Wprowadzenie do usługi Azure Database for PostgreSQL
Usługa Azure Database for PostgreSQL jest dostępna w wersjach wieloserwerowych.
Jako deweloper bazy danych z wieloletnim doświadczeniem w uruchamianiu lokalnych instalacji postgreSQL i zarządzaniu nimi chcesz dowiedzieć się, jak usługa Azure Database for PostgreSQL obsługuje i skaluje jego funkcje.
W tej lekcji zapoznasz się z cennikiem, obsługą wersji, replikacją i opcjami skalowania usługi Azure Database for PostgreSQL.
Azure Database for PostgreSQL
Usługa Azure Database for PostgreSQL to implementacja społecznościowej wersji bazy danych PostgreSQL. Usługa udostępnia typowe funkcje używane przez typowe systemy PostgreSQL, w tym obsługę geoprzestrzeni i wyszukiwanie pełnotekstowe.
Firma Microsoft zaadaptowała program PostgreSQL dla platformy Azure i jest ściśle zintegrowana z wieloma usługami platformy Azure. Usługa Azure Database for PostgreSQL jest w pełni zarządzana przez firmę Microsoft. Microsoft obsługuje aktualizacje i poprawki oprogramowania oraz zapewnia SLA o dostępności na poziomie 99,99%. Oznacza to, że możesz po prostu skoncentrować się na uruchomionych bazach danych i aplikacjach przy użyciu usługi.
W każdym wystąpieniu tej usługi można wdrożyć wiele baz danych.
Poziomy cenowe
Podczas tworzenia wystąpienia usługi Azure Database for PostgreSQL należy określić zasoby obliczeniowe i magazynowe, które chcesz przydzielić, wybierając warstwę cenową . Warstwa cenowa łączy liczbę rdzeni procesora wirtualnego, ilość dostępnego miejsca do magazynowania i różne opcje tworzenia kopii zapasowych. Im więcej zasobów przydzielasz, tym wyższy koszt.
Usługa Azure Database for PostgreSQL używa magazynu do przechowywania plików bazy danych, plików tymczasowych, dzienników transakcji i dzienników serwera. Możesz opcjonalnie określić, że przestrzeń magazynowa zostanie zwiększona, gdy zbliżasz się do bieżącej pojemności. Jeśli nie wybierzesz tej opcji, serwery, na których zabraknie miejsca do magazynowania, będą nadal działać, ale działają jako tylko do odczytu.
Witryna Azure Portal grupuje warstwy cenowe na trzy szerokie zakresy:
- Podstawowa, która jest odpowiednia dla małych systemów i środowisk programistycznych, ale ma zmienną wydajność we/wy.
- Zastosowanie ogólne, który zapewnia przewidywalną wydajność, aż do 6000 IOPS, w zależności od liczby rdzeni procesora i dostępnego miejsca na pamięć.
- Zoptymalizowana pod kątem pamięci, która używa do 32 rdzeni procesorów wirtualnych zoptymalizowanych pod kątem pamięci, a także zapewnia przewidywalną wydajność do 6000 operacji we/wy na sekundę.
Firma Microsoft ma również opcję dużego magazynu w wersji zapoznawczej, która może oferować do 16 TB miejsca magazynowego i obsługiwać maksymalnie 20 000 IOPS.
Możesz dostosować liczbę wymaganych rdzeni procesora i pamięci. Można skalować w górę i w dół zasoby przetwarzania — magazyn można skalować tylko w górę — i po utworzeniu baz danych przełączać się między warstwami cenowymi o Ogólnym przeznaczeniu oraz Zoptymalizowanymi pod kątem pamięci zgodnie z potrzebami. Płacisz tylko za to, czego potrzebujesz.

Uwaga
Jeśli zmienisz liczbę rdzeni procesora, platforma Azure utworzy nowy serwer z tą alokacją obliczeniową. Po uruchomieniu serwera połączenia klienckie są przełączane na nowy serwer. Proces przełączania może potrwać do minuty. W tym interwale nie można nawiązać nowych połączeń, a wszystkie transakcje w locie zostaną wycofane.
Jeśli zmienisz tylko rozmiar magazynu opcji tworzenia kopii zapasowych, nie będzie żadnych przerw w działaniu usługi.
Warstwa cenowa i przydzielone zasoby przetwarzania określają maksymalną liczbę współbieżnych połączeń, które będzie obsługiwać usługa. Jeśli na przykład wybierzesz warstwę cenową Ogólnego przeznaczenia i przydzielisz 64 rdzenie wirtualne, usługa obsługuje 1900 połączeń współbieżnych. Warstwa Podstawowa z dwoma rdzeniami wirtualnymi obsługuje maksymalnie 100 połączeń współbieżnych. Sama platforma Azure wymaga pięciu z tych połączeń do monitorowania serwera. W przypadku przekroczenia liczby dostępnych połączeń klienci otrzymają błąd KRYTYCZNY: niestety, zbyt wielu klientów.
Ceny mogą ulec zmianie. Aby uzyskać najnowsze informacje, odwiedź stronę cennika usługi Azure Database for PostgreSQL .
Parametry serwera
W lokalnej instalacji bazy danych PostgreSQL należy ustawić parametry konfiguracji serwera w pliku postgresql.conf . Użyj usługi Azure Database for PostgreSQL, aby zmodyfikować parametry konfiguracji za pośrednictwem strony Parametry serwera . Nie wszystkie parametry instalacji lokalnej bazy danych PostgreSQL są istotne dla usługi Azure Database for PostgreSQL, dlatego na stronie Parametry serwera są wyświetlane tylko te parametry, które są odpowiednie dla platformy Azure.

Zmiany parametrów oznaczonych jako Dynamiczne zostaną zastosowane natychmiast. Parametry statyczne wymagają ponownego uruchomienia serwera. Uruchom ponownie serwer przy użyciu przycisku Uruchom ponownie na stronie Przegląd w portalu:

Wysoka dostępność
Usługa Azure Database for PostgreSQL to usługa o wysokiej dostępności. Zawiera wbudowane mechanizmy wykrywania błędów i trybu failover. Jeśli węzeł przetwarzania zostanie zatrzymany z powodu problemu ze sprzętem lub oprogramowaniem, nowy węzeł zostanie przełączony, aby go zastąpić. Wszystkie połączenia aktualnie korzystające z tego węzła zostaną porzucone, ale automatycznie otwarte względem nowego węzła. Wszystkie transakcje wykonywane przez węzeł, który ulega awarii, zostaną wycofane. Z tego powodu należy zawsze upewnić się, że klienci są skonfigurowani do wykrywania i ponawiania prób operacji zakończonych niepowodzeniem.
Obsługiwane wersje bazy danych PostgreSQL
Usługa Azure Database for PostgreSQL obecnie wspiera PostgreSQL od wersji 11 do wersji 9.5 włącznie. Określasz, która wersja bazy danych PostgreSQL ma być używana podczas tworzenia wystąpienia usługi. Firma Microsoft ma na celu zaktualizowanie usługi w miarę dostępności nowych wersji bazy danych PostgreSQL i zachowa zgodność z poprzednimi dwoma głównymi wersjami.
Platforma Azure automatycznie zarządza uaktualnieniami baz danych między wersjami pomocniczymi bazy danych PostgreSQL, ale nie wersjami głównymi. Jeśli na przykład masz bazę danych korzystającą z bazy danych PostgreSQL w wersji 10, platforma Azure może automatycznie uaktualnić bazę danych do wersji 10.1. Jeśli chcesz przełączyć się na wersję 11, musisz wyeksportować dane z baz danych w bieżącym wystąpieniu usługi, utworzyć nowe wystąpienie usługi Azure Database for PostgreSQL i zaimportować dane do tego nowego wystąpienia.
Węzły koordynatora i procesu roboczego
Dane są podzielone na fragmenty i dystrybuowane między węzłami roboczymi. Silnik zapytań w koordynatorze może równoleglać złożone zapytania, kierując przetwarzanie do odpowiednich węzłów roboczych. Węzły robocze są wybierane zgodnie z tym, które fragmenty przechowują przetwarzane dane. Następnie koordynator zbiera wyniki z węzłów roboczych przed wysłaniem ich z powrotem do klienta. Bardziej proste zapytania mogą być wykonywane przy użyciu tylko jednego węzła roboczego. Klienci łączą się również z koordynatorem i nigdy nie komunikują się bezpośrednio z węzłem roboczym.
W usłudze można skalować liczbę węzłów roboczych zgodnie z potrzebami, zwiększając lub zmniejszając ich liczbę.
Dystrybucja danych
Dane są dystrybuowane między węzłami roboczymi przez tworzenie tabel rozproszonych. Tabela rozproszona jest podzielona na fragmenty, a każdy fragment jest przydzielany do przechowywania na węźle roboczym. Wskazujesz, jak podzielić dane, definiując kolumnę jako kolumnę dystrybucji . Dane są podzielone na fragmenty na podstawie wartości danych w tej kolumnie. Podczas projektowania tabeli rozproszonej należy uważnie wybrać kolumnę dystrybucji. Należy użyć kolumny z dużą liczbą odrębnych wartości, które zwykle będą używane do grupowania powiązanych wierszy. Na przykład w tabeli dla systemu handlu elektronicznego, który przechowuje informacje o zamówieniach klientów, identyfikator klienta może być rozsądną kolumną dystrybucji. Wszystkie zamówienia dla danego klienta będą przechowywane w tym samym fragmentzie, ale zamówienia dla wszystkich klientów będą rozłożone na fragmenty.
Można również tworzyć tabele referencyjne . Tabele te zawierają dane wyszukiwania, takie jak nazwy miast lub kody stanu. Tabela referencyjna jest replikowana w całości do każdego węzła roboczego. Dane w tabeli referencyjnej powinny być stosunkowo statyczne; każda zmiana wymaga zaktualizowania każdej kopii tabeli.
Na koniec można tworzyć tabele lokalne . Tabela lokalna nie jest fragmentowana, ale jest przechowywana w węźle koordynacji. Użyj tabel lokalnych do przechowywania małych tabel z danymi, które prawdopodobnie nie będą wymagane przez łączenia. Przykłady obejmują nazwy użytkowników i ich szczegóły logowania.
Replikowanie danych w usłudze Azure Database for PostgreSQL
Repliki tylko do odczytu są przydatne do obsługi obciążeń z dużą liczbą operacji odczytu. Połączenia klienta można rozłożyć między repliki, co odciąża pojedynczą instancję usługi. Jeśli klienci znajdują się w różnych regionach świata, należy użyć replikacji między regionami, aby umieścić dane w pobliżu każdego zestawu klientów i zmniejszyć opóźnienie.
Repliki można również używać w ramach planu awaryjnego odzyskiwania po awarii. Jeśli serwer podstawowy stanie się niedostępny, nadal może być możliwe nawiązanie połączenia z repliką.
Uwaga
Jeśli serwer podstawowy zostanie utracony lub usunięty, zamiast tego wszystkie repliki tylko do odczytu staną się serwerami do odczytu i zapisu. Te serwery będą jednak niezależne od siebie, więc wszelkie zmiany wprowadzone w danych na jednym serwerze nie zostaną skopiowane do pozostałych serwerów.
Ustanawianie repliki
Replika tylko do odczytu zawiera kopię baz danych przechowywanych na oryginalnym serwerze — nazywaną podstawową. Do utworzenia repliki podstawowej jest używana witryna Azure Portal lub interfejs wiersza polecenia.

Podczas tworzenia repliki tylko do odczytu platforma Azure tworzy nowe wystąpienie usługi Azure Database for PostgreSQL, a następnie kopiuje bazy danych z serwera podstawowego do nowego serwera. Replika działa w trybie tylko do odczytu. Próba zmodyfikowania danych zakończy się niepowodzeniem.
Opóźnienie repliki
Replikacja nie jest synchroniczna, a zmiany wprowadzone w danych na serwerze podstawowym mogą zająć trochę czasu, aby pojawić się w replikach. Aplikacje klienckie, które łączą się z replikami, muszą być w stanie poradzić sobie z tym poziomem spójności ostatecznej. Usługa Azure Monitor umożliwia śledzenie opóźnienia czasu replikacji przy użyciu metryk Maksymalne opóźnienie między replikami i opóźnieniem repliki .
Zarządzanie i monitorowanie
Możesz użyć znanych narzędzi, takich jak pgAdmin , aby nawiązać połączenie z usługą Azure Database for PostgreSQL w celu zarządzania bazami danych i monitorowania ich. Jednak niektóre funkcje skoncentrowane na serwerze, takie jak wykonywanie kopii zapasowej i przywracanie serwera, nie są dostępne, ponieważ serwer jest zarządzany i obsługiwany przez firmę Microsoft.

Narzędzia platformy Azure do monitorowania usługi Azure Database for PostgreSQL
Platforma Azure udostępnia obszerny zestaw usług używanych do monitorowania wydajności serwera i bazy danych oraz rozwiązywania problemów. Te usługi umożliwiają wyświetlenie sposobu, w jaki postgreSQL korzysta z przydzielonych zasobów platformy Azure. Te informacje służą do oceny, czy chcesz skalować system, modyfikować strukturę tabel i indeksów w bazach danych oraz wizualizować statystyki środowiska uruchomieniowego i inne zdarzenia. Dostępne usługi obejmują:
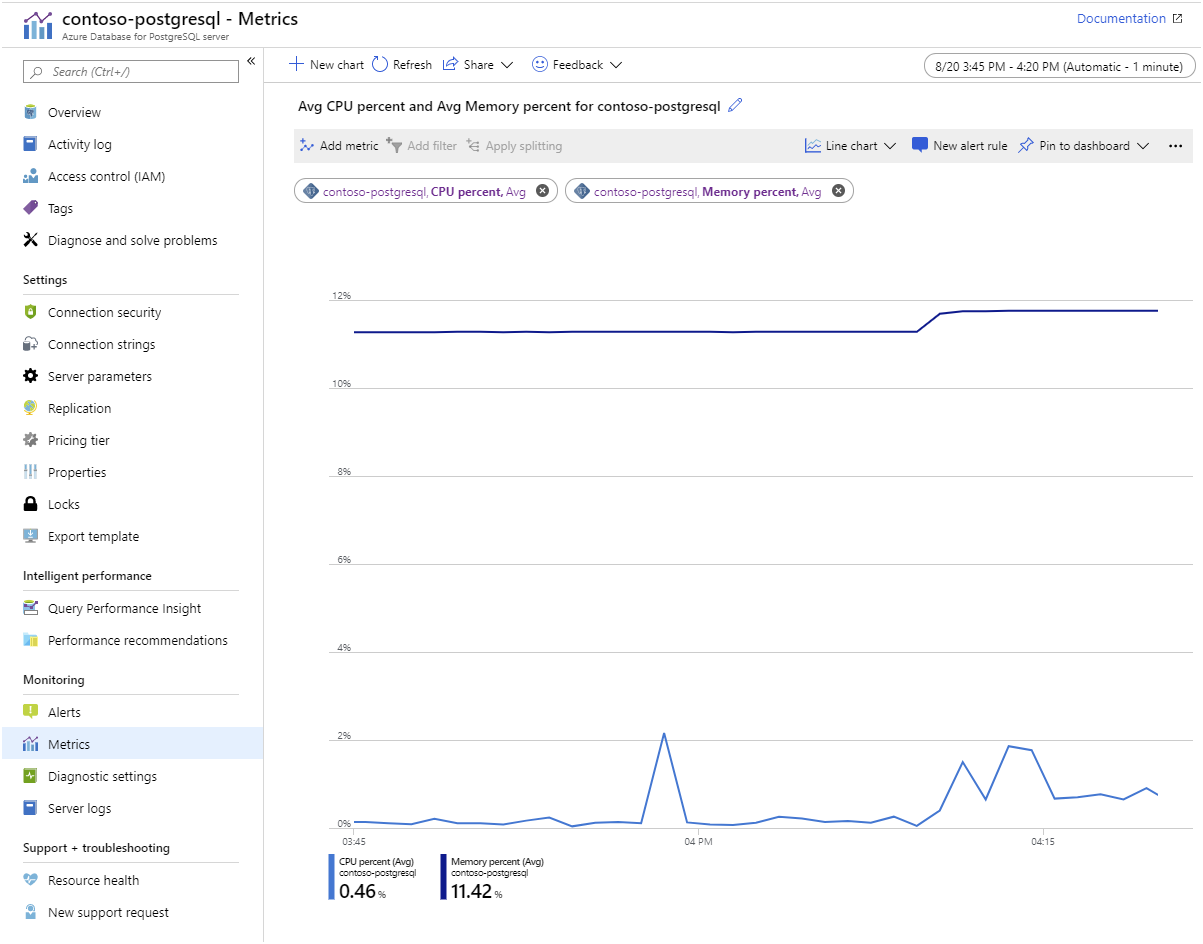
Azure Monitor. Usługa Azure Database for PostgreSQL udostępnia metryki, które umożliwiają śledzenie elementów, takich jak użycie procesora CPU i magazynu, współczynniki we/wy, zajętość pamięci, liczba aktywnych połączeń i opóźnienie replikacji:
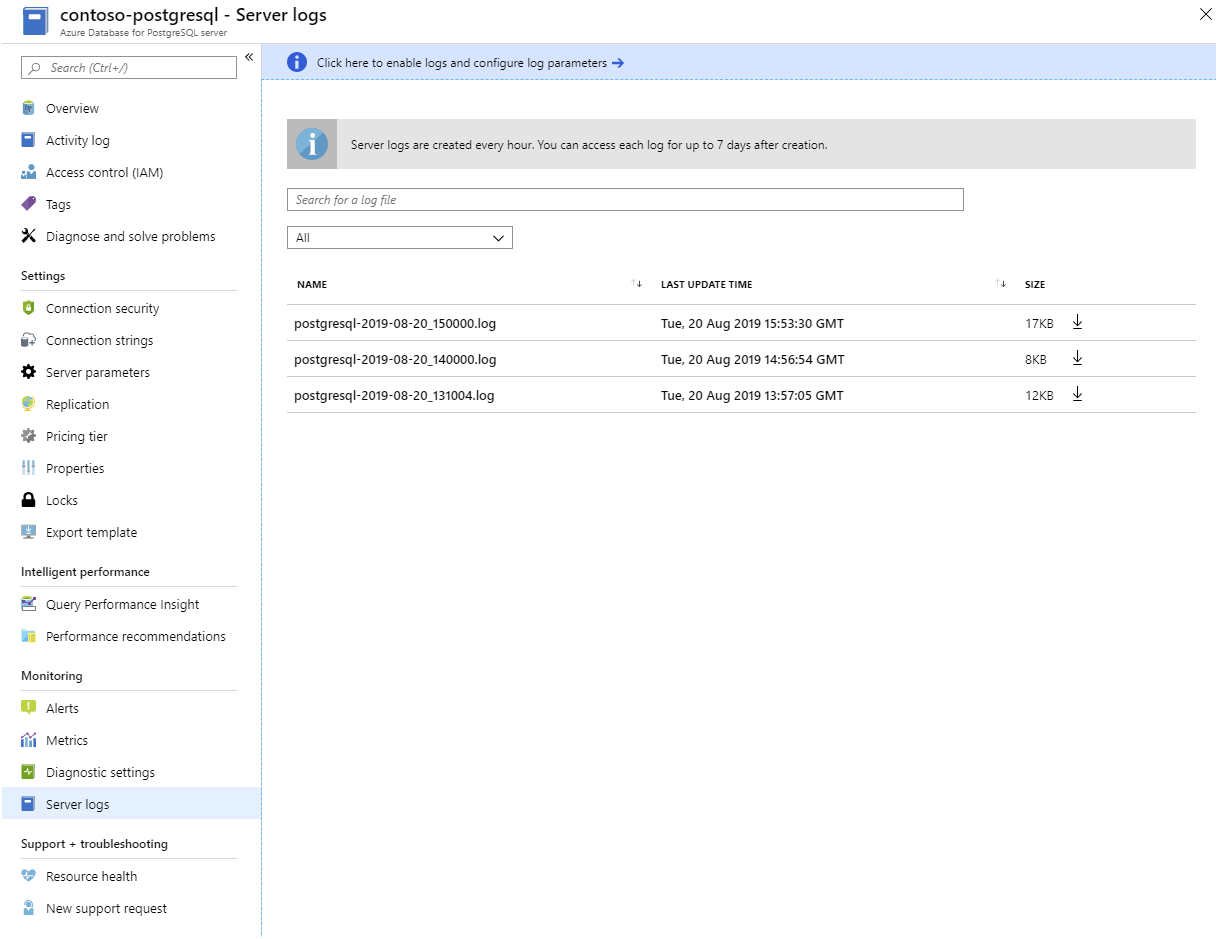
dzienniki serwera . Platforma Azure udostępnia dzienniki dla każdego serwera PostgreSQL. Można je pobrać z witryny Azure Portal:
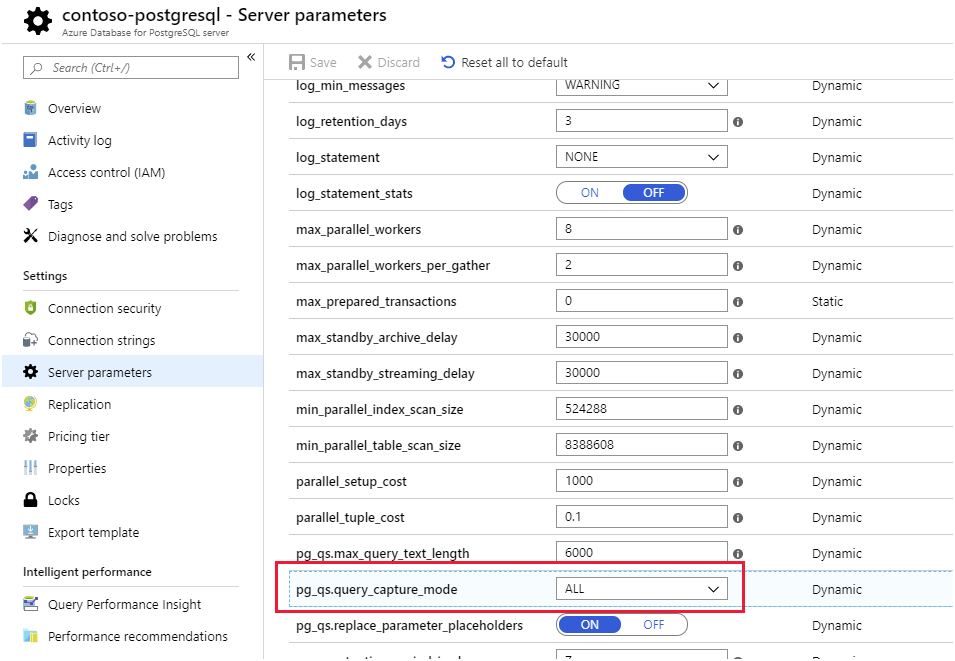
Magazyn zapytań i szczegółowe informacje o wydajności zapytań. Usługa Azure Database for PostgreSQL przechowuje informacje o zapytaniach uruchamianych względem baz danych na serwerze i zapisuje je w bazie danych o nazwie azure_sys w schemacie query_store . Wykonaj zapytanie dotyczące widoku query_store.qs_view, aby wyświetlić te informacje. Domyślnie usługa Azure Database for PostgreSQL nie przechwytuje żadnych informacji o zapytaniach, ponieważ nakłada niewielkie obciążenie, ale możesz włączyć śledzenie, ustawiając właściwość serwera pg_qs.query_capture_mode na ALL lub TOP.
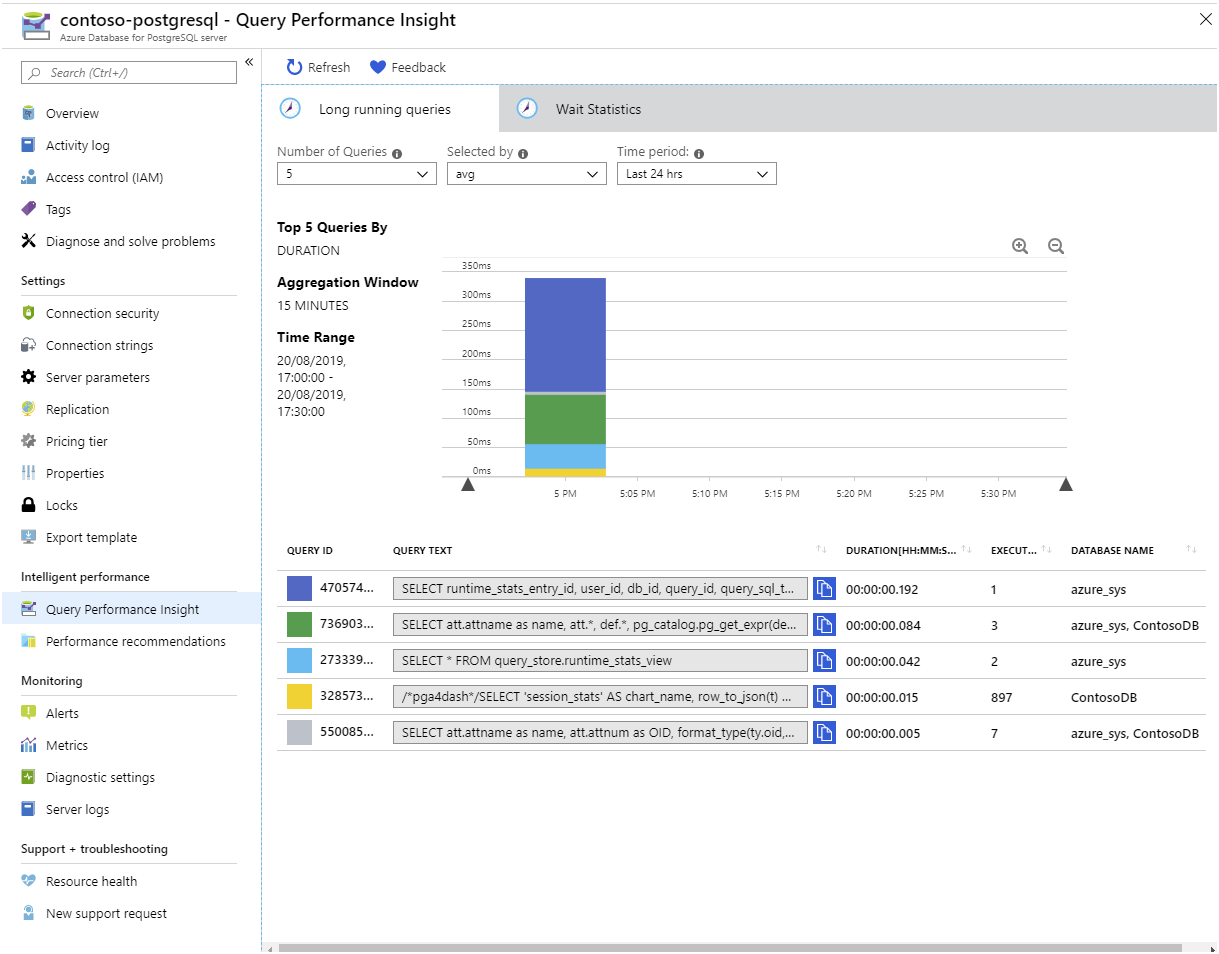
Można również skonfigurować magazyn zapytań, aby przechwytywać informacje o zapytaniach, które spędzają czas oczekiwania. Zapytanie może musieć czekać, gdy inne zapytanie zwalnia blokadę w tabeli, lub ponieważ zapytanie wykonuje wiele operacji we/wy, lub ponieważ pamięć się kończy. Te informacje są widoczne w widoku query_store.runtime_stats_view .
Jeśli wolisz wizualizować te statystyki zamiast uruchamiać instrukcje SQL, użyj szczegółowych informacji o wydajności zapytań w witrynie Azure Portal:
Zalecenia dotyczące wydajności. Narzędzie Rekomendacje dotyczące wydajności, dostępne również w Azure Portal, analizuje zapytania uruchamiane przez aplikacje. Analizuje również struktury w bazie danych i zaleca organizowanie danych — oraz to, czy należy rozważyć dodawanie lub usuwanie indeksów.




Łączność klienta
Usługa Azure Database for PostgreSQL działa za zaporą. Aby uzyskać dostęp do usługi i bazy danych, należy dodać regułę zapory dla zakresów adresów IP, z których klienci nawiązują połączenie. Jeśli musisz uzyskać dostęp do usługi z poziomu platformy Azure — na przykład aplikacji działającej przy użyciu usługi Azure App Services — musisz również włączyć dostęp do usług platformy Azure.
Konfigurowanie zapory
Najprostszym sposobem skonfigurowania zapory jest użycie ustawień zabezpieczeń połączenia dla usługi w witrynie Azure Portal. Dodaj regułę dla każdego zakresu adresów IP klienta. Możesz również użyć tej strony do wymuszania połączeń SSL do swojej usługi.

Kliknij pozycję Dodaj adres IP klienta na pasku narzędzi, aby dodać adres IP komputera stacjonarnego.
Jeśli skonfigurowano repliki tylko do odczytu, należy dodać regułę zapory do każdego z nich, aby były dostępne dla klientów.
Biblioteki połączeń klienta
Jeśli piszesz własne aplikacje klienckie, musisz użyć odpowiedniego sterownika bazy danych, aby nawiązać połączenie z bazą danych PostgreSQL. Wiele z tych bibliotek jest zależnych od języka programowania. Są one utrzymywane przez niezależne strony trzecie. Usługa Azure Database for PostgreSQL obsługuje biblioteki klienckie dla języków Python, PHP, Node.js, Java, Ruby, Go, C# (.NET), ODBC, C i C++.
Logika ponawiania prób klienta
Jak wspomniano wcześniej, niektóre zdarzenia — takie jak przełączenie na awaryjną obsługę podczas odzyskiwania wysokiej dostępności oraz zwiększanie zasobów procesora — mogą spowodować krótką utratę łączności. Wszystkie transakcje w toku zostaną wycofane. Usługa Azure Database for PostgreSQL automatycznie przekierowuje połączonego klienta do węzła roboczego, ale wszystkie operacje wykonywane przez klienta w tym czasie będą zwracać błąd. To zdarzenie należy traktować jako wyjątek przejściowy. Kod aplikacji powinien być przygotowany do przechwytywania tych wyjątków i ponawiania próby.
Funkcje postgreSQL obsługiwane w usłudze Azure Database for PostgreSQL
Usługa Azure Database for PostgreSQL obsługuje większość funkcji najczęściej używanych przez bazy danych PostgreSQL, ale istnieją pewne wyjątki. Jeśli potrzebujesz nieobsługiwanej funkcji, musisz przerobić bazę danych i kod aplikacji, aby usunąć tę zależność, lub rozważyć uruchomienie bazy danych PostgreSQL na maszynie wirtualnej. W tym ostatnim przypadku trzeba będzie wziąć na siebie odpowiedzialność za zarządzanie serwerem i utrzymywanie go.
Obsługiwane rozszerzenia w usłudze Azure Database for PostgreSQL
Wiele funkcji PostgreSQL jest hermetyzowanych w rozszerzeniach. Rozszerzenia to pakiety obiektów SQL i kodu przechowywanego na serwerze — można je załadować do bazy danych przy użyciu polecenia CREATE EXTENSION. Usługa Azure Database for PostgreSQL obecnie udostępnia wiele powszechnie używanych rozszerzeń dla:
- Typy danych
- Functions
- Wyszukiwanie pełnotekstowe
- Indeksy (bloom, btree_gist i btree_gin)
- Język plpgsql
- PostGIS
- Wiele funkcji administracyjnych
Pakiety dblink i postgres_fdw służą do łączenia jednego serwera PostgreSQL z innym — umożliwia to kodowi na jednym serwerze uzyskiwanie dostępu do danych przechowywanych w innym. W usłudze Azure Database for PostgreSQL można łączyć się tylko między serwerami utworzonymi przy użyciu usługi Azure Database for PostgreSQL. Nie można tworzyć połączeń wychodzących z serwerami PostgreSQL hostowanymi gdzie indziej, takimi jak lokalne lub na maszynie wirtualnej.
Uwaga
Lista obsługiwanych rozszerzeń jest stale przeglądana i może ulec zmianie. Wygenerujesz listę rozszerzeń obsługiwanych przy użyciu następującego zapytania. Pamiętaj, że nie można utworzyć własnych rozszerzeń niestandardowych i przekazać je do usługi Azure Database for PostgreSQL:
SELECT * FROM pg_available_extensions;
Usługa Azure Database for PostgreSQL zawiera bazę danych TimescaleDB jako opcjonalne rozszerzenie. Ta baza danych zawiera funkcje analityczne zorientowane czasowo i inne funkcje, które obsługują obciążenia szeregów czasowych. Aby użyć tej bazy danych, wybierz opcję TIMESCALEDB w parametrze serwera shared_preload_libraries , a następnie uruchom ponownie serwer.
Wsparcie języka dla procedur przechowywanych i wyzwalaczy
Obsługa języków innych niż plpgsql zwykle wymaga oddzielnego skompilowania procedury składowanej lub kodu wyzwalacza i przekazania skompilowanej biblioteki na serwer. Głównie ze względów bezpieczeństwa nie można tego zrobić w usłudze Azure Database for PostgreSQL. Jeśli masz kod napisany w innych językach, musisz przełączyć go do pliku plpgsql.