Scenariusze pozyskiwania strumienia
Usługa Azure Synapse Analytics udostępnia wiele sposobów analizowania dużych ilości danych. Dwa z najbardziej typowych podejść do analizy danych na dużą skalę to:
- Magazyny danych — relacyjne bazy danych zoptymalizowane pod kątem rozproszonego magazynu i przetwarzania zapytań. Dane są przechowywane w tabelach i są odpytywane przy użyciu języka SQL.
- Data lake — rozproszony magazyn plików, w którym dane są przechowywane jako pliki, które mogą być przetwarzane i odpytywane przy użyciu wielu środowisk uruchomieniowych, w tym Apache Spark i SQL.
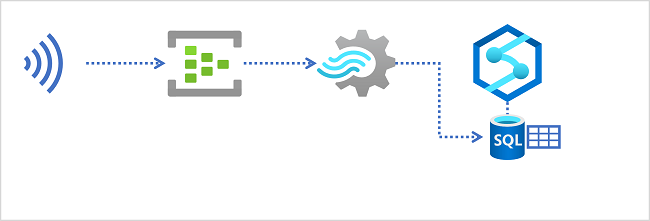
Magazyny danych w usłudze Azure Synapse Analytics
Usługa Azure Synapse Analytics udostępnia dedykowane pule SQL, których można użyć do implementowania magazynów danych relacyjnych w skali przedsiębiorstwa. Dedykowane pule SQL są oparte na wystąpieniu masowego przetwarzania równoległego (MPP) aparatu relacyjnej bazy danych programu Microsoft SQL Server, w którym dane są przechowywane i odpytywane w tabelach.
Aby pozyskiwać dane w czasie rzeczywistym do magazynu danych relacyjnych, zapytanie usługi Azure Stream Analytics musi zapisywać wyniki w danych wyjściowych odwołujących się do tabeli, do której chcesz załadować dane.
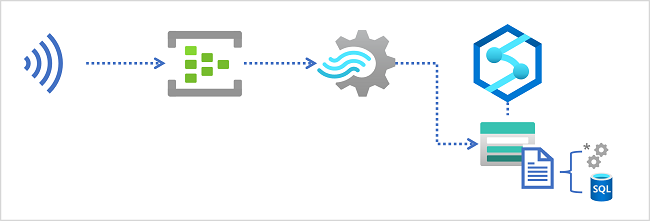
Magazyny data lake w usłudze Azure Synapse Analytics
Obszar roboczy usługi Azure Synapse Analytics zazwyczaj obejmuje co najmniej jedną usługę magazynu używaną jako usługa Data Lake. Najczęściej usługa Data Lake jest hostowana na koncie usługi Azure Storage przy użyciu kontenera skonfigurowanego do obsługi usługi Azure Data Lake Storage Gen2. Pliki w usłudze Data Lake są uporządkowane hierarchicznie w katalogach (folderach) i mogą być przechowywane w wielu formatach plików, w tym tekst rozdzielany przecinkami lub CSV, Parquet i JSON.
Podczas pozyskiwania danych w czasie rzeczywistym do magazynu typu data lake zapytanie usługi Azure Stream Analytics musi zapisywać wyniki w danych wyjściowych odwołujących się do lokalizacji w kontenerze magazynu usługi Azure Data Lake Gen2, w którym chcesz zapisać pliki danych. Analitycy danych, inżynierowie i analitycy mogą następnie przetwarzać i wykonywać zapytania dotyczące plików w usłudze Data Lake, uruchamiając kod w puli Apache Spark lub uruchamiając zapytania SQL przy użyciu bezserwerowej puli SQL.