Definiowanie udostępnionych woluminów klastra
Aby obsłużyć szeroką gamę scenariuszy wysokiej dostępności, technologie klastrowania powinny obejmować obsługę rozproszonego systemu plików. Umożliwia to wydajny, skoordynowany dostęp do magazynu udostępnionego w wielu węzłach klastra, który nie prowadzi do uszkodzenia danych. System Windows Server implementuje taką obsługę przy użyciu woluminów CSV.
Co to są udostępnione woluminy klastra?
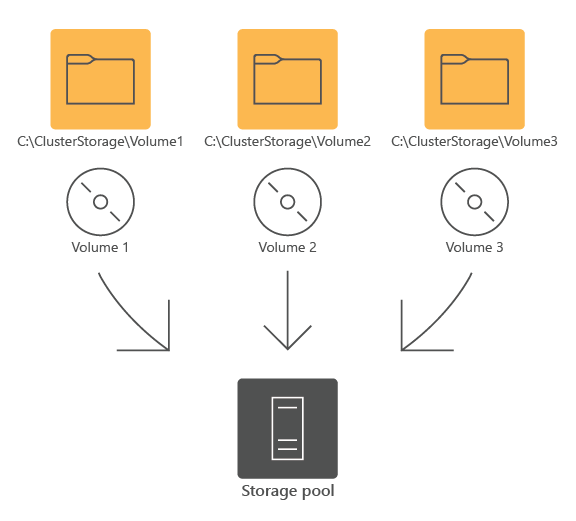
CSV to system plików klastrowanych ogólnego przeznaczenia (określany jako CSVFS), który umożliwia węzłom klastra jednoczesne odczytywanie i zapisywanie w tym samym zestawie woluminów systemu plików NT (NTFS) lub reFS. Wolumin CSV mapuje woluminy hostowane na dyskach połączonych z węzłami klastra do katalogu C:\ClusterStorage\ w każdym węźle klastra. Takie podejście zapewnia jedną przestrzeń nazw z całą zawartością CSV dostępną za pośrednictwem tej samej nazwy i ścieżki w dowolnym węźle w klastrze.
Możliwości woluminów CSV
Zezwalanie na współbieżny dostęp do woluminu zapewnia bardziej zrównoważoną dystrybucję obciążenia i zwiększa szybkość pracy w trybie failover, eliminując konieczność zmiany własności dysku lub odinstalowywanie i ponowne instalowanie woluminów. Ponadto plik CSV oferuje następujące możliwości:
- Obsługa online chkdsk. Operacja chkdsk jest uruchamiana w trybie online bez wpływu na obciążenia z otwartymi uchwytami w systemie plików.
- Obsługa szyfrowania dysków funkcją BitLocker. Funkcja BitLocker umożliwia szyfrowanie woluminów zarówno dla tradycyjnych dysków klastrowanych, jak i woluminów opartych na woluminach CSV.
- Integracja z funkcją SMB Multichannel i SMB Direct. Umożliwia to przesyłanie strumieniowe ruchu CSV między wieloma sieciami w klastrze i korzystanie z kart sieciowych obsługujących zdalny bezpośredni dostęp do pamięci (RDMA).
- Integracja z Miejsca do magazynowania. Umożliwia to zwirtualizowanych magazynów w klastrach ze sprzętem towarów.
- Możliwość skanowania i naprawiania woluminów w trybie online. Plik CSV umożliwia skanowanie i naprawianie woluminów bez przestojów podczas korzystania z narzędzi takich jak chkdsk, fsutil i
Repair-Volumepolecenie cmdlet programu Windows PowerShell. - Ulepszona odporność woluminów CSV. System Windows Server implementuje wiele wystąpień usługi Server, co zwiększa odporność i skalowalność ruchu SMB między węzłami. Domyślne wystąpienie usługi Serwera akceptuje żądania, które uzyskują dostęp do zwykłych udziałów plików, podczas gdy dodatkowe wystąpienia zarządzają ruchem csv między węzłami.
Plik CSV obsługuje dwa główne typy obciążeń:
- Klastrowane maszyny wirtualne funkcji Hyper-V firmy Microsoft (w tym pliki wirtualnego dysku twardego).
- Udziały plików skalowane w poziomie hostowania danych aplikacji dla roli klastrowanej serwera SOFS.
Wolumin CSV umożliwia przechowywanie plików dysków wielu maszyn wirtualnych na jednym woluminie i uruchamianie maszyn wirtualnych w dowolnym miejscu w dowolnym węźle klastra. Ponadto wolumin CSV przyspiesza funkcję migracji na żywo, eliminując konieczność zmiany własności dysku po przejściu maszyny wirtualnej do innego węzła, co zwiększa wydajność i stabilność procesu migracji.
Mimo że każdy węzeł może niezależnie odczytywać i zapisywać poszczególne pliki na woluminie, jeden węzeł działa jako właściciel woluminu CSV (lub koordynator) woluminu. Ten węzeł hostuje instalację woluminu. Istnieje możliwość przypisania pojedynczego woluminu do określonego właściciela, jednak klaster trybu failover automatycznie rozdziela własność woluminów CSV między węzłami klastra. Mechanizm dystrybucji uwzględnia liczbę woluminów CSV, które każdy węzeł jest właścicielem. Usługa klastrowania ponownie równoważy własność po takich zmianach, jak dodawanie, usuwanie lub ponowne uruchamianie węzła.
Gdy zmiany w metadanych systemu plików mają miejsce na woluminie CSV, właściciel jest odpowiedzialny za ich implementację i zarządzanie ich aranżacją, synchronizowanie ich we wszystkich węzłach klastra z dostępem do tego woluminu. Takie zmiany obejmują na przykład uruchamianie, tworzenie, migrowanie lub usuwanie plików dysków maszyny wirtualnej znajdujących się na woluminie. Aktualizacje metadanych nie obejmują bezpośredniej komunikacji z węzłów klastra niebędących właścicielami do udostępnionego magazynu hostowanego woluminu.
Z kolei standardowe operacje zapisu i odczytu do otwierania plików na woluminie CSV nie mają wpływu na metadane. W efekcie tego każdy węzeł klastra z bezpośrednim połączeniem z magazynem bazowym może wykonywać je niezależnie, bez polegania na właścicielu udostępnionego woluminu klastra. Takie operacje, w przeciwieństwie do aktualizacji metadanych, stanowią większość działań magazynu.
Węzeł właściciela minimalizuje również negatywny wpływ awarii łączności magazynu i operacji magazynu, które uniemożliwiają bezpośrednie komunikowanie się danego węzła z magazynem. W przypadku takich zdarzeń węzeł, który musi komunikować się z bazowym magazynem przekierowuje operacje we/wy dysku za pośrednictwem sieci klastra do węzła właściciela odpowiedniego woluminu. Jeśli bieżący węzeł koordynacji wystąpi awaria łączności magazynu, wszystkie operacje we/wy dysku są tymczasowo kolejkowane, podczas gdy klaster automatycznie przypisuje rolę koordynatora do nowego węzła.
Planowanie dla woluminu CSV
Aby można było używać woluminów CSV, magazyn i dyski muszą spełniać następujące wymagania:
- Format systemu plików i konfiguracja dysku. Dysk lub miejsce do magazynowania woluminu CSV musi używać dysku podstawowego w systemie plików NTFS w formacie ReFS. W przypadku korzystania z miejsc do magazynowania można skonfigurować prostą przestrzeń, przestrzeń dublowania lub przestrzeń parzystości.
- Zasoby klastra dysków fizycznych. Wolumin CSV opiera się na typie zasobu Dysk fizyczny. Aby utworzyć typ zasobu Dysk fizyczny, należy dodać dysk lub miejsce do magazynowania klastra.
Dodatkowe zagadnienia dotyczące planowania obejmują:
- Liczba i rozmiar liczb jednostek logicznych (LUN) i woluminów. Aby uzyskać wskazówki, należy skonsultować się z dostawcą magazynu.
- Liczba i rozmiar maszyn wirtualnych (w przypadku wdrożeń maszyn wirtualnych). Chociaż nie ma żadnych ograniczeń dotyczących liczby maszyn wirtualnych na wolumin, należy wziąć pod uwagę zagregowane wymagania we/wy podczas podejmowania decyzji o optymalnej liczbie.
- Sieci klastrów. Sieci klastrów powinny umożliwić potencjalny wzrost ruchu sieciowego do węzła koordynacji podczas przekierowywania we/wy.
Implementowanie pliku CSV
Funkcja woluminów CSV jest domyślnie włączona w klastrze trybu failover. Aby dodać dysk do woluminu CSV, należy najpierw dołączyć go do grupy Dostępne magazyny klastra. Aby można było dodać magazyn do woluminu CSV, odpowiedni dysk musi być dostępny jako magazyn udostępniony w klastrze. Podczas tworzenia klastra trybu failover wszystkie istniejące dyski udostępnione są automatycznie dodawane do klastra. W tym momencie można dodać je do pliku CSV. Jeśli później dodasz więcej dysków do udostępnionego magazynu, musisz najpierw dodać magazyn do klastra, a następnie dodać magazyn do woluminu CSV. Wszystkie te zadania można wykonać przy użyciu Menedżera klastra trybu failover lub poleceń cmdlet programu Windows PowerShell.