, ale zawiera tylko kolumnę produktu. Jeśli dodasz pozostałe kolumny z zapytania do indeksu nieklastrowanego, zobaczysz zmianę planu wykonywania, aby wyeliminować wyszukiwanie klucza.
Zmiana indeksu i planu zapytania bez wyszukiwania kluczy
Utworzony powyżej indeks jest przykładem indeksu obejmującego. Oprócz kolumny klucza dołączasz dodatkowe kolumny do obsłużenia zapytania i eliminujesz potrzebę uzyskiwania dostępu do samej tabeli.
Zarówno indeksy nieklastrowane, jak i klastrowane można zdefiniować jako unikatowe, co oznacza, że nie można duplikować wartości kluczy. Indeksy unikatowe są tworzone automatycznie podczas tworzenia klucza podstawowego lub ograniczenia UNIKATOWEGO w tabeli.
Ta sekcja koncentruje się na indeksach b-tree w programie SQL Server, nazywanych również indeksami magazynu wierszy. Na poniższej ilustracji przedstawiono ogólną strukturę drzewa b:
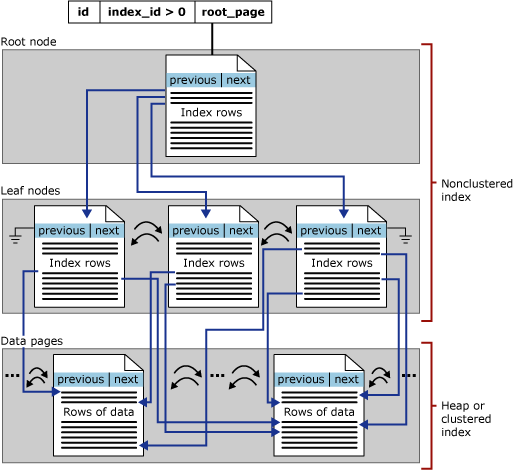
Każda strona w drzewie indeksu b-tree jest nazywana węzłem indeksu, a górny węzeł drzewa b jest nazywany węzłem głównym. Węzły dolne w indeksie są nazywane węzłami liścia, a kolekcja węzłów liścia jest poziomem liścia.
Projektowanie indeksu to mieszanka sztuki i nauki. Wąski indeks z kilkoma kolumnami w kluczu wymaga mniej czasu na aktualizację i ma mniejsze obciążenie konserwacyjne; jednak może nie być przydatne w przypadku tak wielu zapytań, jak szerszy indeks, który zawiera więcej kolumn. Może być konieczne eksperymentowanie z kilkoma metodami indeksowania na podstawie kolumn wybranych przez zapytania aplikacji. Optymalizator zapytań zazwyczaj wybiera to, co uważa za najlepszy istniejący indeks dla zapytania; nie oznacza to jednak, że nie ma lepszego indeksu, który można utworzyć.
Prawidłowe indeksowanie bazy danych może być złożonym zadaniem. Podczas planowania indeksów dla tabeli należy pamiętać o kilku podstawowych zasadach:
- Omówienie obciążeń systemu. Tabele używane głównie do operacji wstawiania korzystają mniej z dodatkowych indeksów w porównaniu z tabelami używanymi do operacji magazynu danych z dużą aktywnością odczytu.
- Zoptymalizuj indeksy wokół najczęściej uruchamianych zapytań.
- Wybierz odpowiednie typy danych dla kolumn w zapytaniach. Indeksy działają najlepiej w przypadku typów danych całkowitych, kolumn unikatowych lub innych niż null.
- Utwórz indeksy nieklastrowane dla kolumn często używanych w predykatach i klauzulach sprzężenia, zachowując je tak wąskie, jak to możliwe, aby zminimalizować obciążenie.
- Rozważ rozmiar/wolumin danych. Skanowania tabel w małych tabelach są stosunkowo tanie, a skanowania w dużych tabelach są kosztowne.
Inną opcją zapewnianą przez program SQL Server jest utworzenie filtrowanych indeksów. Indeksy filtrowane są idealne w przypadku kolumn w dużych tabelach, w których znaczna część wierszy ma taką samą wartość w tej kolumnie. Poniższy przykład to tabela pracowników, w której są przechowywane rekordy wszystkich pracowników, w tym osób, które opuściły lub wycofały się.
CREATE TABLE [HumanResources].[Employee](
[BusinessEntityID] [int] NOT NULL,
[NationalIDNumber] [nvarchar](15) NOT NULL,
[LoginID] [nvarchar](256) NOT NULL,
[OrganizationNode] [hierarchyid] NULL,
[OrganizationLevel] AS ([OrganizationNode].[GetLevel]()),
[JobTitle] [nvarchar](50) NOT NULL,
[BirthDate] [date] NOT NULL,
[MaritalStatus] [nchar](1) NOT NULL,
[Gender] [nchar](1) NOT NULL,
[HireDate] [date] NOT NULL,
[SalariedFlag] [bit] NOT NULL,
[VacationHours] [smallint] NOT NULL,
[SickLeaveHours] [smallint] NOT NULL,
[CurrentFlag] [bit] NOT NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL)
W tej tabeli znajduje się kolumna o nazwie CurrentFlag, która wskazuje, czy pracownik jest obecnie zatrudniony. W tym przykładzie użyto bit typu danych reprezentującego dwie wartości: jedną dla aktualnie zatrudnionych i zero dla aktualnie niezatrudnionych. Utworzenie filtrowanego indeksu WHERE CurrentFlag = 1 z kolumną CurrentFlag umożliwia wydajne wykonywanie zapytań dotyczących bieżących pracowników.
Ponadto można tworzyć indeksy w widokach, co może zapewnić znaczne wzrosty wydajności, gdy widoki zawierają elementy zapytania, takie jak agregacje i/lub sprzężenia tabeli.
Indeksy kolumnowe
Indeksy kolumnowe oferują zwiększoną wydajność zapytań dotyczących dużych obciążeń agregacyjnych. Początkowo ukierunkowane na magazyny danych indeksy kolumnowe zostały zaadaptowane do różnych innych obciążeń w celu rozwiązania problemów z wydajnością zapytań w dużych tabelach. Podobnie jak indeksy b-tree, indeks klastrowanego magazynu kolumn reprezentuje samą tabelę przechowywaną w specjalny sposób, podczas gdy indeksy magazynu kolumn nieklastrowanych są przechowywane niezależnie od tabeli. Klastrowane indeksy magazynu kolumn z założenia zawierają wszystkie kolumny w tabeli, ale nie są sortowane.
Indeksy kolumnowe nieklastrowane są zazwyczaj używane w dwóch scenariuszach. Pierwszy to, gdy typ danych kolumny nie jest obsługiwany w indeksie magazynu kolumn (na przykład XML, CLR, sql_variant, ntext, text i image). Ponieważ indeks klastrowanego magazynu kolumn zawsze zawiera wszystkie kolumny tabeli, indeks nieklastrowany jest jedyną opcją. Drugi scenariusz obejmuje indeksy filtrowane, używane w hybrydowych architekturach przetwarzania analitycznego transakcyjnego (HTAP), gdzie dane są ładowane do tabeli, gdy raporty są uruchamiane jednocześnie. Filtrowanie indeksu (zazwyczaj na polu daty) umożliwia wydajność wstawiania i generowania raportów.
Indeksy magazynowania kolumn przechowują każdą kolumnę niezależnie, oferując dwie korzyści: zmniejszoną liczbę operacji wejścia/wyjścia przez skanowanie tylko niezbędnych kolumn oraz większą kompresję dzięki podobnym danym w obrębie kolumn. Działają najlepiej w przypadku zapytań analitycznych skanujących duże zestawy danych, takich jak tabele faktów w magazynach danych. Indeks columnstore można rozszerzyć za pomocą nieklastrowanego indeksu drzewa B dla wyszukiwań wartości pojedynczej.
Te indeksy również korzystają z trybu wykonywania wsadowego, który umożliwia przetwarzanie zestawów wierszy (zazwyczaj około 900) jednocześnie, zamiast przetwarzać je pojedynczo. Takie podejście znacznie zmniejsza instrukcje procesora CPU.
SELECT SUM(Sales) FROM SalesAmount;
Tryb wsadowy może zapewnić wzrost wydajności w porównaniu z tradycyjnym przetwarzaniem wierszy. Chociaż tryb wsadowy dla magazynu wierszy nie ma takiego samego poziomu wydajności odczytu jak indeks magazynu kolumn, zapytania analityczne mogą osiągnąć do 5-krotnej poprawy wydajności.
Kolejną zaletą indeksów kolumnowych przy pracy z obciążeniami magazynów danych jest zoptymalizowana ścieżka ładowania dla zbiorczego wstawiania 102 400 wierszy lub więcej. Chociaż 102 400 jest minimalną wartością do załadowania bezpośrednio do magazynu kolumn, każda kolekcja wierszy nazywana grupą wierszy może wynosić do około 1024 000 wierszy. Posiadanie mniejszej liczby, ale pełniejszych grup wierszy sprawia, że zapytania są SELECT wydajniejsze, ponieważ aby pobrać żądane rekordy, należy przeskanować mniej grup wierszy. Te obciążenia występują w pamięci i są bezpośrednio ładowane do indeksu. W przypadku mniejszych woluminów dane są zapisywane w strukturze drzewa B zwanej "delta store" i asynchronicznie ładowane do indeksu.
Przykład Ładowania Indeksu Columnstore
W tym przykładzie te same dane są ładowane do dwóch tabel, FactResellerSales_CCI_Demo i FactResellerSales_Page_Demo.
FactResellerSales_CCI_Demo ma indeks klastrowanego magazynu kolumn, a FactResellerSales_Page_Demo ma klastrowany indeks typu b-tree z dwiema kolumnami, skompresowany stronami. Jak widać, każda tabela ładuje 1 024 000 wierszy z tabeli FactResellerSalesXL_CCI. Gdy SET STATISTICS TIME parametr to ON, program SQL Server śledzi czas, który upłynął podczas wykonywania zapytania. Załadowanie danych do tabeli z magazynowaniem kolumnowym trwało około 8 sekund, podczas gdy ładowanie do tabeli z kompresją stron trwało prawie 20 sekund. W tym przykładzie wszystkie wiersze trafiające do indeksu magazynującego kolumny są ładowane do pojedynczej grupy wierszy.
Jeśli załadujesz mniej niż 102 400 wierszy danych do indeksu magazynu kolumnowego podczas jednej operacji, zostanie on załadowany w strukturze drzewa B, znanej jako magazyn różnicowy. Silnik bazy danych przenosi te dane do indeksu magazynu kolumn przy użyciu asynchronicznego procesu nazywanego tuple mover. Posiadanie otwartych baz danych typu delta może wpłynąć na wydajność zapytań, ponieważ odczytywanie tych rekordów jest mniej efektywne niż odczytywanie z magazynu kolumn. Indeks można również zreorganizować przy użyciu opcji COMPRESS_ALL_ROW_GROUPS, aby wymusić dodanie i skompresowanie magazynów różnicowych w indeksach magazynu kolumn.