Co to jest uczenie maszynowe?
Uczenie maszynowe ma swoje początki w statystykach i modelowaniu matematycznym danych. Podstawową ideą uczenia maszynowego jest użycie danych z poprzednich obserwacji w celu przewidywania nieznanych wyników lub wartości. Na przykład:
- Właściciel sklepu z lodami może użyć aplikacji, która łączy historyczne rekordy sprzedaży i pogody, aby przewidzieć, ile lodów prawdopodobnie sprzeda w danym dniu, na podstawie prognozy pogody.
- Lekarz może używać danych klinicznych od poprzednich pacjentów do przeprowadzania testów automatycznych, które przewidują, czy nowy pacjent jest zagrożony cukrzycą na podstawie czynników, takich jak waga, poziom glukozy we krwi i inne pomiary.
- Badacz na Antarktydzie może używać wcześniejszych obserwacji automatyzować identyfikację różnych gatunków pingwinów (takich jak Adelie, Gentoo lub Chinstrap) na podstawie pomiarów flipperów ptaków, rachunku i innych atrybutów fizycznych.
Uczenie maszynowe jako funkcja
Ponieważ uczenie maszynowe opiera się na matematyce i statystykach, często należy myśleć o modelach uczenia maszynowego w kategoriach matematycznych. Zasadniczo model uczenia maszynowego to aplikacja programowa, która hermetyzuje funkcję w celu obliczenia wartości wyjściowej na podstawie co najmniej jednej wartości wejściowej. Proces definiowania tej funkcji jest nazywany trenowaniem. Po zdefiniowaniu funkcji można jej użyć do przewidywania nowych wartości w procesie nazywanym wnioskowaniem.
Przyjrzyjmy się krokom zaangażowanym w trenowanie i wnioskowanie.
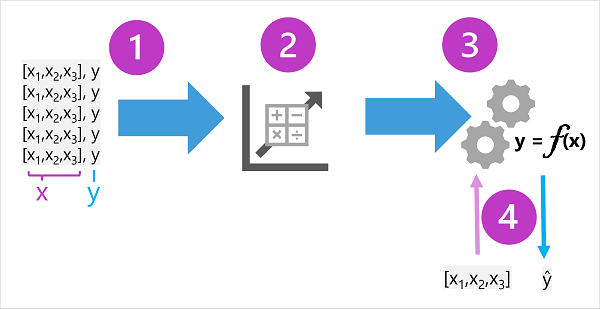
Dane szkoleniowe składają się z wcześniejszych obserwacji. W większości przypadków obserwacje obejmują obserwowane atrybuty lub cechy obserwowanej rzeczy oraz znaną wartość rzeczy, którą chcesz wytrenować do przewidywania (znanej jako etykieta).
W kategoriach matematycznych często zobaczysz funkcje, o których mowa przy użyciu skróconej nazwy zmiennej x, a etykieta określana jako y. Zwykle obserwacja składa się z wielu wartości cech, więc x jest wektorem (tablica z wieloma wartościami), takim jak: [x1,x 2,x 3,...].
Aby to wyjaśnić, rozważmy przykłady opisane wcześniej:
- W scenariuszu sprzedaży lodów naszym celem jest wytrenować model, który może przewidzieć liczbę sprzedaży lodów na podstawie pogody. Pomiary pogody dla dnia (temperatura, opady deszczu, prędkość wiatru itd.) będą cechami (x), a liczba lodów sprzedawanych każdego dnia będzie etykietą (y).
- W scenariuszu medycznym celem jest przewidywanie, czy pacjent jest zagrożony cukrzycą na podstawie ich pomiarów klinicznych. Pomiary pacjenta (waga, poziom glukozy we krwi itd.) są cechami (x), a prawdopodobieństwo cukrzycy (na przykład 1 dla ryzyka, 0 dla ryzyka) jest etykietą (y).
- W scenariuszu badań antarktycznych chcemy przewidzieć gatunek pingwina na podstawie jego atrybutów fizycznych. Kluczowe pomiary pingwina (długość jego flipperów, szerokość rachunku itd.) to cechy (x) i gatunek (na przykład 0 dla Adelie, 1 dla Gentoo lub 2 dla Chinstrap) jest etykietą(y).
Algorytm jest stosowany do danych, aby spróbować określić relację między funkcjami i etykietą, a uogólnić tę relację jako obliczenie, które można wykonać na x w celu obliczenia y. Określony algorytm używany zależy od rodzaju problemu predykcyjnego, który próbujesz rozwiązać (więcej na ten temat później), ale podstawową zasadą jest próba dopasowania funkcji do danych, w których wartości funkcji można użyć do obliczenia etykiety.
Wynikiem algorytmu jest model, który hermetyzuje obliczenia uzyskane przez algorytm jako funkcję — nazwijmy to f. W notacji matematycznej:
y = f(x)
Po zakończeniu fazy trenowania do wnioskowania można użyć wytrenowanego modelu. Model jest zasadniczo programem programowym, który hermetyzuje funkcję utworzoną przez proces trenowania. Możesz wprowadzić zestaw wartości funkcji i otrzymać jako dane wyjściowe przewidywanie odpowiedniej etykiety. Ponieważ dane wyjściowe z modelu to przewidywanie, które zostało obliczone przez funkcję, a nie obserwowana wartość, często zobaczysz dane wyjściowe z funkcji wyświetlanej jako ŷ (co jest raczej uroczo ustalizowane jako "y-hat").