Identyfikowanie problematycznych planów zapytań
Typowe podejście, które polega na rozwiązaniu problemów z wydajnością zapytań, polega najpierw na zidentyfikowaniu problematycznego zapytania, zwykle zużywającego większość zasobów systemowych, a następnie pobieraniu planu wykonania. Istnieją dwa główne scenariusze. Jednym ze scenariuszy jest to, że zapytanie stale działa słabo. Może to być spowodowane różnymi problemami, takimi jak ograniczenia zasobów sprzętowych (choć zwykle nie ma to wpływu na pojedyncze zapytanie uruchomione w izolacji), nieoptymalną strukturę zapytań, ustawienia zgodności bazy danych, brakujące indeksy lub słabe wybory planu przez optymalizator zapytań. Drugi scenariusz polega na tym, że zapytanie działa dobrze w niektórych wykonaniach, ale słabo w innych. Ta niespójność może być spowodowana czynnikami, takimi jak niesymetryczność danych w sparametryzowanym zapytaniu, który ma wydajny plan niektórych wykonań i słaby dla innych. Inne typowe czynniki obejmują blokowanie, gdzie zapytanie czeka na ukończenie innego zapytania w celu uzyskania dostępu do tabeli lub rywalizacji sprzętowej.
Przyjrzyjmy się dokładniej każdemu z tych scenariuszy.
Ograniczenia sprzętowe
Ograniczenia sprzętowe zwykle nie manifestują się podczas wykonywania pojedynczych zapytań, ale stają się widoczne pod obciążeniem produkcyjnym, gdy wątki procesora CPU i pamięć są ograniczone. Rywalizację o procesor cpu można wykryć, obserwując licznik monitora wydajności "% czas procesora", który mierzy użycie procesora serwera. W programie SQL Server typy oczekiwania SOS_SCHEDULER_YIELD i CXPACKET mogą wskazywać na obciążenie procesora. Niska wydajność systemu magazynowania może spowolnić nawet zoptymalizowane pojedyncze wykonania zapytań. Wydajność magazynu jest najlepiej śledzona na poziomie systemu operacyjnego przy użyciu liczników monitora wydajności i Disk Seconds/Read, które mierzą czasy ukończenia operacji we/wyDisk Seconds/Write. Program SQL Server rejestruje niską wydajność magazynu, jeśli we/wy trwa dłużej niż 15 sekund. Wysokie czasy oczekiwania PAGEIOLATCH_SH w programie SQL Server mogą wskazywać na problemy z wydajnością pamięci. Wydajność sprzętu jest zwykle oceniana na wczesnym etapie procesu rozwiązywania problemów ze względu na łatwość oceny.
Większość problemów z wydajnością bazy danych wynika z nieoptymalnych wzorców zapytań, które mogą wywierać nadmierną presję na sprzęt. Na przykład brakujące indeksy mogą prowadzić do wykorzystania procesora CPU, magazynu i pamięci przez pobranie większej ilości danych niż jest to konieczne. Zaleca się rozwiązywanie i dostosowywanie nieoptymalnych zapytań przed rozwiązaniem problemów sprzętowych. Następnie przyjrzymy się dostrajaniu zapytań.
Nieoptymalne konstrukcje zapytań
Relacyjne bazy danych działają najlepiej podczas wykonywania operacji opartych na zestawie, które manipulują danymi (INSERT, UPDATE, DELETEi SELECT) w zestawach, tworząc pojedynczą wartość lub zestaw wyników. Alternatywą jest przetwarzanie oparte na wierszach, przy użyciu kursorów lub pętli while, które zwiększają koszty liniowo z liczbą wierszy, których dotyczy problem — problematyczną skalę w miarę wzrostu ilości danych.
Wykrywanie nieoptymalnego użycia operacji opartych na wierszach z kursorami lub pętlami WHILE jest ważne, ale istnieją inne wzorce anty-wzorce programu SQL Server do rozpoznania. Funkcje wyceniane w tabelach (TVFs), szczególnie wielowydajne pliki TVFs, spowodowały problematyczne wzorce planu wykonywania przed programem SQL Server 2017. Deweloperzy często używają funkcji TVFs z wieloma instrukcjami do wykonywania wielu zapytań w ramach jednej funkcji i agregowania wyników w jednej tabeli. Jednak użycie funkcji TVF może prowadzić do kar za wydajność.
Program SQL Server ma dwa typy plików TVFs: wbudowane i wieloiserowe. Wbudowane funkcje TVF są traktowane jak widoki, podczas gdy wieloiseksowe pliki TVF są traktowane jak tabele podczas przetwarzania zapytań. Ponieważ pliki TVFs są dynamiczne i brakuje statystyk, program SQL Server używa stałej liczby wierszy do szacowania kosztów planu zapytania. Może to być w porządku w przypadku małych liczb wierszy, ale nieefektywne dla tysięcy lub milionów wierszy.
Innym antywzorem jest użycie funkcji skalarnych, które mają podobne problemy z szacowaniem i wykonywaniem. Firma Microsoft wprowadziła znaczne ulepszenia wydajności dzięki inteligentnej przetwarzaniu zapytań na poziomie zgodności 140 i 150.
SARGability
Termin SARGable w relacyjnych bazach danych odnosi się do predykatu (WHERE klauzuli) sformatowanego do używania indeksu w celu przyspieszenia wykonywania zapytań. Predykaty w poprawnym formacie są nazywane "Argumentami wyszukiwania" lub SARG. W programie SQL Server użycie SARG oznacza, że optymalizator wykorzystuje indeks nieklastrowany w kolumnie, na którą wskazuje SARG, dla operacji WYSZUKIWANIA, zamiast skanować cały indeks lub tabelę w celu pobrania wartości.
Obecność SARG nie gwarantuje użycia indeksu dla funkcji SEEK. Algorytmy kosztowania optymalizatora mogą nadal określać, że indeks jest zbyt kosztowny, zwłaszcza jeśli sarG odnosi się do dużej wartości procentowej wierszy w tabeli. Brak SARG oznacza, że optymalizator nie oceni funkcji SEEK na indeksie nieklastrowanym.
Przykłady wyrażeń innych niż SARGable obejmują te z klauzulą LIKE używającą symbolu wieloznakowego na początku ciągu, na przykład WHERE lastName LIKE '%SMITH%'. Inne predykaty inne niż SARGable występują podczas korzystania z funkcji w kolumnie, takich jak WHERE CONVERT(CHAR(10), CreateDate,121) = '2020-03-22'. Te zapytania są zwykle identyfikowane przez badanie planów wykonywania dla skanowania indeksu lub tabeli, w których wyszukiwanie powinno wystąpić w przeciwnym razie.
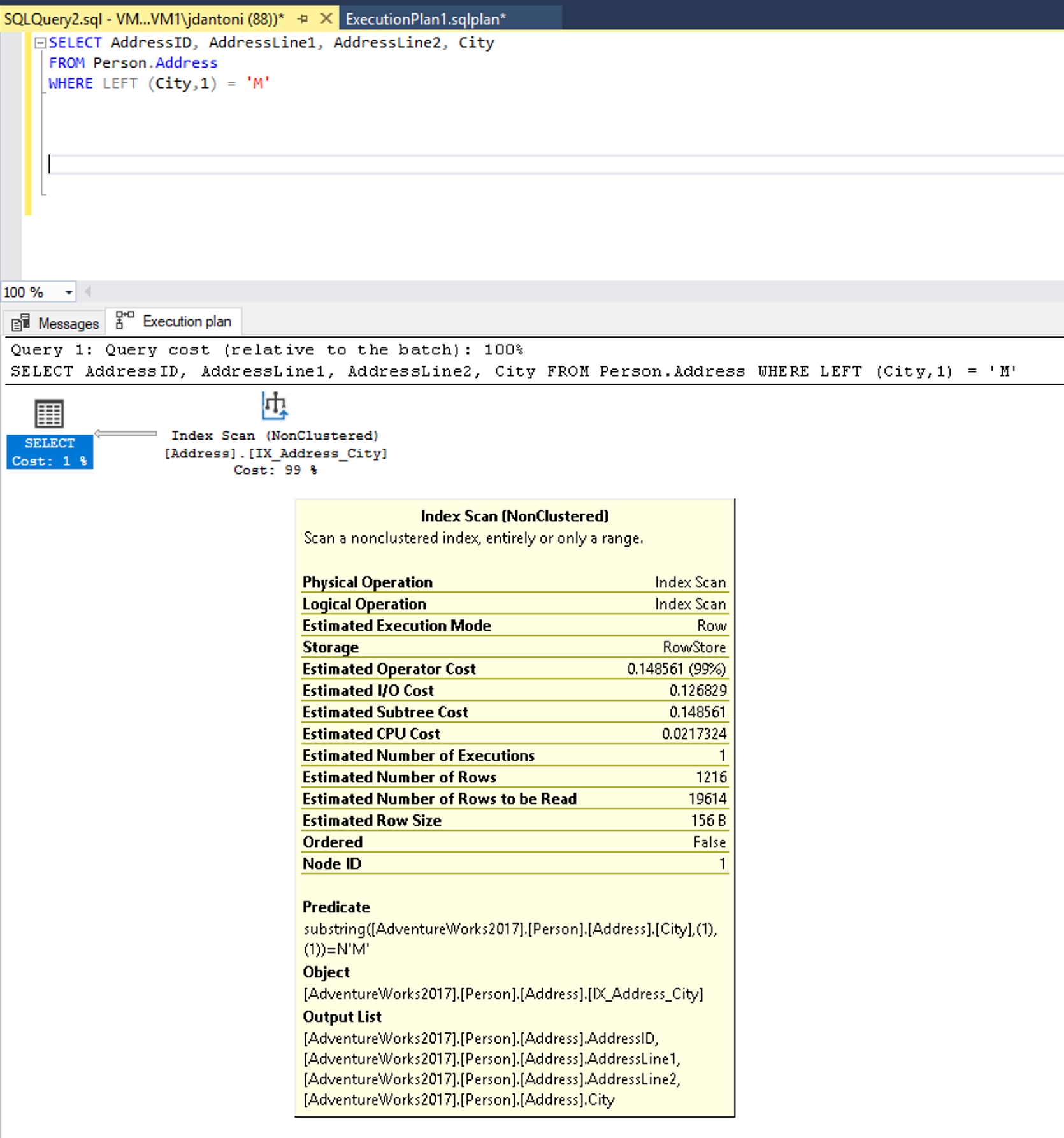
W kolumnie City (Miasto ) znajduje się indeks, który jest używany w WHERE klauzuli zapytania i gdy jest używany w powyższym planie wykonywania, można zobaczyć, że indeks jest skanowany, co oznacza, że cały indeks jest odczytywany. Funkcja LEFT w predykacie sprawia, że to wyrażenie nie jest sargable. Optymalizator nie będzie używał wyszukiwania indeksu na indeksie w kolumnie City.
To zapytanie można napisać, aby użyć predykatu, który jest SARGable. Optymalizator następnie wykona operację SEEK na indeksie w kolumnie Miasto. W tym przypadku operator wyszukiwania indeksu odczytuje mniejszy zestaw wierszy.
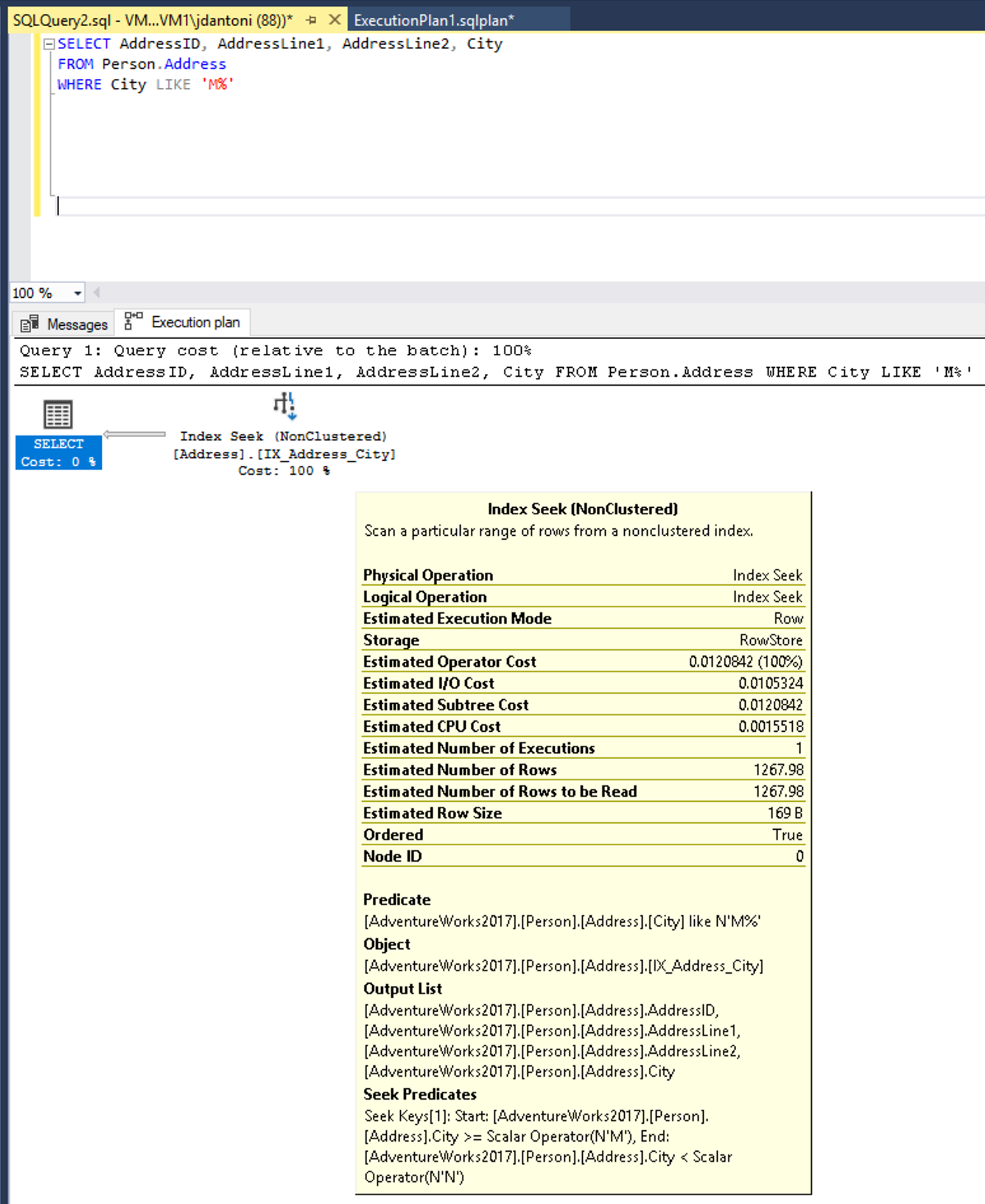
Zmiana funkcji LEFT na LIKE powoduje wyszukiwanie indeksu.
Uwaga
Słowo LIKE kluczowe w tym przykładzie nie ma symbolu wieloznakowego po lewej stronie, więc szuka miast, które zaczynają się od języka M. Gdyby to było "dwustronne" lub zaczęło się od symbolu wieloznacznych ('%M%' lub '%M') byłoby nie-SARGable. Szacuje się, że operacja wyszukiwania zwróci 1267 wierszy lub około 15% oszacowania dla zapytania z predykatem niezwiązanym z sargable.
Niektóre inne wzorce anty-wzorce programistyczne bazy danych traktują bazę danych jako usługę, a nie magazyn danych. Użycie bazy danych do konwertowania danych na format JSON, manipulowanie ciągami lub wykonywanie złożonych obliczeń może prowadzić do nadmiernego użycia procesora CPU i zwiększonego opóźnienia. Zapytania, które próbują pobrać wszystkie rekordy, a następnie wykonywać obliczenia w bazie danych, mogą prowadzić do nadmiernego użycia operacji we/wy i procesora CPU. W idealnym przypadku należy użyć bazy danych na potrzeby operacji dostępu do danych i zoptymalizowanych konstrukcji bazy danych, takich jak agregacja.
Brakujące indeksy
Najczęstsze problemy z wydajnością administratorów baz danych wynikają z braku przydatnych indeksów, co powoduje, że aparat odczytuje więcej stron niż jest to konieczne w celu zwrócenia wyników zapytania. Podczas gdy indeksy zużywają zasoby (wpływające na wydajność zapisu i zużywające miejsce), ich wydajność często przewyższa dodatkowe koszty zasobów. Plany wykonywania z tymi problemami można zidentyfikować za pomocą operatora zapytania Skanowanie indeksu klastrowanego lub kombinacji wyszukiwania indeksu nieklastrowanego i wyszukiwania kluczy wskazujących brakujące kolumny w istniejącym indeksie.
Aparat bazy danych pomaga w raportowaniu brakujących indeksów w planach wykonywania. Nazwy i szczegóły zalecanych indeksów są dostępne za pośrednictwem dynamicznego widoku sys.dm_db_missing_index_detailszarządzania. Inne dynamiczne widoki zarządzania, takie jak sys.dm_db_index_usage_stats i sys.dm_db_index_operational_stats wyróżnić wykorzystanie istniejących indeksów.
Usunięcie nieużywanego indeksu może być rozsądne. Brak widoków DMV indeksu i ostrzeżeń dotyczących planu powinny być punktami początkowymi dla dostrajania zapytań. Kluczowe znaczenie ma zrozumienie kluczowych zapytań i tworzenie indeksów w celu ich obsługi. Tworzenie wszystkich brakujących indeksów bez oceniania ich w kontekście nie jest zalecane.
Brakujące i nieaktualne statystyki
Zrozumienie znaczenia statystyk kolumn i indeksów dla optymalizatora zapytań ma kluczowe znaczenie. Istotne jest również rozpoznawanie warunków, które mogą prowadzić do nieaktualnych statystyk i sposobu, w jaki ten problem może manifestować się w programie SQL Server. Oferty usługi Azure SQL domyślnie mają ustawioną statystykę automatycznego aktualizacji na WŁ. Przed programem SQL Server 2016 domyślne zachowanie statystyk automatycznej aktualizacji polegało na tym, aby nie aktualizować statystyk, dopóki liczba modyfikacji kolumn w indeksie nie będzie równa około 20% liczby wierszy w tabeli. Takie zachowanie może spowodować znaczące modyfikacje danych, które zmieniają wydajność zapytań bez aktualizowania statystyk, co prowadzi do nieoptymalnych planów opartych na nieaktualnych statystykach.
Przed programem SQL Server 2016 można użyć flagi śledzenia 2371, aby zmienić wymaganą liczbę modyfikacji wartości dynamicznej, więc w miarę wzrostu tabeli odsetek modyfikacji wierszy potrzebnych do wyzwolenia aktualizacji statystyk zmniejszył się. Nowsze wersje programów SQL Server, Azure SQL Database i Azure SQL Managed Instance domyślnie obsługują to zachowanie. Funkcja dynamicznego zarządzania sys.dm_db_stats_properties pokazuje czas ostatniej aktualizacji statystyk i liczbę modyfikacji od ostatniej aktualizacji, co pozwala szybko zidentyfikować statystyki, które mogą wymagać aktualizacji ręcznych.
Słabe opcje optymalizatora
Podczas gdy optymalizator zapytań wykonuje dobrą robotę optymalizacji większości zapytań, istnieją pewne przypadki brzegowe, w których optymalizator oparty na kosztach może podejmować decyzje wpływające na niezrozumiane. Istnieje wiele sposobów rozwiązania tego problemu, w tym przy użyciu wskazówek dotyczących zapytań, flag śledzenia, wymuszania planu wykonania i innych korekt w celu osiągnięcia stabilnego i optymalnego planu zapytania. Firma Microsoft ma zespół pomocy technicznej, który może pomóc w rozwiązywaniu problemów z tymi scenariuszami.
W poniższym przykładzie z bazy danych AdventureWorks2017 jest używana wskazówka zapytania, aby powiedzieć optymalizatorowi bazy danych, aby zawsze używać nazwy miasta Seattle. Ta wskazówka nie gwarantuje najlepszego planu wykonania dla wszystkich wartości miasta, ale jest przewidywalna. Wartość "Seattle" dla @city_name parametru będzie używana tylko podczas optymalizacji. Podczas wykonywania jest używana rzeczywista podana wartość (‘Ascheim’) .
DECLARE @city_name nvarchar(30) = 'Ascheim',
@postal_code nvarchar(15) = 86171;
SELECT *
FROM Person.Address
WHERE City = @city_name
AND PostalCode = @postal_code
OPTION (OPTIMIZE FOR (@city_name = 'Seattle');
Jak pokazano w przykładzie, zapytanie korzysta ze wskazówki (klauzuli OPTION), aby poinformować optymalizatora o użyciu określonej wartości zmiennej do zbudowania planu wykonania.
Wąchanie parametrów
Program SQL Server buforuje plany wykonywania zapytań na potrzeby przyszłego użycia. Ponieważ proces pobierania planu wykonywania jest oparty na wartości skrótu zapytania, tekst zapytania musi być identyczny dla każdego wykonania zapytania dla buforowanego planu. Aby obsługiwać wiele wartości w tym samym zapytaniu, wielu deweloperów używa parametrów przekazywanych za pomocą procedur składowanych, jak pokazano w poniższym przykładzie:
CREATE PROC GetAccountID (@Param INT)
AS
<other statements in procedure>
SELECT accountid FROM CustomerSales WHERE sales > @Param;
<other statements in procedure>
RETURN;
-- Call the procedure:
EXEC GetAccountID 42;
Zapytania można również jawnie sparametryzować przy użyciu procedury sp_executesql. Jednak jawna parametryzacja poszczególnych zapytań odbywa się w aplikacji za pomocą jakiejś formy (PREPARE i EXECUTE, w zależności od interfejsu API). Gdy aparat bazy danych wykonuje to zapytanie po raz pierwszy, optymalizuje zapytanie na podstawie początkowej wartości parametru, w tym przypadku 42. To zachowanie, nazywane sniffing parametru, umożliwia zmniejszenie ogólnego obciążenia kompilowania zapytań na serwerze. Jednak w przypadku niesymetryczności danych wydajność zapytań może się znacznie różnić.
Na przykład tabela zawierająca 10 milionów rekordów, a 99% tych rekordów ma identyfikator 1, a pozostałe 1% są unikatowymi liczbami, wydajność jest oparta na tym, który identyfikator został początkowo użyty do optymalizacji zapytania. Ta szalenie zmienna wydajność wskazuje na niesymetryczność danych i nie jest nieodłącznym problemem z sniffing parametru. To zachowanie jest dość typowym problemem z wydajnością, o którym należy pamiętać. Należy zapoznać się z opcjami łagodzenia problemu. Istnieje kilka sposobów rozwiązania tego problemu, ale każdy z nich pochodzi z kompromisów:
- Użyj wskazówki
RECOMPILEw swoim zapytaniu lub opcji wykonywaniaWITH RECOMPILEw procedurach składowanych. Ta wskazówka powoduje ponowne skompilowanie zapytania lub procedury przy każdym jego wykonaniu, co zwiększy wykorzystanie procesora CPU na serwerze, ale zawsze będzie używać bieżącej wartości parametru. - Możesz użyć
OPTIMIZE FOR UNKNOWNwskazówki dotyczącej zapytania. Ta wskazówka powoduje, że optymalizator zdecyduje się nie wąchać parametrów i porównać wartość z histogramem danych kolumny. Ta opcja nie uzyska najlepszego możliwego planu, ale pozwoli na spójny plan wykonania. - Ponownie zapisz procedurę lub zapytania, dodając logikę wokół wartości parametrów tylko do funkcji RECOMPILE dla znanych kłopotliwych parametrów. W poniższym przykładzie, jeśli parametr SalesPersonID ma wartość NULL, zapytanie jest wykonywane przy użyciu .
OPTION (RECOMPILE)
CREATE OR ALTER PROCEDURE GetSalesInfo (@SalesPersonID INT = NULL)
AS
DECLARE @Recompile BIT = 0
, @SQLString NVARCHAR(500)
SELECT @SQLString = N'SELECT SalesOrderId, OrderDate FROM Sales.SalesOrderHeader WHERE SalesPersonID = @SalesPersonID'
IF @SalesPersonID IS NULL
BEGIN
SET @Recompile = 1
END
IF @Recompile = 1
BEGIN
SET @SQLString = @SQLString + N' OPTION(RECOMPILE)'
END
EXEC sp_executesql @SQLString
,N'@SalesPersonID INT'
,@SalesPersonID = @SalesPersonID
GO
Ten przykład jest dobrym rozwiązaniem, ale wymaga dość dużego nakładu pracy deweloperskiej i zdecydowanego zrozumienia dystrybucji danych. Wymaga to konserwacji w miarę zmian danych.