Omówienie indeksów
Indeks usługi Azure AI Search można traktować jako kontener dokumentów z możliwością wyszukiwania. Koncepcyjnie indeks można traktować jako tabelę, a każdy wiersz w tabeli reprezentuje dokument. Tabele zawierają kolumny, a kolumny mogą być uważane za równoważne polam w dokumencie. Kolumny mają określony typ danych, podobnie jak pola w dokumentach.
Schemat indeksu
W usłudze Azure AI Search indeks jest trwałym zbiorem dokumentów JSON i innej zawartości używanej do włączania funkcji wyszukiwania. Dokumenty w indeksie można traktować jako wiersze w tabeli, przy czym każdy dokument w indeksie to pojedyncza jednostka danych z możliwością wyszukiwania.
Indeks zawiera definicję struktury danych w tych dokumentach, nazywaną jej schematem. Poniżej przedstawiono przykład schematu indeksu z wyodrębnianymi polami sztucznej inteligencji:

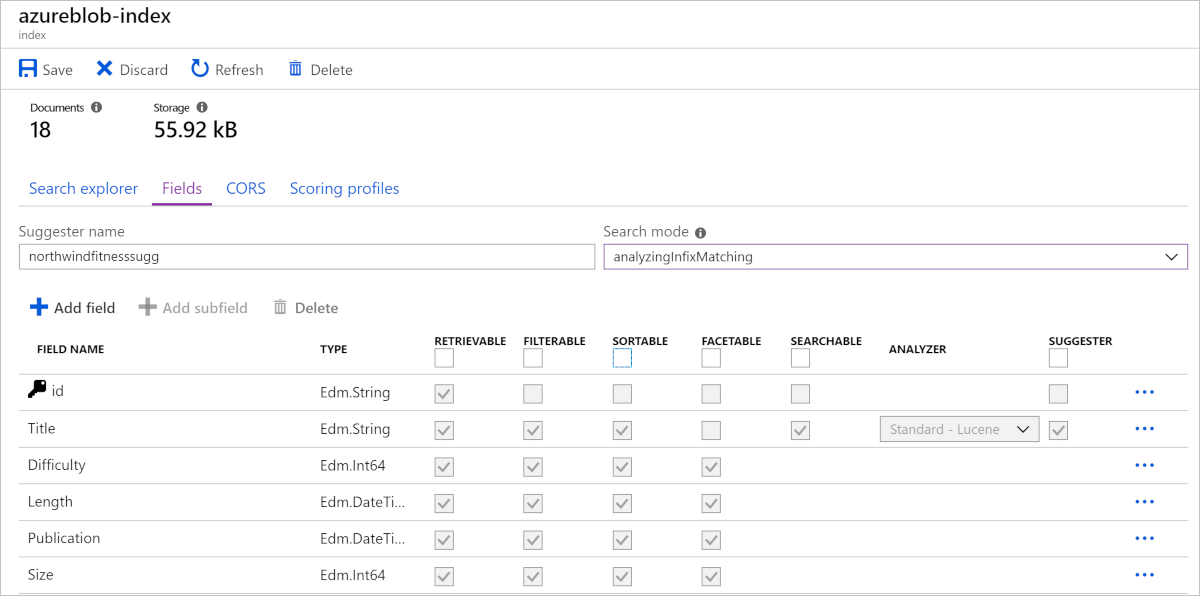
Atrybuty indeksu
Usługa Azure AI Search musi wiedzieć, jak chcesz wyszukiwać i wyświetlać pola w dokumentach. Należy to określić, przypisując atrybuty lub zachowania do tych pól. Dla każdego pola w dokumencie indeks przechowuje jego nazwę, typ danych i obsługiwane zachowania dla pola, takie jak, czy pole można przeszukiwać, czy pole można sortować?
Najbardziej wydajne indeksy używają tylko wymaganych zachowań. Jeśli zapomnisz ustawić wymagane zachowanie w polu podczas projektowania, jedynym sposobem uzyskania tej funkcji jest ponowne skompilowanie indeksu.
Na poniższej ilustracji przedstawiono pola podczas projektowania indeksu na platformie Azure: