Implementowanie klastrów rozproszynych
Tradycyjnie klastry trybu failover zapewniły ochronę wysokiej dostępności przed zlokalizowanymi awariami do co najmniej jednego węzła klastra znajdującego się w tej samej lokalizacji fizycznej. Klastry rozproszone można używać, gdy konieczne jest zapewnienie równoważnej funkcjonalności w różnych lokalizacjach fizycznych.
Co to są klastry rozciągnięte?
Klaster stretch implementuje wysoką dostępność i odzyskiwanie po awarii w dwóch oddzielnych lokalizacjach fizycznych. Obie lokalizacje hostuje oddzielny system magazynowania z replikacją synchroniczną jednokierunkową z lokacji głównej do lokacji dodatkowej. Jeśli awaria wpłynie na dostępność lokacji głównej, aby zminimalizować przestój, klaster automatycznie przenosi obciążenia do węzłów w lokacji dodatkowej. W przypadku planowanej konserwacji w lokalizacji głównej można użyć Hyper-V Live Migration, aby przenieść obciążenia do innej lokalizacji bez przestojów, całkowicie unikając przestojów.
Korzystanie z klastrów rozproszynych zapewnia kilka zalet w porównaniu z ręczną obsługą lokacji odzyskiwania po awarii:
- Automatyczna replikacja i automatyczne przełączanie awaryjne obciążeń klastrowych.
- Zmniejszenie obciążeń administracyjnych.
- Zminimalizuj możliwość wystąpienia błędu ludzkiego, który jest nieodłączny dla procesów ręcznych.
Z drugiej strony klastry rozproszone są bardziej złożone do projektowania i implementowania. Zwykle wymagają one również dodatkowej inwestycji w infrastrukturę magazynu i sieci.
Omówienie Storage Replication
Klastry rozproszone korzystają z repliki magazynu — funkcji systemu Windows Server, która zapewnia replikację woluminów między serwerami lub klastrami na potrzeby odzyskiwania po awarii. Używając Storage Replica, klastry międzylokacyjne mogą synchronizować woluminy pamięci masowej przyłączone do węzłów klastra w dwóch oddzielnych lokalizacjach.
Storage Replica obsługuje replikację synchroniczną i asynchroniczną.
- Replikacja synchroniczna replikuje dane w sieci o małych opóźnieniach w ciągu milisekund czasu podróży w obie strony, zapewniając brak utraty danych na poziomie systemu plików podczas przełączenia awaryjnego.
- Replikacja asynchroniczna replikuje dane na dłuższych dystansach, które podlegają wyższym opóźnieniom, ale bez gwarancji, że obie lokacje mają identyczne kopie danych w momencie przejścia w tryb failover.
Ważne
Klastry rozproszone wymagają replikacji synchronicznej. To wymaganie nakłada limit opóźnienia sieci 5 ms w obie strony między dwiema grupami węzłów klastra w replikowanych lokacjach. W zależności od cech łączności sieciowej fizycznej ograniczenie to zwykle przekłada się na odległość około 20-30 mil.
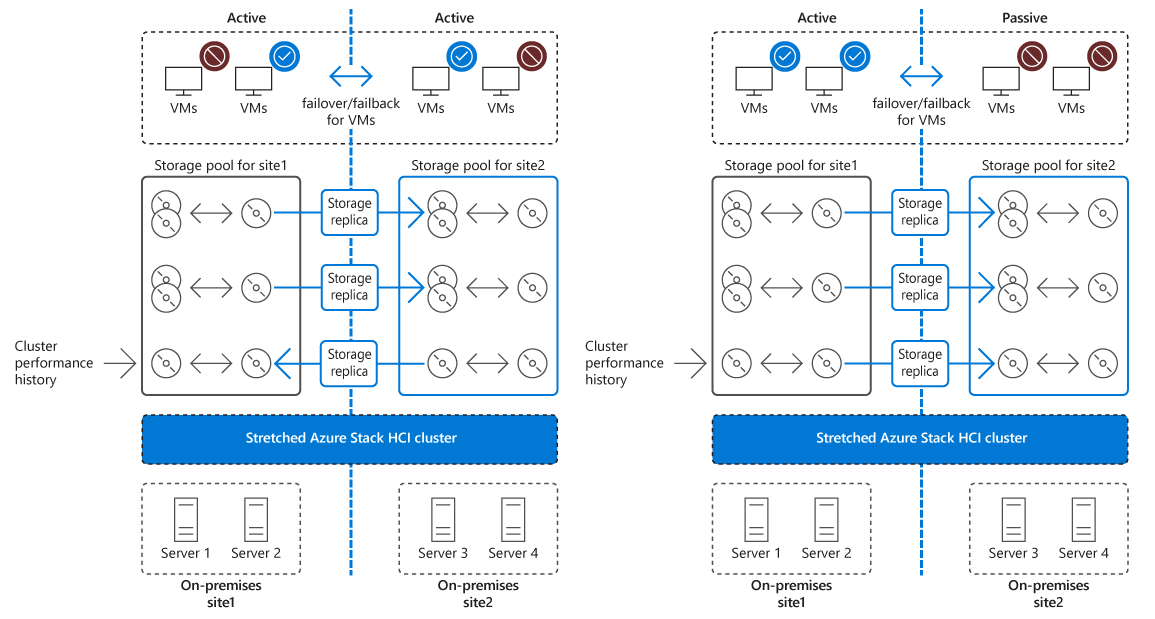
Funkcje repliki magazynu
Główne funkcje Storage Replica są wymienione w poniższej tabeli.
| Funkcja | Opis |
|---|---|
| Replikacja na poziomie bloku | W przypadku replikacji na poziomie bloku nie ma możliwości blokowania plików. |
| Prostota | Możesz polegać na Centrum administracyjnym systemu Windows, aby przeprowadzić cię przez proces tworzenia partnerstwa replikacji między dwoma serwerami. Aby wdrożyć klaster rozproszyny, można użyć kreatora opartego na Menedżerze klastra trybu failover. |
| Korzystanie z bloku komunikatów serwera (SMB) 3.0 | Replika pamięci masowej korzysta z protokołu SMB 3.x wprowadzonego w systemie Windows Server 2012 i znacznie ulepszonego w kolejnych wersjach systemu Windows Server. Wszystkie zaawansowane cechy protokołu SMB, takie jak SMB Multichannel i SMB Direct, są dostępne dla repliki magazynu. |
| Zabezpieczenia | Replika magazynu oferuje szeroką gamę mechanizmów zabezpieczeń, w tym podpisywanie pakietów, pełne szyfrowanie danych AES-128-GCM, obsługę przyspieszania szyfrowania przez zewnętrzne firmy, preautoryzacyjną integralność, oraz zapobieganie atakom typu man-in-the-middle. Replika magazynu korzysta również z protokołu Kerberos AES256 na potrzeby całego uwierzytelniania między węzłami. |
| Ograniczenia sieci | W przypadkach, gdy istnieje wiele ścieżek sieciowych między replikowanymi woluminami, można skonfigurować ruch repliki magazynu do używania wyznaczonych kart sieciowych. Pozwala to zminimalizować potencjalny wpływ ruchu replikacji na obciążenia produkcyjne. |
| Cienkie przydzielanie | Istnieje możliwość zaimplementowania alokowania elastycznego w Miejsca do magazynowania Direct, minimalizując czasy replikacji początkowej. |
Wymagania wstępne dotyczące wdrażania klastrów rozproszynych
Wymagania wstępne dotyczące wdrażania klastrów rozciągniętych obejmują:
Węzły klastra muszą być członkami tej samej domeny lub zaufanego lasu AD DS.
Każdy węzeł klastra powinien mieć co najmniej 2 GB pamięci RAM i dwa rdzenie procesora CPU na serwer.
Każdy węzeł klastra powinien mieć system Windows Server 2025 Datacenter lub Windows Server 2016 Datacenter edition. Można użyć systemu Windows Server 2025 Standard Edition, ale taka konfiguracja obsługuje replikację pojedynczego woluminu o rozmiarze do 2 terabajtów (TB).
Każdy węzeł klastra powinien mieć co najmniej 1 adapter Ethernetowy Gigabitowy na potrzeby replikacji synchronicznej, chociaż bardziej zaleca się użycie technologii Zdalnego Bezpośredniego Dostępu do Pamięci (RDMA).
Dwa zestawy woluminów (jeden dla danych i drugi dla dzienników) w lokacji głównej i dodatkowej z następującymi ustawieniami:
Dyski muszą być inicjowane jako tabela partycji GUID (GPT), a nie główny rekord rozruchowy (MBR).
- Woluminy powinny być sformatowane za pomocą systemu plików ReFS lub NTFS.
- Rozmiary woluminów danych i rozmiary sektorów muszą być zgodne.
- Rozmiary woluminów dziennika i rozmiary sektorów muszą być zgodne.
- Woluminy dziennika powinny używać szybszego magazynu niż woluminy danych.
- Woluminy dziennika nie powinny być używane w przypadku innych obciążeń.
Dwukierunkowa łączność za pośrednictwem protokołu ICMP (Internet Control Message Protocol), SMB (port 445 oraz port 5445 dla protokołu SMB Direct) i sieci Web Services-Management (WS-MAN) (port 5985) między dwiema lokacjami.
Sieć między serwerami z wystarczającą przepustowością dla operacji we/wy obciążeń klastrowanych oraz opóźnieniem dwukierunkowym mniejszym niż 5 ms.
Zagadnienia dotyczące wdrażania klastra rozproszonego
Klastry rozproszone nie są odpowiednie dla każdego obciążenia i każdego scenariusza. Podczas projektowania rozwiązania klastra rozproszonego jasno określ wymagania i oczekiwania organizacji. Ponadto należy pamiętać, że klastry rozproszone nakładają większe obciążenie związane z zarządzaniem niż tradycyjne klastry, w których wszystkie węzły znajdują się w tej samej lokalizacji fizycznej. Należy również uważnie rozważyć optymalny wybór świadka kworum, aby zmaksymalizować jego dostępność w przypadku awarii wpływającej na całe miejsce fizyczne.
Ważne
Aplikacje stanowe i usługi, takie jak Microsoft SQL Server, Hyper-V, Microsoft Exchange Server i AD DS, powinny używać własnych, natywnych mechanizmów odporności, a nie polegać na klastrach rozproszonych w celu zapewnienia wysokiej dostępności.
Zagadnienia dotyczące trybu failover i powrotu po awarii w klastrze rozproszeniowym
W ramach planowania wdrożenia klastra rozproszonego należy zdefiniować jego konfigurację trybu failover i powrotu po awarii, biorąc pod uwagę następujące kwestie:
- Zależności infrastruktury. Należy jasno zdefiniować usługi krytyczne, takie jak AD DS, DNS i DHCP, które powinny pozostać dostępne po przejściu w tryb failover do lokacji zapasowej.
- Model kworumowy Ważne jest, aby wybrać model kworum, który zachowuje funkcjonalność klastra po przejściu w tryb failover.
- Publikowanie usług i rozwiązywanie nazw. Jeśli masz usługi publikowane dla użytkowników wewnętrznych lub zewnętrznych, takich jak poczta e-mail i strony internetowe, należy pamiętać, że w niektórych przypadkach przejście w tryb failover do innej witryny wymaga zmiany nazwy lub adresu IP. Jeśli tak jest, należy mieć procedurę zmiany rekordów DNS w wewnętrznym lub publicznym systemie DNS. Aby zmniejszyć czas przestoju, zalecamy skrócenie wartości czasu wygaśnięcia (TTL) krytycznych rekordów DNS.
- Łączność z klientem. W przypadku awarii plan awaryjny musi umożliwiać łączność aplikacji klienckich z obciążeniami klastrowanymi. Obejmuje to zarówno klientów wewnętrznych, jak i zewnętrznych.
- Procedura powrotu po awarii. Należy zaplanować i wdrożyć proces przywracania po awarii po powrocie głównej lokalizacji do trybu online. Powrót po awarii jest równie ważny jak przejście w tryb failover, ponieważ jeśli wykonasz go nieprawidłowo, możesz spowodować utratę danych i przestój usługi.
Utwórz klaster typu stretch
Klaster rozproszyny można utworzyć przy użyciu centrum administracyjnego systemu Windows, Menedżera klastra trybu failover lub programu Windows PowerShell. Usługa Windows Admin Center upraszcza implementację klastrów rozproszanych, prowadząc cię przez proces aprowizacji i automatyzując większość zadań konfiguracyjnych. Obejmuje to obsługę:
- Klastry hiperkonwergentne (klastrowanie awaryjne, Hyper-V i Bezpośrednie Przestrzenie Dyskowe).
- Klastry pamięci masowane (klastrowanie awaryjne i bezpośrednie miejsca przechowywania).
Uwaga / Notatka
Tworzenie klastra rozciągniętego przy użyciu Menedżera klastra awaryjnego lub Windows PowerShell jest bardziej złożone. Obie metody wymagają wykonania każdego z pośrednich kroków implementacji. Mówiąc najprościej, zaczyna się to od utworzenia tradycyjnego klastra awaryjnego, który składa się ze wszystkich węzłów w głównej i pomocniczej lokalizacji. Po utworzeniu klastra i zakończeniu jego walidacji w każdej lokacji należy utworzyć oddzielny zestaw woluminów magazynu. Na koniec skonfigurujesz replikę magazynu tak, aby replikować woluminy magazynu między dwiema lokacjami.