Semantyczne modele językowe
Uwaga / Notatka
Aby uzyskać więcej szczegółów, zobacz kartę Tekst i obrazy .
Ponieważ stan rozwoju NLP jest zaawansowany, zdolność do trenowania modeli, które uchwycają semantyczną relację między tokenami, doprowadziła do powstania potężnych modeli językowych głębokiego uczenia. W centrum tych modeli jest kodowanie tokenów języka jako wektorów (tablic wielowartościowych liczb) znanych jako embeddings.
Takie podejście oparte na wektorach do modelowania tekstu stało się powszechne w przypadku technik takich jak Word2Vec i GloVe, w których tokeny tekstowe są reprezentowane jako gęste wektory z wieloma wymiarami. Podczas trenowania modelu wartości wymiarów są przypisywane w celu odzwierciedlenia semantycznych cech każdego tokenu na podstawie ich użycia w tekście trenowania. Relacje matematyczne między wektorami można następnie wykorzystać do wykonywania typowych zadań analizy tekstu wydajniej niż starsze techniki czysto statystyczne. Bardziej aktualnym postępem w tym podejściu jest użycie techniki zwanej attention, aby rozważyć każdy token w kontekście i obliczyć wpływ tokenów wokół niego. Wynikowe kontekstowe osadzanie, takie jak te znalezione w rodzinie modeli GPT, stanowią podstawę nowoczesnej sztucznej inteligencji generowania.
Reprezentacja tekstu jako wektorów
Wektory reprezentują punkty w przestrzeni wielowymiarowej zdefiniowanej przez współrzędne wzdłuż wielu osi. Każdy wektor opisuje kierunek i odległość od źródła. Semantycznie podobne tokeny powinny prowadzić do wektorów o podobnej orientacji — innymi słowy, wskazują w podobnych kierunkach.
Rozważmy na przykład następujące trójwymiarowe osadzanie dla niektórych typowych słów:
| Słowo | Vector |
|---|---|
dog |
[0.8, 0.6, 0.1] |
puppy |
[0.9, 0.7, 0.4] |
cat |
[0.7, 0.5, 0.2] |
kitten |
[0.8, 0.6, 0.5] |
young |
[0.1, 0.1, 0.3] |
ball |
[0.3, 0.9, 0.1] |
tree |
[0.2, 0.1, 0.9] |
Możemy zwizualizować te wektory w przestrzeni trójwymiarowej, jak pokazano poniżej:

Wektory dla "dog" i "cat" są podobne (zarówno zwierzęta domowe), jak i "puppy""kitten" (oba młode zwierzęta). Wyrazy "tree", "young"i ball" mają wyraźnie różne orientacje wektorów, odzwierciedlając ich różne znaczenia semantyczne.
Cecha semantyczna zakodowana w wektorach umożliwia używanie operacji opartych na wektorach, które porównują wyrazy i umożliwiają porównania analityczne.
Znajdowanie powiązanych terminów
Ponieważ orientacja wektorów jest określana przez ich wartości wymiarów, wyrazy o podobnych znaczeniach semantycznych mają tendencję do podobnych orientacji. Oznacza to, że można użyć obliczeń, takich jak podobieństwo cosinusu między wektorami, aby dokonać znaczących porównań.
Aby na przykład określić "element odstający" między "dog", "cat" i "tree", można obliczyć podobieństwo kosinusowe między parami wektorów. Podobieństwo cosinus jest obliczane jako:
cosine_similarity(A, B) = (A · B) / (||A|| * ||B||)
Gdzie A · B jest kropką i ||A|| jest wielkością wektora A.
Obliczanie podobieństw między trzema wyrazami:
dog[0.8, 0.6, 0.1] icat[0.7, 0.5, 0.2]:- Produkt kropkowy: (0,8 × 0,7) + (0,6 × 0,5) + (0,1 × 0,2) = 0,56 + 0,30 + 0,0,02 = 0,88
-
dogWielkość : √(0,8² + 0,6² + 0,1²) = √(0,64 + 0,36 + 0,01) = √1,01 ≈ 1,005 -
catWielkość : √(0,7² + 0,5² + 0,2²) = √(0,49 + 0,25 + 0,04) = √0,78 ≈ 0,883 - Podobieństwo cosinusu: 0,88 / (1,005 × 0,883) ≈ 0,992 (wysokie podobieństwo)
dog[0.8, 0.6, 0.1] itree[0.2, 0.1, 0.9]:- Produkt kropkowy: (0,8 × 0,2) + (0,6 × 0,1) + (0,1 × 0,9) = 0,16 + 0,06 + 0,09 = 0,31
-
treeWielkość : √(0,2² + 0,1² + 0,9²) = √(0,04 + 0,01 + 0,81) = √0,86 ≈ 0,927 - Podobieństwo cosinusu: 0,31 / (1,005 × 0,927) ≈ 0,333 (niskie podobieństwo)
cat[0.7, 0.5, 0.2] itree[0.2, 0.1, 0.9]:- Produkt kropkowy: (0,7 × 0,2) + (0,5 × 0,1) + (0,2 × 0,9) = 0,14 + 0,05 + 0,18 = 0,37
- Podobieństwo kosinusowe: 0,37 / (0,883 × 0,927) ≈ 0,452 (niskie podobieństwo)
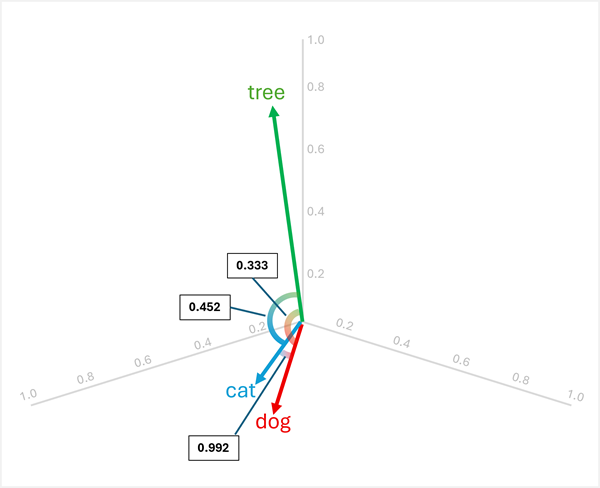
Wyniki pokazują, że "dog" i "cat" są bardzo podobne (0,992), natomiast "tree" mają niższą podobieństwo do obu "dog" (0,333) i "cat" (0,452). Dlatego tree jest wyraźnie tym, który odstaje.
Translacja wektorowa poprzez dodawanie i odejmowanie
Można dodawać lub odejmować wektory, aby tworzyć nowe wyniki oparte na wektorach; które następnie mogą służyć do znajdowania tokenów z pasującymi wektorami. Ta technika umożliwia intuicyjną logikę opartą na arytmetyce w celu określenia odpowiednich terminów na podstawie relacji językowych.
Na przykład, używając wcześniej zdefiniowanych wektorów:
-
dog+young= [0.8, 0.6, 0.1] + [0.1, 0.1, 0.3] = [0.9, 0.7, 0.4] =puppy -
cat+young= [0.7, 0.5, 0.2] + [0.1, 0.1, 0.3] = [0.8, 0.6, 0.5] =kitten
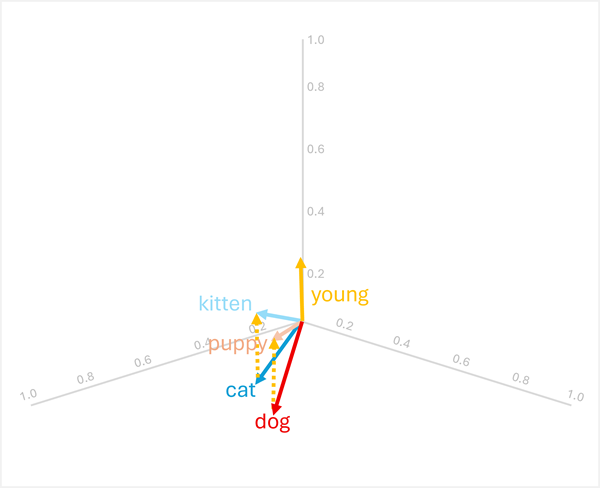
Te operacje działają, ponieważ wektor dla "young" koduje semantyczną transformację od dorosłego zwierzęcia do jego młodego odpowiednika.
Uwaga / Notatka
W praktyce arytmetyka wektorowa rzadko generuje dokładne dopasowania; Zamiast tego należy wyszukać słowo, którego wektor jest najbliżej (najbardziej podobny) do wyniku.
Arytmetyka działa również odwrotnie:
-
puppy-young= [0.9, 0.7, 0.4] - [0.1, 0.1, 0.3] = [0.8, 0.6, 0.1] =dog -
kitten-young= [0.8, 0.6, 0.5] - [0.1, 0.1, 0.3] = [0.7, 0.5, 0.2] =cat
Analogiczne rozumowanie
Arytmetyka wektorowa może również odpowiedzieć na pytania analogii, takie jak "
Aby rozwiązać ten problem, oblicz następujące elementy: kitten - puppy + dog
- [0.8, 0.6, 0.5] - [0.9, 0.7, 0.4] + [0.8, 0.6, 0.1]
- = [-0.1, -0.1, 0.1] + [0.8, 0.6, 0.1]
- = [0.7, 0.5, 0.2]
- =
cat
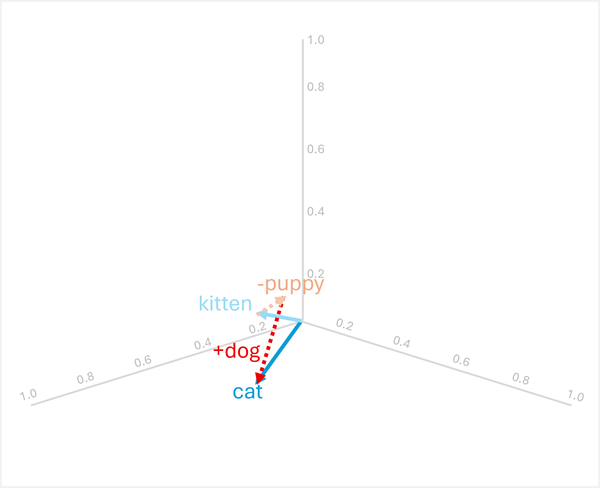
W tych przykładach pokazano, jak operacje wektorów mogą przechwytywać relacje językowe i umożliwiać wnioskowanie o wzorcach semantycznych.
Używanie modeli semantycznych do analizy tekstu
Modele semantyczne oparte na wektorach zapewniają zaawansowane możliwości wielu typowych zadań analizy tekstu.
Podsumowanie tekstu
Osadzanie semantyczne umożliwia podsumowanie ekstrakcyjne, identyfikując zdania z wektorami, które są najbardziej reprezentatywne dla całego dokumentu. Kodując każde zdanie jako wektor (często przez uśrednianie lub buforowanie osadzonych wyrazów składowych), można obliczyć, które zdania są najbardziej kluczowe dla znaczenia dokumentu. Te centralne zdania można wyodrębnić w celu utworzenia podsumowania, które przechwytuje kluczowe motywy.
Ekstrakcja słów kluczowych
Podobieństwo wektorów może zidentyfikować najważniejsze terminy w dokumencie, porównując osadzanie każdego wyrazu z ogólną reprezentacją semantyczną dokumentu. Wyrazy, których wektory są najbardziej podobne do wektora dokumentu lub najbardziej centralne podczas rozważania wszystkich wektorów wyrazów w dokumencie, mogą być kluczowymi terminami reprezentującymi główne tematy.
Rozpoznawanie jednostek nazwanych
Modele semantyczne można dostosować do rozpoznawania nazwanych jednostek (osób, organizacji, lokalizacji itp.) przez reprezentacje wektorów uczenia, które łączą podobne typy jednostek. Podczas wnioskowania model sprawdza osadzanie każdego tokenu i jego kontekst, aby określić, czy reprezentuje nazwę jednostki, a jeśli tak, jaki typ.
Klasyfikacja tekstu
W przypadku zadań takich jak analiza tonacji lub kategoryzacja tematów dokumenty mogą być reprezentowane jako wektory agregujące (takie jak średnia wszystkich wyrazów osadzonych w dokumencie). Te wektory dokumentów mogą być następnie używane jako funkcje klasyfikatorów uczenia maszynowego lub porównywane bezpośrednio z wektorami prototypów klas w celu przypisania kategorii. Ze względu na to, że podobne dokumenty mają podobne orientacje wektorów, takie podejście skutecznie grupuje powiązaną zawartość i rozróżnia różne kategorie.