Eksplorowanie możliwości hiperskala
Warstwa usługi Hiperskala w Azure SQL Database to warstwa usługi w modelu zakupu opartym na rdzeniach wirtualnych, idealna dla obciążeń biznesowych. Jest to wysoce skalowalna warstwa wydajności magazynu i obliczeń w usłudze Azure SQL Database, która używa platformy Azure do znaczącego zwiększania zasobów magazynowych i obliczeniowych, znacznie przekraczając limity dostępne dla warstw Ogólnego przeznaczenia i Krytyczne dla Biznesu. Umożliwia oddzielenie aparatu przetwarzania zapytań od długoterminowych składników magazynu, co umożliwia bezproblemowe skalowanie zasobów obliczeniowych i magazynowych.
Hiperskala upraszcza projektowanie infrastruktury i aplikacji, umożliwiając deweloperom skupienie się na potrzebach biznesowych, a nie zarządzaniu zasobami bazy danych.
Usługa Azure SQL Database była ograniczona do 4 TB magazynu na bazę danych. Jednak warstwa usługi Hiperskala umożliwia teraz bazom danych przekroczenie 100 TB. Warstwa Hiperskala używa skalowania w poziomie w celu dodawania węzłów obliczeniowych w miarę zwiększania się danych. Chociaż koszt jest podobny do zwykłego usługi Azure SQL Database, istnieje dodatkowy koszt magazynu terabajtów.
Omówienie korzyści
Warstwa usługi Hiperskala eliminuje wiele praktycznych ograniczeń zwykle występujących w bazach danych w chmurze. W przeciwieństwie do większości innych baz danych, które są ograniczone przez zasoby jednego węzła, bazy danych w warstwie Hiperskala nie mają takich ograniczeń. Dzięki elastycznej architekturze magazynu magazyn rozszerza się w razie potrzeby i nie ma wstępnie zdefiniowanego maksymalnego rozmiaru. Płacisz tylko za używaną pojemność. W przypadku obciążeń intensywnie korzystających z odczytu hiperskala oferuje szybkie skalowanie w poziomie, aprowizując dodatkowe repliki w celu odciążania operacji odczytu.
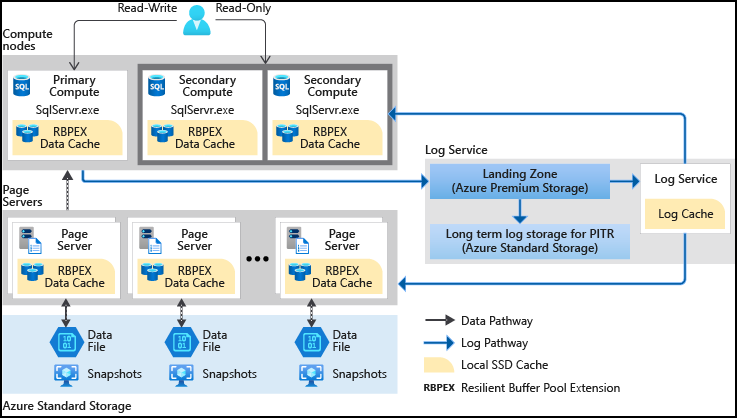
Ponadto czas potrzebny do utworzenia kopii zapasowych bazy danych lub skalowania w górę lub w dół nie zależy już od ilości danych w bazie danych. Bazy danych w warstwie Hiperskala można wykonywać natychmiast. Możesz również skalować bazę danych z dziesiątkami terabajtów w górę lub w dół w ciągu kilku minut. Ta funkcja pozwala uwolnić Cię od obaw związanych z ograniczaniem przez początkowe opcje konfiguracji. Hiperskala zapewnia również szybkie przywracanie bazy danych, co trwa w minutach, a nie w godzinach lub dniach.
Hiperskala zapewnia szybką skalowalność na podstawie zapotrzebowania na obciążenie.
| Funkcja | opis | Korzyści | Przypadek użycia |
|---|---|---|---|
| Skalowanie w górę/w dół | Możesz skalować w górę podstawowy rozmiar obliczeniowy pod względem zasobów, takich jak procesor CPU i pamięć, a następnie skalować w dół w stałym czasie. Ponieważ magazyn jest współużytkowany, skalowanie w górę i skalowanie w dół nie jest połączone z ilością danych w bazie danych. | Zapewnia elastyczność i wydajność zarządzania zasobami. | Idealne rozwiązanie dla aplikacji o różnych obciążeniach wymagających różnych poziomów mocy obliczeniowej. |
| Skalowanie w górę/w dół | Możesz również aprowizować co najmniej jedną replikę obliczeniową do obsługi żądań odczytu. Te dodatkowe repliki obliczeniowe działają jako repliki tylko do odczytu, odciążając obciążenie odczytu z podstawowych obliczeń. Ponadto te repliki służą jako rezerwy na gorąco, które są gotowe do przejęcia, jeśli wystąpi awaria obliczeniowa podstawowa. | Zwiększa wydajność i niezawodność, odciążając obciążenia odczytu i zapewniając możliwości trybu failover. | Odpowiednie dla aplikacji intensywnie korzystających z odczytu, które wymagają wysokiej dostępności i szybkiego przejścia w tryb failover. |
Maksymalizowanie wydajności
Warstwa usługi Hiperskala została zaprojektowana dla klientów z dużymi lokalnymi bazami danych programu SQL Server, którzy chcą zmodernizować swoje aplikacje, przechodząc do chmury. Jest to również idealne rozwiązanie dla klientów korzystających już z usługi Azure SQL Database, którzy chcą znacznie zwiększyć potencjał wzrostu bazy danych. Ponadto hiperskala jest idealna dla osób poszukujących wysokiej wydajności i wysokiej skalowalności
Oprócz funkcji szybkiego skalowania hiperskala zapewnia następujące możliwości wydajności.
- Kopie zapasowe bazy danych są niemal natychmiastowe, niezależnie od rozmiaru, bez wpływu na zasoby obliczeniowe.
- Przywracanie bazy danych jest wykonywane w minutach, a nie w godzinach lub dniach.
- Ogólna wydajność jest zwiększona z powodu wyższej przepływności dziennika transakcji i krótszych czasów zatwierdzania transakcji, niezależnie od woluminów danych.
Uwaga
Aby wdrożyć bazę danych w warstwie Hiperskala w usłudze Azure SQL Database, zobacz
Wdrażanie hiperskala usługi Azure SQL Database
Aby wdrożyć usługę Azure SQL Database z warstwą Hiperskala:
Zaloguj się do witryny Azure Portal.
Przejdź do strony Azure SQL , a następnie wybierz pozycję + Utwórz.
Wybierz pozycję SQL Database, Pojedyncza baza danych i przycisk Utwórz .
Na karcie Podstawowe na stronie Tworzenie bazy danych SQL Wybierz odpowiednią subskrypcję, grupę zasobów i nazwę bazy danych.
Wybierz link Utwórz nowy dla serwera i wypełnij nowe informacje o serwerze, takie jak nazwa serwera, identyfikator logowania administratora serwera i hasło oraz lokalizacja.
W obszarze Obliczenia i magazyn wybierz link Konfiguruj bazę danych .
Wybierz Hiperskala dla warstwy usługi i przydzieloną dla warstwy obliczeniowej.
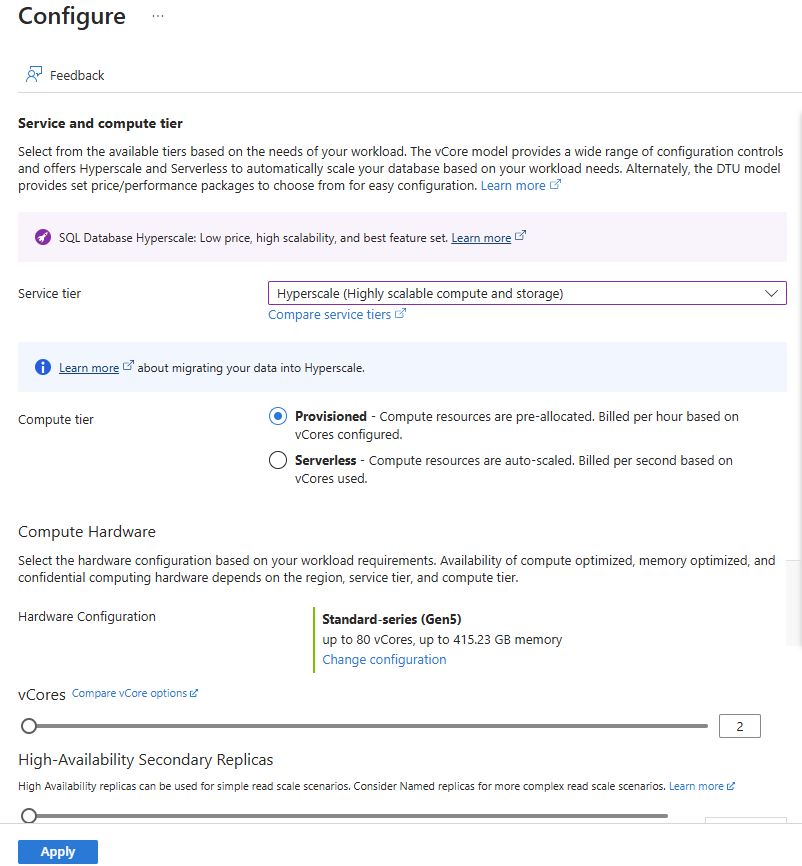
W obszarze Konfiguracja sprzętu wybierz link Zmień konfigurację . Przejrzyj dostępne konfiguracje sprzętu i wybierz najbardziej odpowiednią konfigurację bazy danych. W tym przykładzie pozostawiamy domyślną opcję serii Standardowej (Gen5).
Opcjonalnie dostosuj suwak vCores, jeśli chcesz zwiększyć liczbę rdzeni wirtualnych dla bazy danych.
Dostosuj suwak High-Availability Repliki pomocnicze , aby utworzyć jedną replikę. Wybierz Zastosuj.
Wybierz pozycję Dalej: Sieć w dolnej części strony.
Na karcie Sieć ustaw pozycję Dodaj bieżący adres IP klienta na wartość Tak.
Wybierz przycisk Przejrzyj i utwórz , a następnie wybierz pozycję Utwórz.

Uwaga
Po przekonwertowaniu bazy danych na hiperskala nie można przywrócić jej z powrotem do zwykłej bazy danych Azure SQL Database. Aby dowiedzieć się więcej na temat ograniczeń hiperskala, zobacz Znane ograniczenia dotyczące warstwy usługi Hiperskala.
Nawiązywanie połączenia z repliką tylko do odczytu
Możesz nawiązać połączenie z repliką tylko do odczytu, ustawiając argument ApplicationIntent w łańcuchu połączenia na ReadOnly. Wszystkie połączenia z intencją aplikacji ReadOnly są automatycznie kierowane do jednej z replik obliczeniowych tylko do odczytu.
Server=tcp:<your_server_name>.database.windows.net,1433;Database=<your_database_name>;User ID=<your_username>@<your_server_name>;Password=<your_password>;Encrypt=true;Connection Timeout=30;ApplicationIntent=ReadOnly;