Rozpoznawanie mowy
Uwaga / Notatka
Aby uzyskać więcej szczegółów, zobacz kartę Tekst i obrazy .
Rozpoznawanie mowy, często nazywane zamianą mowy na tekst (STT), to funkcja sztucznej inteligencji, która umożliwia aplikacjom i agentom reagowanie na wypowiedziane dane wejściowe. Rozpoznawanie mowy pobiera słowo mówione i konwertuje je na dane, zwykle tekst. Oprogramowanie zamiany mowy na tekst zwykle używa wielu modeli, w tym:
- Model akustyczny , który konwertuje dźwięk na fonemy (reprezentacje konkretnych dźwięków).
- Model językowy , który mapuje fonezy na słowa.
Słowa rozpoznawane przez AI są konwertowane na tekst. Tekst można używać do różnych celów, takich jak dostarczanie napisów zamkniętych, tworzenie transkrypcji połączeń telefonicznych, automatyzacja dyktowania notatek i wiele innych.
Azure Speech — zamiana mowy na tekst
Usługa Azure Speech zawiera interfejs API zamiany mowy na tekst , którego można użyć do przetwarzania danych głosowych z mikrofonu lub pliku audio.
Uwaga / Notatka
Interfejs API (interfejs programowania aplikacji) to zestaw reguł i punktów końcowych, który umożliwia jednej aplikacji programowej komunikowanie się z innymi aplikacjami i korzystanie z ich funkcji lub danych.
Microsoft Foundry to platforma firmy Microsoft, która ułatwia deweloperom tworzenie, testowanie i wdrażanie aplikacji i agentów sztucznej inteligencji dzięki połączeniu modeli, narzędzi, danych i usług w jednym miejscu.
W nowym portalu Microsoft Foundry możemy zapoznać się z możliwościami zamiany mowy na tekst w laboratorium Foundry usługi Azure Speech. Aby przejść na plac zabaw, przejdź do strony Kompilacja , a następnie przejdź do pozycji Modele, a następnie na karcie Usługi sztucznej inteligencji . Na karcie możesz znaleźć wybrane usługi sztucznej inteligencji dostępne do testowania, w tym Azure Speech — Speech to Text.
Na platformie możesz przesłać plik audio lub nagrać swoje wypowiedzi. Usługa Azure Speech transkrypuje to, co zostało powiedziane, dając ci poczucie, jak twoja własna aplikacja będzie reagować na dane wejściowe audio.

Plac zabaw w portalu Foundry to doskonałe miejsce do eksperymentowania z usługą Azure Speech, ale aby używać zamiany mowy na tekst w aplikacji, musimy napisać jakiś kod.
Korzystanie z usługi SDK do rozpoznawania mowy na tekst w systemie Azure
Zestaw SDK usługi Azure Speech — zamiana mowy na tekst to biblioteka kliencka, która umożliwia aplikacjom konwertowanie dźwięku mówionego na tekst pisany. Zestaw SDK zamiany mowy na tekst został zaprojektowany tak, aby rozpoznawanie mowy było łatwe do dodania do aplikacji.
Uwaga / Notatka
Biblioteka kliencka to zestaw gotowych kodu, którego deweloperzy mogą używać w swojej aplikacji, aby łatwo komunikować się z usługą lub interfejsem API.
SDK umożliwia Twojej aplikacji:
- Przechwytywanie lub wysyłanie dźwięku z mikrofonu, pliku audio lub strumienia audio
- Bezpieczne wysyłanie tego dźwięku do usługi Azure Speech
- Odbieranie transkrypcji tekstu niemal w czasie rzeczywistym lub po zakończeniu przetwarzania
Zestaw SDK obsługuje sieci, uwierzytelnianie, przesyłanie strumieniowe audio i analizowanie odpowiedzi, dzięki czemu deweloperzy mogą skupić się na logice aplikacji.
Tworzenie aplikacji
Zestaw SDK zamiany mowy na tekst jest zwykle używany w warstwie klienta lub usługi aplikacji. Zestaw SDK działa jako most między kodem aplikacji a usługą Azure Speech.
Aby korzystać z zestawu SDK języka Python usługi Azure Speech, musisz mieć zainstalowaną zgodną wersję języka Python i zestaw SDK języka Python usługi Azure Speech.
Zestaw SDK języka Python można zainstalować w terminalu programu Visual Studio Code przy użyciu następujących narzędzi:
pip install azure-cognitiveservices-speech
Uwaga / Notatka
Kod aplikacji jest napisany w edytorach kodu, takich jak Visual Studio Code. Terminal edytora kodu to wbudowane okno wiersza polecenia w edytorze, w którym można uruchamiać polecenia bez opuszczania środowiska projektowego.
Aby korzystać z usługi Azure Speech, należy również utworzyć zasób foundry. Punkt końcowy i klucz zasobu usługi Foundry są używane w kodzie do uwierzytelniania połączenia.
Po zainstalowaniu zestawu SDK języka Python i utworzeniu zasobu foundry możesz utworzyć i uruchomić program. Rozważmy następujący kod w języku Python. Po uruchomieniu:
- Aplikacja inicjuje zestaw SPEECH SDK: zapewnia punkt końcowy i uwierzytelnianie (klucz lub identyfikator Entra firmy Microsoft)
- Dźwięk jest przechwytywany lub ładowany: wejście mikrofonu lub plik audio/strumień
- Dźwięk jest wysyłany do usługi Azure Speech: zestaw SDK przesyła strumieniowo lub bezpiecznie przekazuje dźwięk
- Rozpoznawanie mowy działa w chmurze: modele mowy platformy Azure analizują dźwięk
- Zwracane są wyniki tekstowe: Aplikacja otrzymuje rozpoznany tekst i opcjonalne metadane
import azure.cognitiveservices.speech as speechsdk
# Set up the speech config using resource endpoint
endpoint_url = "ENDPOINT"
speech_key = "FOUNDRY_KEY"
speech_config = speechsdk.SpeechConfig(
subscription=speech_key,
endpoint=endpoint_url
)
# Create a recognizer with microphone input
audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True)
speech_recognizer = speechsdk.SpeechRecognizer(
speech_config=speech_config,
audio_config=audio_config
)
# Event handlers
def recognized_handler(evt):
print(f"Recognized: {evt.result.text}")
def recognizing_handler(evt):
print(f"Recognizing: {evt.result.text}")
# Connect event handlers
speech_recognizer.recognized.connect(recognized_handler)
speech_recognizer.recognizing.connect(recognizing_handler)
# Start continuous recognition
speech_recognizer.start_continuous_recognition()
print("Say something...")
# Keep the program running
input("Press Enter to stop...")
speech_recognizer.stop_continuous_recognition()
Przykład aplikacji klienckiej
Załóżmy na przykład, że chcesz opracować lekką aplikację, która automatycznie transkrybuje wiadomości poczty głosowej. W edytorze kodu mamy jeden plik audio i jeden plik w języku Python, który zawiera kod aplikacji.
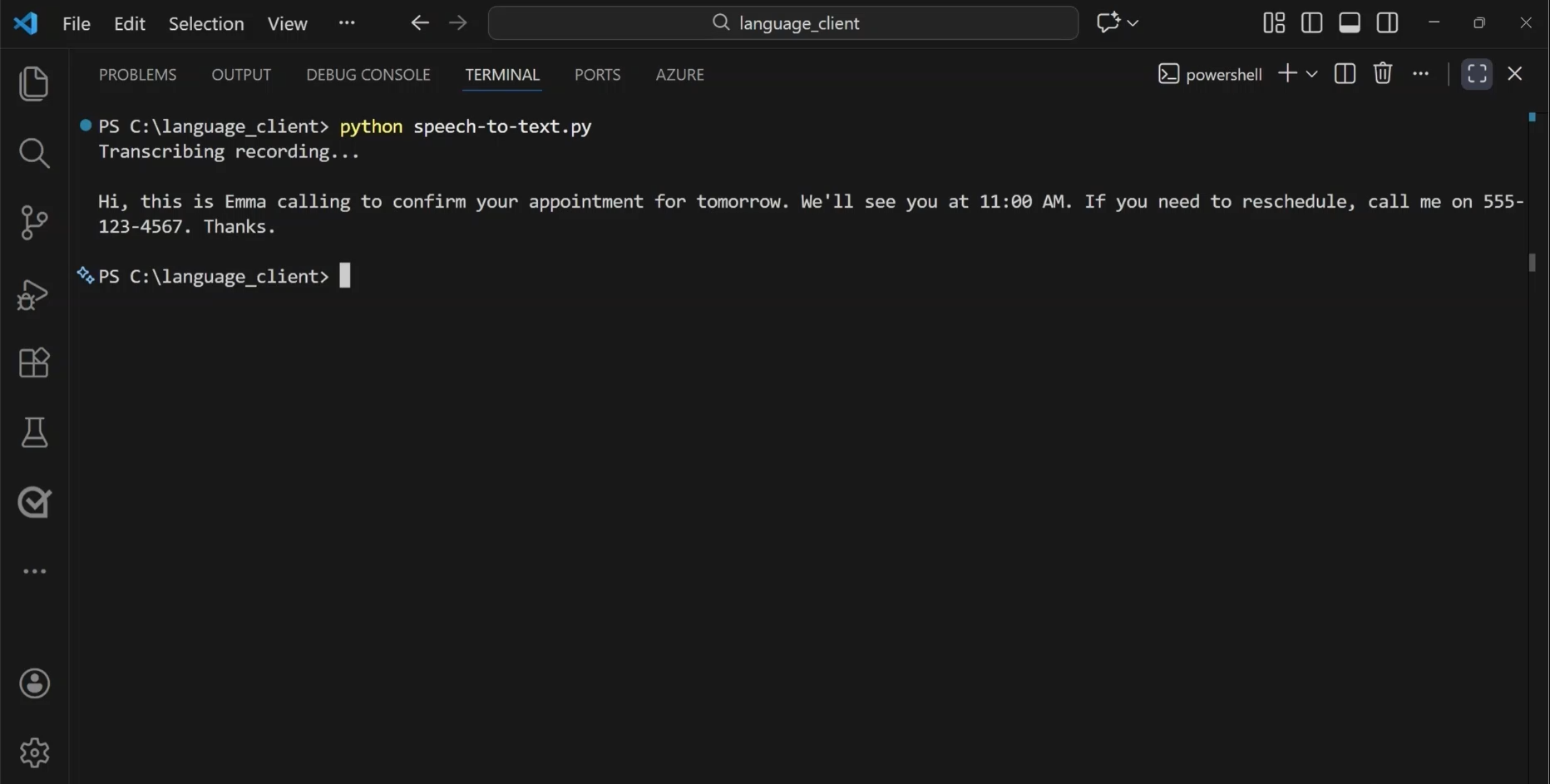
Załóżmy, że masz plik audio zawierający nagranie poczty głosowej. Aby transkrypować komunikat, zacznij od określenia punktu końcowego i klucza oraz źródła dźwięku, które chcesz transkrybować. Następnie użyj SpeechRecognizer obiektu do wykonania transkrypcji przed wyświetleniem wyników.

Po uruchomieniu kodu zobaczysz tekst transkrypcji.
Opcje przetwarzania dźwięku
Interfejs API zamiany mowy na tekst usługi Azure Speech umożliwia wykonywanie transkrypcji audio w czasie rzeczywistym lub wsadowym w formacie tekstowym. Źródłem audio transkrypcji może być strumień audio w czasie rzeczywistym z mikrofonu lub pliku audio.
Transkrypcja w czasie rzeczywistym: zamiana mowy w czasie rzeczywistym na tekst umożliwia transkrypcję strumieni audio do tekstu. Transkrypcję w czasie rzeczywistym można wykorzystać do prezentacji, pokazów lub innych sytuacji, w których ktoś mówi.
Aby transkrypcja w czasie rzeczywistym działała, aplikacja musi nasłuchiwać przychodzącego dźwięku z mikrofonu lub innego źródła danych wejściowych audio, takich jak plik audio. Kod aplikacji przesyła strumieniowo dźwięk do usługi, co zwraca transkrypowany tekst.
Transkrypcja wsadowa: nie wszystkie scenariusze zamiany mowy na tekst są w czasie rzeczywistym. Nagrania audio mogą być przechowywane w udziale plików, serwerze zdalnym, a nawet w usłudze Azure Storage. Możesz wskazać pliki audio z identyfikatorem URI sygnatury dostępu współdzielonego (SAS) i asynchronicznie odbierać wyniki transkrypcji.
Transkrypcja wsadowa powinna być uruchamiana w sposób asynchroniczny, ponieważ zadania wsadowe są zaplanowane na podstawie najlepszego nakładu pracy. Zwykle zadanie rozpoczyna wykonywanie w ciągu kilku minut od żądania, ale nie ma oszacowania, kiedy zadanie zmienia się w stan uruchomienia.
Rozpoznawanie mowy w usłudze Azure Speech to doskonały sposób tworzenia rozwiązań, które transkrybują nagrany dźwięk lub automatyzują transkrypcję mowy. Następnie dowiedz się, jak włączyć syntezę mowy do aplikacji.