Typy uczenia maszynowego
Istnieje wiele typów uczenia maszynowego i musisz zastosować odpowiedni typ w zależności od tego, co próbujesz przewidzieć. Na poniższym diagramie przedstawiono podział typowych typów uczenia maszynowego.
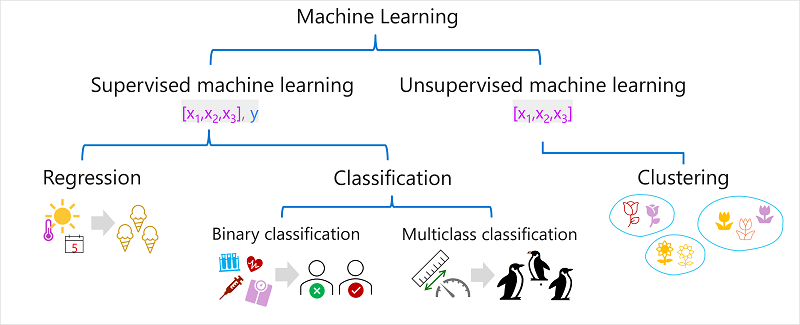
Nadzorowane uczenie maszynowe
Nadzorowane uczenie maszynowe to ogólny termin dla algorytmów uczenia maszynowego, w których dane szkoleniowe zawierają zarówno wartości funkcji, jak i znane wartości etykiet. Nadzorowane uczenie maszynowe służy do trenowania modeli przez określenie relacji między funkcjami i etykietami w poprzednich obserwacjach, dzięki czemu nieznane etykiety mogą być przewidywane dla funkcji w przyszłych przypadkach.
Regresja
Regresja to forma nadzorowanego uczenia maszynowego, w której etykieta przewidywana przez model jest wartością liczbową. Na przykład:
- Liczba lodów sprzedawanych w danym dniu w oparciu o temperaturę, opady deszczu i prędkość wiatru.
- Cena sprzedaży nieruchomości na podstawie jej rozmiaru w stopach kwadratowych, liczba zawartych w nim sypialni i metryki społeczno-ekonomiczne dla jego lokalizacji.
- Wydajność paliwa (w milach na galon) samochodu w oparciu o jego rozmiar silnika, wagę, szerokość, wysokość i długość.
Klasyfikacja
Klasyfikacja to forma nadzorowanego uczenia maszynowego, w której etykieta reprezentuje kategoryzacja lub klasę. Istnieją dwa typowe scenariusze klasyfikacji.
Klasyfikacja binarna
W klasyfikacji binarnej etykieta określa, czy obserwowany element jest (lub nie) wystąpieniem określonej klasy. Możesz też postawić inny sposób, modele klasyfikacji binarnej przewidują jeden z dwóch wzajemnie wykluczających się wyników. Na przykład:
- Czy pacjent jest zagrożony cukrzycą na podstawie metryk klinicznych, takich jak waga, wiek, poziom glukozy we krwi itd.
- To, czy klient bankowy nie zostanie domyślnie wypożyczony na podstawie dochodu, historii kredytowej, wieku i innych czynników.
- Czy klient listy wysyłkowej pozytywnie odpowie na ofertę marketingową na podstawie atrybutów demograficznych i wcześniejszych zakupów.
We wszystkich tych przykładach model przewiduje binarną wartość fałszywą/lubdodatnią/ujemną przewidywania dla pojedynczej możliwej klasy.
Klasyfikacja wieloklasowa
Klasyfikacja wieloklasowa rozszerza klasyfikację binarną, aby przewidzieć etykietę reprezentującą jedną z wielu możliwych klas. Przykład:
- Gatunek pingwina (Adelie, Gentoo lub Chinstrap) na podstawie jego pomiarów fizycznych.
- Gatunek filmu (komedia, horror, romans, przygoda lub science fiction) oparty na jego obsadzie, reżyserze i budżecie.
W większości scenariuszy obejmujących znany zestaw wielu klas klasyfikacja wieloklasowa służy do przewidywania wzajemnie wykluczających się etykiet. Na przykład pingwin nie może być zarówno Gentoo , jak i Adelie. Istnieją jednak również pewne algorytmy, których można użyć do trenowania modeli klasyfikacji wieloznacznego , w których może istnieć więcej niż jedna prawidłowa etykieta dla pojedynczej obserwacji. Na przykład film może być potencjalnie skategoryzowany zarówno jako science fiction , jak i komedia.
Nienadzorowane uczenie maszynowe
Nienadzorowane uczenie maszynowe obejmuje trenowanie modeli przy użyciu danych, które składają się tylko z wartości funkcji bez żadnych znanych etykiet. Algorytmy uczenia maszynowego bez nadzoru określają relacje między cechami obserwacji w danych treningowych.
Klastrowanie
Najczęstszą formą nienadzorowanego uczenia maszynowego jest klastrowanie. Algorytm klastrowania identyfikuje podobieństwa między obserwacjami na podstawie ich cech i grupuje je w odrębne klastry. Na przykład:
- Grupuj podobne kwiaty na podstawie ich wielkości, liczby liści i liczby płatków.
- Zidentyfikuj grupy podobnych klientów na podstawie atrybutów demograficznych i zachowania zakupów.
W pewnym sensie klastrowanie jest podobne do klasyfikacji wieloklasowej; w tym celu kategoryzuje obserwacje w grupach dyskretnych. Różnica polega na tym, że w przypadku korzystania z klasyfikacji znasz już klasy, do których należą obserwacje w danych treningowych; dlatego algorytm działa, określając relację między funkcjami a znaną etykietą klasyfikacji. W klastrowaniu nie ma wcześniej znanej etykiety klastra, a algorytm grupuje obserwacje danych na podstawie podobieństwa funkcji.
W niektórych przypadkach klastrowanie służy do określania zestawu klas, które istnieją przed trenowaniem modelu klasyfikacji. Można na przykład użyć klastrowania, aby podzielić klientów na grupy, a następnie przeanalizować te grupy w celu zidentyfikowania i kategoryzowania różnych klas klientów (wysoka wartość — mała ilość, częste małe nabywcy itd.). Następnie można użyć kategoryzacji, aby oznaczyć obserwacje w wynikach klastrowania i użyć danych oznaczonych etykietami do wytrenowania modelu klasyfikacji, który przewiduje, do której kategorii klienta może należeć nowy klient.