Uczenie głębokie
Uwaga / Notatka
Aby uzyskać więcej szczegółów, zobacz kartę Tekst i obrazy .
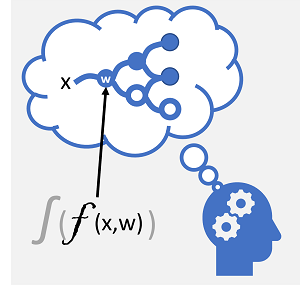
Uczenie głębokie to zaawansowana forma uczenia maszynowego, która próbuje naśladować sposób, w jaki ludzki mózg uczy się. Kluczem do uczenia głębokiego jest utworzenie sztucznej sieci neuronowej , która symuluje aktywność elektrochemiczną w neuronach biologicznych przy użyciu funkcji matematycznych, jak pokazano tutaj.
| Biologiczna sieć neuronowa | Sztuczna sieć neuronowa |
|---|---|

|
|
| Neurony są wyzwalane w odpowiedzi na bodźce elektrochemiczne. Po aktywacji sygnał jest przekazywany do połączonych neuronów. | Każdy neuron jest funkcją, która działa na wartości wejściowej (x) i wadze (w). Funkcja jest opakowana w funkcję aktywacji, która określa, czy przekazać dalej dane wyjściowe. |
Sztuczne sieci neuronowe składają się z wielu warstw neuronów, zasadniczo definiując głęboko zagnieżdżoną funkcję. Ta architektura jest powodem, dla którego technika jest nazywana uczeniem głębokim , a modele tworzone przez nią są często nazywane głębokimi sieciami neuronowymi (DNN). Możesz używać głębokich sieci neuronowych dla wielu rodzajów problemów z uczeniem maszynowym, w tym regresji i klasyfikacji, a także bardziej wyspecjalizowanych modeli przetwarzania języka naturalnego i przetwarzania obrazów.
Podobnie jak inne techniki uczenia maszynowego omówione w tym module, uczenie głębokie obejmuje dopasowywanie danych treningowych do funkcji, która może przewidywać etykietę (y) na podstawie wartości co najmniej jednej funkcji (x). Funkcja (f(x)) to zewnętrzna warstwa zagnieżdżonej funkcji, w której każda warstwa sieci neuronowej hermetyzuje funkcje, które działają na wartościach x i wagi (w) skojarzonych z nimi. Algorytm używany do trenowania modelu polega na iteracyjnym przekazywaniu wartości cech (x) w danych treningowych do przodu przez warstwy w celu obliczenia wartości wyjściowych dla ŷ. Następnie model jest weryfikowany w celu oceny, jak bardzo obliczone wartości ŷ odbiegają od znanych wartości y, co kwantyfikuje poziom błędu, czyli stratę (loss) modelu. Na końcu modyfikowane są wagi (w) w celu zmniejszenia straty. Wytrenowany model zawiera końcowe wartości wagi, które powodują najdokładniejsze przewidywania.
Przykład — używanie uczenia głębokiego do klasyfikacji
Aby lepiej zrozumieć, jak działa głęboki model sieci neuronowej, przyjrzyjmy się przykładowi, w którym sieć neuronowa jest używana do definiowania modelu klasyfikacji dla gatunków pingwinów.
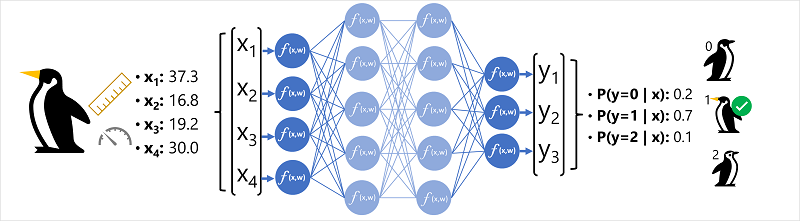
Dane funkcji (x) składają się z niektórych pomiarów pingwina. W szczególności pomiary to:
- Długość rachunku pingwina.
- Głębokość rachunku pingwina.
- Długość flipperów pingwina.
- Waga pingwina.
W tym przypadku x jest wektorem czterech wartości lub matematycznie x=[x1,x2,x3,x4].
Etykieta, którą mamy przewidzieć (y), dotyczy gatunku pingwina, mówiąc o trzech możliwych gatunkach, które mogą być:
- Adelie
- Gentoo
- Pasek pod brodą
Jest to przykład problemu klasyfikacji, w którym model uczenia maszynowego musi przewidzieć najbardziej prawdopodobną klasę, do której należy obserwacja. Model klasyfikacji pozwala przewidzieć etykietę składającą się z prawdopodobieństwa dla każdej klasy. Innymi słowy, y jest wektorem trzech wartości prawdopodobieństwa; jeden dla każdej z możliwych klas: [P(y=0|x), P(y=1|x), P(y=2|x)].
Proces wnioskowania przewidywanej klasy pingwinów przy użyciu tej sieci jest następujący:
- Wektor cech obserwacji pingwina jest wprowadzany do warstwy wejściowej sieci neuronowej, która składa się z neuronu dla każdej wartości x . W tym przykładzie następujący wektor x jest używany jako dane wejściowe: [37.3, 16.8, 19.2, 30.0]
- Funkcje dla pierwszej warstwy neuronów obliczają sumę ważoną przez połączenie wartości x i wagi w, i przekazuje ją do funkcji aktywacji, która określa, czy może zostać przekazana do następnej warstwy.
- Każdy neuron w warstwie jest połączony ze wszystkimi neuronami w następnej warstwie (architektura czasami nazywana w pełni połączoną siecią), więc wyniki każdej warstwy są przekazywane do przodu przez sieć, dopóki nie dotrą do warstwy wyjściowej.
- Warstwa wyjściowa tworzy wektor wartości; w tym przypadku użycie softmax lub podobnej funkcji w celu obliczenia rozkładu prawdopodobieństwa dla trzech możliwych klas pingwina. W tym przykładzie wektor wyjściowy to : [0.2, 0.7, 0.1]
- Elementy wektora reprezentują prawdopodobieństwa dla klas 0, 1 i 2. Druga wartość jest najwyższa, więc model przewiduje, że gatunek pingwina wynosi 1 (Gentoo).
Jak uczy się sieć neuronowa?
Wagi w sieci neuronowej mają kluczowe znaczenie dla sposobu obliczania przewidywanych wartości etykiet. Podczas procesu trenowania model uczy się wag, które pozwolą na najdokładniejsze przewidywania. Przyjrzyjmy się procesowi trenowania nieco bardziej szczegółowo, aby zrozumieć, jak odbywa się to uczenie.
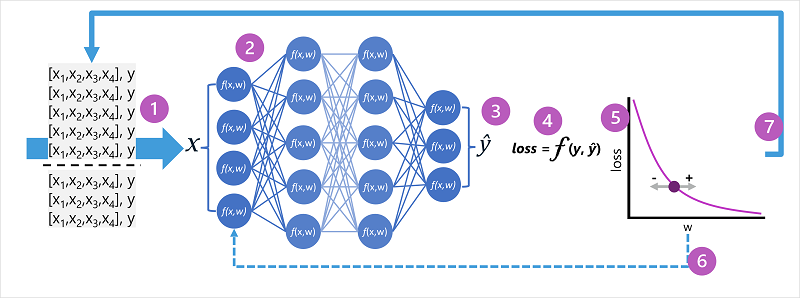
- Zestawy danych trenowania i walidacji są definiowane, a funkcje trenowania są przekazywane do warstwy wejściowej.
- Neurony w każdej warstwie sieci stosują swoje wagi (które są początkowo przypisywane losowo) i przekazują dane przez sieć.
- Warstwa wyjściowa tworzy wektor zawierający wartości obliczeniowe dla ŷ. Na przykład dane wyjściowe przewidywania klasy pingwinów mogą mieć wartość [0.3. 0.1. 0.6].
- Funkcja straty służy do porównywania przewidywanych wartości ŷ ze znanymi wartościami y i agregowania różnicy (czyli utraty). Jeśli na przykład znana klasa dla przypadku, która zwróciła dane wyjściowe w poprzednim kroku, to Chinstrap, wartość y powinna mieć wartość [0.0, 0.0, 1.0]. Bezwzględna różnica między tym a wektorem ŷ to [0.3, 0.1, 0.4]. W rzeczywistości funkcja straty oblicza zagregowaną wariancję dla wielu przypadków i podsumowuje ją jako pojedynczą wartość straty .
- Ponieważ cała sieć zasadniczo działa jak jedna duża funkcja zagnieżdżona, funkcja optymalizacji może użyć rachunku różniczkowego do oceny wpływu każdej wagi w sieci na wielkość straty i określić, jak można je zmienić (zwiększyć lub zmniejszyć), aby zmniejszyć wartość całkowitej straty. Konkretna technika optymalizacji może się różnić, ale zwykle polega na podejściu metody gradientowej, w którym każda waga jest zwiększana lub zmniejszana w celu zminimalizowania straty.
- Zmiany wag są przekazywane wstecz do warstw w sieci, zastępując wcześniej używane wartości.
- Proces jest powtarzany w przypadku wielu iteracji ( nazywanych epokami), dopóki strata nie zostanie zminimalizowana, a model przewiduje prawidłowo.
Uwaga / Notatka
Chociaż łatwiej jest myśleć o każdym przykładzie w danych treningowych jako przekazywanym przez sieć pojedynczo, w rzeczywistości dane są grupowane w macierze i przetwarzane metodami algebry liniowej. Z tego powodu trenowanie sieci neuronowej jest najlepiej wykonywane na komputerach z procesorami graficznymi (GPU), które są zoptymalizowane pod kątem manipulowania wektorami i macierzami.