Opis przetwarzania zdarzeń
Azure Stream Analytics to usługa służąca do złożonego przetwarzania zdarzeń i analizy danych przesyłanych strumieniowo. Usługa Stream Analytics jest używana do:
- Pozyskiwanie danych z danych wejściowych, takich jak centrum zdarzeń platformy Azure, Azure IoT Hub lub kontener obiektów blob usługi Azure Storage.
- Przetwarzanie danych przy użyciu zapytania w celu wybrania, projektu i zagregowania wartości danych.
- Zapisz wyniki w danych wyjściowych, takich jak Azure Data Lake Gen 2, Azure SQL Database, Azure Synapse Analytics, Azure Functions, Centrum zdarzeń platformy Azure, Microsoft Power BI lub inne.
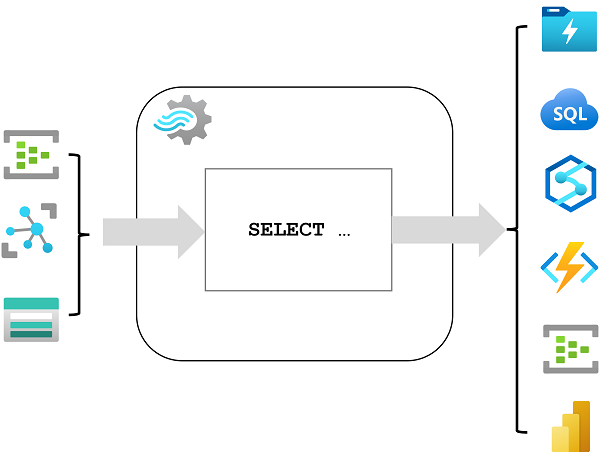
Po uruchomieniu zapytanie usługi Stream Analytics będzie uruchamiane bezterminowo, przetwarzając nowe dane po nadejściu danych wejściowych i przechowując wyniki w danych wyjściowych.
Usługa Stream Analytics gwarantuje dokładnie jednokrotne przetwarzanie zdarzeń oraz co najmniej jednokrotne dostarczenie zdarzeń, więc nigdy nie dochodzi do utraty zdarzeń. Ma wbudowane funkcje odzyskiwania na wypadek awarii podczas dostarczania zdarzeń. Ponadto usługa Stream Analytics udostępnia wbudowane punkty kontrolne umożliwiające utrzymywanie stanu zadania i zapewniające powtarzalność wyników. Ponieważ usługa Azure Stream Analytics to rozwiązanie typu "platforma jako usługa" (PaaS), jest w pełni zarządzane i wysoce niezawodne. Wbudowana integracja z różnymi źródłami i miejscami docelowymi zapewnia elastyczny model programowości. Aparat usługi Stream Analytics umożliwia obliczenia w pamięci, dzięki czemu zapewnia wysoką wydajność.
Zadania i klastry usługi Azure Stream Analytics
Najprostszym sposobem korzystania z usługi Azure Stream Analytics jest utworzenie zadania usługi Stream Analytics w subskrypcji platformy Azure, skonfigurowanie danych wejściowych i wyjściowych oraz zdefiniowanie zapytania, którego zadanie będzie używać do przetwarzania danych. Zapytanie jest wyrażane przy użyciu składni języka zapytań strukturalnych (SQL) i może uwzględniać statyczne dane referencyjne z wielu źródeł danych w celu dostarczania wartości odnośników, które można połączyć z danymi przesyłanymi strumieniowo pozyskanymi z danych wejściowych.
Jeśli wymagania dotyczące przetwarzania strumieniowego są złożone lub intensywnie obciążające zasoby, możesz utworzyć klaster usługi Stream Analysis, który używa tego samego aparatu przetwarzania jako zadania usługi Stream Analytics, ale w dedykowanej dzierżawie (więc przetwarzanie nie ma wpływu na innych klientów) i z konfigurowalną skalowalnością, która umożliwia zdefiniowanie odpowiedniej równowagi przepływności i kosztów dla konkretnego scenariusza.
Dane wejściowe
Usługa Azure Stream Analytics może pozyskiwać dane z następujących rodzajów danych wejściowych:
- Azure Event Hubs
- Azure IoT Hub
- Azure Blob Storage
- Usługa Azure Data Lake Storage 2. generacji
Dane wejściowe są zwykle używane do odwołowania się do źródła danych przesyłanych strumieniowo, które są przetwarzane w miarę dodawania nowych rekordów zdarzeń. Ponadto można zdefiniować dane wejściowe referencyjne używane do pozyskiwania danych statycznych w celu rozszerzenia danych strumienia zdarzeń w czasie rzeczywistym. Można na przykład pozyskać strumień danych obserwacji pogody w czasie rzeczywistym, który zawiera unikatowy identyfikator dla każdej stacji pogodowej, i rozszerzyć te dane przy użyciu statycznych danych referencyjnych, które pasują do identyfikatora stacji pogodowej, aby uzyskać bardziej zrozumiałą nazwę.
Dane wyjściowe
Dane wyjściowe są miejscami docelowymi, do których są wysyłane wyniki przetwarzania strumienia. Usługa Azure Stream Analytics obsługuje szeroką gamę danych wyjściowych, których można użyć do:
- Utrwalanie wyników przetwarzania strumieniowego w celu dalszej analizy; na przykład przez załadowanie ich do usługi Data Lake lub magazynu danych.
- Wyświetlanie wizualizacji strumienia danych w czasie rzeczywistym; na przykład przez dołączenie danych do zestawu danych w usłudze Microsoft Power BI.
- Generowanie przefiltrowanych lub podsumowanych zdarzeń na potrzeby przetwarzania podrzędnego; na przykład pisząc wyniki przetwarzania strumieniowego do centrum zdarzeń.
Zapytania
Logika przetwarzania strumieniowego jest hermetyzowana w zapytaniu. Zapytania są definiowane przy użyciu instrukcji SQL, które wybierają pola danych z co najmniej jednego danych wejściowych, filtrują lub agregują dane, a następnie zapisują wyniki w danych wyjściowych. Na przykład następujące zapytanie filtruje zdarzenia z danych wejściowych zdarzeń pogodowych w celu uwzględnienia tylko danych z zdarzeń o wartości mniejszej niż 0 i zapisuje wyniki w danych wyjściowych zimnych tempów :
SELECT observation_time, weather_station, temperature
INTO cold-temps
FROM weather-events TIMESTAMP BY observation_time
WHERE temperature < 0
Pole o nazwie EventProcessedUtcTime jest tworzone automatycznie w celu zdefiniowania czasu przetwarzania zdarzenia przez zapytanie usługi Azure Stream Analytics. To pole umożliwia określenie znacznika czasu zdarzenia lub jawne określenie innego pola DateTime przy użyciu klauzuli TIMESTAMP BY , jak pokazano w tym przykładzie. W zależności od danych wejściowych, z których dane przesyłane strumieniowo są odczytywane, możliwe jest automatyczne utworzenie co najmniej jednego potencjalnego pola znacznika czasu; na przykład w przypadku korzystania z danych wejściowych usługi Event Hubs pole o nazwie EventQueuedUtcTime jest generowane w celu zarejestrowania czasu odebrania zdarzenia w kolejce centrum zdarzeń.
Pole używane jako sygnatura czasowa jest ważne podczas agregowania danych w oknach czasowych, które omówiono w następnej części.