Metodyka DevOps w uczeniu maszynowym
Metodyka DevOps i metodyka MLOps
Metodyka DevOps jest opisana jako związek osób, procesów i produktów w celu umożliwienia ciągłego dostarczania wartości naszym użytkownikom końcowym przez Donovan Brown w artykule Co to jest DevOps?.
Aby dowiedzieć się, jak jest ona używana podczas pracy z modelami uczenia maszynowego, zapoznajmy się z podstawowymi zasadami metodyki DevOps.
DevOps to kombinacja narzędzi i praktyk prowadzących deweloperów do tworzenia niezawodnych i powtarzalnych aplikacji. Celem korzystania z zasad metodyki DevOps jest szybkie dostarczanie wartości użytkownikowi końcowemu.
Jeśli chcesz łatwiej dostarczać wartość, integrując modele uczenia maszynowego w potokach przekształcania danych lub aplikacje w czasie rzeczywistym, skorzystaj z implementacji zasad Metodyki DevOps. Edukacja o metodyce DevOps pomoże Ci organizować i automatyzować pracę.
Tworzenie, wdrażanie i monitorowanie niezawodnych i powtarzalnych modeli w celu dostarczania wartości użytkownikowi końcowemu jest celem operacji uczenia maszynowego (MLOps).
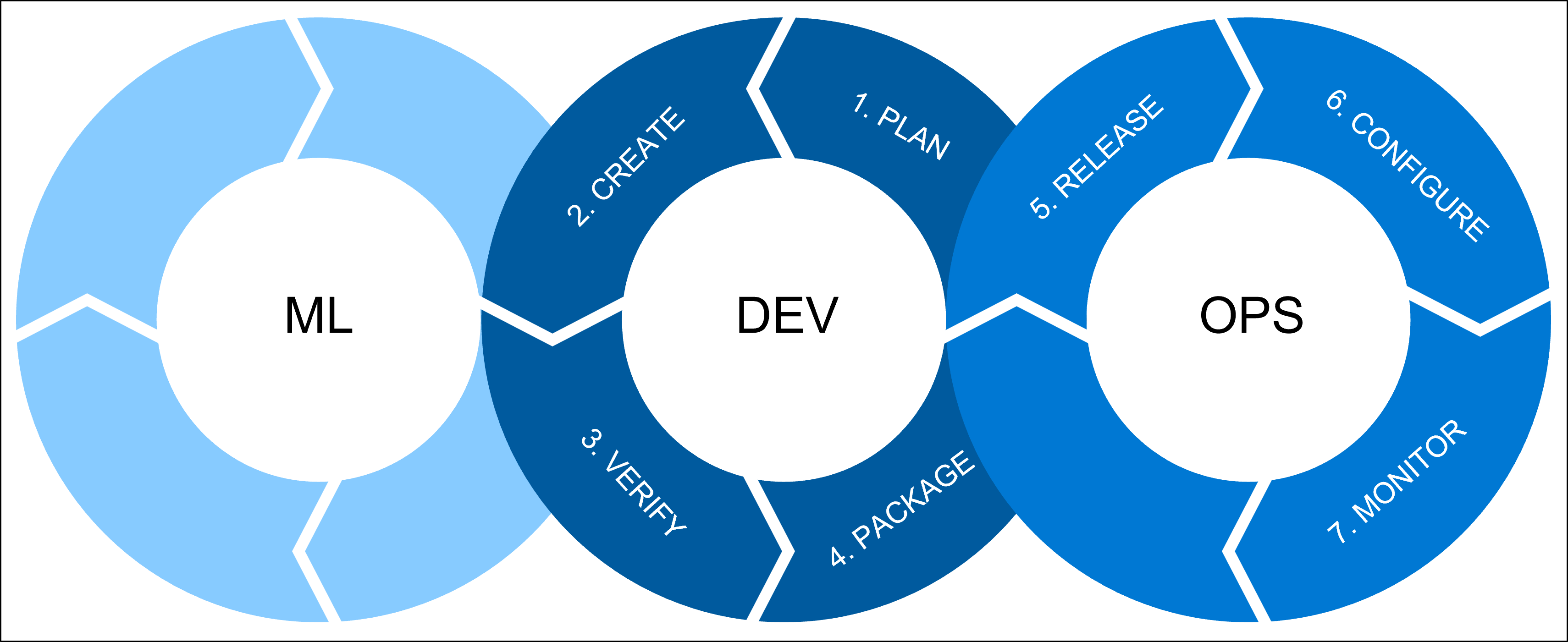
Istnieją trzy procesy, które chcemy połączyć za każdym razem, gdy mówimy o operacjach uczenia maszynowego (MLOps):
Uczenie maszynowe obejmuje wszystkie obciążenia uczenia maszynowego, za które odpowiada analityk danych. Analityk danych wykona:
- Eksploracyjna analiza danych (EDA)
- Inżynieria cech
- Trenowanie i dostrajanie modelu
Deweloper odnosi się do tworzenia oprogramowania, w tym:
- Plan: zdefiniuj wymagania i metryki wydajności modelu.
- Tworzenie: tworzenie skryptów trenowania i oceniania modelu.
- Sprawdź: sprawdź, czy kod i jakość modelu.
- Pakiet: Przygotuj się do wdrożenia, inscenując rozwiązanie.
Platforma OPS odnosi się do operacji i obejmuje:
- Wydanie: Wdróż model w środowisku produkcyjnym.
- Konfigurowanie: Standaryzacja konfiguracji infrastruktury przy użyciu infrastruktury jako kodu (IaC).
- Monitor: śledź metryki i upewnij się, że model i infrastruktura działają zgodnie z oczekiwaniami.
Przyjrzyjmy się niektórym zasadom metodyki DevOps, które są niezbędne dla metodyki MLOps.
Zasady metodyki DevOps
Jedną z podstawowych zasad metodyki DevOps jest automatyzacja. Automatyzując zadania, aspirujemy do szybszego wdrażania nowych modeli w środowisku produkcyjnym. Dzięki automatyzacji utworzysz również odtwarzalne modele, które są niezawodne i spójne w różnych środowiskach.
Szczególnie jeśli chcesz regularnie ulepszać model w miarę upływu czasu, automatyzacja umożliwia szybkie wykonywanie wszystkich niezbędnych działań w celu zapewnienia, że model w środowisku produkcyjnym jest zawsze najlepszym modelem.
Kluczową koncepcją do osiągnięcia automatyzacji jest ciągła integracja/ciągłe dostarczanie, co oznacza ciągłą integrację i ciągłe dostarczanie.
Ciągła integracja
Ciągła integracja obejmuje tworzenie i weryfikowanie działań. Celem jest utworzenie kodu i zweryfikowanie jakości kodu i modelu przez automatyczne testowanie.
W przypadku metodyki MLOps ciągła integracja może obejmować:
- Refaktoryzacja kodu eksploracyjnego w notesach Jupyter do skryptów języka Python lub R.
- Linting, aby sprawdzić wszelkie błędy programowe lub stylistyczne w skryptach języka Python lub R. Na przykład sprawdź, czy wiersz skryptu zawiera mniej niż 80 znaków.
- Testowanie jednostkowe w celu sprawdzenia wydajności zawartości skryptów. Na przykład sprawdź, czy model generuje dokładne przewidywania na testowym zestawie danych.
Napiwek
Dowiedz się, jak konwertować eksperymenty uczenia maszynowego na produkcyjny kod w języku Python
Aby przeprowadzić testowanie lintingu i jednostkowe, możesz użyć narzędzi automatyzacji, takich jak Azure Pipelines w usłudze Azure DevOps lub GitHub Actions.
Ciągłe dostarczanie
Po zweryfikowaniu jakości kodu skryptów języka Python lub R używanych do trenowania modelu warto przenieść model do środowiska produkcyjnego. Ciągłe dostarczanie obejmuje kroki, które należy wykonać, aby wdrożyć model w środowisku produkcyjnym, najlepiej zautomatyzować jak najwięcej.
Aby wdrożyć model w środowisku produkcyjnym, najpierw należy go spakować i wdrożyć w środowisku przedprodukcyjnym. Przesiewając model w środowisku przedprodukcyjnym, możesz sprawdzić, czy wszystko działa zgodnie z oczekiwaniami.
Po pomyślnym wdrożeniu modelu w fazie przejściowej i bez błędów można zatwierdzić wdrożenie modelu w środowisku produkcyjnym.
Aby współpracować nad skryptami języka Python lub R w celu wytrenowania modelu i dowolnego niezbędnego kodu do wdrożenia modelu w każdym środowisku, użyjesz kontroli źródła.
Kontrola źródła
Kontrola źródła (lub kontrola wersji) jest najczęściej osiągana przez pracę z repozytorium opartym na usłudze Git. Repozytorium odnosi się do lokalizacji, w której można przechowywać wszystkie odpowiednie pliki w projekcie oprogramowania.
W przypadku projektów uczenia maszynowego prawdopodobnie będziesz mieć repozytorium dla każdego posiadanego projektu. Repozytorium będzie zawierać między innymi notesy Jupyter, skrypty szkoleniowe, skrypty oceniania i definicje potoków.
Uwaga
Najlepiej, że nie przechowujesz danych treningowych w repozytorium. Zamiast tego dane szkoleniowe są przechowywane w bazie danych lub usłudze Data Lake, a usługa Azure Machine Edukacja pobiera dane bezpośrednio ze źródła danych przy użyciu magazynów danych.
Repozytoria oparte na usłudze Git są dostępne przy użyciu usługi Azure Repos w usłudze Azure DevOps lub repozytorium GitHub.
Hostując cały odpowiedni kod w repozytorium, możesz łatwo współpracować nad kodem i śledzić wszelkie zmiany wprowadzone przez członka zespołu. Każdy element członkowski może pracować na własnej wersji kodu. Zobaczysz wszystkie wcześniejsze zmiany i możesz przejrzeć zmiany, zanim zostaną zatwierdzone w repozytorium głównym.
Aby zdecydować, kto pracuje nad częścią projektu, zaleca się użycie planowania elastycznego.
Planowanie Agile
Ponieważ chcesz, aby model został szybko wdrożony w środowisku produkcyjnym, elastyczne planowanie jest idealne dla projektów uczenia maszynowego.
Planowanie agile oznacza izolowanie pracy w sprintach. Przebiegi to krótkie okresy, w których chcesz osiągnąć część celów projektu.
Celem jest zaplanowanie przebiegów, aby szybko poprawić dowolny kod. Niezależnie od tego, czy jest to kod używany do eksploracji danych i modelu, czy wdrażania modelu w środowisku produkcyjnym.
Trenowanie modelu uczenia maszynowego może być procesem niekończącym się. Na przykład jako analityk danych może być konieczne zwiększenie wydajności modelu z powodu dryfu danych. Możesz też dostosować model, aby lepiej dostosować go do nowych wymagań biznesowych.
Aby uniknąć poświęcania zbyt dużo czasu na trenowanie modelu, elastyczne planowanie może pomóc w zakresie projektu i pomóc wszystkim dopasować się, zgadzając się na krótsze wyniki.
Aby zaplanować swoją pracę, możesz użyć narzędzia takiego jak Usługa Azure Boards w usłudze Azure DevOps lub problemy z usługą GitHub.
Infrastruktura jako kod (IaC)
Stosowanie zasad metodyki DevOps do projektów uczenia maszynowego oznacza, że chcesz tworzyć niezawodne powtarzalne rozwiązania. Innymi słowy, wszystko, co robisz lub utworzysz, powinno być możliwe powtarzanie i automatyzowanie.
Aby powtórzyć i zautomatyzować infrastrukturę wymaganą do trenowania i wdrażania modelu, zespół będzie używać infrastruktury jako kodu (IaC). Podczas trenowania i wdrażania modeli na platformie Azure usługa IaC oznacza, że definiujesz wszystkie zasoby platformy Azure potrzebne w procesie w kodzie, a kod jest przechowywany w repozytorium.
Napiwek
Dowiedz się więcej o metodyce DevOps, eksplorując moduły usługi Microsoft Learn na drodze do transformacji metodyki DevOps